一种基于神经网络模型的句子排序方法
2016-05-04康世泽黄瑞阳
康世泽,马 宏,黄瑞阳
(国家数字交换系统工程技术研究中心,河南 郑州 450002)
一种基于神经网络模型的句子排序方法
康世泽,马 宏,黄瑞阳
(国家数字交换系统工程技术研究中心,河南 郑州 450002)
句子排序是多文本摘要中的重要问题,合理地对句子进行排序对于摘要的可读性和连贯性具有重要意义。该文首先利用神经网络模型融合了五种前人已经提出过的标准来决定任意两个句子之间的连接强度,这五种标准分别是时间、概率、主题相似性、预设以及继承。其次,该文提出了一种基于马尔科夫随机游走模型的句子排序方法,该方法利用所有句子之间的连接强度共同决定句子的最终排序。最终,该文同时使用人工和半自动方法对句子排序的质量进行评价,实验结果表明该文所提出方法的句子排序质量与基准算法相比具有明显提高。
句子排序;多文本摘要;神经网络模型;马尔科夫随机游走模型
1 简介
互联网发展至今蕴含了巨大的信息量,当计算机用户在网络上查询需要的信息时往往会面临海量的检索结果,怎样从中筛选出需要的答案变成了一个难题。文本摘要技术应运而生成为了从海量信息中筛选所需信息的一种途径。文本摘要系统可以从大量的文本信息中生成可以概括原文本主要信息的简短摘要。从一组给定的文本集合中生成的摘要被称为多文本摘要[1-3],从单一的文本中生成的摘要被称为单文本摘要。
多文本摘要系统的任务通常包括句子抽取、话题检测、句子聚类、句子排序[4]等。句子的抽取和聚类决定了生成摘要所涵盖的信息量,而Barzilay[5]的研究表明对句子的合理排序可以显著提升摘要的可读性和连贯性。
相对于单文本摘要,多文本摘要的句子排序问题更加具有挑战性,因为对于多文本摘要来说,尽管一个文本集中的文本都在讨论相同或相似的话题,但是从不同的文本中摘取到的句子通常由不同的作者完成于不同的时间,具有不同的写作风格和背景知识。因此对于多文本摘要系统来说,合理地对句子进行排序对于摘要的可读性和连贯性意义更大,同时也更加具有难度。当然句子排序技术也不仅仅应用在摘要生成之中。在自然语言生成中[6],系统生成的句子也需要通过科学的排序,组织成具有连贯性的摘要。
本文第二部分将介绍本文的相关工作;第三部分将详细介绍本文提出的句子排序方法;第四部分介绍句子排序的评价方法;第五部分是实验部分;最后是对全文的总结。
2 相关工作
目前已有很多关于句子排序的相关工作。有些将句子排序与句子选择相互分离,仅研究句子排序的方法,而另一些工作则将选择和排序同时进行。
对于第一类工作,Peng[7]提出了一种结合支持向量机和灰色模型的句子排序方法,该方法首先利用支持向量机对原文档进行学习并预测句子顺序,之后再利用灰色模型对句子顺序进行修正。Bollegala[8]提出了一种基于偏好学习的句子排序方法。为了捕获句间的偏好,Bollegala定义了五种偏好专家: 时序、概率、主题相似性、预设以及继承。他们使用人工编写的摘要作为训练数据来学习几种偏好专家的最佳组合。最终,学习到的最佳组合将会被用于对从多文本摘要系统抽取的句子进行排序。该工作提出的句子排序算法使用贪婪搜索方法,通过把各个句子成对比较来生成最终的排序。Sukumar[9]在Bollegala工作的基础上考虑了句子之间的语义关系。他们提出的系统使用WordNet同义词集考虑摘要中句间的语义关系,该系统在安排摘要中句子顺序的时候构建了一个蕴含模型来对句间的逻辑关系进行推测。
对于第二类工作,Nishikawa[10]提出了一种同时考虑信息量和可读性的情感摘要算法。该方法将句子的选择与排序同时进行。其中信息量的分数是通过计算情感表达式个数获得的,而可读性的分数是通过从目标语料学习获得的。之后Nishikawa[11]又提出了同时考虑内容和连贯性的情感摘要算法。该工作将摘要视为一个句子序列并且通过线性规划方法,从多个文档选择和排序以获得最佳的序列。他们提出的线性规划方程是最大覆盖问题和旅行商问题的融合。
第二类方法由于还要兼顾句子选择,在进行句子排序时考虑的因素相对较少,因此本文舍去了句子选择的部分。
3 本文方法
3.1 文本片段间关系
本文引入判断函数f(a→b)来表示句子a和b之间的连接强度和方向,如式(1)所示。
(1)
其中p表示两个句子a和b之间的连接强度。
(1) 时间标准
时间标准反应了两个句子在语料中出现的时间先后。本文定义了将b排列在a后的时间标准函数如式(2)所示。
(2)
其中,T(a)为句子a的发布时间,D(a)表示句子a所属文档,N(a)表示句子a在所处文档中所处的行数。当句子a在发布时间上先于b时f(a→b)会被赋予值1,如果两个句子在同一文档中,句子a相对句子b位置靠前时f(a→b)会被赋予值1;当两个句子不在同一文档却有相同的发布时间时会被赋予值0.5,表示两个句子的顺序无法判断。
(2) 概率标准
概率标准反应了两个句子在语料中相邻出现的概率。本文利用Lapata[12]提出的概率模型来计算两个句子相邻的概率。
Lapata的模型定义一个摘要T是由句子序列{s1,s2,…,sn}按序列内部顺序构成的,观察到该序列的概率P(T)如式(3)所示。
(3)
基于马尔科夫假设可以认为一个句子出现的概率仅和与它直接相邻的前一个句子相关,由此式(3)可以改写为式(4)。
(4)
Lapata把名词、动词和依存结构作为特征来表示句子,假设这些特征彼此独立,并且用相邻句子笛卡尔乘积特征组中的特征对P(si|si-1)进行估计,如式(5)所示。
(5)
a
(6)
其中d(a
(7)
(3) 主题相似性标准
Barzilay[5]提出利用两个句子所涉及的主题来对它们的相似性进行衡量的方法。对于摘要中的任意句子l,首先定义主题相似性函数如式(8)所示。
(8)
其中Q表示已经排序完毕的句子组,q是Q中的一个子句。sim(l,q)表明两个句子向量的相似性。为了计算句子的相似性首先需要将句子转化为向量。为了将句子转化为向量需要做停用词去除和词型转换的预处理。Barzilay使用的句子向量将向量的每个元素对应于原句的一个名词或动词,并使用余弦相似性对两个向量的相似性进行计算。
使用以上定义的主题相似性函数,本文定义如式(9)所示的主题相似性标准函数。
(9)
其中,∅代表空集,a、b代表正在被考虑的两个句子,Q为已经排序完毕的句子集合。主题相似性标准函数的值在两个句子的主题相似性相同或还没有开始进行句子排序时取值为0.5,表示两个句子的排序无法决断。
(4) 预设标准
一个被抽取式摘要算法抽取的句子可能包含一些预设信息,这些信息可能包含在原文位于该句子前面的一组句子中,而这组句子没有被摘要算法摘取。预设标准衡量了一个句子是否可以替代另一个文本片段的预设信息。该想法是由Okazaki[13]提出的句子排序算法提炼的。首先定义预设函数如式(10)所示。
(10)
其中Q表示已经排序完毕的句子组,q是Q中的一个子句。Pq是在原文中位于句子q之前的句子组,从中选择可以使sim(p,l)最大的句子来计算预设函数的值。
最终可以定义预设标准函数如式(11)所示。
(11)
其中,∅代表空集,a、b代表正在被考虑的两个句子,Q为已经排序完毕的句子集合。预设标准函数的值在两个句子的预设函数值相同或还没有开始进行句子排序时取值为0.5,表示两个句子的排序无法决断。
(5) 继承标准
继承标准是和预设标准相对的,对于一个被抽取式摘要算法抽取的句子,在原文位于该句子后的句子组可能和其构成逻辑上的因果关系或包含该句子的一些继承信息。继承标准衡量了一个句子b是否可以替代另一个文本片段的继承信息。首先定义继承函数如式(12)所示。
(12)
其中,Sq是在原文中位于句子q之前的句子组,从中选择可以使sim(p,l)最大的句子来计算继承函数的值。
最终可以定义继承标准函数如下式(13)所示。
(13)
继承标准函数的值在两个句子的继承函数值相同或还没有开始进行句子排序时取值为0.5,表示两个句子的排序无法决断。
3.2 句子间分数计算
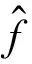
(14)
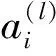
如图1所示为该模型的隐含层含有五个节点即n=5时的示例。
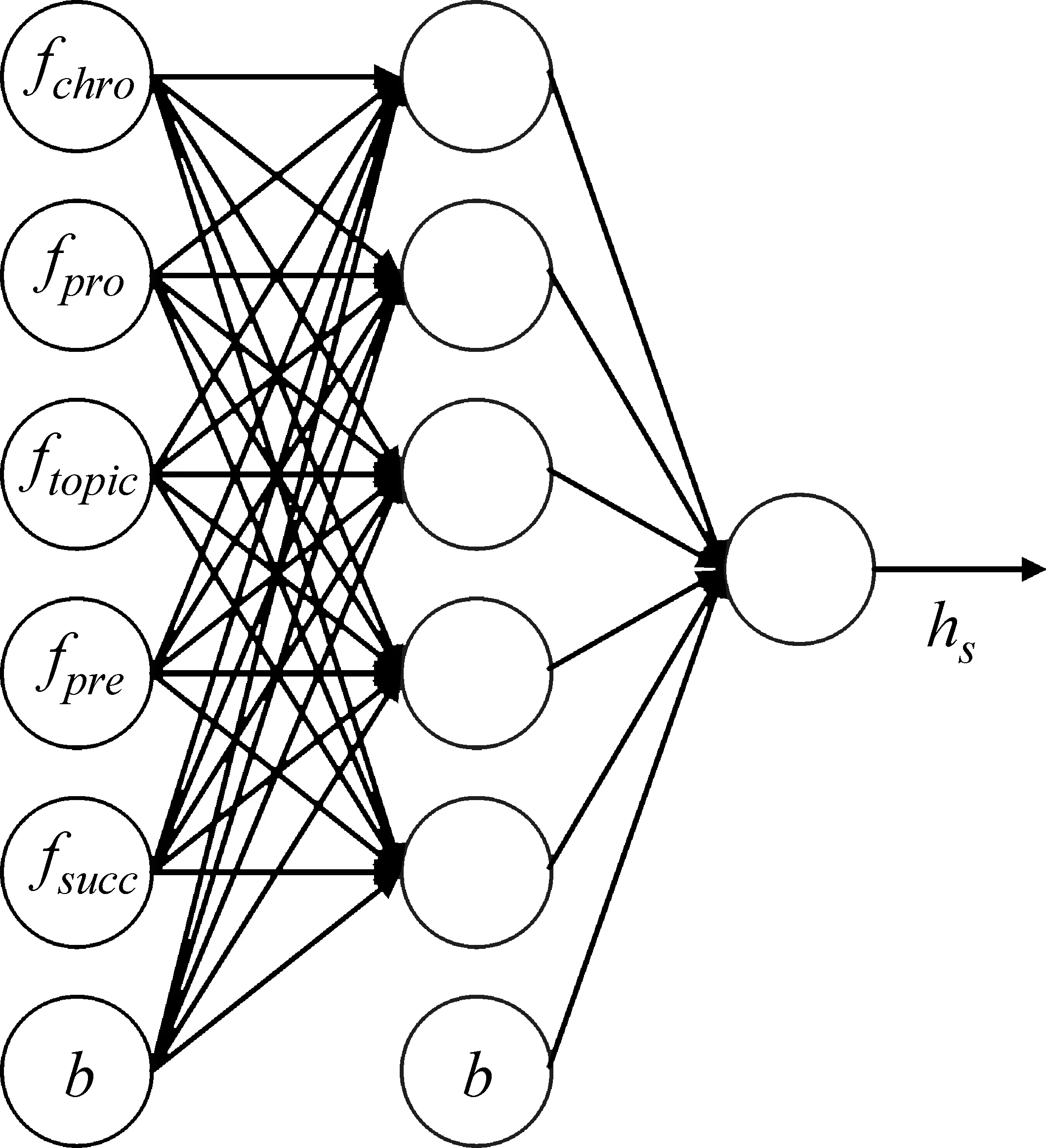
图1 隐含层有五个节点的神经网络示例
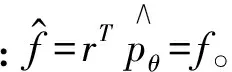
(15)
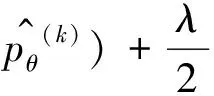
(16)
其中m是用于训练的对数,上标k代表第k对文本片段组。
本文设置K=13,在对语料进行标注时,句子a排在句子b之前的分数如式(17)所示。
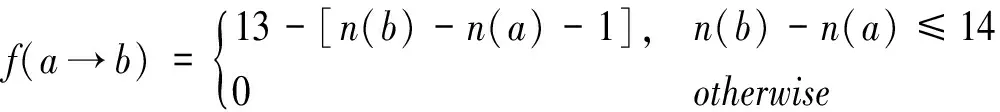
(17)
其中n(a)为句子a在文档中的位置。当两个句子的位置差距大于14时相互之间的影响会比较小,因此分数本文将其分数设为0。
3.3 句子排序

算法1
本文基于马尔科夫随机游走模型对句子进行排序。马尔科夫随机游走模型(MRW)可以通过从全图递归得到的全局信息决定图内任一顶点的重要性。定义图G=(V,E)如图2所示。V是顶点集,任一顶点vi∈V是待排序句子序列中的一员。E是边的集合,任意两个顶点vi和vj的判断函数值如果存在(大于0)都会存在一条边eij∈E。每条边都对应着句间的连接权重,该权重就是两个句子间的判断函数值f(i→j)。
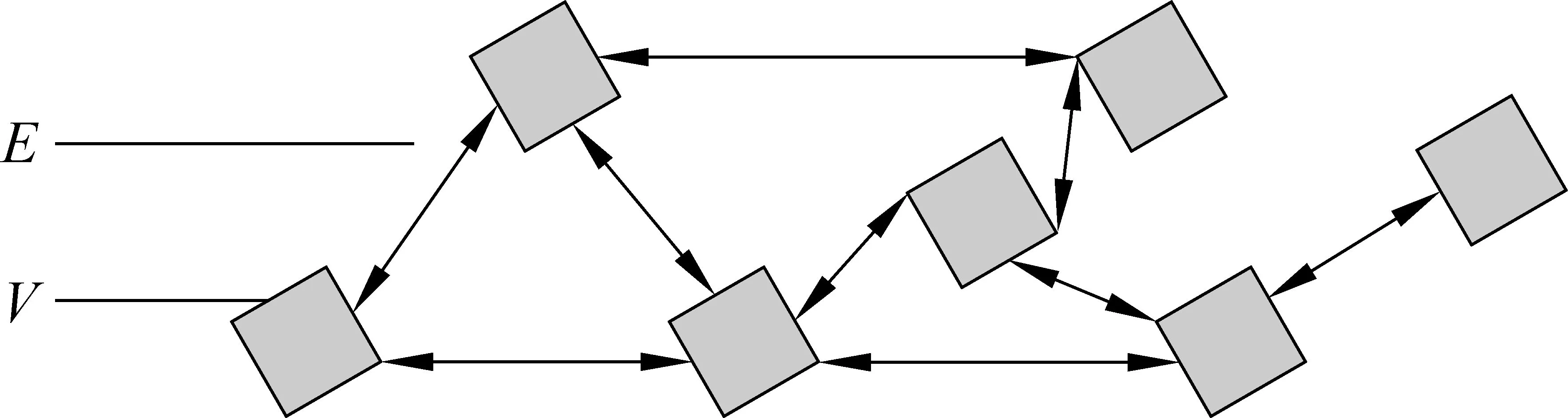
图2 马尔科夫随机游走模型
通过归一化相应权重可以得到从顶点vi到vj的过渡概率如式(18)所示。
(18)
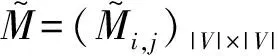
(19)
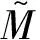
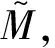
(20)
它的矩阵形式为式(21)。
(21)
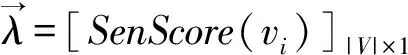
在执行阶段,所有句子的初始分数都设为1并利用公式(20)来迭代计算各个句子的分数。通常连续两次迭代各个句子的差值都小于一个固定阈值时算法收敛。
当图G按照公式(20)执行至收敛后从X中选取排序分数最高的句子加入句子组Q,剩下的句子组成新图并按照(20)执行至收敛,按照算法1中的步骤执行到X中没有句子为止,Q中的句子顺序就是最终的排序结果。
4 实验结果与分析
本文收集了2012年六大门户网站(网易、新浪、腾讯、搜狐、新华网、中华网)的新闻数据,共分为国内、国际、体育、社会、娱乐等18个类别,其中每条新闻数据都标注了发布的时间。
本文使用MEAD[14]从每个类别中抽取句子。MEAD是一种基于质心的多文本摘要算法,对于一系列相关文档中的每个句子,MEAD使用三种特征并利用它们的线性结合判断哪些句子最有突显性。这三种特征分别是质心分数、位置以及最短句长。最终,本文利用MEAD从每个类别之中抽取了15个句子。
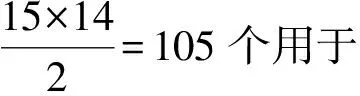
为了进行比较,本文使用了六种方法。
随机排序(RO) 此种方法就是指对句子进行随机排序,它代表了性能较低的基准算法。
概率排序(PO) 此种方法就是指利用概率标准函数对句子进行排序。使用此种方法的前提是训练语言模型。本文将18个类别的所有语料作为训练语料,利用fudannlp对语料进行分词和提取依存结构并将它们作为特征。
时间排序(CO) 此种方法就是指利用时间标准函数对句子进行排序。
支持向量机监督方法(SVM) 本文所使用的神经网络主要起到分类器作用,因此将其替换为支持向量机分类器作为对比。
贝叶斯分类器监督方法(Naïve Bayes) 将本文所使用的神经网络模型替换为朴素贝叶斯分类器作为对比。
本文提出方法(LO) 即为本文所使用的方法。
本文并未使用主题相似性标准、预设标准和继承标准,因为这几种标准都无法在句子排序没有进行初始化的情况下使用,当然它们都融入了本文所提出的方法。
4.1 人工评价
可以使用人工评价的方法评价句子顺序的质量。评价人在对一个摘要进行评价时通常从以下四个指标中选择一种作为该摘要的评价结果。
完美 完美摘要是指无法通过重新排序进一步改进的摘要。
可接受 可接受摘要是指可以理解并且无需修改,但在可读性上仍然需要提高的摘要。
一般 一般摘要是指丢失了某些故事主线,并需要少量修改使其可以提升到可接受级别的摘要。
不可接受 无法接受的摘要是指需要较大的改进并且需要从整体上调整结构的摘要。
本文安排了两名评价员按照上文所提到的四种评价指标对各种方法生成的摘要进行评价。两名评价员都已经阅读了摘要的源文档,并被告知使用各种方法生成的摘要只有内部句子顺序不同。每种句子排序方法一共有18×2=36组评价结果,分别累加各方法所获得四种评价的数量并计算比例,最终的评价结果如图3所示。
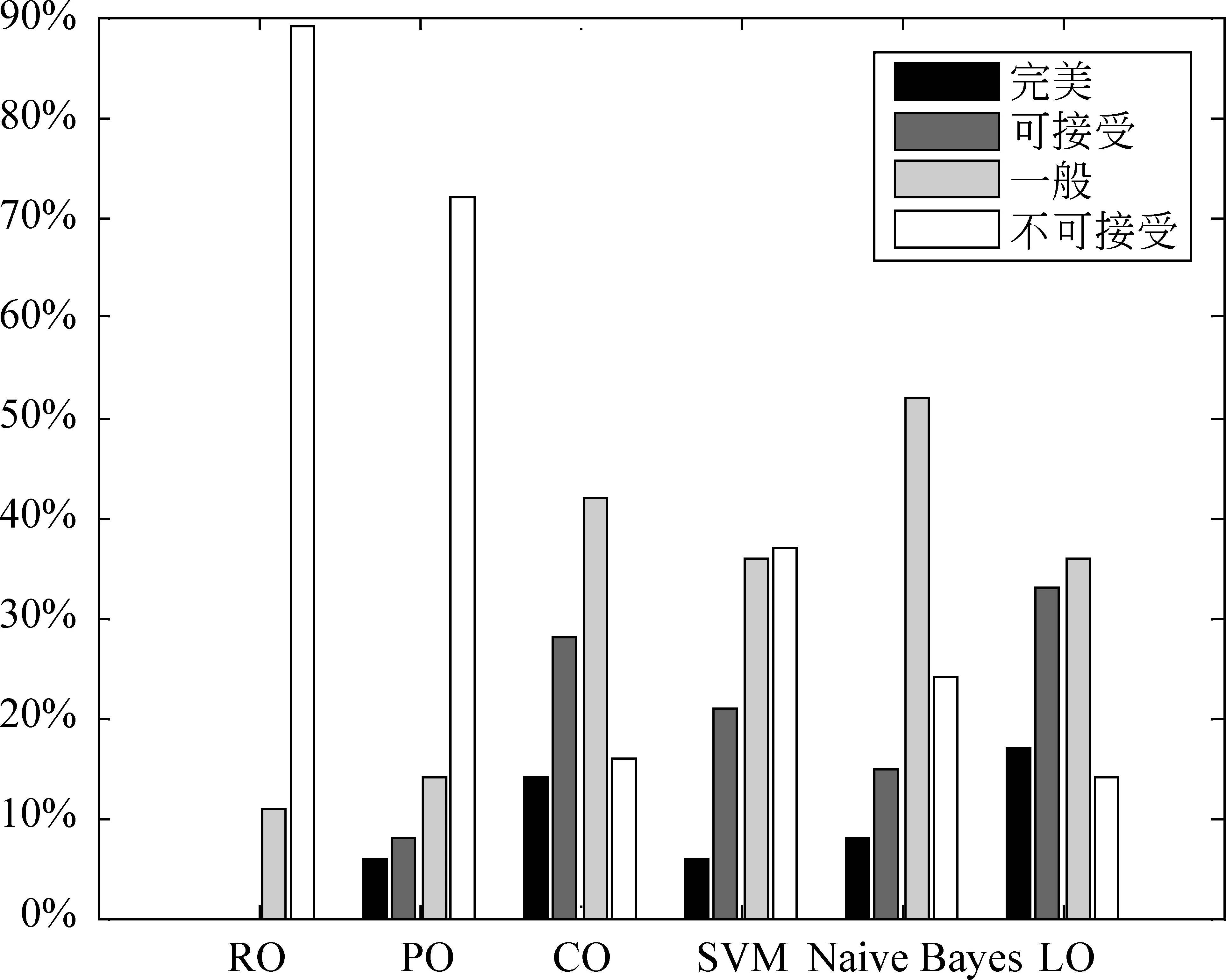
图3 人工评价结果
从图3的实验结果可以看出,本文所提出方法的实验效果是最好的。虽然利用时间排序方法生成的一般质量摘要比例高于本文所提出方法,但是本文提出方法生成的一般以上(完美、可接受)质量摘要所占的比例要高于利用时间排序方法生成的摘要,而且时间排序方法效果较好的原因主要是新闻语料实时性强。另外使用SVM和Naïve Bayes方法所取得的结果整体不如本文所提出方法,主要表现在它们生成的不可接受摘要比例较高。
4.2 半自动评价
人工评价的方法工作量太大,需要消耗大量的时间,因此本文又使用了Kendall等级相关系数、Spearman等级相关系数以及平均连续性(Average Continuity,AC)[16]等半自动方法对句子顺序进行评价。评价结果如表1所示。
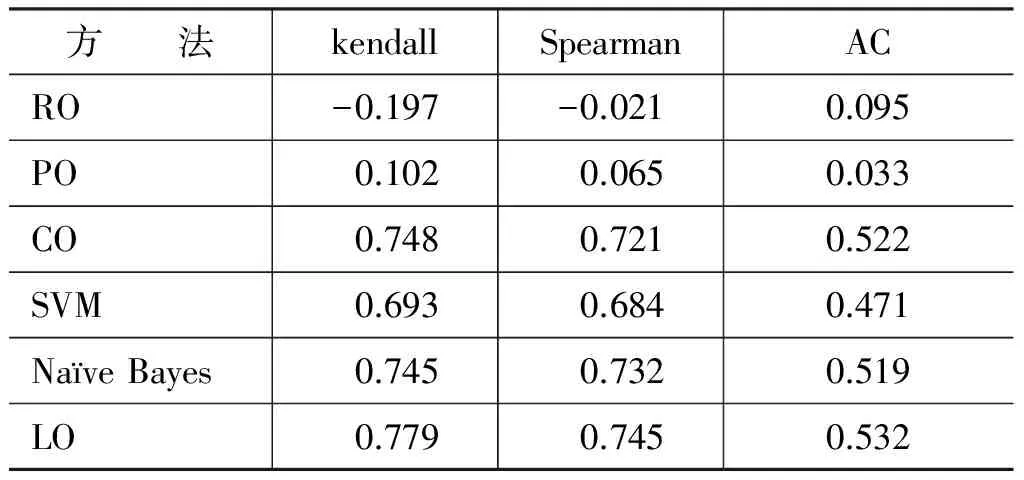
表1 语料1半自动评价结果
从表1的结果可以看出,本文所提出方法的性能在六种方法中是最好的。其中随机排序方法和概率排序方法的实验效果较差。概率排序方法效果较差的原因是本文在训练概率模型时使用的是新闻语料,新闻语料是用于描述新事件的,因此在旧新闻中在相邻句子中共现的词语很少在需要排序的两个句子中共现。时间排序方法相对概率排序方法效果较好,原因也是由于本文采用的训练语料是新闻语料,语料中本身包含了时间信息。效果最好的是本文所提出的方法,因为它同时综合了多种因素对句子进行排序。Naïve Bayes方法效果与时间排序方法相近,都差于本文所提出方法,而SVM方法效果稍差于Naïve Bayes方法。在将神经网络模型作为监督分类器的其他一些工作中,其性能也好于SVM和Naïve Bayes[17-18]。
4.3 图排序算法性能对比
本文提出了一种基于马尔科夫随机游走模型的方法对句子进行排序,为了验证该方法的性能,本文将其与其他几种常用的图排序算法进行了对比。这几种基准算法分别是PageRank[19]算法、HITS算法[20]以及传统的马尔科夫随机游走模型(MRW)[21]。将从每个新闻类别选取的15个句子分别利用基准算法进行排序,由于人工评价方法比较费时,因此本文利用半自动评价方法将各基准算法排序的结果与本文提出方法获得的结果进行对比,评价结果如表2所示。
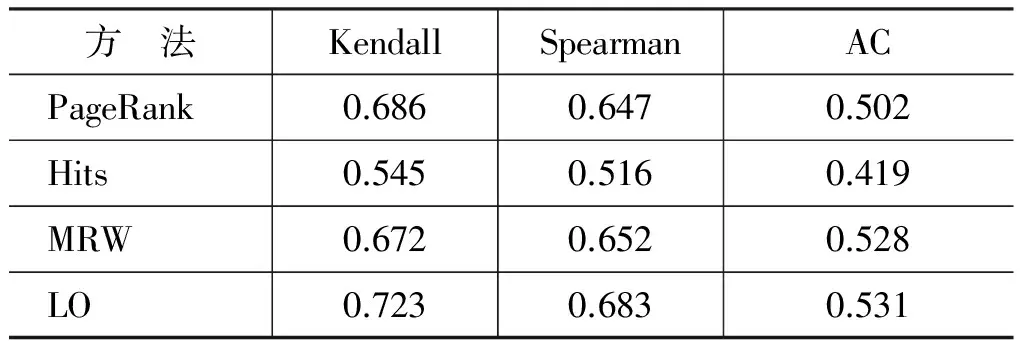
表2 语料1半自动评价结果
从实验结果可以看出,本文所提出的方法性能最好。PageRank算法和传统的马尔科夫随机游走模型表现接近而且和本文所提出方法的差距不大。HITS算法相对其他几种算法表现最差。本文提出方法效果更好的原因是本文在图排序算法的基础上又提出了算法1所示的句子排序方法。
5 结论
本文利用神经网络将几种前人提出的句子排序方法融合,并在此基础上提出了一种基于马尔科夫随机游走模型的句子排序算法。经过实验验证,利用本文所提出的方法对句子进行排序相对基准算法可以取得更好的效果。接下来的工作主要集中在进一步提高摘要的可读性上,例如,利用句子压缩的方法进行摘要润色。
[1] 韩永峰, 许旭阳, 李弼程, 等. 基于事件抽取的网络新闻多文档自动摘要[J]. 中文信息学报, 2012, 26(1): 58-66.
[2] 刘平安. 基于HLDA模型的中文多文档摘要技术研究[D]. 北京邮电大学, 2013.
[3] Wang L,Raghavan H, Castelli V, et al. A Sentence Compression Based Framework to Query-Focused Multi-Document Summarization[C]//Proceedings of ACL, 2013.
[4] Ferreira R, Cabral L D S, Freitas F, et al. A multi-document summarization system based on statistics and linguistic treatment[J]. Expert Systems with Applications, 2014, 41(13): 5780-5787.
[5] R Barzilay, N Elhadad, K McKeown. Inferring strategies for sentence ordering in multidocument news summarization[J]. Journal of Artificial Intelligence Research,2002,17: 35-55.
[6] Banik E, Kow E, Chaudhri V. User-Controlled, Robust Natural Language Generation from an Evolving Knowledge Base[J]. Enlg, 2013.
[7] Peng G, He Y, Zhang W, et al. A Study for Sentence Ordering Based on Grey Model[C]//Proceedings of Services Computing Conference (APSCC) IEEE, 2010: 567-572.
[8] Bollegala D, Okazaki N, Ishizuka M. A preference learning approach to sentence ordering for multi-document summarization[J]. Information Sciences, 2012, 217: 78-95.
[9] Sukumar P, Gayathri K S. Semantic based Sentence Ordering Approach for Multi-Document Summarization[J]. International Journal of Recent Technology and Engineering (IJRTE), 2014, 3(2): 71-76.
[10] Nishikawa H, Hasegawa T, Matsuo Y, et al. Optimizing informativeness and readability for sentiment summarization[C]//Proceedings of the ACL 2010 Conference Short Papers. Association for Computational Linguistics, 2010: 325-330.
[11] Nishikawa H, Hasegawa T, Matsuo Y, et al. Opinion summarization with integer linear programming formulation for sentence extraction and ordering[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 910-918.
[12] M Lapata,Probabilistic text structuring: Experiments with sentence ordering[C]//Proceedings of the annual meeting of ACL, 2003: 545-552.
[13] Naoaki Okazaki, Yutaka Matsuo, and Mitsuru Ishizuka. Improving chronological sentence ordering by precedence relation[C]//Proceedings of 20th International Conference on Computational Linguistics (COLING 04), 2004: 750-756.
[14] Dragomir R Radev, Hongyan Jing, and Malgorzata Budzikowska. Centroid-based summarization of multiple documents: sentence extraction, utility-based evaluation, and user studies[J]. ANLP/NAACL Workshop on Summarization, Seattle, WA, April 2000.
[15] Hinton G E. A Practical Guide to Training Restricted Boltzmann Machines[M]. Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012: 599-619.
[16] D Bollegala, N Okazaki, M Ishizuka, A bottom-up approach to sentence ordering for multi-document summarization[J]. Information Processing and Management,2010,46(1): 89-109.
[17] Sharma A K, Prajapat S K, Aslam M. A Comparative Study Between Naive Bayes and Neural Network (MLP) Classifier for Spam Email Detection[C]//IJCA Proceedings on National Seminar on Recent Advances in Wireless Networks and Communications. Foundation of Computer Science (FCS), 2014,(2): 12-16.
[18] Gharaviri A, Dehghan F, Teshnelab M, et al. Comparison of neural network, ANFIS, and SVM classifiers for PVC arrhythmia detection[C]//Proceedings of Machine Learning and Cybernetics, International Conference on. IEEE, 2008, 2: 750-755.
[19] 林莉媛, 王中卿, 李寿山, 等. 基于 PageRank 的中文多文档文本情感摘要[J]. 中文信息学报, 2014, 28(2): 85-90.
[20] 苗家, 马军, 陈竹敏. 一种基于 HITS 算法的 Blog 文摘方法[J]. 中文信息学报, 2011, 25(1): 104-109.
[21] Wan X, Yang J. Multi-document summarization using cluster-based link analysis[C]//Proceedings of the 31st annual international ACM SIGIR conference on research and development in information retrieval. ACM, 2008: 299-306.
A Neural Network Model Based Sentence Ordering Method for Multi-document Summarization
KANG Shize,MA Hong,HUANG Ruiyang
(National Digital Switching System Engineering & Technological R&D Center, Zhengzhou,Henan 450002, China)
Sentence ordering is an important task in multi-document summarization. For this purpose, we first use neural network model to incorporate five proposed criteria for sentence connection, namely chronology, probabilistic, topical-closeness, precedence, and succession. Then, a sentence ordering method based on Markov random walk model is proposed, which determines the final ordering of the sentences based on the strength of connection between them. Examined by the semi-automatic and a subjective measures, the proposed method achieves obviously better sentence order compared with the baseline algorithms in the experiments.
sentence ordering;multi-document summarization;neural network model;Markov Random Walk Model

康世泽(1991—),硕士研究生,主要研究领域为数据挖掘、自然语言处理。E⁃mail:xdkangshze@163.com马宏(1968—),硕士,研究员,主要研究领域为数据挖掘、电信网信息关防。E⁃mail:13838175769@139.com黄瑞阳(1986—),博士,助理研究员,主要研究领域为文本挖掘、图挖掘。E⁃mail:277433109@qq.com
1003-0077(2016)05-0195-08
2015-10-15 定稿日期: 2016-04-15
TP391
A
