一种基于SOM网络预测剩余油分布的方法
2016-03-22鄢栋云
鄢栋云
摘要:该文针对基于地球物理的勘探方法不能有效地定量预测剩余油,提出了一种基于SOM网络的方法来预测剩余油。本文阐述了SOM网络的工作过程、算法的训练过程以及SOM网络聚类的方法。通过对含油饱和度敏感的属性进行聚类分析,可以及时预测剩余油的分布,对提高石油产量具有非常重要的现实意义。
关键词:剩余油;SOM网络;聚类分析
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)02-0161-02
Abstract: This paper is aimed at the exploration methods which are based on geophysics can not predict the remaining oil accurately and quantitatively, a method which is based on SOM network is approached to predict the remaining oil. The paper briefly introduces SOM network work process, algorithm training process and cluster method. Through the sensitive attribute of oil saturation for clustering analysis, can predict the distribution of remaining oil in time which has very important practical significance to improve the oil production.
Key words: Remaining Oil; SOM Network; Clustering Analysis
随着经济的发展,生活水平的提高,人们越来越离不开石油。在常规的油田预测中,一般用井中地震数据随时间的变化研究油田的动态变化,如油田中剩余油的变化。常规油田监测方法有一定局限性, 它无法获得大量井间信息。现阶段我国各大油田较易开采的工区几乎被开采殆尽,较难开采的工区仍然有大量石油剩余。国家历来重视较难开采工区剩余油的分布作出测,一些传统的勘探方法无法有效定量预测工区中剩余 的石油,这一直是地质工作者和专家关注的焦点。因此,迫切需要一些新的方法对较难开采的工区中剩余油进行预测,以便提高石油采收率,从而增加石油油产量,为国民经济发展作出贡献。近来越来越多基于神经网络的方法应用到剩余油预测的领域中,这些方法在一定程度上获得不错的效果。因此本文引入自SOM网络,利用其学习和自适应能力强的优点,并利用SOM聚类的方法实现对剩余油的分布作出预测。该方法不仅能够对剩余油进行定量分析,而且还可获取剩余油的分布情况。
1 SOM网络简介
SOM(Self-Organizing Map)是自组织神经网络的意思,由芬兰学者Kohonen在20世纪80年代初期模拟真实存在的生物神经系统,并且结合前人在20世纪70年代的工作建立了的,因此也称为Kohonen映射。
Kohonen映射的结构可以认为是由输入层和输出层构成的双层网络,其拓扑结构是网络上的所有神经元接受不同刺激时做出不同的反应,即不同形式的兴奋状态下形成的整体。双层网络之间连接是通过一系列的权值实现的,如果这些权值变得收敛或者相对稳定,输出层的某个神经元上就会接受到来自输入层的信号,这就是SOM网络多维数据聚类的基础。SOM网络的聚类性质是按几何特征进行的,一般以几何中心作为参照,此外SOM具有很强的自组织学习能力。
SOM网络在无监督的学习方式由以下几个机制组成:
1)竞争机制:映射中的神经元计算所有输入的信号(也称为模式),分别得到它们判别函数的值,为神经元之间的竞争提供了基础。网络中输出层的神经元之间互相竞争以求被激活,任一时刻都有且只有一个神经元被激活,这个神经元称之为竞争获胜神经元,竞争过程中选择胜利者的标准是具有判别函数最大值的特定神经元。
2)协作机制:兴奋神经元的拓扑邻域的空间位置是由成为胜利者的神经元所决定的,提供了类似的相邻神经元协作的基础。
3)权值的调节机制:兴奋神经元通过对它们权值的适当调节,以增加其关于该输入模式的判别函数值。所做的调节增强了成为胜利者的神经元对以后相似的输入模式的响应。
2 SOM算法
设δij 是输入层各个节点i到输出层的神经元j的连接权向量, λ=(λ1,λ2,…,λn)是一个输入为n维的向量。SOM算法如下:
1)初始化。对输出层的各权向量δij随机赋值,范围在0到1之间,其中δij的值两两不相等。
2)接受输入。从输入集中随机选取一个模式,并对其做归一化处理。
3)计算神经元的激活值。即寻找胜利者的神经元。从初始输入集按一定的方式选取初始网络训练样本集φ,对每一输入向量λ(λ∈φ), 使用欧几里得距离作为不相似性度量, 计算输出层各神经元的激活值。
5)接受新的输入,重复步骤(2)(3)(4)直到到达预设的循环次数为止,即可完成SOM神经网络的训练。
3 预测工区中剩余油
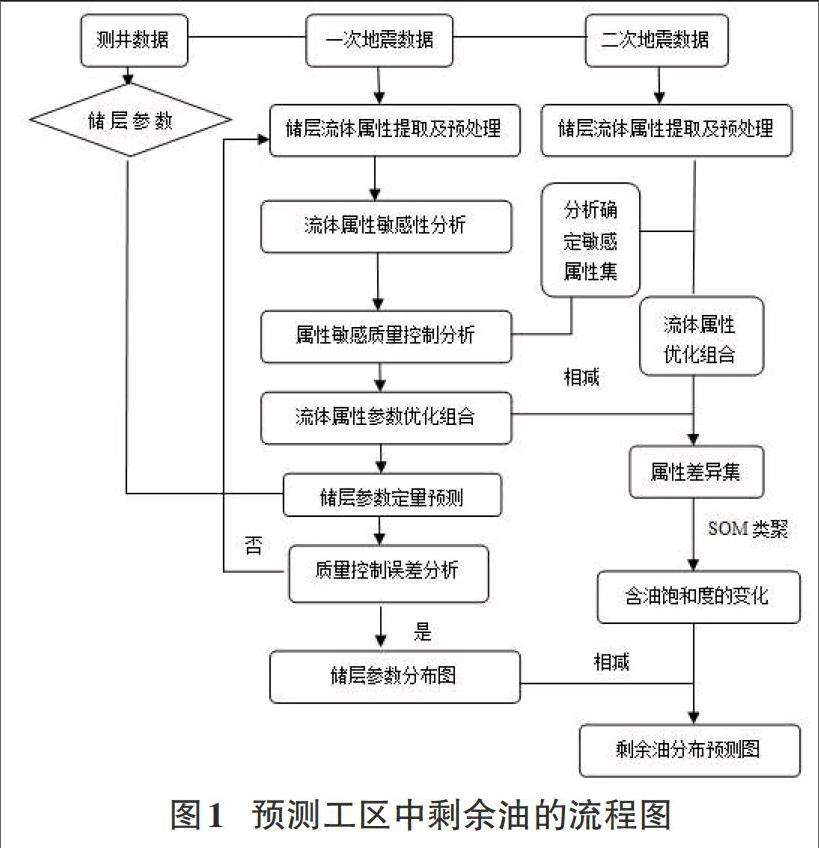
利用SOM聚类分析的特点,将时移地震数据与一次地震数据分别做一系列的处理,然后比较其中的差异,即可得到工区中剩余油的分布。如图所示,大体可分为以下4个步骤:
1)优选出对含油饱和度敏感的属性
首先对工区中所有井进行勘测获得其基本的储层参数,即原始含油饱和度。经过一段时间的开采,分别在两个不同的时间对所有井进行勘测,第一次获得数据称为一次地震数据,第二次获得的数据称为二次地震数据,也称时移地震数据。然后对一次地震数据做加权平均计算出每个储层井点含油饱和度的原始值,其中不乏一些差异较大的值,根据统计储层参数的分布的真实性去除这些异常值,并把其他的值作为样本。在样本中提取储层的流体属性并进行预处理,优选出对含油饱和度敏感的流体属性。
2)储层参数预测的预处理
为了简化处理工作,对优选出的敏感属性进行降维压缩,以便获取压缩的敏感属性集合。SOM网络的输入节点是压缩后的敏感属性集,输出节点为统计的储层参数。经过网络的训练,得到模式识别的参数,结合降维后的敏感属性压缩集合来预测储层参数的分布情况。
3)工区的预测结果校正
对原始预留的样本和测井数据拟合地理几何信息进行检验,若预测的效果跟实际情况不符合,应重新提取和处理储层流体属性,直至重新预测的结果跟实际情况相差无几。
4)多属性的SOM聚类差异化
获得时移地震数据后,首先提取其中的敏感性流体属性并对它做预处理,分析敏感性流体集合,并对该集合做优化处理。将时移前后的敏感流体属性优化组合相比较,可以得出属性差异集。再将该差异集进行SOM类聚处理可以得出时移后的含油饱和度的变化图,与时移前储层参数分布图相比较,得到剩余油分布的预测图。
参考文献:
[1] 高兴军,于兴河,李胜利,等. 利用神经网络技术预测剩余油分布[J]. 石油学报,2005(3):60-63.
[2] 石小松,程国建. BP神经网络在剩余油分布预测中的应用研究[J]. 电脑知识与技术,2008(36):2706-2708.
[3] Kai Xie, Zhijun Bai, Wenmao Yu,Fast Seismic Data Compression Based on High-efficiency SPIHT, ELECTRONICS LETTERS,50(5), pp365-366,2014.
[4] 丁露,崔平.SOM聚类算法在文本分类上的应用[J]. 现代情报,2007(9):162-164.
[5] 于鷃.基于一维SOM神经网络的聚类及数据分析方法研究[D].天津大学,2009.
