基于增量记忆视觉注意模型的复杂目标识别研究
2016-04-13崔丽娜胡玉兰片兆宇
崔丽娜,胡玉兰,片兆宇
(沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159)
基于增量记忆视觉注意模型的复杂目标识别研究
崔丽娜,胡玉兰,片兆宇
(沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159)
针对复杂背景下的目标识别问题,提出一种新的基于增量记忆的视觉注意模型。首先根据目标的颜色形状,以及自底向上的原始视觉特征颜色、强度、方向、对称性对目标进行粗定位。在此基础上,利用粗选目标的颜色、形状生成一组自顶向下的偏差信号,对初选目标进行及时指导修正。为了提高识别的准确率,算法设计了一种增量学习记忆的机制来指导偏差信号,所提出的增量注意机制不仅可以不断学习和记忆各类目标的颜色和形状特征,而且利用这种机制可生成一个自顶向下的偏差信号,对关注的候选区域的目标进行精确定位。此外,训练后的增量记忆的颜色、形状特征有助于推断新的未知目标。最后的仿真实验中,与五种典型算法对比,无论是主观还是客观实验,都获得了较优结果。因此,所提算法是一种高效的、切实可行的算法。
自底向上注意;自顶向下注意;增量记忆;视觉显著性
0 引言
人类视觉系统[1]具有机器无法比拟的灵活、高效的适应能力,在自然或杂乱复杂的场景中,往往可以轻松地检测到任意目标。因此,把人类视觉系统的特性融入到人工视觉系统中一直是计算机视觉领域的研究重点。而显著目标检测,由于其高效的处理性能、广阔的应用前景,被认为是机器视觉研究的重中之重。
本文利用增量记忆将自底向上处理过程与自顶向下处理过程结合起来,提出一种新的注意模型。基于该模型的算法强调自顶向下的注意感知,实际上是一个自底向上和自顶向下有机融合和相互作用的过程,将目标对象生成的偏差信号定义为增量记忆,自顶向下模型生成的增量记忆不断指导修正自底向上模型对目标对象的识别,达到即使在复杂背景下,也可以准确、高效地识别出目标对象。最后的仿真结果中,与6种典型自底向上注意模型对比,所提算法体现了更好的稳定性和有效性。
1 视觉注意机制
视觉注意机制是模拟人脑来处理信息的机制[2]。通过将不同的处理优先级赋予不同的图像区域,可以降低处理过程的复杂度,提高处理速度和抗干扰能力,即在特征整合理论的基础上,提取图像的亮度等初级视觉特征,形成各个特征维的显著图;然后基于非均匀采样的方式,采用多特征图合并策略对这些不同特征维的显著图进行融合,形成一幅最终的显著图。根据显著图可以得到一系列的待注意的目标,各目标通过注意转移的禁止返回(Iinhibition of retum)机制[3]和胜者为王(Winner-take-all)竞争机制[4]吸引注意焦点,并使得注意焦点在各个待注意的目标之间依一定的原则转移。注意信息是由每一个对应于特定区域图像特征的点组成的。
以基于视觉注意机制的注意快速识别目标为例,其识别效果如图1所示。

图1 识别效果图
由图可知,单纯视觉注意模型检测显著目标的效果并不好,在目标对象和背景对比度不明显的情况下识别效果很差,显著区域的边界不清晰,特征细节给模糊掉了,目标对象并不突出,尤其背景比较复杂的情况下,噪声干扰也比较大。
2 基于增量记忆视觉注意模型的复杂目标
为了模拟人类的智能视觉系统,本文提出一种基于增量记忆的视觉注意的模型。本模型包括两个处理过程:自底向上处理过程[5],自顶向下处理[6]过程。自顶向下处理过程生成增量记忆,指导修正自底向上处理过程的识别目标对象工作,其中增量注意不仅可以不断学习和记忆各类目标的颜色和形状特征,而且利用增量记忆生成自顶向下的偏差信号,可以对目标对象进行精确定位。整体框图如图2所示。
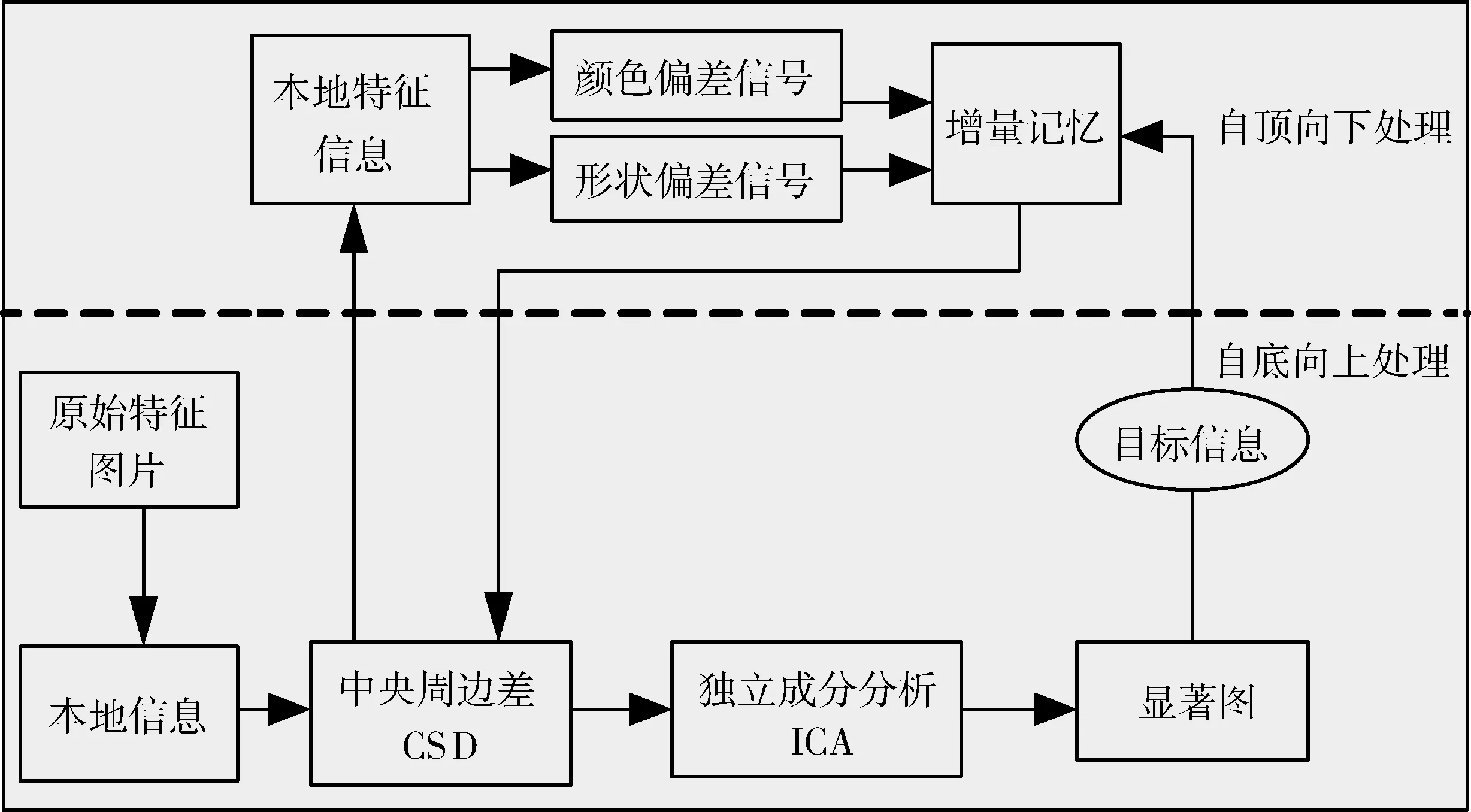
图2 该模型的概述
首先由原始的输入图像可获取到图像的基本特征,通过高斯金字塔提取粗尺度图像,图像通过中央标准差(CSD)获取到显著信息[7];同时对图像的基本颜色特征、形状特征进行加权等处理生成基于原始图像的颜色、形状偏差信号,即增量记忆,在生成细识别目标对象的过程中,偏差信号对识别不断指导修正,以实现复杂背景下目标对象的高效准确识别,生成显著图。通过增量记忆[8]不仅可以识别显著区域,而且可以将其存储下来。
2.1 自底向上处理
2.1.1 颜色特征提取
为了提高识别精度,并且实现彩色图像的识别,识别过程中各个颜色通道需保持独立。若想获得最佳的图像边缘就需要采用IUV颜色空间[9]。把对彩色图像(R,G,B)的识别问题转换成(I,U,V)颜色空间的问题,识别过程中各个颜色通道保持独立,这种方法识别精度高,并且实现了彩色图像的识别。通过公式(1)计算:
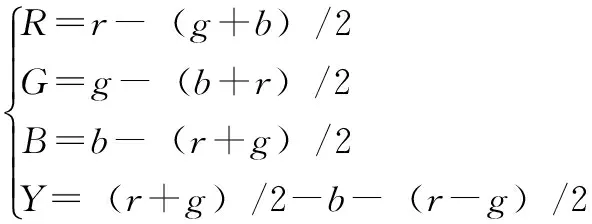
(1)
根据RGB颜色空间模型[10]构建一个 IUV 颜色模型,转化方法如公式(2)所示:
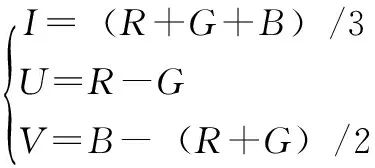
(2)
强度特征i通过公式(3)获得:
i=(r+g+b)/3
(3)
2.1.2 基于中央周边差的特征处理
在显著图模型中,以方向(O)和对称性(S)特性作为高阶特性,分别利用Gabor滤波器和Fukushima对称性提取边缘特性的方法,将I、O、S、U、V5个特征通过高斯金字塔,生成7个不同尺寸的特征图,可以得到35幅特征图。然后,利用中央周边差,将I、O、S、U、V的显著图组合成4个显著图,如式(4):
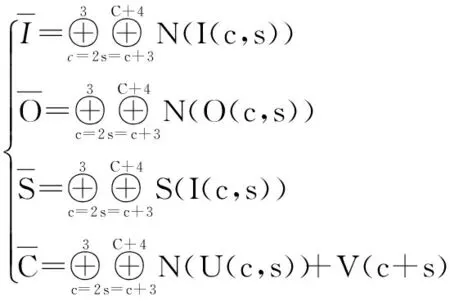
(4)
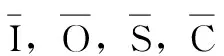
2.1.3 基于显著图的独立成分分析
在该模块中,采用独立分量分析算法[11]来减少冗余,以视觉皮层的作用作为冗余减速器。将特征图各个特征通道与滤波器宽度作卷积计算并求和来确定局部显著区域。最合适的规模显著区域集中在x,如式(5)所示:
(5)
HD(l,x)和WD(l,x)分别是熵和窗大小。在自底向上显著图模型中获取局部区域,定义为IOR 区域[12]。自底向上凸起的局部地区获得的地图模型被定义为IOR地区。那么屏蔽掉这个IOR 区域也就是排除了先前认为的显著对象,接着可以找到下一个显著目标。
2.1.4 显著图的熵值选择与目标对象中央加强
本文通过抑制幅度谱脉冲进行显著目标检测,对脉冲的抑制量不同检测出的显著图结果也不同,所以建立了不同高斯函数平滑后幅度谱尺度空间[13],它是由一系列高斯函数与幅度谱卷积[14]得到的,每个高斯函数具有一个不同的尺度参数,如式(6)所示:
(6)
其中k为可调节的尺度参数, k=1…K,K由图像的尺寸决定,如式(7)所示:
K=[log2min{H,W}]+1
(7)
H,W为图像的长和宽,t0=0.5。给定图像的幅度谱为A(u,v),则平滑幅度谱的尺度空间如式(8)所示:
Λ(u,v,k)=(g(u,k)*A(u,v))
(8)
对不同尺度的显著图求熵值,熵值最小的显著图[15]认为检测结果是最好的,其计算公式如式(9)所示:
kp=argmin{H(Sk)}
(9)
其中熵值计算为传统的计算公式如式(10)所示:
(10)
2.2 自顶向下处理
2.2.1 提取颜色和形状特征
由R,G,B和Y色彩成分可以获取到RG和BY特性,而由RG和BY可以获取物体的颜色和形状特性,通过此过程可以有效地通过颜色特征来提取图像的细节信息。目标物体的RG和BY特征通过裁剪变成两个16×16极对数特性,并且将每个极对数特性转换为一维向量。
本文采用熵最大模型来分别模拟视觉注意机制简单特性和复杂特性,即S1和C1特性。S1特性构造使用一个对象在一个局部区域的定位信息,并通过Gabor滤波器具有不同尺度的输入图像。通过滤波可以获得2尺度和8个方向的滤波特性的S1特性。因此每个方向就有了两个S1定位图,通过S1定位图对每个方向的操作取最大的操作可以得到C1特性。
2.2.2 自顶向下信号生成偏差矩阵
当成功训练学习目标对象后还有一个额外的作用就是可以生成权重矩阵,矩阵可以生成自上而下的偏差信号,这样便在输入场景中可以找到目标对象区域。基于特定偏差注意的目标对象任务来考虑尺度不变特性,基于三种不同尺度的高斯金字塔,其三种不同的尺度可以用来训练三种不同比例的颜色和形状特性。所以这三种不同比例训练的权重矩阵可以生成三种不同尺度的特性。在中央周边差(CSD&N)过程中,三种不同比例的权重矩阵可以用于生成不同尺度的偏差信号。
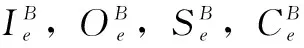
(11)
其中c_We和f_We分别是颜色和形状的加权矩阵,Ie,Oe,Se,Ce分别是强度、方向、对称性和颜色特征。
2.3 增量记忆
首先将自顶向下处理工程生成的颜色、形状偏差信号定义为增量记忆,结合考虑自顶向下的目标对象的形状和颜色偏差信号,得出显著图,利用提出的模型可以成功地提取出目标物体区域,生成流程图如图3所示。
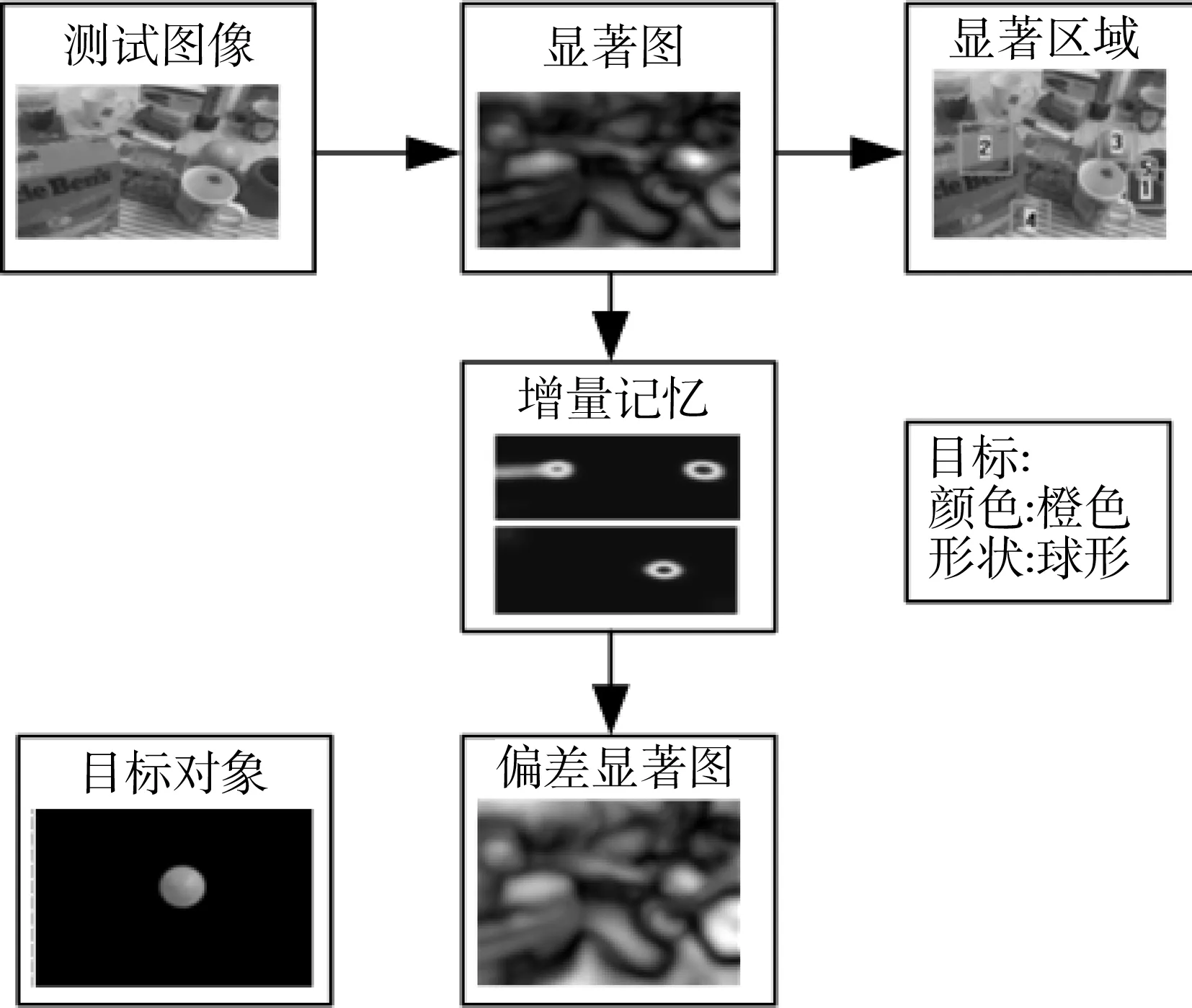
图3 自顶向下注意的实验结果
通过对一个特定尺度的目标对象的感知可以获取到每个感知对象的权重矩阵。因此,通过使用不同尺度的自底向上特征并用自上向下的加权矩阵提出的自上向下偏差模型可以检测出尺度不变的对象定位区域。基于同一特征图生成过程由自顶向下的偏差强度特征、方向特征、对称性特征、颜色特征可以创建偏差强度特征图、偏差方向特征图、偏差颜色特征图、偏差对称性特征图这四种不同的偏差特征图。
3 实验结果
将本文提出的方法与FT,SR,AIM,Gbvs,Itti算法进行比较,实验结果如图4。

图4 实验结果:(a)原图 (b)FT (c)SR(d)AIM (e)Gbvs (f)Itti (g)本文方法
从上图的对比结果可以看出,本文方法具有最好的显著性能评估。对于测试图像,大多数方法都能够检测出显著目标,但是都各有利弊,并不完善。FT算法可以识别目标对象但是精确度不高,没有消除冗余信息;SR算法抗噪声性能不好,识别效果也不是很理想;AIM算法在目标对象和背景对比度不明显的情况下识别效果很差,显著区域的边界不清晰;Gbvs算法和Itti算法可以识别出目标对象的大体轮廓,但是对象的细节信息被复杂的背景给模糊掉了,所以最终识别效果不好。从本文算法最终识别效果可以看出,对于复杂背景下的目标对象识别效果还是很不错的,冗余信息处理的也比较好,抗噪声性能相比较也是比较强的,精确度、准确率等各方面的表现都不错。
4 结束语
在正常的人类视觉中,自底向上和自顶向下处理过程的结合将会影响注意,并将注意吸引到显著的相关场景部分。所以,强调模拟自顶向下的注意感知实际上是一个自下而上和自上而下的有机融合和相互作用的过程,在这个过程中自动运用视觉认知规律,通过一系列视知觉操作,使视觉处理过程在一定目的下,以尽可能小的代价获得尽可能好的结果,也更加符合人类视觉感知的基本特征。
复杂背景下的目标识别是计算机视觉的研究热点和难点问题。本文中提出了一种基于增量记忆将自底向上和自顶向下相结合的方式来定位复杂背景下目标对象的方法。在复杂的背景下,该模型有较强的噪声抑制能力,可以把目标准确定位出来并且更好地解决目标识别的问题。
[1] 田媚.模拟自顶向下视觉注意机制的感知模型研究[D].北京:北京交通大学,2007.
[2] 暴林超.复杂目标视觉注意模型研究[D].武汉:华中科技大学,2011.
[3] 谢玉林.贝叶斯框架下图像显著性检测[D]. 大连: 大连理工大学, 2011.
[4] 殷德奎,张保民,柏连发.一种热图像的多模板边缘检测方法[J].南京理工大学学报,1999,23(1): 16-20.
[5] TREISMAN A,GELADE G. A feature integration theory of attention [J]. Cognitive Psychology, 1980, 12(1): 97-136.
[6] 王岳环,张天序.基于视觉注意机制的实时红外小目标预检测[J].华中科技大学学报: 自然科学版,2001,29(6):7-9.
[7] 唐奇伶.基于初级视皮层感知机制的轮廓与边界检测[D].武汉:华中科技大学,2007.
[8] 张鹏,王润生.基于视点转移和视区追踪的图像显著区域检测[J].软件学报,2004,15(6):891-899.
[9] 单列.视觉注意机制的若干关键技术及应用研究[D].合肥:中国科学技术大学,2008.
[10] PETER R J. Components of bottom-up gaze allocation in natural images[J]. Vision Research, 2005, 45(8): 2397-2416.
[11] ITTI KOCH. Feature combination strategies for saliency-based visual attention systems[J],Iournal of Electronic Imaging,2001,10(1):161-169.
[12] LIU T,SUN J, ZHENG.X. Learning to detect a salient object[C]. in: Proceedings of CVPR,1969:97-145.
[13] 谢玉林.贝叶斯框架下图像显著性检测[D]. 大连: 大连理工大学, 2011.
[14] 田媚,罗四维,廖灵芝.基于what和where信息的目标检测方法[J].电子学报,2007,35(11):2055-2061.
[15] DALAL N. Histograms of oriented gradients for human detection[C]. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition,2005: 886-893.
Target recognition of visual attention model based on the incremental memory
Cui Lina,Hu Yulan, Pian Zhaoyu
(School of Information Science and Engineering, Shenyang Ligong University,Shenyang 110159, China)
A new method to recognize target of visual attention model based on the incremental memory is proposed, it is about the target recognition problem under complex background. First of all, according to the shape and the color of the target, and the original visual characteristic of the bottom-up color, intensity, direction, symmetry, the target is located roughly. On this basis, a set of top-down bias signal is generated. In order to improve the accuracy of recognition, target recognition of visual attention model based on the incremental memory is proposed. The proposed incremental attention mechanism not only can keep on learning and memory of all kinds of color and shape features of target, and taking advantage of this mechanism, it can generate a top-down bias signal, to pay attention to the candidate regions of target for precise positioning. In addition, unknown object is located by the training characteristics of the color and shape of the increment of memory. In the final simulation experiment, the proposed method is compared with five kinds of typical algorithms, both subjective and objective experiment. The proposed method is the best one. Therefore, the proposed method is an efficient and practical method.
top-down attention; bottom-up attention; incremental memory; saliency map
TP391
A
1674-7720(2016)01-0045-04
崔丽娜,胡玉兰,片兆宇.基于增量记忆视觉注意模型的复杂目标识别研究[J] .微型机与应用,2016,35(1):45-48,52.
2015-09-08)
崔丽娜(1990-),通信作者,女,硕士生,主要研究方向:自适应信号处理。E-mail:cuilina_krystal@163.com。
胡玉兰(1961-),女,硕士,教授,主要研究方向:多机器人系统、人工智能、多传感器信息融合技术、系统检测技术等。
片兆宇(1980-),男,博士,教授,主要研究方向:自适应信号处理。
