基于主题模型的通信网络建模与仿真
2016-04-28李全刚秦志光
李全刚 刘 峤 秦志光
(电子科技大学计算机科学与工程学院 成都 610054)
(quangang.l@163.com)
基于主题模型的通信网络建模与仿真
李全刚刘峤秦志光
(电子科技大学计算机科学与工程学院成都610054)
(quangang.l@163.com)
Modeling and Simulation of Communication Network Based on Topic Model
Li Quangang, Liu Qiao, and Qin Zhiguang
(SchoolofComputerScience&Engineering,UniversityofElectronicScienceandTechnologyofChina,Chengdu610054)
AbstractUnderstanding how communication networks form and evolve is a crucial research issue in complex network analysis. Various methods are proposed to explore networks generation and evolution mechanism. However, the previous methods usually pay more attention to macroscopic characteristics rather than microscopic characteristics, which may lead to lose much information of individual patterns. Since communication network is associated closely with user behaviours, the model of communication network also takes into consideration the individual patterns. By implicitly labeling each network node with a latent attribute-activity level, we introduce an efficent approach for the simulation and modeling of communication network based on topic model. We illustrate our model on a real-world email network obtained from email logs. Experimental results show that the synthetic network preserves some of the global characteristics and individual behaviour patterns. Besides, due to privacy policy and restricted permissions, it is arduous to collect a real large-scale communication network dataset in a short time. Much research work is constrained by the absence of real large-scale datasets. To address this problem, we can use this model to generate a large-scale synthetic communication network by a small amount of captured communication stream. Moreover, it has linear runtime complexity and can be paralleled easily.
Key wordscommunication network; generative model; simulation; complex network; communication stream
摘要探知通信网络的形成和演化机制是复杂网络领域中一个重要的研究点.众多研究者也提出了许多关于探索通信网络形成及演化机制的方法.现有的网络模拟方法主要着眼于网络的宏观特征而忽视了微观特征,导致个体用户模式的信息丢失.既然通信网络是与使用者的行为紧密相关的,那么构建模型时单用户的模式也应当被考虑进来.通过对网络中每个节点标注一个隐含属性——活跃度,提出一种基于主题模型的通信网络高效模拟生成方法.在真实邮件网络数据集上的实验结果验证了提出的方法能够很好地模拟原网络的整体特征和个体用户的行为模式.此外,由于隐私策略和访问权限的限制,对于大多数研究者而言,短时间内采集大规模的真实通信网络数据是十分困难的.许多研究工作因缺乏实验数据而受到制约,应对这个问题,可以使用该算法借助少量已有的通信数据流来生成大规模的模拟数据.该算法具有线性时间复杂度并且可以方便地并行化处理.
关键词通信网络;生成模型;模拟;复杂网络;通信流
在现代生活中,随着互联网技术的发展和移动终端设备的普及,人们使用邮件、电话、即时通信软件等各种通信方式进行信息交流也变得越来越普遍.人们使用各种个人通信服务中产生的通信记录所构成的网络通常称为通信网络,比如电子邮件网络、即时通信网络、移动电话网络、手机短信网络等.这类通信网络包含了人们的社交关系、日常作息时间、工作生活习惯、工作性质等诸多十分有价值的信息.近年来,面向通信网络的应用研究引起了学者们的广泛关注,产生了许多十分有意义的研究工作,例如用户行为模式挖掘[1]、社团发现[2-3]、社交关系推断[4-5]、事件检测[3,6-7]等.
由于通信网络通常具有规模大、时变性强的特点,许多面向通信网络的应用研究需要以一定规模的实验数据作为研究基础.现实中的通信网络本身规模可能十分庞大,例如一个大型企业的邮件系统可能包含上万节点,每天产生大量的邮件通信记录.另外通信网络是典型的时变性网络,网络结构是随着时间不断变化的,不同时刻对网络进行采样会得到不同的网络拓扑镜像.目前基于大数据的应用技术研究正如火如荼地开展,在面向通信网络的应用技术研究中诸如系统设计调试、算法效率优化等工作也需要有大规模的实验数据做支持.
用户个人隐私、系统管理权限、数据采集的时间成本等诸多限制,使得获取大规模的真实通信网络数据对于大多数的研究者而言十分困难.虽然通信网络在日常生活中随处可见,但是可供研究者使用的大规模公开的真实数据非常缺乏.不同于分享式的社交网络数据,研究者可以通过网络爬取的方法来采集实验数据,而通信网络所产生的记录信息涉及到个人的隐私,通常是仅对通信双方公开可见,其他人是无法获知的.要想获得真实的实验数据就仅能在提供通信服务的服务器上部署采集程序,除却系统权限获取、隐私保护问题之外,要采集大时间跨度的数据其中的时间成本也是一个不可避免的问题.
如何获取大规模的实验数据成为开展后续应用研究的首要瓶颈.为了应对这个问题,通常会构建通信网络的生成模型,然后利用计算机模拟的方法来生成模拟实验数据.通信网络可以视为复杂网络的一种,经典的复杂网络生成模型如ER随机网络模型[8]、WS小世界网络模型[9]、BA无标度网络模型[10]等,主要从网络拓扑结构层面来描述网络的形成和演化特征并模拟真实网络的一些重要拓扑结构特性,如连通性、小世界性及节点度的幂率分布特性等.这类普适的网络生成模型大多不需要真实网络数据作为训练数据集,模拟效果主要依赖于选取合适的模型参数,而参数的选取很难有明确的限定.这类模型的主要目的是揭示一些重要网络拓扑特征的产生机制,仅能从宏观层面对网络某些全局特征进行模拟,不能很好地保留个体用户的特征,其生成的模拟数据与真实数据相比信息丢失比较严重,不适合用来作为实验数据的生成器.
面向通信网络的生成模型要求尽可能多地保留原始网络特征之外还要有一定的泛化能力.多数面向应用的研究依赖于对应场景的真实通信网络数据,然而各种通信方式下用户群体以及运行模式的差异决定了不同类型通信网络具有各自的网络特征及个体差异.不同类型的通信网络间的差异性不可忽略,例如面向邮件网络的应用技术研究一般不能使用移动手机网络的数据来替代,而即使同样是邮件网络,不同的组织也会有不一样的网络结构及特性.
基于以上分析本文重点考虑如下问题:假设已获取一定数量的通信网络数据,如何利用这些数据来构建一个能够合理地解释通信网络生成机制的模型并利用该模型快速生成大规模的模拟数据,并且保证生成的模拟数据可以很好地保留原来的网络拓扑结构以及个体用户的通信行为特征.电子邮件网络是通信网络的代表性网络之一,本文以某单位内部人员间真实邮件通信网络为例,详细描述了通信网络生成模型的参数学习和模拟效果.本文的贡献主要体现在:
1) 通过引入用户活跃度的概念构建了一种通信网络的生成模型.该模型首先模拟了网络中各等级活跃度用户的分布,然后从用户角度描述了通信的发生过程,模拟结果兼顾了网络整体和用户个体2方面的特征,有着较为合理的解释性,有助于理解通信网络的产生和演化机制.
2) 在真实邮件数据集上进行实验并验证了该模型可用于快速生成大规模的模拟通信网络数据,同时能保证生成的模拟通信网络既能体现通信网络的宏观特征又可以保留个体用户的特征.模型的生成过程具有线性时间复杂度并且能方便地进行分布式及并行化处理.
3) 该模型有良好的可扩展性.模型训练完成后可以方便地通过修正模型的参数来生成不同情景下的模拟通信网络数据.比如设置定期删除和添加一些节点或者改变一些节点的活跃度便可生成一个具有动态演化特征的通信网络.
1相关工作
面向通信网络的生成模型研究已有很多研究成果,可大致按是否需要训练集而分成2类:1)不需要训练集的模型.该模型是构建某种数学迭代机制,通过对初始参数的调节来生成符合真实网络某些特征的模拟网络.但是这类模型有着局限性,例如网络的结构特性是十分复杂的,很多新的特征还在不断地被发现,而通过构建数学机制来模拟网络的特征往往只考虑到一个或几个已知的特征,无法对未知的特征进行有效的拟合,很多网络特性很难通过单一的数学公式来模拟产生.2)需要训练集的网络模型.该模型可以依据训练集来获取更丰富的信息,对于不同类型的通信网络更加有针对性,能够更好地对网络的局部信息进行拟合.

概括地讲,上述这些模型更加关注生成的网络是否符合已知的网络性质,比如是否服从度的幂率分布、较小的网络直径等.模拟网络的生成过程不需要训练集的参与,仅需要设置参数然后不断迭代来生成最终的网络.这类模拟方法没有考察通信发生的时间,其中矩阵迭代的方式生成模拟网络会丢失网络中的节点标签信息,使得模拟网络与真实网络只能在网络宏观拓扑结构上保证是属于同一类型的网络,但无法判定模拟网络中通信双方的身份,这会对后续工作造成极大的不利影响.
此外,Budka等人[15]提出一种用于模拟动态社交网络演化的分子模型(molecular model).该模型首先将邮件网络按照固定的时间间隔划分成快照,每个快照就代表邮件网络在该时间间隔内的一个影像;然后定义2节点间的距离函数,计算快照的距离矩阵;再将距离矩阵嵌入到一个高维欧几里德空间,网络中的节点就映射为欧几里德空间中的点,通过分子动力学方法不断迭代寻找网络稳定状态;最后利用网络的稳定状态重构出新的邮件网络.对邮件网络数据的实验表明重构得到的邮件网络可以保持原网络的整体特性,但会丢失网络的局部特征,如个体的行为特性等.McCallum等人[16]提出的ART(author recipient topic) 模型同时对邮件的内容和通信关系进行了模拟.ART模型假设已知某封邮件的发信者s和其联系人集合,先从联系人集合中随机挑选一位接收者r,这样就生成一个通信关系(s,r),再通过自然语言处理中的主题模型来生成邮件的内容.但ART模型中假设发信者与每位接收者的通信概率是均匀的,而现实中某发信者与其联系人的通信概率通常是不均匀的,应当考虑到这一点.
以上2种方法都需要借助训练集的数据来计算快照距离矩阵或获取某用户的联系人列表,在对真实网络特征的拟合上有着较好的效果,但他们没有很好地描述个体用户的真实行为特征以及通信时间规律.
综上所述,许多关于网络模拟的方法通常都是关注对网络的整体特性,而没有兼顾到个体用户的特性也没有对时间因素进行模拟,而通信发生的时间也是用户行为模式研究中十分重要的特征.此外有些模型需要复杂的矩阵迭代计算,运算效率较低,同样不适合用于快速生成大规模的模拟网络数据.
2通信网络生成模型
如果把通信过程中的通信双方作为节点,有向边表示信息的传递方向,发信者a在时刻t给接收者b发送了一条消息,则他们之间就产生了一条通信记录(a,b:t).本质上讲,通信网络就是由一条条通信记录所构成的通信流.如果将通信网络按照某固定的时间间隔来划分便可得到一系列的通信网络快照{g1,g2,…,gm,…},每个快照包含了在该时间跨度内所产生的所有通信记录.本文假设每个快照之间以及快照内每条记录之间都是不相关的.
假设已经获得了一些通信网络快照,本节下文详细描述如何构建通信网络的生成模型并利用这些网络快照来快速生成大规模的模拟网络快照.
2.1基本思路
主题模型(topicmodel)是自然语言处理领域中应用极广的一种文档主题挖掘方法.它引入了主题这一潜在变量,将每篇文档视为若干主题的混合分布,而每个主题又可视为关于单词的概率分布.最具代表性的主题模型就是LDA模型[17](latentDirichletallocation),它在“文档-主题”这层结构中引入先验Dirichlet分布,这样就构成了一个“文档-主题-单词”的3层贝叶斯概率模型.主题模型对于每篇文档生成过程解释为先从该文档的主题分布中抽取一个主题,然后从该主题对应的单词分布中抽取一个单词,整个过程重复R次即得到一篇含有R个单词的文档.在LDA模型的基础上,学者们进行了深入地研究,相继提出了许多改进的主题挖掘模型,如DTM[18](dynamictopicmodels),MB-LDA[19]等.
鉴于主题模型的思想,本文在通信网络中引入了用户活跃度的概念,将通信网络的生成过程描述为“快照-用户活跃度-通信记录”的3层贝叶斯网络,其中通信记录又包含了发送者、接收者、时间戳3个元素,利用训练集数据计算模型参数,然后依次生成多个模拟通信网络快照.本文假设通信网络快照是由一些彼此无关的通信记录组成的,如果将网络快照和通信记录分别比作主题模型中文档和单词的概念,那么用户活跃度就是连接二者的隐含变量.借助活跃度我们可以从宏观网络层面和微观个体层面对网络进行建模分析并将二者合理地统一起来,用于阐述网络整体特征及个体用户行为的形成机制.
定义1. 用户活跃度.用户在各通信网络快照中主动发起通信的概率.
用户活跃度表示了用户使用通信服务的频繁程度,用户活跃度越高就说明该用户在以往的快照中多次主动发送过信息,这也意味着该用户在下一个快照中有较大的概率会以发送者的身份再次出现.本文以用户在M个训练集快照中作为信息发送者出现过的快照个数作为参照,将全体用户划分成K个活跃度等级,K为[2,M]的整数.活跃度等级个数K的选取会影响模型的复杂度和模型的准确度,简便的方法是将用户在训练集中作为发送者出现过的快照个数直接作为该用户的活跃度等级,即如果用户在m个训练集快照中都发送过消息则定义他的活跃度等级为m.为简便起见,本文第3节的实验将采用这种方式来定义用户的活跃度等级个数,即K=M.
本文使用的标识和含义详见表1所示:

Table 1 Interpretation of Symbols
2.2生成模型的构建与参数推导
每个通信网络快照内包含了若干条通信记录,类比于主题模型,我们认为这些通信记录是由不同活跃度等级的用户所发送的,而每个快照中出现的这些不同的活跃度等级服从Categorical分布*http:en.wikipedia.orgwikiCategorical_distribution;在同一活跃度等级内的各用户发送信息的概率也不相同,也服从Categorical分布;同一用户发送消息的时刻和消息接收者也服从Categorical分布.类似于LDA模型,我们也在“快照-用户活跃度”层面引入Categorical分布的共轭分布——Dirichlet分布——作为先验分布,构建3层贝叶斯网络.
图1展示了通信网络生成模型的概率图(也称为“盘子表示法”).图1中的阴影圆圈表示可观测变量,非阴影圆圈表示潜在变量,箭头表示变量间的条件依赖性,方框及其下角的字母表示重复抽样次数.

Fig. 1 Graphical representation of the generative model.图1 生成模型的概率图表示
对于单个通信网络快照gm,其生成过程可以形式化描述如下:
过程1. 单个快照的生成过程.
① DrawNm~Normal(Θ);*确定快照中通信记录的数量Nm*
② Draw ϑm~Dirichlet(α);*确定快照中发送者的活跃度分布参数ϑm*
③ forn=1:Nm*循环生成Nm条通信记录*
④ Drawzm n~Categorical(ϑm);*采样得到一个发送者的活跃度等级zm n*
⑤ Drawsm n~Categorical(φzm n);*从zm n等级发送者集中采样得到某发送者sm n*
⑥ Drawtm n~Categorical(tsm n);*从sm n的时间集中采样得到某发送时间戳tm n*
⑦ Drawrm n~Categorical(γsm n);*从sm n的联系人集中采样得到某收信者rm n,这便构成一条通信记录(sm n,rm n:tm n)*
⑧ end for
图1所示的模型中各活跃度等级下用户的概率分布参数φ、各用户的发信时刻的概率分布参数t、各用户的联系人的概率分布参数γ均可通过对训练快照进行简单地统计计算得出,则求解狄利克雷分布的超参α推导过程如下:

(1)
由生成过程中步骤②可知:
(2)
其中,Γ(x)为Gamma函数,αk表示α的第k个分量.
由过程1中步骤④可知:
(3)
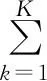
将式(2)、式(3)带入式(1)可得:
(4)

(5)
将式(5)带入式(4)可得:
假设给定α下各个快照间是条件独立的,因此:
(6)

对式(6)进行最大似然估计即可求得狄利克雷分布的超参α.此外,Minka在文献[20]中提出一种简单高效的估算狄利克雷分布超参α的不动点迭代方法,则本文提出的网络生成模型中Dirichlet分布超参α的各个分量αk,k∈[1,k]可按如下公式来迭代计算:
(7)


Fig. 2 Number of communications for snapshots.图2 各快照通信量
在使用该模型生成模拟快照时,只需要对训练集进行简单统计计算得到参数Θ,α,φ,t,γ,即可重复过程1来生成多个模拟网络快照.注意过程1中利用正态分布采样来得到各模拟快照中通信记录的个数,此处正态分布仅是示例,在实际使用中应该根据真实通信网络快照的通信量进行拟合分布的选择,在3.2节中给出了一种选择策略.
此外,该模型对训练集的依赖性较强,训练集中未出现的通信记录,同样不会出现在模拟网络中.解决这个问题可以通过类似PageRank算法[21]中设置一个阻尼因子(damping factor)d来调节,即用户有d的概率从自己训练集联系人列表中按概率挑选一个信息接收者,有1-d的概率在全网中随机挑选一个用户作为信息接收者.同样地,对于用户的发信时间也可以依此方法来做调整.另外,模型并没有考虑通信网络中节点的增加和消失等现象,对此可以通过在模型训练好的参数中随机添加或删除某些节点、更改节点的活跃度等级以及修改联系人列表等方式来模拟网络的进化和演变,从而能够产生符合某种演化情景的模拟网络,同时这也说明本文提出的通信网络生成算法具有较好的可扩展性.
3实验结果与分析
由于本文的方法仅涉及到通信网络中通信记录的发送者、接收者以及发送时间3个属性,以下工作仅以邮件通信网络为例,相关工作可以很自然地应用到其他类型的通信网络.
3.1实验数据
本文实验数据取自某单位自2011-02-19(周六)—2011-04-29(周五)共10周的内部人员间邮件通信网络日志数据,过滤掉无效的邮件地址,仅保留通信双方均是内部邮箱的数据.实验数据按天为时间间隔划分成70个快照,每个快照包含当日所有的邮件通信记录,每条记录包含发信时间、发信者ID、收信者ID三个信息,共包含109 709条通信记录和2 797个邮箱.
图2表示了各个快照的通信记录数量,从图2可以看出周末的通信记录数量与工作日相比有明显的区别.通过对快照的通信量进行参数为2的Kmeans聚类分析可知,数据明显地被划分为工作日和周末2类.对此可理解为邮件通信更多地被用于工作上的信息交流,而周末是休息时间,因此通信量会大大降低.考虑到工作日和周末2个时间段内用户的邮件通信会有着不同的行为模式,因此在后续实验中我们将原始数据分成工作日和周末2个快照集合来分别进行模拟,最后将二者的模拟数据合并到一起作为最终的实验模拟数据.
3.2初始参数设置
由于工作日和周末2类数据的模拟过程是一致的,为了简便起见本节中仅以工作日的50个快照数据集作为示例来描述实验中快照通信量的分布选择过程和狄利克雷分布初始参数的设置.
为了模拟各个快照的通信量分布,实验中选取正态分布(normal)、对数正态分布(lognormal)、泊松分布(poisson)、随机分布(random)作为候选的拟合分布.首先利用工作日快照的通信量数据作为训练集得到各候选分布的拟合参数;然后使用该参数来产生通信量的50个拟合数据;再对训练集数据和拟合数据按通信量大小进行排序并计算两者的平均误差,计算方法如下:
其中,M指训练集的快照个数,T(i)指训练集通信量排序后的第i个值,S(i)指拟合数据排序后第i个值.

Fig. 3 Fitting performance of different distributions on snapshot communications.图3 不同分布对快照通信量的拟合效果
实验中上述拟合分布的选择过程重复进行50次,各候选拟合分布的平均误差如图3所示.从图3可以看出,使用正态分布来拟合工作日的通信量平均误差最小,因此本实验中选用正态分布作为工作日通信量的拟合分布来生成模拟快照的通信量数据.不同的测试数据可能有着不同的拟合分布,在实际情况下应当有针对性地选取恰当的拟合分布来进行通信量的模拟.利用式(7)迭代计算狄利克雷分布参数α时需要给定一个初始值,实验表明该初始值的选取对于计算结果是无影响的,只会影响到收敛所需要的迭代次数.实验中以迭代前后2次α的欧氏距离作为误差阈值,迭代终止阈值设为10-4;α各个分量初始值设为αk=pkM,k=1,2,…,K,其中pk指训练集中发信者活跃度为k的通信记录所占比例,M代表训练集快照个数,K代表发信者活跃度等级个数.
3.3实验评估与分析
本节中先依次生成50个工作日模拟快照和20个周末的模拟快照,然后将二者组合起来作为10周的模拟通信网络数据,再对该模拟通信网络从网络整体特征和个体行为特征2个层面与训练集通信网络进行对比评估,最后对本文生成算法的运行效率进行简要的实验分析.
1) 在网络整体特征层面本文选取网络整体的节点度分布和通信发生的时间分布来作对比.通信网络节点度服从幂率分布是通信网络的一个重要特征,同时也说明了网络的无标度(scale-free)特性[22].图4给出了模拟网络与训练网络的节点度分布对比图.从图4可以直观地看出,二者在节点度分布上是非常吻合的,这也说明了模拟网络很好地保留了节点度分布这一网络整体结构特征.通信网络中节点度服从幂率分布本质上是对节点通信关系进行统计归纳得出的结论.本文提出的生成模型通过对训练集网络的学习既从网络层面保证了各活跃度等级的用户在模拟网络中的分布比例,同时生成的模拟网络中节点的通信关系具有较高的真实性,因此模拟网络的许多统计特征都与训练集网络有着很好的相似性.

Fig. 4 Comparison of node degree of two networks.图4 模拟网络与原始网络节点度对比
通信网络整体的通信时间分布反映了该通信网络的活跃时段是研究网络变化的一个重要特征.通信网络中各个时间段内产生通信次数的比例反映了全体用户的基本活跃时间.在没有突发事件相对稳定的情况下,通信网络中各时间段内产生通信次数的比例也应当是一致的.

Fig. 5 Comparison of time distribution of two networks.图5 模拟数据与原始数据时间分布对比图

Fig. 6 Comparison of frequency of one user’s recipients.图6 某用户的各联系人通信频率对比图
图5给出了模拟网络与训练网络的活跃时间分布对比图.从图5(a)(b)可以看出,模拟网络很好地保留了上午、下午、晚上3个明显的通信活跃时间段,其中纵轴表示该时间段通信量占全天通信量的比值;图5(c)给出了对应时间段内二者的差距,可以看出波动范围维持在±3%内,说明模拟通信网络对网络整体活跃时间分布的模拟效果很好.2) 在用户的个体特征层面本文选取用户的常用联系人通信频率和用户发起通信的时间分布2个特征进行对比.用户的常用联系人通信频率体现了用户日常的社交关系网是研究用户地位和社交关系的重要特征.首先将该用户在训练网络中的联系人按照通信频度进行排序并编号,然后与模拟网络中该联系人的通信频度作对比.图6给出了某用户与其160位联系人的通信频率对比图.从图6可以看出,模拟网络在全局上较好地维持了个体用户与其联系人的通信频度.

Fig. 7 Comparison of time distribution of one user.图7 某用户模拟数据与原始数据时间分布对比图
用户发起通信的时间分布体现了该用户工作、生活中的基本作息规律是分析用户行为模式的时间标尺.图7给出了模拟网络与训练网络的活跃时间分布对比图.从图7(c)可以看出,该用户在模拟网络中的通信时间分布与训练网络相比维持在±2%的波动范围内,这表明使用本文的方法生成的模拟通信网络对个体用户的活跃时间分布也有很好的模拟效果.3) 对本文提出的通信网络模拟生成算法的运行效率作简单的实验分析.该算法的训练阶段仅是对训练集进行简单的统计计算,用来标记用户活跃度等级、计算快照的通信量分布参数和狄利克雷分布参数等.由于训练集的规模通常是比较小的,并且仅需要训练一次即可重复使用;另外对于生成大规模模拟通信网络而言主要的时间消耗是在算法的生成阶段,因此下文假设已经得到了训练阶段的相关参数,仅对算法生成阶段的运行效率进行实验评估.
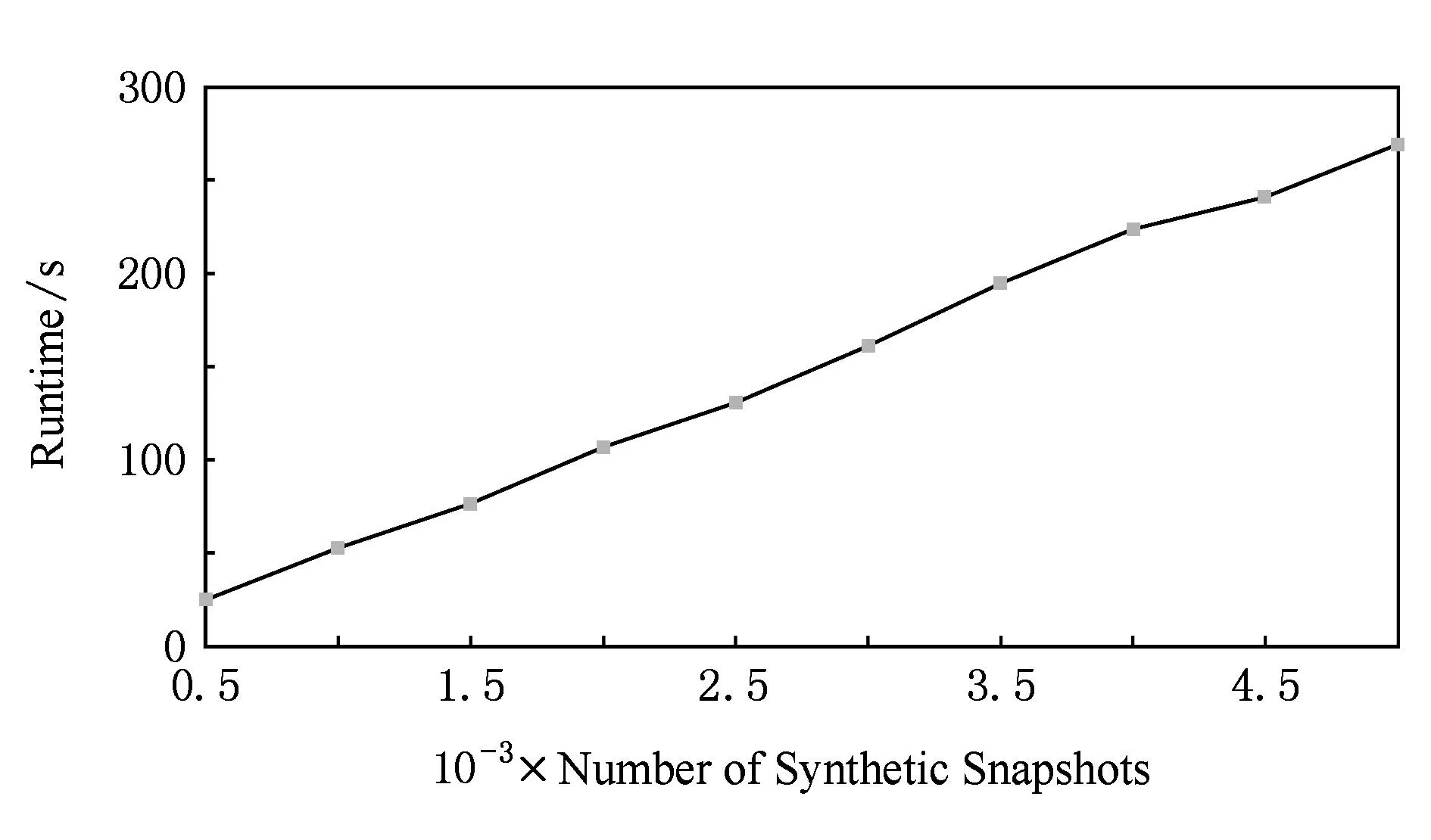
Fig. 8 Relationship between number of synthetic snapshots and runtime.图8 模拟快照数量与运行时间的关系
这部分测试实验仅以50个工作日快照数据为例,采用过程1的C++实现(未并行化)在一台普通笔记本(CPU主频2.5 GHz、4核、可用内存2.91 GB)上运行多次,分别生成500~5 000个模拟通信网络快照,程序的运行时间如图8所示.从图8可以看出,程序的运行时间与需要生成的模拟快照数量是呈线性相关的;生成5 000个模拟工作日快照大约需要270 s,而模拟数据规模是训练集的100倍.此外,由于生成的模拟快照之间没有联系是相互独立的,故生成算法可以方便地进行分布式并行处理以提升生产效率,适用于大规模网络模拟工作.
4结束语
本文针对通信网络的形成机制和仿真问题,提出一种基于主题模型的通信网络快速生成算法,并通过对真实邮件网络的实验分析,验证了该算法的有效性及运行高效性.与现有很多网络模拟算法相比,本文提出的方法生成的模拟通信网络可以很好地保留原始的网络拓扑结构以及个体用户的通信行为特征,也为通信网络的形成及演变机制提供了新的解释思路;同时它具有运行效率高、可并行化的特点,能够快速生成大规模的模拟数据.
但是本文并没有考虑时间和快照的关系,仅把模拟网络快照生成的前后顺序作为模拟快照时间的顺序.而在实际中,通信网络可能会跟时间有某种特殊联系,例如大学中寒、暑假期间邮件网络的通信量会明显减少,而开学初期又会有大量新邮箱注册激活等.这些事件跟具体通信网络的应用场景紧密相关,如何在模拟通信网络中如实地体现通信网络的演化特征以及周期性事件是一个值得深入研究的问题.另外,如何恰当地确定模型中活跃度等级个数K也有待进一步研究.
参考文献
[1]On B W, Lim E P, Jiang J, et al. Messaging behavior modeling in mobile social networks[C]Proc of the 2nd Int Conf on Social Computing. Piscataway, NJ: IEEE, 2010: 425-430
[2]Tyler J R, Wilkinson D M, Huberman B A. E-mail as spectroscopy: Automated discovery of community structure within organizations[J]. The Information Society, 2005, 21(2): 143-153
[3]Sun J, Faloutsos C, Papadimitriou S, et al. GraphScope: Parameter-free mining of large time-evolving graphs[C]Proc of the 13th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2007: 687-696
[4]Hu Xia, Liu Hua. Social status and role analysis of palin’s email network[C]Proc of the 21st Int Conf Companion on World Wide Web. New York: ACM, 2012: 531-532
[5]Rowe R, Creamer G, Hershkop S, et al. Automated social hierarchy detection through email network analysis[C]Proc of the 9th WebKDD and the 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis. New York: ACM, 2007: 109-117
[6]Akoglu L, Dalvi B. Structure, tie persistence and event detection in large phone and SMS networks[C]Proc of the 8th Workshop on Mining and Learning with Graphs. New York: ACM, 2010: 10-17
[7]Akoglu L, McGlohon M, Faloutsos C. OddBall: Spotting anomalies in weighted graphs[C]Proc of the 14th Pacific-Asia Conf on Knowledge Discovery and Data Mining. Berlin: Springer, 2010: 410-421
[8]Erdös P, Rényi A. On the evolution of random graphs[J]. Publication of the Mathematical Institute of the Hungarian Academy of Sciences, 1960, 5: 17-61
[9]Watts D J, Strogatz S H. Collective dynamics of ‘small-world’ networks[J]. Nature, 1998, 393(6684): 440-442
[10]Barabási A L, Albert R. Emergence of scaling in random networks[J]. Science, 1999, 286(5439): 509-512
[11]Li Xiang, Chen Guanrong. A local-world evolving network model[J]. Physica A: Statistical Mechanics and Its Applications, 2003, 328(1): 274-286
[12]Chakrabarti D, Zhan Yiping, Faloutsos C. R-MAT: A recursive model for graph mining[C]Proc of the 2004 SIAM Int Conf on Data Mining. Philadelphia, PA : SIAM, 2004: 442-446
[13]Leskovec J, Chakrabarti D, Kleinberg J, et al. Realistic, mathematically tractable graph generation and evolution, using Kronecker multiplication[C]Proc of the Knowledge Discovery in Databases. Berlin: Springer, 2005: 133-145
[14]Liu Yanheng, Li Feipeng, Sun Xin, et al. Social network model based on the transmission of information[J]. Journal on Communications, 2013, 34(4): 1-9 (in Chinese)(刘衍珩, 李飞鹏, 孙鑫, 等. 基于信息传播的社交网络拓扑模型[J]. 通信学报, 2013, 34(4): 1-9)
[15]Budka M, Juszczyszyn K, Musial K, et al. Molecular model of dynamic social network based on e-mail communication[J]. Social Network Analysis and Mining, 2013, 3(3): 543-563
[16]McCallum A, Wang X, Corrada-Emmanuel A. Topic and role discovery in social networks with experiments on enron and academic email[J]. Journal of Artificial Intelligence Research, 2007, 30(1): 249-272
[17]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022
[18]Blei D M, Lafferty J D. Dynamic topic models[C]Proc of the 23rd Int Conf on Machine Learning. New York: ACM, 2006: 113-120
[19]Zhang Chenyi, Sun Jianling, Ding Yiqun. Topic ming for microblog based on MB-LDA model[J]. Journal of Computer Research and Development, 2011, 48(10): 1795-1802 (in Chinese)(张晨逸, 孙建伶, 丁轶群. 基于MB-LDA模型的微博主题挖掘[J]. 计算机研究与发展, 2011, 48(10): 1795-1802)
[20]Minka T. Estimating a Dirichlet distribution[ROL].[2014-10-01]. http:research.microsoft.comen-usumpeopleminkapapersdirichletminka-dirichlet.pdf
[21]Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the Web[OL]. [2014-10-01]. http:ilpubs.stanford.edu: 809042211999-66.pdf
[22]Ebel H, Mielsch L I, Bornholdt S. Scale-free topology of e-mail networks[J]. Physical Review E, 2002, 66(3): 035103

Li Quangang, born in 1986. PhD candidate. Student member of China Computer Federation. His main research interests include pattern recognition, social network and machine learning.

Liu Qiao, born in 1974. PhD and associate professor. His main research interests include pattern recognition, social network and machine learning.

Qin Zhiguang, born in 1956. PhD, professor and PhD supervisor. His main research interests include information security and complex network.
中图法分类号TP181
基金项目:国家“八六三”高技术研究发展计划基金项目(2011AA010706);国家自然科学基金重点项目(61133016);中央高校基本科研业务费专项资金(ZYGX2012J067)
收稿日期:2014-10-17;修回日期:2015-02-09
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2011AA010706), the Key Program of the National Natural Science Foundation of China (61133016), and the Fundamental Research Funds for the Central Universities (ZYGX2012J067).
