基于GPU的并行MSD算法研究
2016-04-09李梓博单福悦
李梓博,单福悦,高 宁
(中国人民解放军63778部队,黑龙江 佳木斯 154002)
基于GPU的并行MSD算法研究
李梓博,单福悦,高宁
(中国人民解放军63778部队,黑龙江 佳木斯 154002)
摘要通用计算机的遥测信号处理系统通用性、灵活性强,不受硬件平台限制,便于开发、升级和维护,能够有效克服传统硬件平台的不足。多符号检测(MSD)算法性能优良,具有计算量大、并行度高的特点,适合在通用计算机上进行处理。针对如何提高处理速度,在通用计算机平台上研究基于图形处理器(GPU)的并行MSD算法,通过使用GPU对MSD算法并行加速,提高算法运算效率。实验结果表明,在同样条件下,基于GPU的并行MSD算法较串行算法最大可提速约134倍,能够有效提高处理速度。
关键词PCM/FM解调;多符号检测;GPU;并行计算
Research on Parallel MSD Algorithm Based on GPU
LI Zi-bo,SHAN Fu-yue,GAO Ning
(Unit63778,PLA,JiamusiHeilongjiang101416,China)
AbstractThe telemetry signal processing system based on general-purpose computer has multiple advantages which can effectively overcome the shortcomings of current hardware devices,such as high versatility and flexibility,low cost,no limits of hardware platform,and easy upgrade and maintenance.The multi-symbol detection(MSD)algorithm has such characteristics as large computing and high parallelism and better performance,and it is suitable for processing on a general-purpose computer.For the method to improve processing efficiency,this paper studies parallel MSD algorithm based on GPU on general-purpose computer platform.The results show that the processing speed of parallel MSD algorithm is about 134 times higher than sequential algorithm.
Key wordsPCM/FM demodulation;MSD;GPU;parallel computing
0引言
脉冲编码调制/调频(PCM/FM)体制相较于其他遥测体制,具有能量效率高、灵活性强、精度高和抗噪声性能好等优势,这些优势使得PCM/FM体制广泛应用于航天遥测领域中[1]。PCM/FM信号具有相位记忆性,即信号当前相位不仅仅与当前符号有关,而且受已发送的所有符号的影响[2]。MSD算法将接收信号码组与所有可能的参考信号码组做相关运算,使得相关运算结果最大的参考信号序列即为最优判决序列。该算法充分利用前后码元之间的相位信息,可以实现更高精度的PCM/FM信号解调,提高解调处理增益,从而降低解调门限。其内部包含有大量并行乘加运算,非常适合使用并行计算技术对其并行优化。
本文将MSD算法与通用计算机平台相结合,在通用计算机平台上通过GPU对其并行优化,加快算法的运算速度,提高运算效率。
1MSD算法原理及计算量分析
设s为接收信号包含信息,r为接收信号解得信息,r(t)为接收信号,则错误概率可表示为:
pε=p(r≠s|r(t))。
(1)
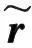
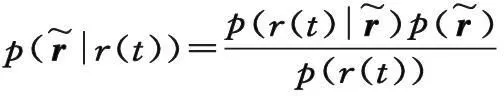
(2)

(3)


(4)

(5)
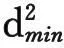

(6)
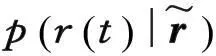

图1 MSD算法原理
MSD算法的计算过程即是一连串的求相关运算,若每个码元内包含Ns个采样点,每次判决结束向后滑动一个码元长度,则对于包含L个码元的信号来说,共有L-N+1次MSD运算,每次有N×Ns个采样点参与。那么在求相关过程中,共有4×N×Ns×2N次乘法,(4×N×Ns-2)×2N次加法;求模平方过程中,共有2×2N次乘法,2N次加法。则单次MSD算法共有(4×N×Ns+2)×2N次乘法,(4×N×Ns-1)×2N次加法。
2串行MSD算法
进行一次MSD判决,最终需要得到的即是与接收信号序列具有最大相关结果的本地参考序列。对于每一个接收信号序列,共有2N个实部相关结果和2N个虚部相关结果,对它们求模得到2N个模值,从中可判决出最大模值及其对应本地参考序列的通道号。具体实现步骤如下:
① 计算接收信号序列与每一个本地参考序列对应的实部与虚部相关值;
② 由步骤①中相关值求得对应模值,选出其中的最大值及其对应本地参考序列通道号;
③ 重复调用步骤①和步骤②,直到全部计算完成。
串行MSD算法流程如图2所示。
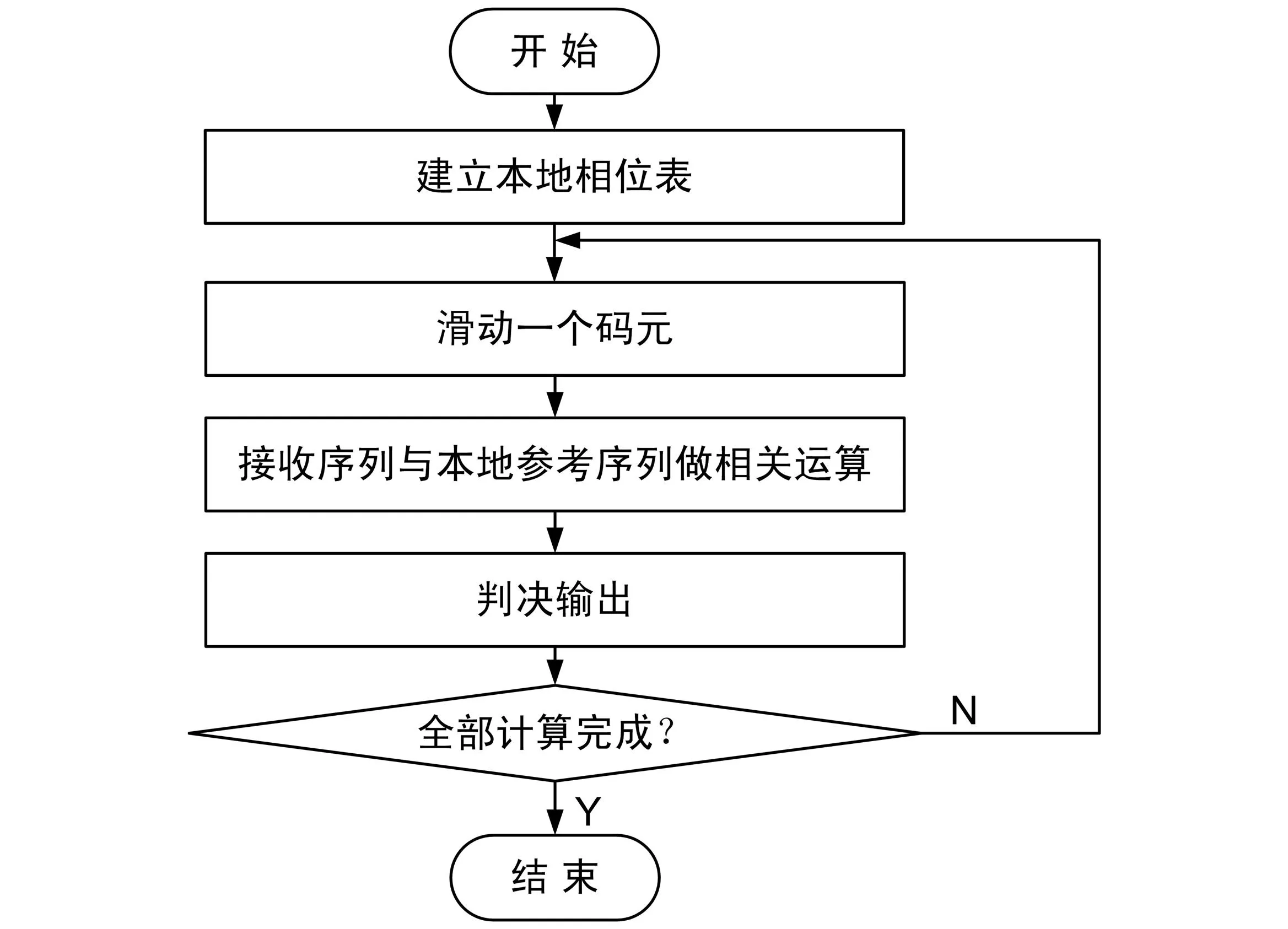
图2 串行MSD算法流程
随着观测长度的增加,MSD算法计算量呈指数增长,采样率56 MHz的信号每秒也将产生大量待处理数据。串行MSD算法需要消耗大量的时间,不利于处理效率的提高。同时需要注意到,MSD算法将接收信号与2N组本地参考信号相乘,积分累加并求模平方,得到2N个对应似然值,但这2N组计算之间是独立不相关的。
由于计算资源及能力的限制,串行MSD算法逐次计算的方式效率较低。考虑到每次MSD算法计算过程中,接收信号与本地参考信号的相关计算过程是相互独立的,每次滑动所得到的接收信号序列也是相互独立的,故可将接收信号分为若干段,并行地进行MSD判决。
3基于GPU的并行MSD算法
GPU拥有海量计算核心,在处理大规模并行数据计算中存在与生俱来的优势,极其适合承担并行计算任务、提高MSD算法计算效率[5]。CUDA是由NVIDIA公司推出的一种通用并行计算架构,采用单指令多线程体系结构,为访问GPU提供了直接的硬件接口,使用标准C语言及其扩展即可进行软件开发与研究[6]。下面对CUDA编程模型及GPU体系结构做一个简单概述。
CUDA编程模型如图3所示[7]。

图3 CUDA编程模型
CPU作为Host,负责逻辑性强的事务处理和串行运算,与负责处理高密度并行运算、作为Device的GPU协同工作。有CUDA程序被执行时,首先由Host执行CPU代码,当有任务需要GPU处理时,Host将向Device发起Kernel函数。在此之后,Host继续完成自己的工作,直到Device计算完成,Host将从中获取计算结果并进行下一步处理。
Kernel是运行在GPU上的CUDA并行计算函数,它是CUDA中一个可被并行执行的步骤。Kernel函数以及Kernel之间进行的串行计算由CPU负责调用。每个Kernel由GPU里的海量Thread并行执行。Thread的规模和结构由block和Grid决定,其中,block为Thread的集合,Grid为block的集合。每个Kernel中存在2个层次的并行,即block中Thread之间的并行与Grid中block之间的并行。
在基于GPU的并行MSD算法中,由CUDA中block的每一个thread负责一次MSD计算。对于一个长为L的信号,共有L-N+1个thread被发起。以2N个本地参考序列的组合为单位,可将需要计算的所有本地参考序列放入GPU缓存中,提高计算效率,如此可最大化地利用GPU中的thread资源来进行并行计算。基于GPU的并行MSD算法流程如图4所示。

图4 基于GPU的并行MSD算法流程
4性能测试
单次MSD算法计算量表明,若本地参考信号长度增加,计算量将会呈指数增长。由Nyquist采样定理,可通过对接收信号适当重采样,减少单个码元内采样点数Ns,有效降低计算量。根据文献[8]的结论,本文将重采样后的Ns取值定为7。
使用配置有Intel Xeon E5-2640 CPU,NVIDIA Tesla K20c GPU的通用计算机对并行加速性能进行测试。通过在重采样前后选取不同MSD观测长度,测试系统计算效率。实验数据如下:采样率fs=56 MHz,码速率Rb=2 Mbps,重采样前后每个码元分别包含28个和7个采样点。实验结果如表1和表2所示。

表1 重采样前并行加速效果

表2 重采样后并行加速效果
表1和表2表明,信号重采样后,随着采样点数的减少,单次MSD计算时间明显减少,但加速比却有所降低。这是由于在观测长度较小时,GPU上的计算资源尚未被充分利用;而当观测长度较大时,由于计算量的增加,GPU的计算能力逐渐饱和,达到了更高的计算资源利用率。以N=9为例,重采样后并行MSD算法较重采样前串行MSD算法,加速约408倍,取得了极为可观的加速比。
5结束语
本文围绕PCM/FM遥测信号解调,针对MSD算法计算量大、并行度高的特点,在通用计算机平台上使用GPU对其并行加速。并行优化后,并行MSD算法的计算效率较串行最高可提速约134倍。重采样后并行MSD算法运行效率是重采样前串行MSD算法的408倍。测试结果表明并行加速效果显著,能够极大地缩短MSD算法的处理时间,提高系统处理速度。下一步将结合多GPU并行技术等,进一步提高系统计算效率。
参考文献
[1]严匡武.PCM/FM再入遥测信道波形设计方法研究[D].成都:电子科技大学,2005.
[2]RICE M,SATORIUS E.Equalization Techniques for Multipath Mitigation in Aeronautical Telemetry[C]∥Military Communications Conference.MILCOM.IEEE,2004:65-70.
[3]盛骤,谢式千,潘承毅.概率论与数理统计(第4版)[M].北京:高等教育出版社,2010.
[4]刘毅.CPM 信号载波同步研究[D].西安:西安电子科技大学,2008.
[5]刘培志,宿红毅,罗壮,等.面向海量数据高性能计算的cpu/gpu协同处理方法[P].中国:CN102708088 A,2012.
[6]赵炳财.基于GPU技术的并行运算应用研究[D].长沙:国防科学技术大学,2012.
[7]张舒,褚艳利.GPU 高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
[8]李梓博,侯孝民,郑海昕,等.基于MSD的PCM/FM信号解调参数性能研究[J].无线电工程,2014,(8):38-40.
李梓博男,(1991—),硕士,助理工程师。主要研究方向:航天测控。
单福悦男,(1983—),工程师。主要研究方向:航天测控。
作者简介
收稿日期:2015-11-17
中图分类号V556.1
文献标识码A
文章编号1003-3106(2016)03-0026-04
doi:10.3969/j.issn.1003-3106.2016.03.08
引用格式:李梓博,单福悦,高宁.基于GPU的并行MSD算法研究[J].无线电工程,2016,46(3):26-29.
