基于RAID系统和GPU技术的快速CT重建方法研究
2016-04-13刘俞辰
刘俞辰
(中北大学信息与通信工程学院,山西 太原 030051)
基于RAID系统和GPU技术的快速CT重建方法研究
刘俞辰
(中北大学信息与通信工程学院,山西 太原 030051)
摘要:针对锥束CT三维重建算法存在数据量大,重建时间长的问题,提出了一种基于RAID存储系统和GPU共同加速锥束CT重建过程的方法。该方法先构建RAID存储系统,利用多个磁盘阵列并行读取投影数据,提高数据的载入时间;在此基础上,利用GPU技术来加速FDK重建算法,减少重建过程的时间。实验结果表明,在保证重建质量的前提下,本文提出的加速方法,相比于传统方法,速度提升约60倍。
关键词:独立磁盘冗余阵列;图形处理器;计算机断层重建
近年来,锥束CT凭借其扫描速度快、射线利用效率高和重建图像轴向分辨率高[1]等特点,在工业和医学上得到了广泛的应用。但是其重建的数据量大,公式比较复杂,仅仅靠CPU重建,耗时太大,无法满足工业上实时、准确、快速的重建要求[2]。针对这一问题,国内外许多学者做了大量研究,目前的主流方法是利用RAID技术改善存储设备性能以及利用GPU技术加速运算过程。
磁盘作为存储设备的主要部件,其性能多年来一直未得到明显的提高,是整个计算机系统中的性能瓶颈。Patterson等提出的冗余磁盘阵列RAID技术[3]大大提高了存储系统的性能和可靠性,使得存储系统有了新的发展方向。RAID系统数据传输速率高,安全性强等特点也满足工业CT对重建数据的要求。
2007年NVIDIA公司推出了基于CUDA的GPU,CUDA不需要借助于图形学API,采用了比较容易掌握的类C语言进行开发,极大降低了开发难度,使得利用GPU并行计算来加速复杂算法成为可能。Scherl等[4]使用CUDA技术实现了对FDK算法的加速,取得了比传统基于图形学API加速算法更好的加速效果。Mueller等[5]通过利用缓存优化,进一步提高了加速比;王钰等[6]利用GPU的多处理器实现了FDK算法中的滤波与反投影过程,得到了较高的加速比,但是算法相对比较复杂。
本文充分运用并行化思想,通过组建RAID系统,优化GPU访问全局存储器的时间和次数减少FDK算法重建过程所消耗的时间。实验结果表明,本文提出的优化方法在实际工业中有广泛的应用前景。
1基础知识
1.1RAID技术简介
RAID是一种使用多磁盘驱动器来存储信息的存储系统。其基本思想是把多个磁盘驱动器组成一个阵列组合,使其在逻辑上只形成一个磁盘驱动器,数据以分段的形式存储在这个逻辑磁盘阵列的不同物理磁盘上,用户操作磁盘阵列的与操作单个磁盘无异。在进行数据存取时,阵列中的所有磁盘同时并行工作,因此大幅降低了数据存取的时间。RAID技术主要包含RAID 0~RAID 50等数个规范,每种级别的侧重点各不相同,都是在增加数据可靠性与加快存储器读/写性能两个目标之间取得平衡。
1.2CUDA基础
CUDA是NVIDIA公司2007年推出的一种GPU架构模式,该模式引入了Grid、Block以及Thread的概念。Grid是二维笛卡尔直角拓扑结构,其上的每个节点标识一个Block,用户可以通过Block的ID来索引特定的网格节点;Block为三维直角坐标结构;Thread是块中的元素,使用时可以通过Thread的ID来索引目标线程。该模式集合了数据并行计算的软硬件体系和开发工具,运行在CUDA平台的程序是GPU和CPU的混合代码。实际执行中,程序首先由NVIDIA编译器进行编译。编译后的代码分为两部分:在CPU端运行的控制流程的串行程序以及在GPU端运行的计算密集的并行程序。
1.3FDK算法原理
FDK算法是Feldkamp等人在1984年针对锥束几何圆形扫描轨迹提出的一种近似的三维图像重建算法。图1为该算法的扫描方式,o-xyz为扫描对象坐标系,o-ts为射线源旋转坐标系,o-tz为探测器坐标系。S射线源通过射线源中心并与探测器平面垂直。
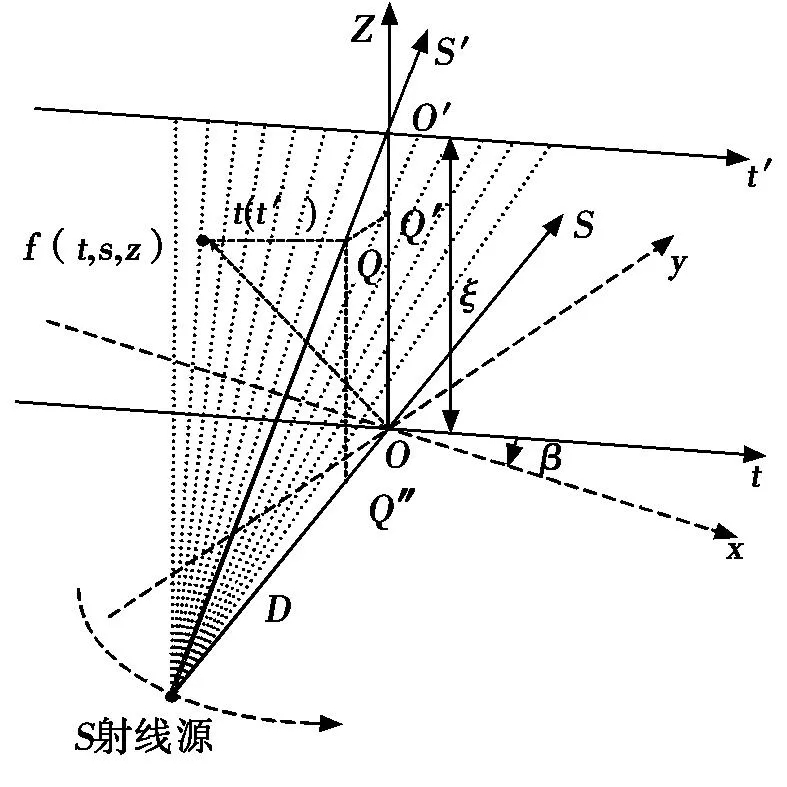
图1 FDK扫描原理图
FDK算法主要包括3个步骤:加权,滤波与反投影。具体实现如下:
1) 对二维投影数据进行加权修正:
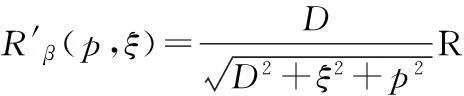
(1)
其中:D表示射线到旋转中心O的距离,(p,ξ)为探测器平面坐标,Rβ(p,ξ)表示第β角度的投影数据,R′β(p,ξ)表示对投影数据加权后的结果。
电子商务背景下烟草商企实现精准化营销的途径……………………………………………强智辉 晁 源 史露露(5.57)
2) 对加权后的投影数据沿行方向进行滤波:

(2)
3) 计算投影地址p1、ξ,进行反投影重构:

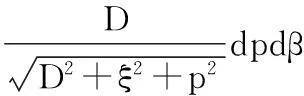
(3)
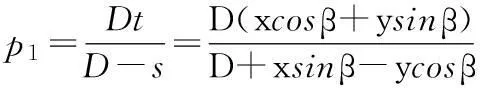
(4)

(5)

(6)
其中:f(t,s,z)为被重建函数,p1、ξ为反投影地址,U为加权因子。
2加速方法
2.1组建RAID5系统
RAID5是一种存储性能和数据安全兼顾的存储解决方案,可以理解为RAID 0和RAID 1的折中方案,也是目前应用最为广泛的RAID技术。RAID 5具有和RAID 0相近的数据读取速度,由于多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘利用率要比RAID 1高。若RAID5中一个磁盘数据发生损坏,可以利用余下的数据和相应的奇偶校验信息去恢复被损坏的数据,因此在速度和安全方面都有很高的保障。
本文采用4块1TB磁盘组成RAID5级别进行实验。做RAID5阵列所有磁盘容量必须一样大,当容量不同时,会以最小的容量为准。当有N块阵列盘,用户空间为N-1块盘容量,假设单硬盘的数据读取速度为T,则数据读取速度理论上为N×T。其数据存储方式如图2所示:Ap为A1、A2和A3的奇偶校验信息存储在磁盘3上,Bp为B1、B2和B3的奇偶校验信息存储在磁盘2上,其它以此类推。

图2 RAID5结构示意图
2.2使用GPU并行化FDK重建方法
加权和滤波所耗时间占整个FDK算法消耗时间的比例较少,并且随着重建规模的增大,所占比例还会继续降低。滤波相当于求卷积,目前主流方法都是利用CUDA自带的CUFFT库对投影数据做频域滤波。根据复数FFT的特点,首先要对投影数据进行重排,实数和虚数部分各对应一行,这样每个线程每次都可对投影数据相邻的两行做滤波。滤波完成后再进行IFFT运算,并把数据重排到对应的两行中。
2.2.2反投影加速方法
随着近几年GPU的快速发展,GPU用于高性能计算的瓶颈不再是计算消耗而是访存消耗。重建数据通常存放于GPU全局存储器内,但全局存储器没有缓存加速,虽然使用合并访问可以提高访问速度,但仍然会有几百个周期的访问延迟。因此,如何缩减访问全局存储器的时间和次数是GPU加速的关键因素之一。
通常情况下,一个核函数中只对1幅投影图像进行运算,对于360幅的投影数据,整个反投影过程就需要读写全局存储器360×N3次。本文提出一种使用一个核函数完成m个角度投影图像的反投影的方法,即每个核函数需要计算m个角度投影图像的反投影参数,但只读写全局存储器N3次,这样就使读写全局存储器的次数变为原来的1/m。但是在减少全局存储器读写次数的同时,核函数中每个线程的计算负担就会增大,随着m的不断增大,整个GPU中活动Block和活动Warp的数量就会减少,并行化程度就会降低,同时活动的Block和活动的Warp数量减少反过来又会影响GPU隐藏访问全局存储器的优势。所以,m的大小关系着这个程序的效率。通过借助CUDA profiler进行反复实验得出,当m取6,即核函数中同时完成的反投影图像为6幅时,加速效果最为理想。
3实验结果
为了验证该方法的可行性,本文采用实际投影数据进行测试。扫描工件为圆柱型,扫描模式为圆轨迹。射线源到旋转中心的距离为800 mm,物体中心到探测器的距离为150 mm,射线为ISOVOLT 450,探测器为paxscan2520,探元大小0.127 mm,电压110 kV,电流2.5 mA,投影数据大小为570×460,中心坐标(285,228),旋转角度为360度,扫描间隔为1度。其中,实验平台采用的计算机配置如下,CPU:I7-4770,GPU:GTX760。软件环境为Visual studio 2012+CUDA 5.5。

表1 重建过程时间对比表(s)
表1给出了具体重建过程中每个步骤的时间对比表。从中可以看出,数据读取阶段,RAID 5的速度相比单硬盘,达到其近4倍的速度,接近于理论值。数据处理阶段,本文方法与原GPU方法相比,提高了2倍,这是由于访存优化节省了大量数据传输耗时。与原CPU方法相比,加速比达到了60多倍,重建速度得到明显改善,充分说明了GPU在大规模运算中的优势。

(a) 原CPU方法重建结果 (b) 本文方法重建结果
图3原CPU方法和本文方法重建结果对比
针对Z=100层图像,图3给出了CPU与本文方法重建结果对比图。可以看出,两种方法的重建结果基本一致,在精度允许范围之内,这是因为本文算法的实现方式不包含任何图形编程内容,只是将运行于CPU上的代码改写为GPU上执行的代码。这进一步验证了本文加速方法的实用性和有效性。
4结论
针对锥束CT三维重建耗时长的问题,本文从实际工业应用角度出发,充分利用并行处理思想,提出了一种基于RAID存储系统和GPU共同加速锥束CT重建整个过程的方法。实验结果表明,本文提出的方法比原GPU方法在重建速度上提高了2倍,比原CPU方法在重建速度上提高了60多倍,基本满足工业实时性需求。
参考文献
[1]马俊峰.三维锥束CT图像重建加速技术研究[D].济南:山东大学,2011.
[2]Li L,Xing Y,Chen Z,et al.A Curve-filtered FDK (C-FDK) Reconstruction Algorithm for Circular Cone-beam CT[J].Journal of X-ray Science and Technology,2010,19(3):355-371.
[3]Cabrera L F,Long D D E.Swift:Using Distributed Disk Striping to Provide High I/O Data Rates[J].Computing Systems,1991,4(4):405-436.
[4]Scherl H,Keck B,Kowarschil M,et al.Fast GPU-based CT Reconstruction Using the Common Unified Device Architecture[C].Nuclear Science Symposium,Honolulu.Washington,DC:IEEE Computer Society,2007:4464-4466.
[5]Zheng Z,Mueller K.Cache-aware GPU Memory Scheduling Scheme for CT Back-projection[C].Nuclear Science Symposium Conference Record (NSS/MIC),2010 IEEE.IEEE,2010:2248-2251.
[6]王珏,曹思远,邹永宁.利用CUDA技术实现锥束CT图像快速重建[J].核电子学与探测技术,2010,30(3):315-320.
Research on Fast CT Reconstruction Method Based on RAID System and GPU
Liu Yuchen
(SchoolofInformationandCommunicationEngineering,NorthUniversityofChina,TaiyuanShanxi030051,China)
Abstract:Aiming at the problems of large volumes of data and long reconstruction time existing in cone-beam CT three dimensional reconstruction algorithm, a new method based on RAID storage system and GPU is proposed to together accelerate the reconstruction process of cone-beam CT. Firstly, a RAID storage system is constructed to parallel read the projection data with multiple disk arrays and shorten the time of loading data. Then, a GPU technology is used to accelerate FDK reconstruction algorithm to reduce the reconstruction time. The experimental results show that the proposed acceleration method can develop the reconstruction speed about 60 times without compromising the reconstruction image quality compared with the traditional method.
Key words:redundant array of independent disk; graphics processing unit; CT
中图分类号:TP391
文献标识码:A
文章编号:1674- 4578(2016)01- 0077- 03
作者简介:刘俞辰(1988- ),男,湖南衡阳人,硕士研究生,主要从事CT重建与GPU加速技术研究。
收稿日期:2015-09-18
