基于多特征融合和图匹配的维汉句子对齐
2016-05-03倪耀群许洪波程学旗
倪耀群,许洪波,程学旗
(1. 中国科学院 计算技术研究所网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100049;3. 洛阳外国语学院 语言工程系,河南 洛阳 471003)
基于多特征融合和图匹配的维汉句子对齐
倪耀群1,2,3,许洪波1,程学旗1
(1. 中国科学院 计算技术研究所网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100049;3. 洛阳外国语学院 语言工程系,河南 洛阳 471003)
维吾尔语新闻网页与对应的中文翻译网页在内容上往往并非完全可比,主要表现为双语句子序列的错位甚至部分句子缺失,这给维汉句子对齐造成了困难。此外,作为新闻要素的人名地名很多是未登录词,这进一步增加了维汉句子对齐的难度。为了提高维汉词汇的匹配概率,作者自动提取中文人名、地名并翻译为维吾尔译名,构造双语名称映射表并加入维汉双语词典。然后用维文句中词典词对应的中文译词在中文句中进行串匹配,以避免中文分词错误,累计所有匹配词对得到双语句对的词汇互译率。最后融合数字、标点、长度特征计算双语句对的相似度。在所有双语句子相似度构成的矩阵上,使用图匹配算法寻找维汉平行句对,在900个句对上最高达到95.67%的维汉对齐准确率。
句子对齐;人名、地名翻译;多特征融合;二部图最佳匹配
1 引言
随着互联网的发展,多民族网络交流日益频繁和深入,迫切需要机器翻译和跨语言检索等工具的支持。双语语料是统计机器翻译、跨语言检索、双语词典构建等研究领域的重要基础资源。而平行句对挖掘则是构建双语语料的关键技术,因而具有重要的研究价值。
互联网维汉双语新闻的出现为平行语料库的构建提供了稳定的来源。目前天山网、人民网(维文版)和新疆自治区政府网站会登载、转发维汉双语新闻,但是从中挖掘平行句对存在一些困难,主要表现在:
(1) 维文与中文的差异大
中国维吾尔族使用的维吾尔文是一种拼音文字,有老维文和拉丁维文两种等价的书写体系(本文以拉丁维文为标准进行叙述,后同),在词汇形态构成上属于黏着语,变化复杂,在语法上常常动词后置(SOV结构)。而中文是一种象形文字,在词汇构成上属于分析语,词汇之间没有自然边界,在语法上一般使用主谓宾(SVO)结构。
(2) 网页双语文本存在较大噪音
维汉双语网页新闻的特点是更新快,用语准确度低和摘要式翻译,从中提取的篇章对齐文本称为准可比语料(quasi-comparable corpus)[1]。摘要翻译往往会省略中文(或者维文)的若干段落,或段落中的某些句子,导致双语句子不能一一对应,双语句子标号不一定呈现线性关系。因此,双语新闻中在内容上只是部分对应,这是一类噪音。此外,网页转载时,新闻网页的元信息(如记者、新闻机构名、发布时间等)一般会发生变化,新闻中常常出现一些新的名称(人名、地名、新词等),这些不断变化的非词典词是另一类噪音。
(3) 句子对齐模式复杂
双语句子对齐的基本单位称为句珠(sentence bead),一个句珠含有若干原文句子和对应的若干译文句子。具体到维汉双语,假设维文句子数目和中文句子数目分别m个和n个,称该句珠为m: n的句子对齐模式。据文献[2]统计,维汉篇章语料库中有93.2%是双语句子1∶1对齐模式,还有5.3%是1∶2或者2∶1的对齐模式。句珠的对齐模式还存有1∶0模式、0∶1模式、2∶2模式、1∶3模式等多种可能,这些复杂多样的对齐模式增大了句子对齐的难度。
针对以上问题,作者提取了双语句子的多种特征计算双语句对的互译程度(相似度)。先使用规则构造了中文人名地名与维文译名的映射,解决了大部分未登录词的互译匹配问题;同时为避免中文分词错误,在计算词汇互译率时,用词典中文词直接在中文句子中进行串匹配。同时融合了句子中的数字、标点等特征,使得双语句子的相似度计算具有较高的可靠性。在此基础上,将双语句子作为二部图的顶点,句子相似度作为连边的权值,使用图匹配的方法求得最佳匹配。图匹配方法避免了动态规划算法中最优子结构和重叠子结构的限制(原语句子无法与译文中位置相差较大的句子对齐),使句子匹配的范围更大,甚至在颠倒句子顺序时也可以正常匹配。需要说明的是,本文主要针对占比最大的1∶1模式的句珠(即平行句对)的自动生成展开研究。
本文的组织结构如下: 第二部分介绍了句子对齐的相关工作,总结了存在的问题;第三部分介绍了维汉句子特征选取和双语特征的匹配,分为人地名转写、数字特征、词典词汇匹配与句子长度因素特征;第四部分基于融合的特征计算双语句子相似度,在900对双语句子生成的相似度矩阵上,使用贪婪匹配和二部图最大权匹配(KM算法)进行句子对齐,比较了各种算法的准确率;分析实际数据后得出三种算法的适用范围;第五部分是总结和未来工作方向。
2 句子对齐的相关工作
句子对齐主要有基于长度的方法和基于词汇的方法,以及目前研究较多的两者融合的方法。
基于长度的方法有两个前提条件,第一个条件是表达同一语义的双语文本,在长度上是正相关的;另一个条件是原文句子的序号(句子位置)与译文句子序号差值不大。文献[3]在英德法语料库中,按照字符长度构造了一个表征译文长度对应原文长度的标准化变量δ,该随机变量服从标准正态分布,使用δ估计句子的相似度,如式(1)所示。
(1)
其中,l2为译文句长,l1为原文句长。在Gale的方法中计算原文句子和译文句子的六种对齐模式(1∶1),(1∶0),(1∶2),(0∶1),(2∶1),(2∶2)。尽管1∶0的对齐关系的句子完全判断错误,但由于该类问题所占比例非常小,总体句子对齐达到96%的准确率。
文献[4]首次将该方法引入英汉句子对齐。在得到的438个1∶1句珠中,有377个(86.1%)是正确的。另外结合词汇信息后,准确率提升到92.1%。Wu[4]分析纯粹基于长度的方法易受长度伸缩性大的文本影响,尤其在中文这种高度精炼的非拼音文字中,句子长度没有印欧语系拼音文字那么强的相关性。结合词汇信息能获得更高的句子对齐准确率。
基于词汇的方法根据双语句子互译词的个数来计算互译率,互译词要么来源于双语词典,要么根据事先统计的双语词汇共现概率。语言专家编辑的双语词典包含了双语最基本的词汇映射关系,是单词匹配的基础。但是未登录词问题和译文的灵活翻译问题限制了双语词典的匹配效果[5]。
香港学者[1]在英汉准可比语料上利用词典和词汇互信息,在篇章集合、句子和词汇三个级别反复迭代,用多级自举(multi-level bootstrapping)和阈值筛选的方法生成平行句对。英汉双语文本的普遍性使得在双语文档集合内,词汇共现的次数足够丰富,不需要进行稀疏词汇共现的T检验。
文献[6]在维汉语料库中先确定锚点,即可信度较高的1: 1对齐的句对;在锚点之间根据句子长度使用动态规划方法对齐句子。锚点句的评价使用三个指标: ①句长对应关系②关键词词典及标点匹配程度③位图斜率(Bitext map slope)和最小二乘斜率(least squares line)夹角。其中关键词由2 000个双语常见词和高频技术术语构成;锚点的中维句子标号形成了文本图中的一个点的纵横坐标,若干锚点的拟合斜率与所有句子的位图斜率夹角反映了锚点斜率与整体句子标号斜率的偏离程度;Samat对维汉句子长度的衡量标准进行了研究,表明维文以词为单位,中文以字符为单位计算,得到的方差最小,而且相关系数最大(0.977)。在十篇文本中评价达到94.6%的准确率和94.8%的召回率。
文献[2]的方法与Samat的步骤基本类似,不同点有二: 一是用双语词汇共现概率(用五万个平行句对统计)计算词汇互译率;二是用中文句相对编号和维文句相对编号的差代替Samat的斜率夹角,两人的做法其实都反映了锚点句子在整个句子序列中的位置偏差。在四篇人工对齐的语料中,平均达到97.6%的准确率和98.2%的召回率。
双语新闻中人名地名是重要的新闻要素,但是人名和地名一般属未登录词,无法直接匹配。
词汇共现概率需要在大规模双语句对中统计,在新的规模较小的可比语料库中,用语变化及数据稀疏问题导致词汇共现信息很难得到。
3 句子对齐的特征选择
句子特征可以分为外部特征和内部特征。外部特征在本文中指句子的整体特征(包含句子长度、句子编号);句子的内部特征指该句子内部的局部特征(如词汇、数字、标点等)。在打乱句子编号的情况下,维文句子u和中文句子c的对齐主要依赖句子内容的互译程度和句子长度的匹配程度。本文使用的句子内部特征有人名地名、数字、词典词和标点。
3.1 双语人名地名特征
人名地名构成了新闻的主要因素,是双语句子对齐的重要特征。但是人名地名多为未登录词,无法用双语词典互译匹配。经分析,维汉双语新闻中出现的人名地名大多为汉族维族人名和中国地名,小部分为外国人名地名。作者借助ICTCLAS抽取中文专名(“/nr”为人名,“/ns”为地名),使用改进的转写翻译方法获得维文译名,建立人名地名的映射关系并合并到双语词典,间接实现了人名和地名的互译匹配。
3.1.1 汉字到维文的直译方法
文献[6]提出了一种将中文专名自动翻译为维文的方法。主要基于汉语拼音声母韵母与维文音节的映射规则。文献[7]翻译维文中的汉族人名也是基于这样的映射规则。经过对比实验,发现李佳正使用的声母韵母与维文音节映射表中,存在非法分解(如chuang被错误分解为ch uan g)和多样转写(如汉语的u对应维文u或者ü等)问题,对现有数据的统计结果表明,仅仅u字母的1对2映射就造成了51个拼音的混乱。
为此,作者将全部27 803个汉字归结为402个普通话标准音(姓氏汉字中的多音字不计声调变化共有39个,按姓氏规范确定其正确读音),将汉字标准音映射为维文,避免非法分解转写造成的错误,提高维文人名地名识别的准确率。
对于音节的多个合法转写造成的多样性,在402个标准音的基础上请维语专家人工审定,剔除那些音节合法但是整字组合后非法的转写,在后续处理的时候枚举所有合法多样拼写,提高召回率(查全率)。
最终构建的汉字整字标准音与拉丁维文映射表去除了很多非标准音biang,chua,并增补一些汉字的兼容拼音如nve(虐nue)等,共402行,表1给出了表格的一部分。
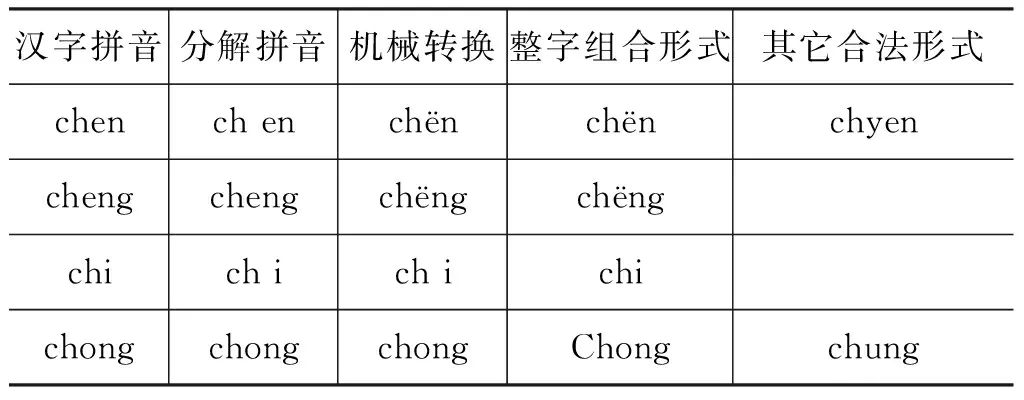
表1 汉字拼音转写拉丁维文的映射表
3.1.2 汉族人名的直译转写
文献[7]从维文到汉族人名的翻译方法存在不确定性,一个人名拼音对应的多个中文人名只能通过概率计算,得到最可能的中文名。作者基于中文人名的汉字拼音,按照确定的规则获取维文人名,避免了概率计算可能带来的错误。
例如,中文人名“俞正声”转换为唯一的汉语拼音形式“yu zheng sheng”,按规则翻译为两个合法维文译名“yü j⊇ngshen”及“yü j⊇ngsheng”。人名字典添加
中文人名要在篇章范围构建,这样可以避免同一个人名在不同句子中ICTCLAS分词结果不一致的情况。例如:
例句1 “上海市委/nt书记/n 俞/nr1 正/d 声/ng接受/v 新华社/nt记者/n 的/ude1 专访/vn。/wj”
例句2 “俞正声/nr 表示/v …”
在例句1中的人名“俞正声”被错误切分为“俞/nr1 正/d 声/ng”,例句2切分正确“俞正声/nr”。在篇章范围内可正确抽取“俞正声”(根据“/nr”标记)并获得两个合法维文译名“yü j⊇ngshen”和“yü j⊇ngsheng”。
随后的匹配过程(详见3.3节)维文切分采用正向最大匹配的方式,可以找到“yü j⊇ngshen”或者“yü j⊇ngsheng”,查找词典后得到“俞正声”。然后用“俞正声”作为模式串在未分词的中文原句中进行串匹配,在中文句子1的原句中可匹配到正确结果“俞正声”。
也就是说,中文名字只要有一次是正确标注的,词典中就加入了正确的条目,随后进行的中文串匹配对所有中文句进行,从而可排除错误的切分。
3.1.3 中国内地地名的转写
在地名转写时需要剥离地名单位(省市县区路等),再查看抽取的地名是否为新地名。具体可以分三种情形。
(1) 中文地名和维文译名都是未登录词,添加词典条目。如“苏州路”抽出“苏州”,维文译名“suju”都是未登录词,直接将
(2) 中文地名和维文译名都是已登录词,忽略该地名。如“山东省”抽出“山东”后发现中文词“山东”已经存在于双语词典,见“shendung山东”。
(3) 中文地名是未登录词,但维文译名已登录,将中文地名添加为词典已登录维文词的中文义项。如中文地名“河北”是未登录词,但是转写的维文译名"x⊇b⊇y"已经在词典里(中文义项为“北洋”),现在,需在词典中"x⊇b⊇y"条目的中文释义中添加“河北”,变更为“x⊇b⊇y北洋;河北”。
获得汉族人名和中国内地地名的维文中映射关系后,加上双语词典本身就涵盖的8 227个维吾尔人名和943个新疆地名,可以解决大部分未登录词的双语匹配问题。外国人名和地名由于出现概率极小,并且构造双语译名时错误率偏高,作者未做专门处理。
经过对449个中文人名地名及其维文译名的人工检验,正确翻译为442个,错误的情形包括中文人名识别错误(如: 陈壮/nr 为/p 同志/n)及翻译错误(如大西沟翻译为da shigow,真实译名为dashi gu)。正确率达到了98.4%。实际上不计重复出现的双语人名地名数量为482,一些汉族人名被识别为外国人名(如马伊磊/nrf 同志)而未纳入词典。因此,构造的人名地名词典的覆盖度为93.1%。
3.2 数字特征的抽取与匹配
数字是一种明显的特征,双语句子出现的数字序列,相对顺序基本上一致,可以认为是两个向量,在句子匹配中区分作用明显。
维汉数字特征的抽取要注意如下问题。
(1) 复合数字,如维文数字“13milyon 600ming 800”对应中文的一千三百六十万零八百,分别转写为136000800。
(2) 非阿拉伯形式的数字存在歧义,如bir,在bir milyon 470ming(一百四十七万)中是数字,在bir gewdileshtürüsh是一体化。作者简单认为四个数量词tirliyon(万亿)、milyard(十亿)、milyon(百万)、ming(千)前出现的维文数字为真实数字。
(3) 时间写法,19∶20与晚上7∶20统一成一种写法。
计算数字特征的相似度时,为防止数字抽取错误引起的数字缺失和顺序错乱,没有按照向量的余弦距离或者相关系数计算,而是采用式(1)。其中δ为克罗内克符号,#cnNum表示中文句子的数字总个数,#uyNum为维文句子的数字总个数。
(1)
3.3 双语词汇特征及匹配方法
本文中词汇泛指单词和短语。作者使用的双语词典Anatilim Uyghur Chinese dictionary (Uyghur Latin Writing Edition)有385 486条目,其中两万个不连续短语直接丢弃,如“meyli … bolsun也好;也罢”。剩余363 037条目,其中57 274个是维文单词,305 763个是短语(以空格隔开的两个以上的单词)。
为充分利用长词的区分能力,作者将维文短语、单词、标点以及前面得到的维文译名一起作为维文句子切分的“广义词表”,对维文句子进行正向最大匹配切分。去除后缀得到维文词汇特征,然后查询双语词典后得到中文词汇,用中文词汇在中文句子中进行串匹配。
3.3.1 维文短语切分和单词形态还原
将维文句子切分后,如果切分单位内含有空格,表明该单元是短语,可以直接作为维文短语特征,丢弃其后的词缀。因为短语已经含有空格,作者将所有切分单元用{}括起来。如 {xelq sariyi}{da},其中的“xelq sariyi”意思为“人民大会堂”,“da”是表示时空的“位格”。反之,如果切分单位内无空格,说明该切分单位是某个单词的词现(token),需要进行词干还原。如维文原token“mesililer”被切成“{mes}{ili}{ler}”,就要将后缀"ler"去掉,处理变音后还原为“mesile”(“mesile”意思是“问题”,“mes”意为“商”)。
词干还原涉及复杂的变音(增减变),尤其是动词的末尾可能有3~4个字母与词干不同。词的前缀共有六个,后缀532个[8]。
作者基于词干表stemWordList(57 274项)和词缀表suffixList(429项),采用规则方法进行名词的词干还原。
3.3.2 词典词匹配方法
维文双语词典中的中文词,与中文句子分词得到的中文词差别很大。无论是机械分词方法(词表为双语词典中的所有中文词)还是统计分词方法都有问题,主要表现为:
(1) 词表分词的过切分问题
如中文“市政协副主席”切分为{市政}{协}{副主席},不管文本分词方向是正向还是逆向,匹配原则是最小匹配还是最大匹配还是全切分匹配,机械分词方法都很难避免这样的越界问题。
(2) ICTCLAS分词与双语词典的中文词不一致问题
中文机构团体被ICTCLAS标记为(/nt),从中文角度看比较合理,但是与词典词相比粒度有些过大。例如,“任命/v 赵宇澄/nr 同志/n 为/p 乌鲁木齐市文化局/nt…”,其中“乌鲁木齐市文化局”无法在词典中进行匹配。
为避免分词方法造成的错误,提高互译词的匹配成功率,作者把中文句子作为模式匹配的主串,把维文词的中文译词作为模式串,进行串匹配操作。
维文词uyTerm在双语词典中查询的结果可能是一个中文词(单义项,记作cnSense),也可能是多个中文词(多义项)。多个义项依次在中文句中扫描,一旦匹配,后面义项就忽略,认为该义项与维文词汇uyTerm配对。句子中所有的匹配词汇按照公式(2)计算广义词义匹配度。其中len(uyTermi)与len(cnSensei)为互译的维文词长度和中文词长度。
simT(Us,Cs)=
(2)
3.4 双语句子长度特征
考虑到维文词典中存在大量的短语,切分出的词长悬殊较大,因而词个数也不一致,作者统一采用unicode字符作为句子的长度单位。参考Gale[3]和文献[2]中双语句子长度关系的分析,作者定义δ如式(3)所示。其中len(Us)为维文句子长度,len(Cs)为中文句子长度。
(3)
δ为关于双语句子长度的标准化变量,c是每个中文字对应维文字符数的期望值,通过计算维中句子长度比值的平均值得到;之后根据c计算(len(Us)-c*len(Cs))2/len(Cs)的均值,得到统计方差σ2。本文取c=4.541 337 144 858 13,σ2=26.667 909 114 906 5。
正态分布是连续变量的理论分布,δ=δi的概率只能通过累积某一区间内的概率密度得到。约定累积分布函数如式(4)所示。
(4)
对给定的维汉句子u和c,变量δ取定值δi,句子长度的匹配概率simL(u,c)有两种计算方法。Gale在[-∞,-|δi|]和[|δi|,+∞]区间内累积δ的概率,即
Pr(|δ|>δi)=2(1-F(|δi|)),王斌[10]在[δi-Δ, δi+Δ]区间内累积概率,如式(5)所示。
(5)
作者通过实验表明,王斌的方法比Gale的方法在匹配正确率稍高(约1.3%),因此,采用了式(5)计算句子长度匹配度simL,即
(6)
4 基于二部图匹配的维汉平行句对挖掘
提取了维文句子和中文句子的各种特征后,可以通过多特征融合的方式计算维汉句对的相似度。多个维文句子与多个中文句子两两之间的相似度构成一个矩阵,基于相似度矩阵可以采用二部图匹配的方法挖掘平行句对。
4.1 多特征融合的双语句对相似度计算
维文句子U和中文句子C的内容相似度sim0可以用式(7)计算,其中词义匹配度simT(泛指人名地名、标点和词汇匹配度)与数字特征匹配度simD分别在式(1)、公式(2)中定义。作者在区间[0.05,0.95]内以0.05的间隔试探λ,将其确定为0.85。
sim0(us,cs)=λ·simT(us,cs)+
(7)
很明显,如果维文句子Us和中文句子Cs配对,那么len(Us)-c*len(Cs)≈0,δ≈0;从而simL(Us,Cs)也较大,以句子长度衡量匹配度较大。但是反过来,两个句子的长度即使满足δ=0,也不能说两个句子就是配对的(因为内容可能完全不同)。可见句子长度匹配度simL只是一个必要非充分条件。这样的条件一般用于惩罚原相似度sim0。为此作者修正句子相似度为式(8)。
(8)
式(8)中,sim0为浮点数,当δ=0时,sim0不受惩罚;δ偏离0越远,sim0惩罚越大。α取经验值0.3,可以让δ≠0的句对相似度的惩罚得到适当松弛。
维文句子i和中文句子j的相似度计算过程如图1所示。
m个维文句子和n个中文句子两两之间可计算m×n个相似度,每个相似度为[0,1]区间内的浮点数,所有的相似度构成一个m×n的权值矩阵。
4.2 二部图构建
如果将m个维文句子看作二部图的一组顶点,将n个中文句子看作二部图的另一组顶点,将相似度矩阵中不为零的元素看作二部图的边,边的取值范围是(0,1]。则本文关注的句子对齐问题(平行句对挖掘)就转化为二部图的最佳匹配问题,定义如下。
定义: 二部图最佳匹配
带权二部图G=(V,W)的每条边都有一个非负权值(以邻接矩阵W表示),顶点集合V=L∪R,约定|L|≤|R|,要求一种完备匹配方案,使得L中的顶点都被匹配而且匹配边的权和最大,记做最大权匹配(maximum weight matching in bipartite graph),也称最优完备匹配或者最佳匹配。R中没有匹配的点,称为未覆盖点。
4.3 平行句对挖掘算法
为从双语句子集合构成的二部图中挖掘平行句对,作者采用了三种图匹配算法,即顶点优先的贪婪算法、权值优先的贪婪算法、二部图最大权匹配算法。
(1) 顶点优先的贪婪算法
为计算完备匹配,一种策略是从顶点x∈L出发,在其相邻的未覆盖顶点中,挑选边权最大的顶点y∈R,
容易理解,维汉句子数分别为m和n时,算法时间复杂度为O(m*n)。算法匹配结果与顶点x的取出顺序有关,经过实验比较,随机取x比按照固定顺序(从1到m)的匹配准确率高20%左右。另外该算法做法是贪心的,不能保证权值之和最大,只能保证完备匹配。
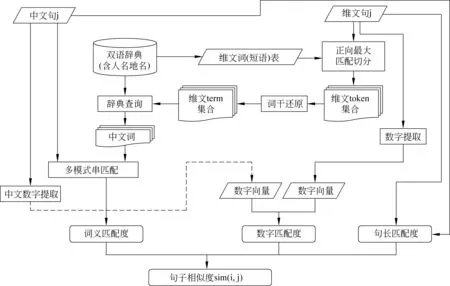
图1 双语句子相似度的计算流程图
(2) 权值优先的贪婪算法
另一种策略是从权值大的边开始,如果该边的两个顶点都是未配点,则该边加入匹配,否则丢弃。依次处理直到没有可用边或者没有可用顶点。
设图中有e条边,该算法的时间复杂度为O(eloge),即算法的主要运算为边的排序操作。在完全图(满边)情况下,e=m*n,算法复杂度退化为O(m*n*log(m*n))。如果在计算边权时按照阈值滤除较小的权值,将边的数量减少,会提高算法速度,但是有可能导致不完备匹配。该算法也是贪心的,不能保证匹配边的权和最大。
(3) 二部图最大权匹配算法(KM算法)
二部图最佳匹配的KM经典算法由Kuhn和Munkras在1957年提出,时间复杂度为O(n3),n为顶点个数。该算法最新的实现[9]在受限条件下的时间复杂度降低到O(m*sqrt(n)*logN),条件是权值只能取区间[1,N]内的整数。
因为作者构建的二部图中边的权值是浮点数,所以使用了原始KM算法的一个实现型,时间复杂度为O(m2*n),m,n分别为左右两部分顶点的个数。
与前面的贪婪算法相比,KM算法在按照确定的顺序,不断扩展相等子图中的匹配边,达到完备匹配时就能保证总体权和最大。
4.4 实验结果
目前可共享的维汉对齐语料集几乎没有,本文使用的实验数据为维语专家人工对齐的无重复的900个中文句和900个对应维文句(来自不同的互联网新闻文章)。
4.4.1 特征有效性检验
为了检验不同特征对平行句对挖掘的作用,首先使用词典词作为唯一匹配特征,在900个维文句子和900个中文句子的相似度矩阵中,使用KM算法,得到正确句珠781个(句珠总数为900个),正确率为86.78%。在此基础上逐步增加其他特征,包括人名地名、数字特征、句子长度等,最后融合所有的句子特征进行对齐实验。结果如图2所示。
从图2可以看出,融合人名地名特征后,正确率上升到87.11%,再融合数字特征后,正确率有了较大的提升,达到93.78%。这一点在三种算法的结果中都得到验证。最后融合长度特征后,顶点优先匹配算法的正确率出现轻微下降(从70.33%到67.78%),而权值优先匹配算法和KM算法的正确率仍有提高。说明句子长度特征有时会干扰句子对齐,尤其在对齐大规模无序句子时,不宜将其作为主要特征。
结果表明,词典词、人名地名、数字和句子长度特征的融合有效增加了句子对齐的正确率。

图2 特征选择在平行句对挖掘中的效果
4.4.2 算法比较
为比较三种算法的对齐效果,分别用100对句子,200对直至900对句子进行验证。实验结果如图3所示。
从图3中可以看出,句子集合的规模增加后,一个原文句子对应的候选句子变多,对齐算法的准确率有所下降。但是三种算法的表现不同: KM算法对所有句子的配对反复调整,进行全局优化,确实做到了最佳匹配。而权值优先算法只按照句子相似度进行贪婪匹配,在句子数少于300时,准确率与KM差距很小,句子规模超过300时,有大约5%的下降。表明句子相似度本身是对齐的基础因素,而全局的优化调整能进一步提高对齐正确率。而顶点优先算法的准确率整体上比较低。在句子规模超过300后,匹配正确率下降较快,而且曲线不单调(从88%下降到68.86%再回升到70.44%)。说明该算法不稳定,对句子规模比较敏感。原因是一旦某个顶点(原文句)选择了错误的对应顶点(译文句),必然要影响其他顶点的匹配,造成错误的蔓延。
随着句子规模的增大,权值优先匹配算法和KM算法鲁棒地保持了较高的准确率。说明这两种算法的泛化能力较强。

图3 三种算法在维中文句子上的匹配准确率
4.4.3 句子数量不均衡情形下的双语句子对齐
真实语料中往往存在无法找到匹配句的情况,因而不是严格意义上的1: 1对齐。为了检验这种情况的影响,我们构建了不均衡语料。先使用100个维文句与不同数量的中文句子(从100到900)进行对齐测试,结果如图4中深色柱状图所示;然后用100个中文句与不同数量的维文句进行对齐测试,结果如图4中浅色柱状图所示。测试结果的召回率和准确率相等,分子是正确匹配的句对数,分母是中文句子数量和维文句子数量的较小值。
从图4中可以看出,随着双语句子数量差异的增大,对齐效果逐渐变差,这表明均衡语料的对齐效果要优于偏斜语料。而图4中每一组深色柱状图均高于浅色柱状图,即中文句子较多时,对齐的效果好于维文句子较多的情形,这说明维文句子更适合作为对齐的基准。
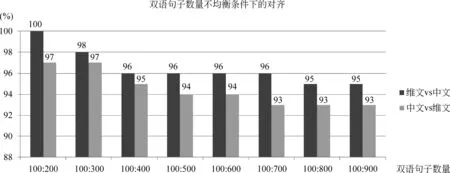
图4 KM算法在维中文句子数量不均衡时的对齐准确率
4.4.4 包含一对多对齐情形的双语句子
真实双语网页文本中的句子数量从几十句到几百句不等。其中对齐模式1∶0或者0∶1的孤立句子无法匹配, 对齐模式为1对多的对齐只抽取其中
最大匹配部分,输出为1∶1模式的假平行句对,剩余部分作为孤立句子丢弃。为考察算法在这种情况下的效果,作者搜集了30篇不同时期的双语新闻网页,分段分句后进行测试。表2给出了表格的一部分。
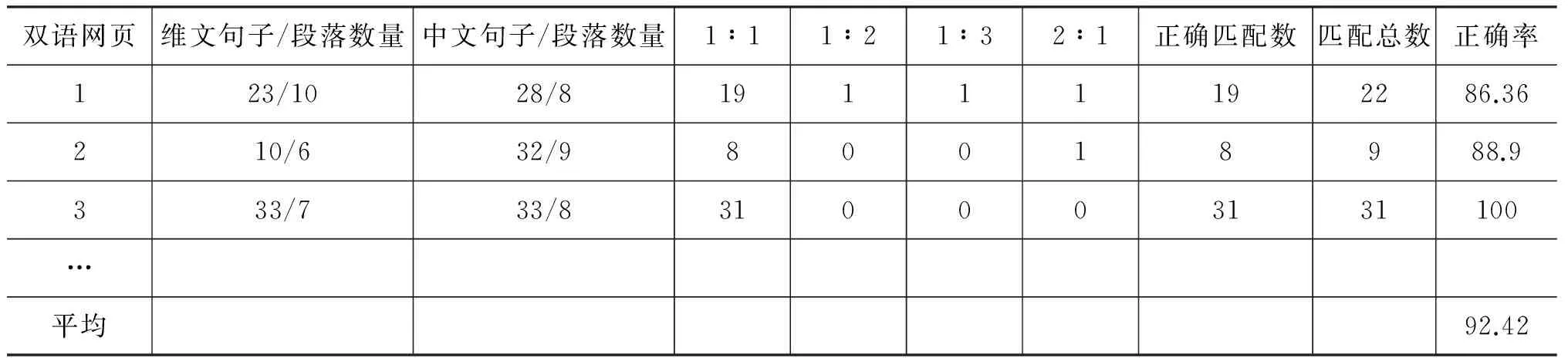
表2 句子缺失和部分匹配情形下的对齐准确率
从表2中看出,所有1∶1模式的句珠几乎都能正确找到;而1∶2,2∶2和1∶3模式的句珠只能得到部分匹配,这样匹配结果并非完全错误,而是近似匹配,但是在统计正确率时都认为是错误的。
5 总结与下一步工作
本文提出了一种基于多特征融合的双语句子相似度计算方法,在此基础上利用二部图匹配算法实现非连续双语文本的平行句对挖掘。先在篇章层面利用ICTCLAS获得中文人名地名,然后按规则转写对应的维文译名,解决了大部分未登录词的互译匹配,又在句子层面用串匹配方法避免了中文分词的歧义问题。然后在句对相似度矩阵上,使用二部图的最佳匹配(KM算法)得到句珠,在900个句对的测试中,达到95.67%的准确率。在实验中发现,维汉法律文件和政府工作报告等正式文本的句子对齐正确率接近100%。而多处省略了大段中文句子的双语新闻句子对齐正确率稍低(86.36%),该情形并不适合采用动态规划算法处理。
经统计每个维文句子中平均有五个单词需要进行词干还原。作者仅仅根据规则进行词干还原,发现正确率几乎没有变化(从95.33%提高到95.67%),说明词干还原的方法需要深入研究。
[1] Pascale Fung, Percy Cheung. Multi-level Bootstrapping for Extracting Parallel Sentences from a Quasi-Comparable Corpus[C]//Proceedings of the 20th international conference on Computational,2004.
[2] 田生伟,吐尔根·伊布拉音,禹龙,等.与策略汉维句子对齐[J].计算机科学,2010,37(4):215-218.
[3] William A Gale,Kenneth W Church. A program for aligning sentences in bilingual corpora[C]//Proceedings of the ACL-91.
[4] Dekai Wu. Aligning a parallel English-Chinese corpus statistically with lexical criteria[C]//Proceedings of the 32nd annual meeting of the association for computational linguistics, Las cruces, New Mexico.
[5] 吴宏林,刘绍明,于戈.基于加权二部图的汉日词对齐[J],中文信息学报,2011,21(5): 101-106.
[6] Samat mamitimin, Min Hou. Chinese-Uyghur Sentence Alignment: An approach Based on Anchor Sentences[C]//Proceedings of the 2ndWorkshop on Building and Using Comparable Corpora, ACL-IJCNLP 2009.
[7] 李佳正,刘凯,麦热哈巴·艾力,等. 维吾尔语中汉族人名的识别及翻译[J],中文信息学报,2011,25(4): 82-87.
[8] Batuer Aisha, Maosong Sun. A Statistical Method for Uyghur Tokenization[C]//Proceedings of the Natural Language Processing and Knowledge Engineering, 2009.
[9] Ran Duan, Hsin-Hao Su. A Scaling Algorithm for Maximum Weight Matching inBipartite Graphs[C]//Proceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms,2012.
[10] 王斌. 汉英双语语料库自动对齐研究[D]. 中国科学院计算技术研究所博士学位论文,2000.
[11] 塞麦提·麦麦提敏,亚森·伊明. 基于转换规则的汉文-维文专有名词自动翻译研究[C].第七届中文信息处理国际会议,2007.
Uyghur Chinese Sentence Alignment Based on Multi Features and Optimal Matching
Ni Yaoqun1,2,3, Xu Hongbo1, Cheng Xueqi1
(1. CAS Key Laboratory of Network Data Science & Technology, Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100190, China;2. Department of Language Engineering, University of Chinese Academy of Sciences,Beijing 100049, China;3. Department of Language Engineering, University of Foreign Languages, Luoyang, Henan 471003, China)
The content of Uyghur webpage news is usually partial comparable with the content of the Chinese counterpart. Uyghur sentence sequences may be shuffled or even partially missing in Chinese text, which cause some difficulties in mining parallel sentences (i.e. sentence bead) from bilingual news. Fist, to improve the word matching rate of this kind, person and location names in Chinese are extracted and translated into Uyghur to enhance bilingual mapping. Then we scan the Chinese sentences with translation of Uighur words and calculate the translation rate via string matching to avoid mistakes in Chinese word segmentation. The final similarity of a sentence pair is calculated by combining the word translation rate with the numbers, punctuations and length of sentences as features. Similarities of all the bilingual sentence pairs constructed a weight matrix. We used greedy algorithm and maximum weight matching algorithm in bipartite graph to find the parallel sentence pairs with highest probability. Our method achieves an accuracy of 95.67% in sentence alignment.
sentence alignment; translation of human name and location name; multiple features blending; maximum weight matching in bipartite graph

倪耀群(1974—),博士,讲师,主要研究领域为自然语言处理、数据挖掘等。E-mail:niyaoqun@126.com许洪波(1975—),博士,副研究员,主要研究领域为互联网搜索与挖掘、大数据分析与计算、自然语言处理等。E-mail:hbxu@ict.ac.cn程学旗(1971—),博士,研究员,主要研究领域为互联网搜索与挖掘、网络科学与社会计算、网络与信息安全等。E-mail:cxq@ict.ac.cn
1003-0077(2016)04-0124-10
2014-10-09 定稿日期: 2015-03-15
国家自然科学基金(61232010,61303156);国家973课题(2012CB316303);国家863课题(2012AA011003);国家科技支撑计划(2012BAH46B04)
TP391
A
