构建基于文献信息网络的知识发现系统应用模型的设想
2016-03-22,,,,
,,,,
文献的海量增长使知识发现和有效利用愈发困难,基于文献进行知识发现,是未来文献服务的重要方向。传统的文献检索平台能够帮助用户快速查找与定位目标文献,但检索到的候选文献数量依然庞大。要从大量的候选文献集中获得有效的知识,仍然需要经过人工的阅读分析,费时费力甚至难以实现。文献蕴含的知识并不是孤立存在的,它们之间存在千丝万缕的联系,既包括人们可利用数据库检索到的显性联系,如文献直接报道的生物分子关系[1]、互相引用的文献之间主题内容上的相关性[2],也包括常规的数据库检索不出的隐性联系,如很多文献虽互不引用但却存在对相同问题的阐述。这种文献中的隐性关联的挖掘比信息本身的增长更有意义。
基于文献的知识发现研究是通过潜在的关联挖掘来推断出新的科学假设[3]。本文主要探讨关联知识的图结构组织对文献知识发现的作用,并建立文献信息网络的知识发现系统应用模型。
1 基于复杂网络的文献知识发现
基于文献的知识发现理论(Literature-based Discovery,LBD)是由Swanson教授最早提出的。其基本原理是如果有两类文献集As和Cs,其中As主要讨论了概念A和概念集B之间的关系,而Cs则讨论了概念C和概念集B之间的关系,但是没有任何文献直接讨论概念A和概念C的关系,那么A与C之间通过共同的桥梁B,隐含地存在某种关系,这是一个新的科学发现[4]。在Swanson关于雷诺氏病和食用鱼油的假设中,A代表食用鱼油,B代表血液和循环系统的一系列变化,即血液粘稠的降低、血小板聚集的降低及血管收缩的减少,C代表雷诺氏病,未知的外部循环混乱。由已知文献可得出两个结论:一是食用鱼油可以引起特定的血管变化,即A引起B(A,B);二是同样的血管变化可改善雷诺氏病,即B引起C(B,C),由ABC模式得出假设:A引起C,即雷诺氏病与鱼油之间有一定联系,食用鱼油可能对雷诺氏病有治疗作用[5]。
大量文献集聚会使研究内容的相关性呈现出一个关联知识网络,如果将文献集转化为基于网络模型存储管理的结构化知识库,可以进一步通过知识网络进行关联挖掘,提高知识发现的效率。如通过对文献中关键词共现网络的研究,可以帮助我们总结出当前的研究热点、分析科研结构、发现研究内容的相关性等[6-7]。还有一些工作开始从系统层面上考察信息间的整合分析,通过多领域多数据源交叉融合,发现间接的隐含联系[8]。此外,文献[9]报道了利用文献衍生的生物医学实体关联网络进行科学研究结构与相关性的挖掘分析,研究主题和研究内容之间关联的紧密程度非常高。在同一个大的研究领域中,从一个研究对象可以很快转移到另外一个研究对象,两者结合很容易形成新的研究内容,从而促使不同领域研究对象之间可以相互借鉴,使科研人员获得好的科研思路,这也从网络的角度验证了基于文献的知识发现的思想。
早期基于文献的知识发现方法涉及大量的人工对文本的统计分析操作,文本分析的数据集多控制在文献的标题。随着文本挖掘技术的快速发展,基于文本挖掘方法的文献知识发现研究在科学发现中得到了越来越广泛的应用。然而,基于文献的知识发现过程实际上是一个启发式的过程,获得的潜在关联知识需要进一步确证的假设,不同种类、不同相关程度的关联都可能是激发新假设的有用知识,于是对文献蕴含的各种关联知识的便捷导航访问便显得至关重要。因此,基于复杂网络模型整合大量文献数据,将文献集转化为基于网络模型存储管理的结构化知识库,对获取新的知识具有重要意义。这不仅是一种可行的方法,而且具有更强的操作性。
2 文献的信息网络建模
2.1 文本处理
非结构化的文献必须利用自然语言处理技术对其进行文本处理,将非结构化的文本转化为结构化的数据集,以便后续进行深入的数据挖掘。结构化处理的核心是提取文献中能用于关联发现的知识单元,在自然语言文本中最有用的莫过于有意义的名词或名词短语。一般来说,生物医学文献中最有价值的是各种描述生物医学领域的专业术语,即生物概念或实体。因此,在生物医学文献挖掘领域,绝大多数文献挖掘工作的一个必不可少的步骤就是从文献中识别出感兴趣的命名概念或实体,即从文献中获得生物医学工作者所感兴趣的专业实例和术语,包括基因、蛋白质、细胞、化合物和药物等。文本处理的基本过程主要包括分词、词性标注、短语识别、停用词去除、词干提取和命名实体识别等(图1)。
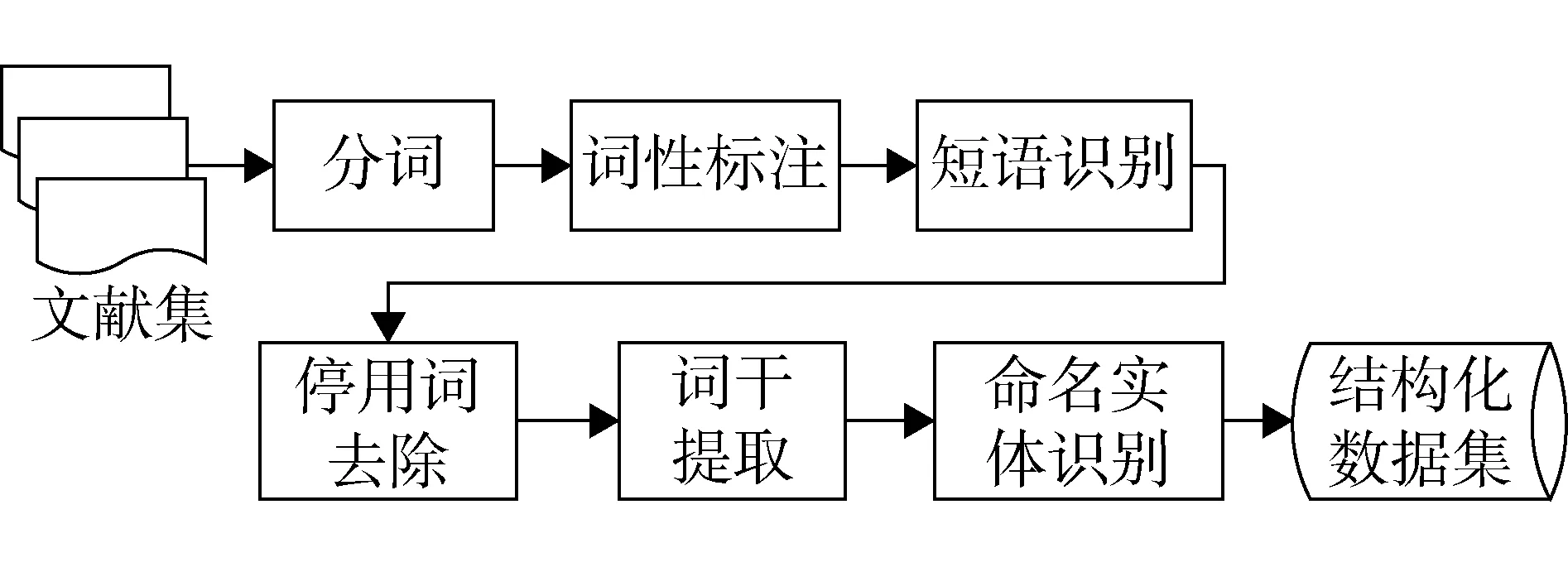
图1 文本处理的基本步骤
分词:将句子还原为单词序列。其目的是识别文本数据中的句子和单词边界,为词性标注和实体识别提供统一的输入数据。
词性标注:将文本分成单词之后,需要再对单词的特征进行分析,确定每个单词的词性。词性用来描述一个词在上下文中的作用,例如描述概念的名词、下文中引用名词的代词等。词性标注就是为给定句子中的每个词赋予正确的词性标记。
短语识别:识别出句子中多个单词组成的有意义的短语单元。短语识别可以借助于自然语言处理中的句法分析技术,也可以借助于概率统计的方法。如两个单词经常共同出现,两者很可能是一个短语。
停用词去除:停用词是指在文档中出现次数很多而本身没有实际意义的词, 例如英文中的大部分介词、冠词等。通常需要针对特定领域文献集的特点,制定一部分相应的规则,人工建立一个停用词表对候选词进行过滤。
词干提取:是去除词缀得到词根的过程,包括词干化与词形还原两种方法。前者是通过一定的规则提取词干,后者是通过完全的形态分析并借助词典得到词的精确词形。
命名实体识别:命名实体是一种标识了某个概念或实体的短语,如专有名词、人名、地名等。命名实体识别主要是提取短语并识别后得到名称短语。
直接利用自然语言处理的方法,从文献中提取以名词短语为基础的概念实体,不针对特定的生物医学实体,不但能提取到文献关键词,而且可以尽可能地收集到文献中出现的实体,以满足通用性和覆盖率的要求。
2.2 信息网络构建
通常一个简单的无向无权网络,可记为G=(V,E),其中集合 V 称为节点集,V={v1,v2,…,vn},集合E称为边集,E={e1,e2,…,em},任意一条边对应一个节点的二元组:ex=(vi,vj),E是V ×V的一个子集。对于用节点和边描述的图,可以用节点的度、连通性与路径等几个定量指标来描述图的性质。
节点的度:节点V在图G的度是指图G中与节点V连接的边数,记为d(v)或k(v)。节点的度主要用于描述节点的连通性。
连通性:若G中每对不同节点u,v之间都至少存在一条通路,则称G是连通的,即G为连通图。
路径:图的路径是指连接两个节点的节点与边交替出现的序列,且所有节点与边都不相同。路径长度是连接两个节点之间的边的数量,网络距离可以通过路径长度来描述,通常用最短路径作为连接两个节点的路径。
信息网络是将文献集中的内容相关性转化为基于关联信息存在的图结构数据模型,根据文献中的语义单元即概念实体及其关联信息,对文献中所蕴含的知识进行网络结构化。信息网络的构建分概念实体及其关联的抽取和实体、关联及内容链接的结构化管理两个步骤。在文献信息网络G=(V,G)中,节点集V是各种从生物医学文献中提取出的实体的集合,如基因、蛋白质、化合物或疾病等;边集E 是实体之间的关联集合,且边是无向加权的,边的权值对应于两实体共现的次数。
2.2.1 关联信息的提取
目前已有多种实体及其关系提取的方法。在生物医学文献挖掘研究中,常用共现的方法来提取实体的关联,认为当两个词语共现于一定的语境中时,词语之间可能存在一定的语义相关性[10]。通过关系抽取技术,从非结构化的自然语言文本中抽取出格式统一的关系数据,能够建立多个实体之间广泛的信息关联。以基于句子共现的实体关联提取为例,其基本步骤如下:根据基于自然语言的方法识别出句子的实体NP及其位置。如果在同一个句子中得到的实体按其在句子中的顺序依次为NP1、NP2、NP3,则得到关联:(NP1,NP2),(NP1,NP3),(NP2,NP3)。
例如,文献标题(PMID:20856896):β1-syntrophin modulation by miR-222 in mdx mice,提取得到实体及其位置的列表为[(β1-syntrophin modulation,1)、(miR-222, 4),(mdx mouse,6)],进一步得到关联:(β1-syntrophin modulation,miR-222)、(β1-syntrophin modulation,mdx mouse)、(miR-222,mdx mouse)。
2.2.2 实体、关联及内容链接的图结构管理
图G中每个节点包含有属性,数据记录在节点都包括的属性里面,由节点组成的关系可以拥有自己的属性,关系相关的数据记录在其包括的属性里面。如图2所示,针对建立起的关联信息网络,可以利用遍历算法对图进行导航访问,遍历节点与关系,每一次遍历操作通过具体的路径识别算法实现,根据路径有序地排列节点。同时,可以分别为节点、关系与属性分别建立映射,分配独立的索引标识,并基于属性快速查询节点与关系,快速获取节点与关系的属性中记录的数据,然后将文献集转化为句子集,每个关联能够链接到句子,句子又能够链接到摘要或原文,便于回溯文献并加以分析,进一步确定关联的语义信息。

图2 信息网络的存储结构
3 基于信息网络的知识发现的应用
3.1 特异性关联的发现
特异性关联的发现是指通过对语义相关性的计算去搜索与置优特异性关联,以便更好地获得用户感兴趣并能激发科学假设的关联。特异性关联主要包括强关联与弱关联,强关联是指频繁共现的关联,弱关联是指共现次数很少的关联。传统文献检索强调获得强相关的内容,容易忽略那些可激发新科学假设的弱关联,而从这些弱关联中可能更容易获得新知识。信息网络中节点与节点之间的关联都给定了相应权重W,特异性关联的核心任务是如何快速获取给定节点的关联。如图3所示,给定X,可以方便地提取其关联的节点Y;通过对候选关联集按权重Wi(1≦i≦n)排序,可以根据不同需求去筛选强弱关联。
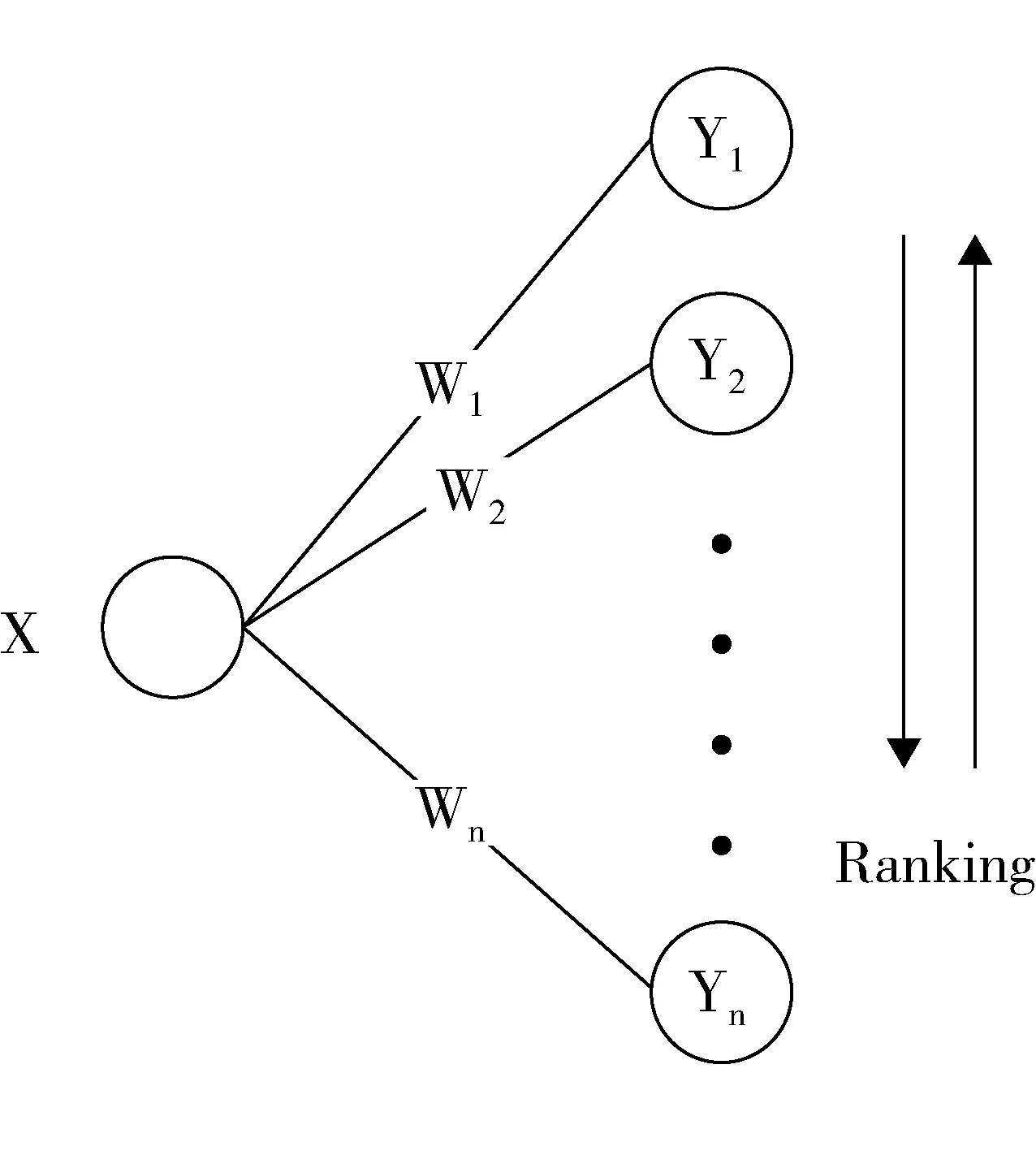
图3 特异性关联的发现
3.2 间接关联的推断
基于文献的知识发现的核心是通过ABC模型来挖掘概念间的间接关系,即当不相关的实体A与C同时与实体B相关时,A与C也可能通过实体B形成间接关系,三者构成一条A-B-C关系链。因此,必须明确A、B、C三个元素才可以获得一条有用的关联知识发现链。B的出现为科研人员提供有益的启发和关键性的引导,显著增强了目的性和方向性,帮助专业研究人员认识和发现潜在有用的知识片断间的关联,进一步证实科学假设的可行性。如图4所示,给定任意节点B,以B为支点或起点,可以获取间接关联A-B-C与B-C-D,即AC之间与BD之间都可能形成新的科学假设。
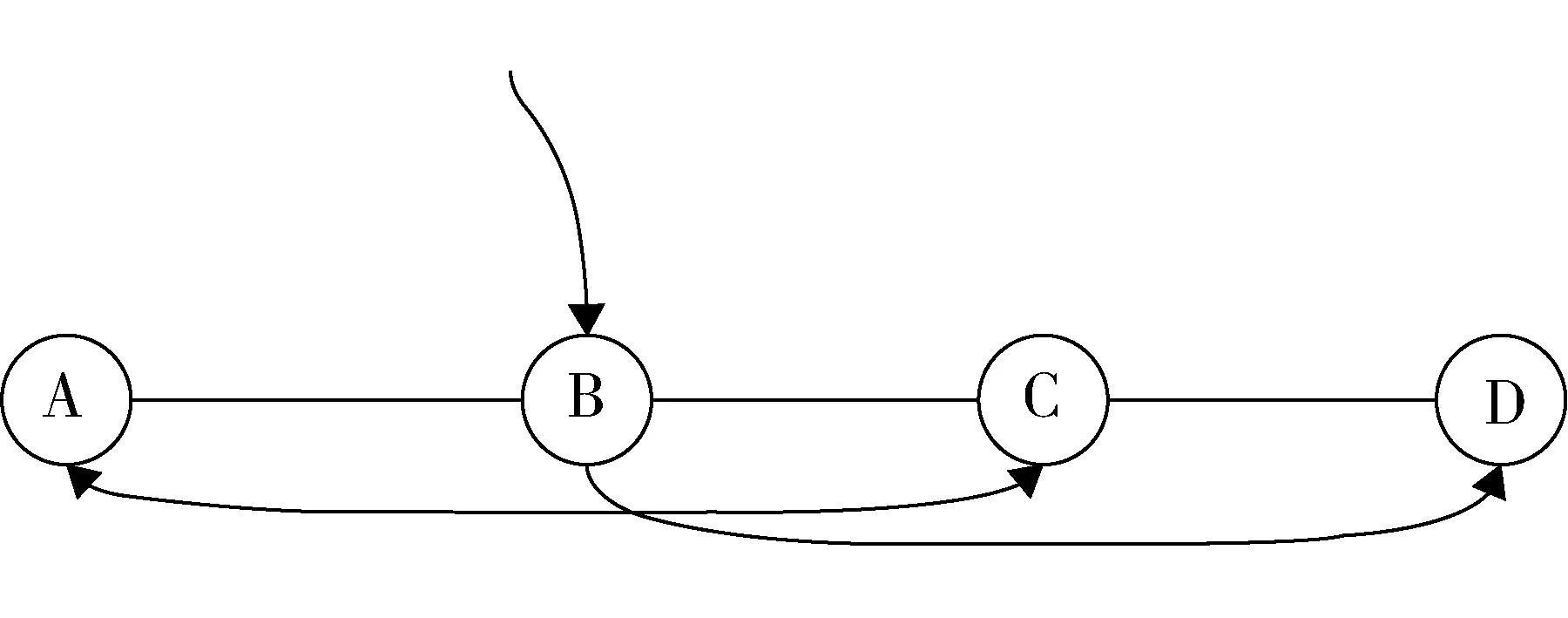
图4 间接关联的推断
3.3 通路知识的抽取
关联网络把文献库中的知识以网络形式表示,既显示出知识之间的联系,也过滤了冗余知识而以最简化的形式表示,这就方便研究人员发现未直接报道的对象间的隐含关系。建立关联网络中任意两个节点间的关联,能够计算两个节点之间的语义相关性,从而辅助科研人员筛选出有用的通路知识,即应该按照怎样的路径建立它们之间的关联。实际上是哪些语义关系可以发生关联,即哪些语义关系可以进行运算(图5)。
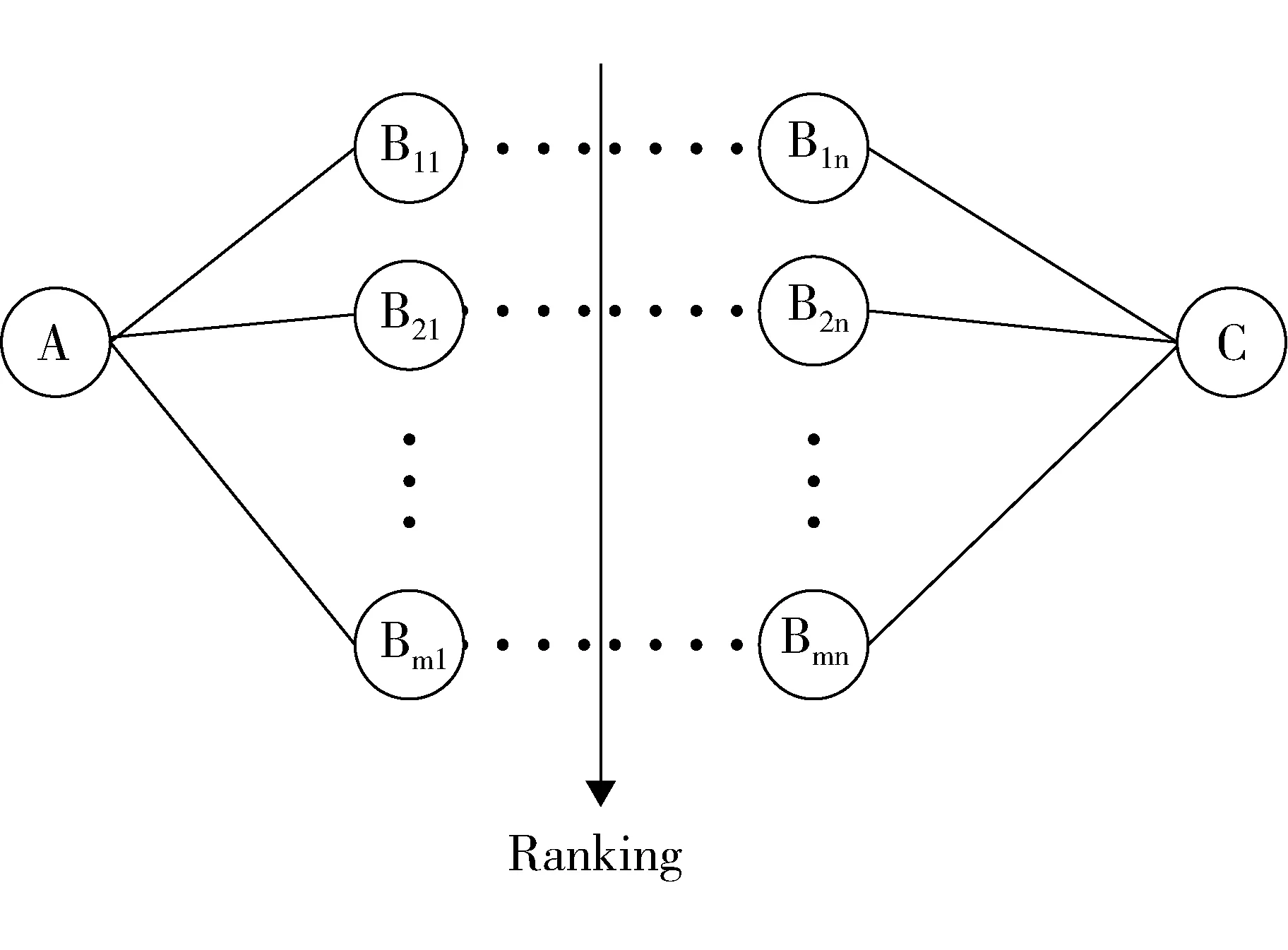
图5 通路知识的抽取
通路知识的抽取是指在实体关联网络中指定概念实体A与C,提取连接它们的一系列关键词构成的最短路径。最短路径是衡量连贯性和凝聚力的重要指标, 两个对象节点距离越短, 对象之间的联系越密切, 存在语义关联并可能形成科学假设的可能性越大。因此,我们将两个概念实体A与C之间的通路知识发现的问题等价于在关联网络中的最短路径搜索问题。如图5所示,给定任意A和C,提取它们之间的最短路径A-(B1…Bn)-C,计算每条路径的语义相关性,对结果集进行排序。显然,当A与C之间的距离为2时,即等价于间接关系的提取,获得ABC模型。
4 总结与讨论
关联信息是文献保存的重要科学知识,如一个基因相关的疾病有哪些,换句话说,就是如何找到已有文献报道的与某个基因相关的疾病。本文探讨了图结构对文献知识组织的重要作用,建立了基于关联信息网络的知识发现的应用模型。在网络结构的知识库基础上,可以更便捷地导航访问文献集中蕴含的关联知识,更快速地发现与筛选有效的特异性关联。对于间接关联的获取,关系链中的中间节点具有极其重要的“桥”的作用,节点的度可直观表示出节点在网络中的权重,因为仅仅从关键词出现的频率来判断节点的重要性,往往是一些宽泛的概念,而一些频率较小的节点或关联,很可能表达出重要的意义。此外,网络中任意一条通路在一定程度上都可能是一个语义水平上的关系链,能揭示某种有意义的联系,进而为用户提供一种科学思路。
与传统的基于文献的知识发现方法相比,基于复杂网络的方法不但能够揭示非相关文献中的隐含知识,更可以帮助发现任意文献集中潜在的关联性知识,对于文献中任意实体间的语义相关性的评估都具有非常重要的意义。整合网络的拓扑结构特征与统计信息,研究出新的语义相关性的计算指标,将未来文献知识发现研究的新的重要内容。
