基于Hadoop平台的图像检索研究
2016-04-13裴新超尹四清
裴新超,尹四清
(中北大学软件学院,山西 太原 030051)
基于Hadoop平台的图像检索研究
裴新超,尹四清
(中北大学软件学院,山西 太原 030051)
摘要:随着计算机技术的快速发展,图像数据的不断增长,针对传统的图像检索方法在处理海量图像数据存在低效率的问题,提出了一种基于Hadoop平台的并行图像检索方法。首先,设计合理的Map方法和Reduce方法,并行地提取图像的综合特征(颜色、形状、纹理),生成图像特征库;然后,并行地计算样例图像与图像库中的图像的相似度,输出最相似的图像。实验结果表明,基于Hadoop平台的图像检索方法比传统的图像检索方法具有更高的检索效率,适合大规模的图像检索。
关键词:Hadoop;MapReduce;相似度;图像检索
随着互联网的快速发展,每天图像数据以数亿计产生。如何根据输入的任意一幅图像快速检索到相似的图像,如何对海量的多媒体信息进行快速检索,已经成为一个亟待解决的问题。传统串行处理方式难以满足海量图像高效处理的需求,因此,寻求新的方式逐渐变成新的研究方向[1]。
近年来,云计算得到了快速发展,与云计算密切相关的大数据处理同样得到快速的发展,所以基于Hadoop平台来解决海量图像检索的问题被人们广泛的研究[3]。Hadoop平台具备优秀的大规模数据处理能力、较高的容错性以及可靠性、低成本等优势,能够提供分布式的数据存储和分析的解决方案,为并行地处理海量图像数据提供了基础。
针对传统图像检索方法检索效率不高的问题[8],本文提出了一种基于Hadoop平台的并行图像检索方法,在建立图像特征库的过程中,设计合理Map和Reduce方法,并行地提取图像特征,实现图像的存储;在进行图像检索的过程中,利用MapReduce并行地计算样例图像与图像库中图像之间的相似性。与传统的检索方法进行比较,本文检索方法具有更好的检索效率,更能适用于大规模图像检索。
1图像特征提取
传统的图像处理通常使用图像底层的物理特征,包括颜色直方图、形状SIFT特征、Tamura纹理特征、小波变换等。颜色直方图是最直观和最常用的颜色特征,SIFT是图像的局部特征,具有旋转、尺度缩放的不变性,能够更好地表述形状特征。本文提取图像颜色、形状、纹理等多种特征。提取图像特征的过程:
1) 首先将数据库中图像上传到HDFS上;
2) 设计合理的Map和Reduce方法,提取每幅图像的综合特征(颜色,形状,纹理),计算获得每幅图像的一个特征向量;
3) 最后获得所有图像的图像特征向量库。
在Map阶段,提取图像的颜色,形状,纹理特征,生成一个特征向量。并且把生成的特征向量作为一行记录存入HBase中,如果提取特征失败,那么记录图像的ID。在Reduce阶段,把无效的图像ID返回给HDFS[4]。
提取图像特征Map函数如下:
public void map (LongWritable key, Text value, OutputCollector < LongWritable , Text> output, Reporter reporter)
其中:key为图像的主键ID;value为图像的原始内容;输出LongWritable为图像的主键ID;Text为图像的特征数据。Map函数提取图像的颜色、形状、纹理特征组合生成综合特征。
提取图像特征Reduce函数如下:
public void reduce (LongWritable key, Iterator
其中:key为图像的主键ID;values为图像的特征数据;输出的LongWritable为图像的主键ID;Text为图像的特征数据。Reduce函数对全部的图像特征排序,output是所有排序后的图像特征。
2图像检索
图像以及图像特征都存储在HBase中,随着数据量的不断变大,在文件中进行检索需要花费很长的时间,为了提高检索的效率和减少检索的时间,采取基于Hadoop对图像进行检索[2]。基于Hadoop平台图像检索具有高并发性,它是将串行操作过程变成并行操作过程,其图像检索过程如下:
1) 用户提交样例图像,系统提取图像的颜色,形状,纹理特征;
2) 设计合理的Map和Reduce方法,并行计算出图像库中图像与样例图像之间的相似度;
3) 对相似结果进行排序,获得最后的相似图像。
在Map阶段,首先提取样例图像的图像特征,然后与特征数据库中的图像特征进行特征相似度的比较与匹配。<相似性,图像ID>作为map输出,并且按照相似性的大小对其进行排序和重新划分,输入到Reduce。在Reduce阶段,把所有的<相似性,图像ID>集合起来,根据相似性的大小排序,将前N个<相似性,图像ID>输入到HDFS,找出与样例图像相似性最大的图像的ID,得到相似性最高的N幅图像[5]。
图像检索的Map函数如下:
public void map(LongWritable key, Text value, OutputCollector< LongWritable ,Text> output, Reporter reporter)
其中:key为图像的主键ID;value为图像特征数据;输出LongWritable为图像的主键ID;Text为空。Map函数根据比较图像特征与样例图像特征之间的相似性得到检索的结果,output为最相似图像的主键ID集合。
图像检索的Reduce函数如下:
public void reduce(LongWritable key, Iterator
其中:key为图像的ID;value为空;输出的LongWritable为图像的主键ID;Text为图像的元数据。根据Reduce函数检索图像的属性、文字,获取Map操作中相似的图像,继而进行关于文字、属性的检索,最终得到同时满足两种特征的图像,output是所有最相似的图像。
3实验与分析
3.1实验环境
在Linux环境下搭建Hadoop平台,包括1个主节点(NameNode)以及3个子节点(DataNode),保证四台机器在同一个局域网,服务器配置如表1所示[7]。在搭建的Hadoop平台图像检索系统上,采用各个不同的节点数的情况下,做图像检索的实验,比较本实验平台的测试结果和传统单节点的测试,根据存储效率和检索速度来评价系统的性能,并且对基于Hadoop平台的检索系统进行全面表述[6]。

表1 Hadoop平台的系统服务器配置
3.2实验数据
对于Hadoop分布式图像检索系统,本实验采用40万服饰图像作为测试数据,分别采用10万、20万、40万、60万、80万、100万服饰图像对平台进行实验测试[9]。
3.3图像存储性能的对比
根据各个数量的服饰图像,依据各个节点数目,对所有进行存储消耗的时间如图1所示。从图中分析可得,如果服饰图像的数量低于10万,二者系统之间的存储所消耗的时间差异甚小;但是伴着图像总数的增大,采用单节点的存储图像消耗的时间剧烈增大,然而基于Hadoop平台系统存储消耗的时间增长不是很剧烈。因此,本文基于Hadoop平台的检索系统消耗了较短的存储时间,对系统的整体性能起到提高的作用。

图1 二者检索方式的服饰图像存储时间比较
3.4图像检索效率的对比
根据不同数目的图像库以及依据各个节点数的情况,服饰图像检索消耗时间如图2所示。从图中分析可得,如果服饰图像数目较少,基于Hadoop平台的系统和单节点系统的检索消耗时间差不多;如果增加服饰图像数量,二者检索消耗的时间均相应增加,并且传统的单节点系统图像检索消耗时间相比于Hadoop平台系统的消耗时间,前者的增长更大。重点是因为基于Hadoop的分布式系统采用MapReduce具有并行计算优势,在各个节点上同时进行服饰图像的检索,提升了服饰图像的检索效率;并且如果节点的数目越大,检索的效率越高,采用更多基于Hadoop分布式系统的节点数目,能够大幅提升图像检索系统的性能。
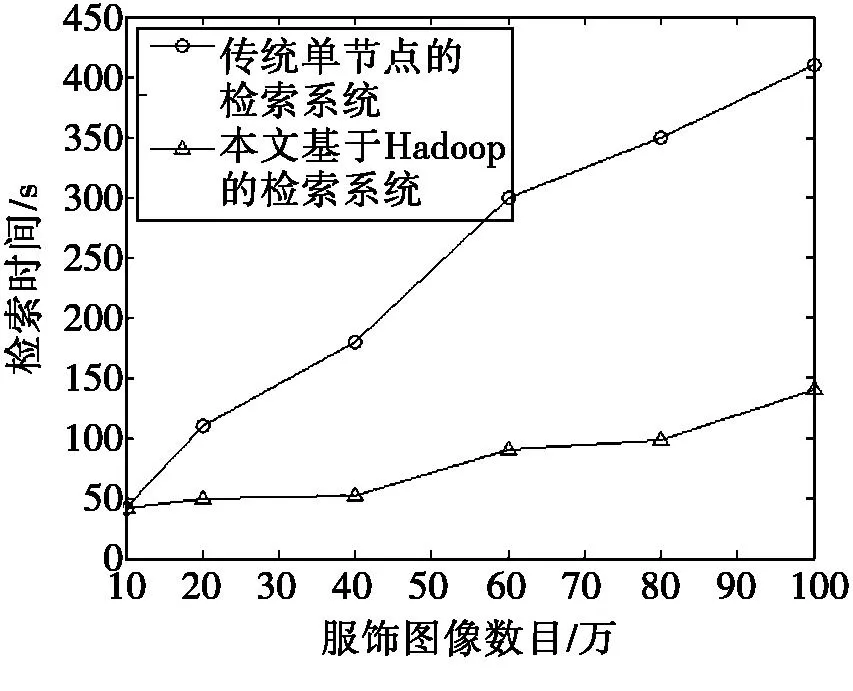
图2 二者系统的服饰图像检索效率比较
4结束语
随着图像数量的不断增长,传统图像检索方式在处理海量图像时存在效率低、可靠性差等缺陷,基于此提出了基于Hadoop平台的分布式并行图像检索方法。实验测试表明,基于Hadoop的分布式图像检索能够提升图像存储和检索的效率,能够给用户提供较好检索结果,同时在处理海量图像数据时,体现出比传统单节点更明显的优点。以后的工作重心是更有效的在Map和Reduce之间进行数据传输,使这过程的时间消耗降低,从而更加有效地提升检索的效率。
参考文献
[1]霍树民.基于Hadoop的海量影像数据管理关键技术研究[D].长沙:国防科学技术大学,2010.
[2]杨丛聿.基于MapReduce模型的图像相似度分析[D].北京:北京邮电大学,2013.
[3]卓友胜,刘利.基于Hadoop云计算平台的CBIR设计[J].电脑知识与技术,2014,27:6318-6320.
[4]杨曼,何鹏,齐怀琴,等.基于Map/Reduce的海量视频图像检索系统设计[J].电视技术,2015(4):33-36.
[5]李素若.基于MapReduce的互联网图像相似性度量研究[J].荆楚理工学院学报,2015(2):32-36+49.
[6]朱为盛,王鹏.基于Hadoop云计算平台的大规模图像检索方案[J].计算机应用,2014(3):695-699.
[7]范敏,徐胜才.基于Hadoop的海量医学图像检索系统[J].计算机应用,2013(12):3345-3349.
[8]蔡丽娟.一种基于Hadoop架构的海量图像检索方法[J].通讯世界,2014(8):16-18.
[9]郭飞,詹炳宏,刘刚.基于Hadoop的服饰图像存储与检索关键技术研究[J].计算机应用研究,2014(4):1086-1089+1126.
Image Retrieval Solution Based on Hadoop Platform
Pei Xinchao, Yin Siqing
(SoftwareSchool,NorthUniversityofChina,TaiyuanShanxi030051,China)
Abstract:With the development of Internet and the growing of image data, in view of the low efficiency problem with traditional image retrieval methods in the treatment of massive image data, this paper proposes a parallel image retrieval method based on Hadoop platform. First of all, the reasonable design method of the Map and Reduce method are made to parallel extract the image color, texture feature and generate the image feature database; then, in parallel to compute the similarity of sample images with the images in the image library, output the most similar images. The experimental results show that comparing with the traditional image retrieval method, the image retrieval method based on Hadoop platform has higher retrieval efficiency and suitable for large-scale image retrieval.
Key words:Hadoop; MapReduce; similarity; image retrieval
中图分类号:TP391
文献标识码:A
文章编号:1674- 4578(2016)01- 0085- 02
作者简介:裴新超(1989- ),男,山西运城人,硕士研究生,CCF会员(49769G),主要研究方向为:基于内容的图像检索。
收稿日期:2015-10-18
