森林资源一类清查与二类调查数据控制与融合研究
2016-04-12陶吉兴张国江季碧勇
陶吉兴,张国江,季碧勇
(浙江省森林资源监测中心,浙江 杭州 310020)
森林资源一类清查与二类调查数据控制与融合研究
陶吉兴,张国江,季碧勇
(浙江省森林资源监测中心,浙江 杭州 310020)
同时开展省、市森林资源一类清查与县级二类调查的地方,并存着一类清查数据和二类调查数据的加合数,出现了二套数据的现象。以浙江省森林资源为研究对象,分析了一类与二类两个调查体系的方法基础、方案设计、适用范围、数据特性和服务适用性,对一类清查与二类调查数据的控制与融合作了深入研究。阐述了一类清查对二类调查的3种不同的控制形式,一类清查与二类调查的2种融合方式,对每种控制形式和融合方式进行了实证分析,提出了各自的适用范围。
一类清查;二类调查;控制;融合;森林资源
上世纪80年代,我国形成了以森林资源连续清查为主体的国家森林资源监测体系和以森林资源规划设计调查为主体的地方森林资源监测体系[1~2]。国家森林资源连续清查,以省(直辖市、自治区)为单位,主要依据数理统计理论进行设计,采用固定样地定期复查的抽样调查方法,简称“一类清查”。森林资源规划设计调查,以森林经营管理单位或县级行政区域为调查总体,主要采用小班区划并逐块调查的方法,简称“二类调查”。
浙江省的一类清查已延伸至各设区市,对于省、设区市范围的森林资源调查,并存着一类清查与二类调查加合两种森林资源数据。在同一个调查范围,由于调查方法不同,产生了不同的数据,给数据的使用者带来了不解和不便。实现一类清查与二类调查的科学对接,是森林资源一体化监测工作中迫切需要解决的一个重大技术问题[3~4]。
1 分析综述
1.1 两个调查体系特征分析
森林资源一类清查与二类调查,从方案设计、调查方法、调查目的和服务对象等方面都不相同,两个调查体系各自所呈现的特征见表1。

表1 两个调查体系特征分析Table 1 Characteristics of the two inventory systems
1.2 现实分析
一类清查与二类调查是两个不同调查体系,因而数据不可能完全一致。聂祥永认为,森林资源监测数据的主要误差来源于技术方法、时空差异和人为因素等原因[4];曾伟生等也认为,两套数的不一致主要受技术标准、调查时间、调查质量的影响[5]。据曾伟生等研究,各省的一类清查和二类调查数据普遍相差较大,而且绝大部分是二类调查数据大于一类清查数据[6]。湖北省1999年同时进行一类清查与二类调查,二类调查的森林面积和森林蓄积均高出一类清查数据的20%以上[6];广东省2012年进行了一类清查和二类更新,一类清查林地面积1 031.83万hm2、森林面积861.52万hm2,二类调查则相应为1 097.16万hm2,1 024.24万hm2[7],林地面积二类较一类高6.3%,但森林面积相差162.72万hm2,二类较一类高18.9%。2009年是浙江省连清调查年,同时出于编制林地保护利用规划需要,将各县的“十一五”森林资源二类调查数据统一更新至2009年,结果显示,林地面积、森林面积,二类调查分别较一类清查大2.3%,5.4%,但二类的活立木蓄积较一类的小4.7%[8~9]。
以上结果显示,二类调查数据普遍偏大,特别是面积类指标;蓄积类数据则通常一类大于二类。
1.3 研究数据源
浙江省1979年建立连续清查体系,至今已完成了8次国家森林资源清查。自2004年起,建立了省级森林资源年度监测体系,采取每年复查1/3的连清固定样地方法,实现了省级年年出数;2012年起,省年度监测体系升格为省、市联动年度监测体系,在对4 252个省级样地进行全面复查的基础上,通过样地加密方法,将省级年度监测延伸到各设区市,实现了省、市联动森林资源年度出数,目前全省每年调查的样地总数已达到5 375个。
浙江省的森林资源二类调查,已完成了5次,最近完成的是“十一五”(2005-2009年)二类调查。2005年开始推动县级森林资源动态监测,努力解决县级森林资源年度出数问题,目前以26个欠发达县为主体的资源年度监测工作已进入常态化。目前正在开展新一轮二类调查,要求林木蓄积量300万m3以上的县,对二类调查结果进行抽样控制[10]。
2008-2012年,以杭州市为研究地,开展了市、县联动森林资源监测,市级采用固定样地抽样调查方法,县级采用抽取部分小班复位调查、模型推算、档案更新相结合方法,建立市级抽样控制下的县级二类联动更新森林资源年度监测体系,实现了市、县联动年年出数据[11]。
上述诸多省、市、县一类清查与二类调查数据构成了本研究的基础数据材料。
2 一类清查对二类调查的控制
2.1 控制形式
在森林资源监测中,一类清查与二类调查两个体系多数情况下独立运行、互不衔接,因而出现了两套数据。有人认为二类调查以小班为基础逐块区划调查的,应更为准确。但事实并非如此,二类调查的优势是能将数据落实到具体地点,且小成数地类数据更可靠,而总体数据及大成数地类数据,一类清查比二类调查更准确、可靠,更接近真实[6~8],且一类清查的主要指标有精度保证、区间范围。鉴此,采用一类总体数据控制二类调查数据,实践证明有效。
所谓一类清查对二类调查的控制,并非要求两个调查体系的指标数据完全相等,而是要求二类调查的指标数值落在一类清查相应指标的区间范围内,且越接近指标中值越好;若超出区间范围,则需要进行纠错、补课、调整乃至返工。一类清查对二类调查的控制,主要是林地面积、森林面积、林木蓄积、森林蓄积4个大成数指标的控制,浙江省的实践形式主要有3种。
(1)以省域为总体、各设区市为副总体,建立了以抽样调查为基本方法的省、市联动监测体系,利用省总体一类清查数据对11个副总体的一类清查数据进行控制。
(2)采用市级一类抽样调查、县级二类动态更新方法,建立了市、县联动监测体系,利用各设区市一类清查数据对所辖县的二类动态更新合计数据进行控制。
(3)在县级森林资源二类调查中,要求林木蓄积量300万m3以上的县,采用抽样控制下的二类调查方法,利用一类清查数据对二类调查结果进行控制,目前规程要求对林木蓄积量指标进行抽样控制[10]。
2.2 结果分析
2.2.1 省、市联动监测 2012年浙江省建立了省、市联动森林资源监测体系,省总体与市副总体均采用一类清查方法,至今已连续开展4 a,属于省一类数据控制市一类数据的控制类型,其主要指标监测结果见表2。表2显示,2012-2015年,11个副总体的各指标合计数均在相应的省总体指标区间内,且与其中值十分接近,说明省总体对11个副总体具有很好的控制效果。这是由于省总体与市副总体均采用一类清查方法且副总体样地是在省总体样地基础上加密而成,使得省总体对11个副总体数据的控制作用达到了非常理想的效果。
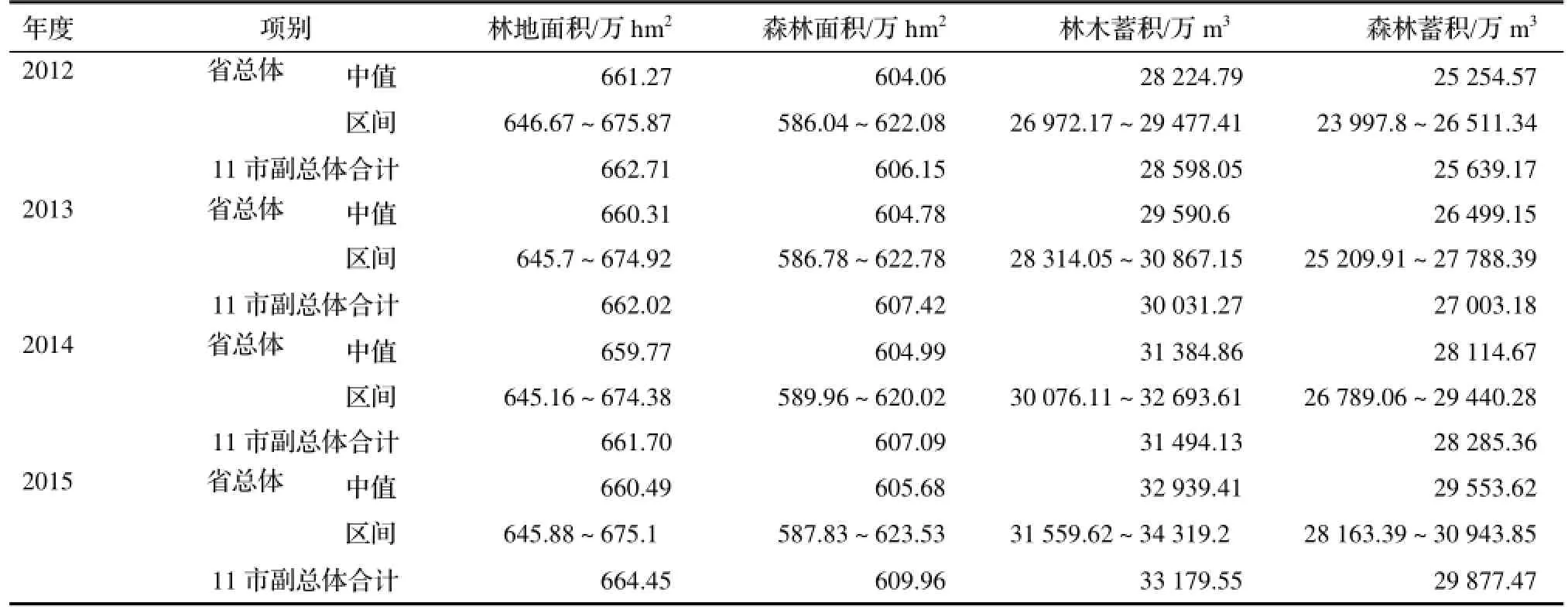
表2 省、市联动监测主要指标Table 2 Monitoring index for CFI and FMI
2.2.2 市、县联动监测 2008-2012年,选择杭州市开展了市、县联动森林资源监测研究,市级采用固定样地抽样调查方法,县级采用抽取部分二类小班复位调查、模型推算、档案更新相结合方法,建立市级抽样控制下的县级联动更新年度监测体系,其主要指标监测结果见表3。
表3显示,市对县的控制属于市一类数据对县二类合计数的控制,各年度各指标的合计数也均在相应的市总体指标区间内,但从离中值情况分析,其控制效果显然不及省一类数据对市一类数据的控制。实际工作中,如果县级二类更新合计数不在市抽样调查区间范围时,应以县为单位分析二类动态更新的工作质量,对工作质量差的县先进行整改,效果仍不理想,再整改质量次差的县,若多数县进行整改后效果还不理想,就要考虑系统误差,需对县级二类更新数据进行系统平差,使其落到市级一类指标区间内。
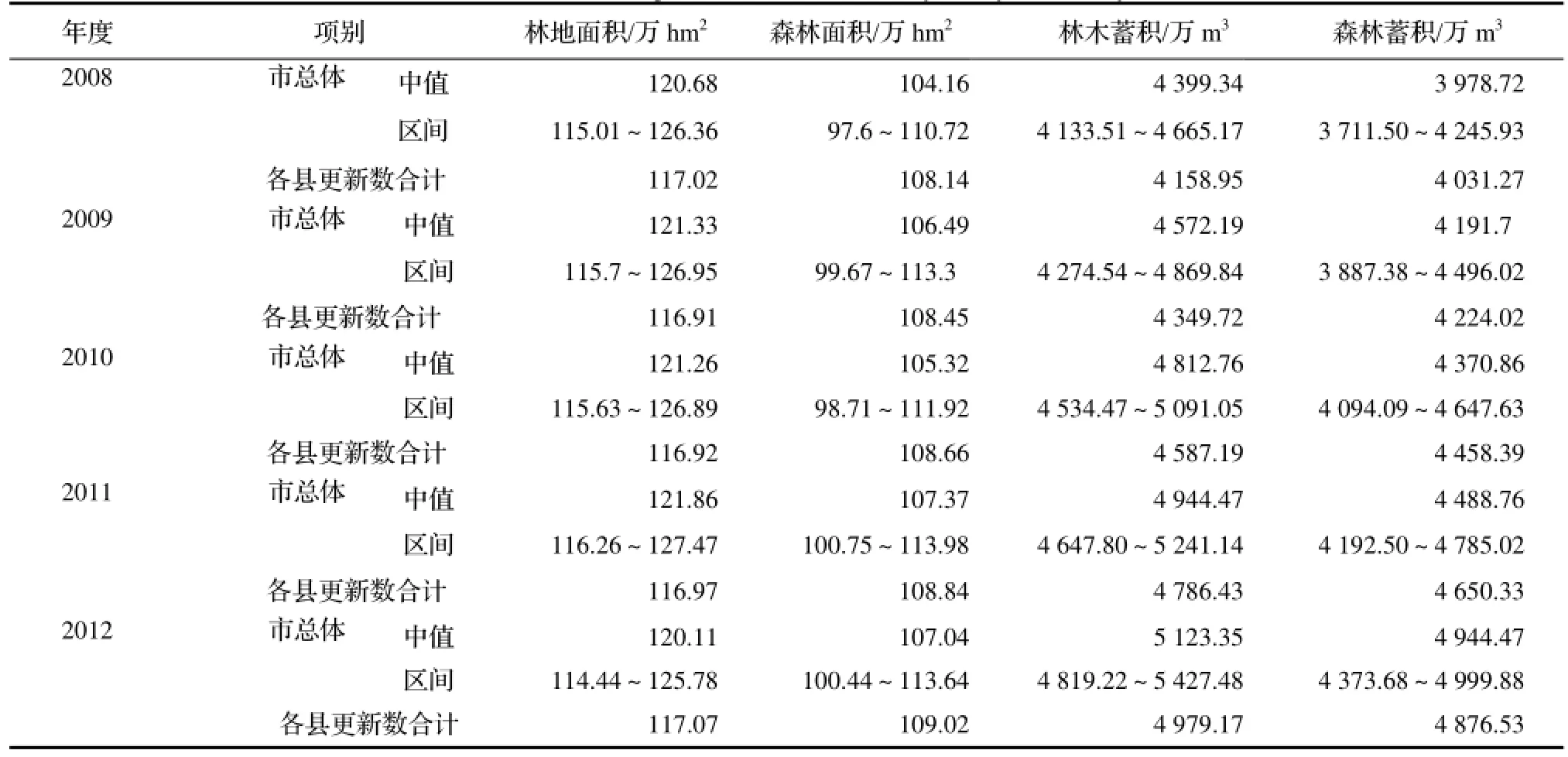
表3 市、县联动监测主要指标Table 3 Monitoring index for forest inventory of city and county
2.2.3 县级抽样控制下的二类调查 所谓抽样控制下的二类调查,即要求森林资源相对丰富的县,开展二类调查时,对其主要指标进行一类抽样控制,以防止二类调查出现系统偏差,确保二类调查结果与一类清查结果有良好对接。此时,一类清查与二类调查的时间、技术标准、调查人员应该一致,二类调查结果与一类清查结果越接近,说明二类调查质量越好。丽水市是浙江省的重点林区,辖9个县(市、区),在“十一五”二类调查时,均按要求对林木蓄积量指标进行了抽样控制,取得了良好的效果,结果详见表4。
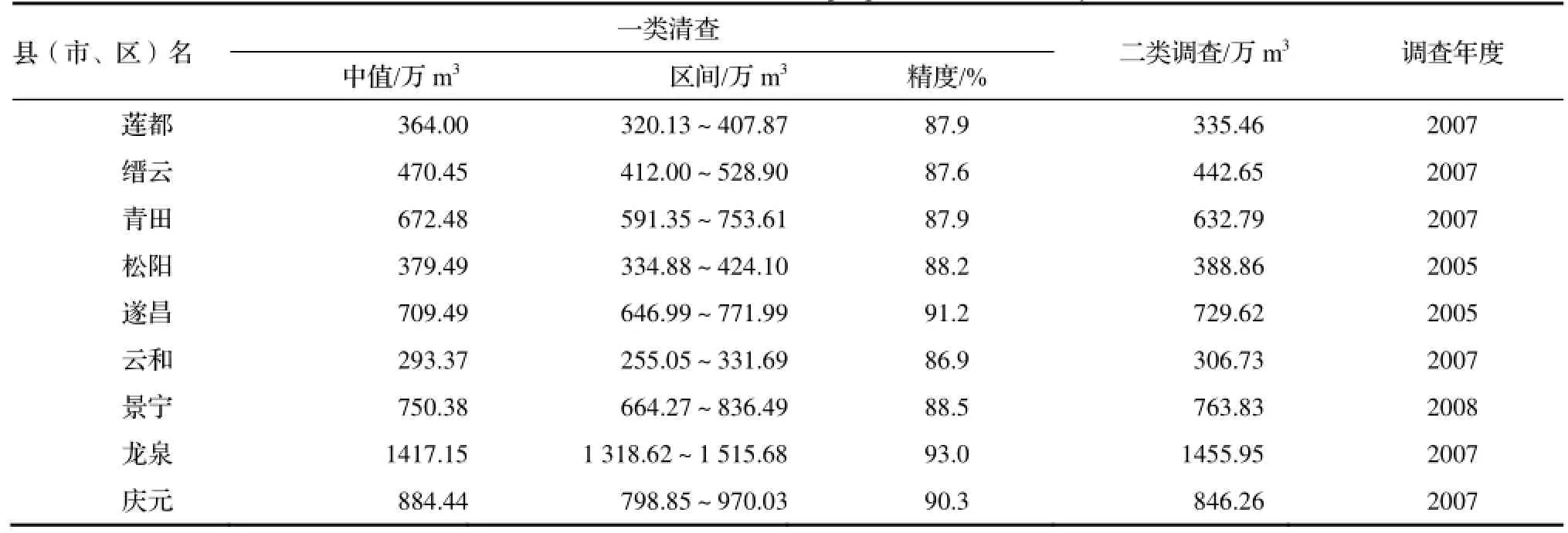
表4 县级抽样控制调查林木蓄积量指标Table 4 Forest stock in the same sample plots as CFI at county level
表4显示,丽水市辖下的9个县(市、区),其二类调查林木蓄积量均在一类抽样的控制区间范围,说明二类调查结果可信、质量较好。但各县的表现情况有所不同,莲都、缙云、青田、庆元明显低于指标中值,松阳、遂昌、云和、景宁、龙泉稍高于中值。
3 一类清查与二类调查的融合
3.1 融合方式
一类清查与二类调查的融合,根据融合环节不同,可分为数据融合与工作融合两种方式。
3.1.1 数据融合 数据融合是指当一类清查与二类调查的两套数据并存时,依据两个调查体系的各自特征,按照一定的处理规则,通过合适的方法与手段,综合出一套修正数据。
(1)一类清查是有精度保证的实测调查,且具有指标值越大精度越高的特征,林地面积、林木蓄积2个总体指标及森林面积、森林蓄积2个大成数指标,拟采用一类清查数据。
(2)二类调查不论指标值大小,其调查精度基本一致,一类清查小成数指标精度很低,除上述四大指标外的其它指标,依据二类调查结果,通过按占比摊算方法确定其指标值。
(3)具体数据融合程序。林地面积、林木蓄积、森林面积、森林蓄积4大指标按一类清查结果确定指标值;面积类指标与蓄积类指标两大体系,按照各指标的逻辑层级关系,在每一个逻辑层内先根据二类调查指标值计算各指标的占比,再根据其占比大小按逻辑层对一类清查的全额或余额进行摊算,得到经融合处理后的指标值。3.1.2 工作融合 工作融合是指二类基础年调查独立开展、形成独立的基础年数据后,在监测年二类动态更新时,利用同个年度的一类清查样地数据建立林分更新模型,再利用更新模型对二类调查小班进行动态更新,使得二类更新的小班数据中有一类清查数据的痕迹,受到一类清查结果的影响。至于二类基础年时的融合,则采用数据融合方法。
工作融合是在监测年通过一类清查与二类调查的工作协同实现,其协同点是建立二类小班数据更新模型时,采用了一类样地调查的原始数据作为建模样本,使一类清查的部分工作内容被吸纳到了二类动态更新工作之中,实际上工作融合的同时,也包含了原始调查数据的融合,使得二类动态更新结果不会与一类清查结果偏离太大。
3.2 结果分析
3.2.1 数据融合实例 以杭州市2008年完成的市、县联动森林资源基础年监测成果为例,对市级一类清查数据与所辖县二类动态更新合计数进行面积类、蓄积类指标融合,各地类标准执行《森林资源规划设计调查技术规程》(GB/T26424—2010)和《浙江省森林资源规划设计调查技术操作细则(2004年)》。结果详见表5、表6。
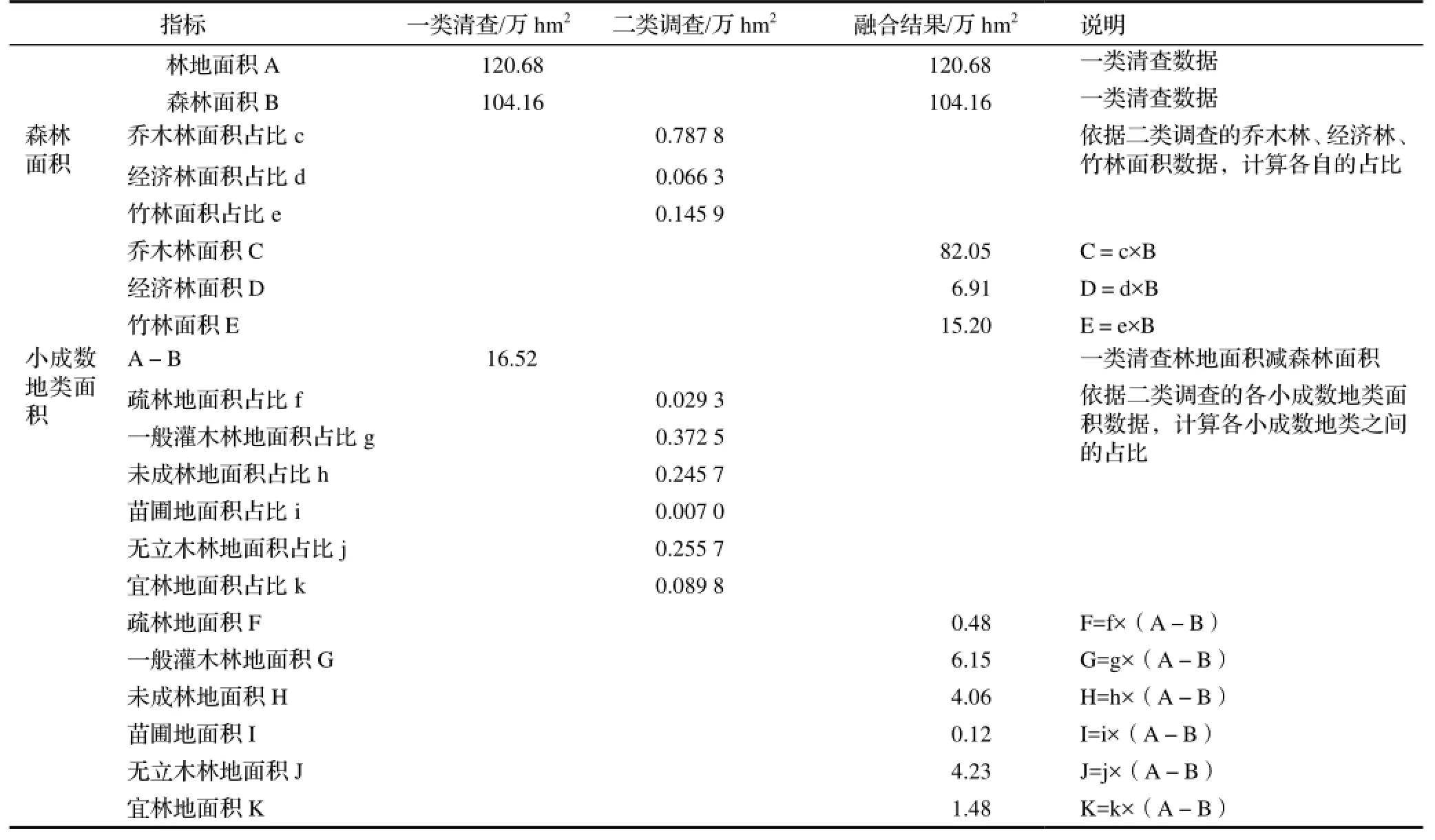
表5 面积类指标一类清查与二类调查数据融合Table 5 Data fusion of area indicators of CFI and FMI
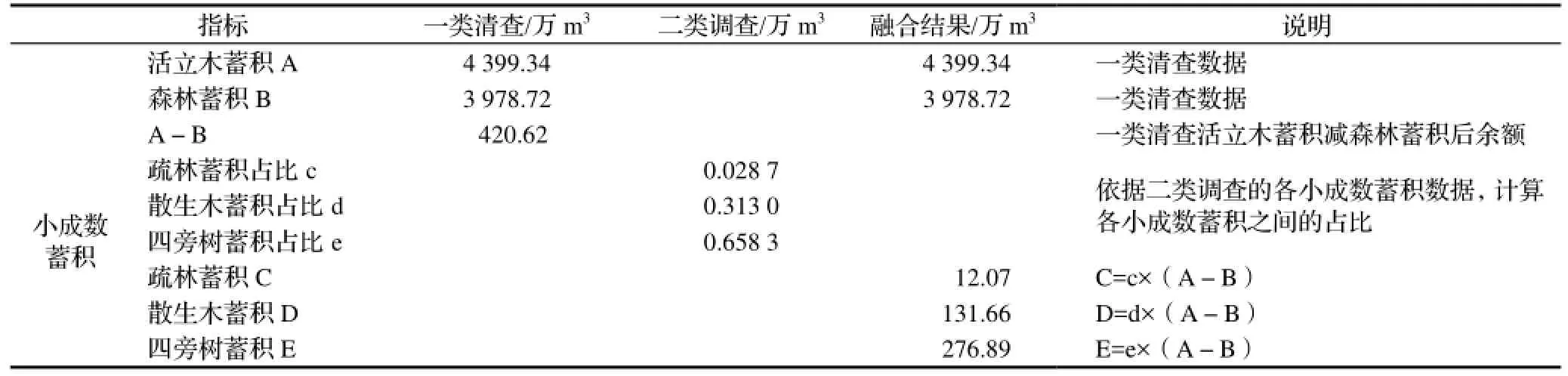
表6 蓄积类指标一类清查与二类调查数据融合Table 6 Data fusion of forest stock of CFI and FMI
表5、表6均体现了总体指标数和大成数指标数按照一类清查结果确定,小成数指标数按照二类调查数据先计算其各自的占比,然后根据占比进行分摊确定。根据这一方法,还可继续对下个层级的指标值进行分摊确定,如未成林地中,可再分解为未成林造林地、未成林封育地;无立木林地中,可再按采伐迹地、火烧迹地、其它无立木林地进行分解;宜林地中,可再按宜林荒山荒地、宜林沙荒地、其它宜林地进行分解。森林蓄积中,按林种、龄组、权属等作进一步分解。
3.2.2 工作融合实例 以丽水市为例[12],利用2014和2015年固定样地复位调查数据,筛选出两期均为乔木林的405个样地作为建模样本,建立小班林分生长率模型进行同年度的林分生长量更新。模型以林分平均胸径为自变量,以保留木进界木生长量减去枯损木消耗量后的林分蓄积年生长率为因变量,采用联立方程组模型和非线性混合效应模型方法,构建胸径与生长率混合模型的联立方程组。生长率混合模型的联立方程组结构式为:

式中,PV为当期蓄积生长率预估值,为当期林分平均胸径预估值,Dpre为前一年林分平均胸径,龄组、起源、树种组的随机效应参数值见表7。

表7 生长率模型随机效应参数值Table 7 Parameter value of random effect for growth rate model
将表7的随机效应某一类目值代入联立方程组结构式,即得到不同胸径、龄组、起源、树种组的林分生长率预测值,实现了抽样外业调查工作与小班生长率模型建模样本采集工作的融合。同时,抽样调查生长率监测结果对模型更新的生长率起控制和检验作用,也实现了抽样监测生长率控制数与数学模型生长率更新结果分析与控制的工作融合[13]。
4 结论与讨论
在一类清查与二类调查体系已经存在的情况下,重新采用一个新的体系不大现实,进行协调处理才是明智的做法。为此,针对一类清查与二类调查数据的协调性问题进行了探索研究,提出了控制与融合的基本思路和方法。
(1)一类清查与二类调查是两个调查体系,调查因子及统计指标很多,结构体系复杂,保证所有统计指标特别是成果统计表的协调统一,几乎不可能,因此妥协兼顾十分必要。目前的处理方法能做到主要指标数据或一级指标数据相协调,但进一步细化的结构性统计表,如乔木林面积蓄积按龄组统计表等含有多个统计因子交叉组合的表格,很难做到协调统一。
(2)一类清查与二类调查的协调结果存在着两种情况,一是两套数据调整成一套数据;二是使二类调查结果落在一类调查允许的区间范围内,使两套数据得到较好对接。在实际工作中,应根据不同的情况做出具体的分析与选择。
(3)一类清查数据与二类调查数据不能同等对待,要分清情况,主次有别[14]。通行的做法,总体数据与大成数指标数,即主要资源数据依据一类清查直接确定;小成数指标数,依据二类调查数据通过占比分摊方法确定。尽管如此,分摊的工作量可能很大,只能停留在一级指标的分摊上,如再进一步细分到起源、林种、龄组、树种组等,就不可能保证完全统一了。另一种较少采用的方法,以二类调查数据为基础,小成数指标数据由二类调查直接确定,大成数指标数据根据一类清查结果进行修正,经修正后的二类数据落到一类数据允许的误差限范围,两套数据虽不一致但也相协调。
(4)在森林资源一体化监测工作中,同个行政区范围的一类清查与二类调查融合,基础年适合数据融合方法,监测年适合工作融合方法。
[1] 林业部. 关于建立全国森林资源监测体系有关问题的决定[J]. 林业资源管理,1989,(5):3-5.
[2] 肖兴威. 中国森林资源与生态状况综合监测体系建设的战略思考[J]. 林业资源管理,2004,(3):15.
[3] 闫宏伟,黄国胜,曾伟生,等.全国森林资源一体化监测体系建设的思考[J].林业资源管理,2011,(5):6-11.
[4] 聂祥永.森林资源监测成果数据的差异与误差问题研究[J].林业资源管理,2013,(1):32-37.
[5] 曾伟生,周佑明.森林资源一类和二类调查存在的主要问题与对策[J]. 中南林业资调查规划,2003,22(2):8-11.
[6] 曾伟生,程志楚,夏朝宗.一种衔接森林资源一类清查和二类调查的新方案[J]. 中南林业调查规划,2012,31(3):14.
[7] 李清湖,余松柏,薛春泉,等.不同森林资源监测体系数据协同性初步分析——以广东省为例[J]. 中南林业调查规划,2013,32(4):16-19.
[8] 翁卫松,徐达,谭莹,等. 基于高分辨率影像的城市和平原绿化调查技术研究[J]. 西南林业大学学报. 2013(05):78-82.
[9] 浙江省林业厅. 浙江省林地保护利用规划[R]. 杭州,2013.
[10] 浙江省森林资源规划设计调查技术操作细则[S]. 杭州:浙江省林业厅,2014.
[11] 陶吉兴,季碧勇,张国江,等. 浙江省森林资源一体化监测体系探索与设计[J]. 林业资源管理,2016,(3):28-34.
[12] 陶吉兴,季碧勇等. 浙江森林资源一体化监测理论与实践[M]. 北京:中国林业出版社,2016.
[13] 徐军,谭莹,吴伟志,等. 浙江省森林资源监测数据分析及预测[J]. 浙江林业科技. 2013,(03):43-46.
[14] 李炳凯.全国森林资源清查和规划设计调查结果的比较及其使用[J]. 浙江林业科技. 2005,(06):37-39.
Research on Data Control and Fusion of Continuous Forest Inventory and Forest Management Inventory
TAO Ji-xing,ZHANG Guo-jiang,JI Bi-yong
(Zhejiang Forest Resources Monitoring Center, Hangzhou 310020, China)
Data are different from continuous forest inventory (CFI) and forest management inventory (FMI) in the same place. Analysis was made on difference between CFI and FMI in terms of method, scheme design, application, data characteristics and services in Zhejiang province. Descriptions were made on three different control forms of CFI data on FMI one, and two fusion methods of CFI on FMI. Empirical analysis was carried out on each control form and fusion method, and their scope of application.
continuous forest inventory; forest management inventory; control; fusion; forest resources
S757.2
A
1001-3776(2016)06-0008-07
2016-06-23;
2016-09-28
国家林业局“全国森林资源年度监测试点”项目(资调函[2014]53号)
陶吉兴(1963-),男,浙江绍兴人,教授级高工,从事森林资源调查监测与规划评估工作。
