基于树加权朴素贝叶斯算法的入侵检测技术研究
2016-03-17陈泓予杨姗姗
王 辉 陈泓予 杨姗姗
(河南理工大学计算机科学与技术学院 河南 焦作 454000)
基于树加权朴素贝叶斯算法的入侵检测技术研究
王辉陈泓予杨姗姗
(河南理工大学计算机科学与技术学院河南 焦作 454000)
摘要针对朴素贝叶斯(NB)算法在现实情况中所存在的缺陷,提出一种改进后的朴素贝叶斯算法——树加权朴素贝叶斯(TW-NB)算法。该算法通过引入决策树归纳法(DTI)在属性之间条件独立的集合中选择出相对更为重要的子属性集,并利用权重参数弱化了NB算法的条件独立假设性,从而降低了分类数据的维度,提高了算法的分类准确率。结合实验结果证明,在使用有限的计算资源下,基于TW-NB算法的入侵检测技术对于不同的网络入侵类型皆能表现出较高的检测率(DR)和较低的误检率(FR)。
关键词朴素贝叶斯决策树归纳法入侵检测准确率
INTRUSION DETECTION TECHNOLOGY BASED ON TREE-WEIGHTING NAIVE BAYESIAN ALGORITHM
Wang HuiChen HongyuYang Shanshan
(School of Computer Science and Technology,Henan Polytechnic University,Jiaozuo 454000,Henan,China)
AbstractAiming at the deficiency of naive Bayesian (NB) algorithm in the reality, this paper proposes an improved NB algorithm which is called tree-weighting naive Bayesian (TW-NB) algorithm. This algorithm, by introducing the decision tree induction (DTI), selects a comparatively more important subset of attributes from the set of conditional independence assumption, and uses weighting parameter to weaken the conditional independence assumption of naive Bayesian and thus reduces the dimensionality of the classification data, as well as improves the classification accuracy of the algorithm. It is verified by combining the experimental results that the intrusion detection technology based on the TW-NB algorithm can achieve higher detection rates (DR) and lower false rates (FR) for different network intrusion types when the computational resources used are limited.
KeywordsNaive BayesianDTIIntrusion detectionAccuracy
0引言
随着网络信息量的不断增大以及网络服务规模的日益扩大,保障网络数据安全性的网络信息安全技术开始受到各界领域的关注与重视。入侵检测技术(IDT)在网络环境中作为防火墙技术(FT)的有效补充可被分为异常检测(AD)和误用检测(MD)两大类,它能够通过审计、检测、识别和响应的方式实时地对网络行为进行监控并过滤信息数据,形成一种内外呼应的智能保护体系[1]。
由于网络技术的不断更新,网络入侵行为也演变的更加复杂多变,海量数据情况下的网络环境也使得入侵检测技术不断面临着巨大的挑战。因此,将针对大数据环境的数据挖掘(DM)算法如:KNN[2]、朴素贝叶斯(NB)[3]、支持向量机(SVM)[4]、K-means[5]等应用在入侵检测技术当中逐渐成为研究热点。其中,朴素贝叶斯(NB)算法作为最优秀的分类模型之一被广泛应用于各信息领域。但由于NB的“独立性假设”要求,这样会忽略属性与属性之间的依赖关系,使得属性所具有的关系性得不到体现,这与网络环境中数据之间的复杂联系情况相违背,对于入侵检测技术中的网络行为分类就会表现出较低的准确率。因此,针对这一算法缺陷,研究人员运用各种方法技术对朴素贝叶斯(NB)算法进行改进,以提升其分类的性能。
文献[6]中首次引入了隐朴素贝叶斯(HNB)模型的概念,该算法在NB模型的基础上通过为每个属性节点增加一个隐藏父节点来记录该节点与其他节点间的依赖关系,弱化了属性间的独立性条件,从而提高了分类精度,但该模型对于多重属性的关系网络却显得效率较低。在文献[7]中,针对HNB算法改进的双隐朴素贝叶斯(DHNB)模型被提出。该模型通过再度为每个属性节点增加一个新的隐藏父节点,该节点用来记录每个属性依赖关系的加权总和,从而更加充分地表示每个节点之间的关系情况,通过权重(Weight)属性进一步提升了NB算法的性能。文献[8]介绍了一种随机选择朴素贝叶斯(RSNB),该算法是在包装器(Wrapper)属性特征子集选择方法(FSS)的基础之上,在整个属性空间中装载随机搜索,使得NB算法的预测性和分辨性增强,但在一定程度上也增加了算法本身的时间和空间复杂度O(n)。Flores等人[9]采用了在连续和离散域AODE (Aggregating One-dependence Estimators)模型中自动建立基于复杂属性值的半朴素贝叶斯(SNB),该算法能够将依赖性较强的基本属性特征组合成集合,因此SNB在某种程度上简化了属性集的复杂度,去除冗余属性,从而避免了分类干扰因素。在文献[10]中,一种动态完全朴素贝叶斯(DCNB)分类模型被建立,该算法通过使用多元高斯核函数估计属性条件联合密度与平滑参数优化的方法,有效地利用了属性之间的条件依赖信息,从而提升了NB算法的分类准确性,但该改进算法针对大数据环境却显得效率有所降低。文献[11,12]分别引入属性加权的思想对NB算法进行了改进,通过对不同的条件属性赋予不同的权值来降低分类干扰,提高检测精度。
本文在前人的研究基础之上,针对上述改进方法的优缺点,提出了一种改进的NB算法——树加权朴素贝叶斯(TW-NB)算法,并将该算法引入到入侵检测技术当中。该算法通过使用决策树归纳法(DTI)过滤出重要的属性子集,首先通过决策树估计出被选择的属性权重,然后只有这些由决策树根据它们相关权重所选择出的最重要的属性才能被用于“类条件独立性假设”的计算。本文将结合使用KDD’99入侵检测数据集测试并验证TW-NB算法在入侵检测技术中的性能,并与NB算法进行分类准确度的比较。实验结果证明,TW-NB算法在网络入侵行为的检测率与误检率方面较NB算法都有显著的改善,针对复杂多级的集合环境也能表现出较高的分类效率。
1改进算法相关研究
1.1NB分类算法
给定一个N维训练样本集T={D1,D2,…,Dn},其中Di={d1,d2,…,dn}表示集合中每个数据记录。训练集T包含属性集合A={A1,A2,…,An},而每个属性Ai拥有属性值集合{a1,a2,…,an},属性值可以是离散值或者连续值。训练数据集T还包含类集合C={C1,C2,…,Cm|(m≤n)},每个训练样本实例D(D∈T)均拥有一个特定的类别标记Cj。对于一个测试样本集E={e1,e2,…,en},测试实例ei可根据贝叶斯定理计算的后验概率P(Cj|Ai)得出其所属类别。先验概率P(Cj)可由拉普拉斯校正方程统计每个类别Cj(j≤m)在训练集T中所出现的频率估算所得,条件概率P(Ai|Cj)可相应地根据属性值ai(i≤n)在训练集T中对应的所属类别Cj中出现的频率计算得出。因此,朴素贝叶斯(NB)算法可通过先验概率和条件概率进行预测,从而得出待分类样本实例的所属类别,达到不同数据归类的目的。
(1)
根据式(1)可分别计算出测试样本属性ei所属类别的后验概率,NB分类算法找出最大后验概率MAP最终划分属性的归属类别,根据式(2)计算所得,即在训练集中仅当P(Ci|ei)>P(Cj|ei)(i≠j,1≤j≤m),则ei的类别标签为Ci,概率P(Ci|ei)即为最大后验假设。

(2)
朴素贝叶斯分类器(NBC)是一个基于概率的算法,可以预测样本所属类成员的概率。该算法有以下优点:(1) 算法构造简单,时间复杂度低;(2) 概率生成仅需单次遍历训练集合;(3) 模型结构清晰严谨,具备较好的鲁棒性和可扩展性。NBC需要条件独立性假设的前提,即属性在给定类的影响独立于其他属性。
1.2决策树归纳法
决策树归纳法(DTI)是一组规则集合,使用递归的方式将训练样本集(TS)划分成更小的子集合(Sub-TS),直到每一个子集合拥有独有的所属类别标签。DTI算法通常采用信息论(IT)作为属性选择方法,根节点TS的选择是基于计算出的所具有最高信息增益的属性。给定一个N维训练样本集T={t1,t2,…,tn},pj表示样本实例ti(i≤n)属于类别Cj(j≤m)的先验概率,可根据式(3)得出对给定的样本实例进行分类所需要的期望信息Info(T)。
(3)
相应地,训练样本集T根据属性A={a1,a2,…,an}迭代地被划分成N个不同的子集合{T1,T2,…,Tn},其中Ti为样本集合T中属性A=ai时的样本子集合。可根据权重值|Ti|/|T|计算出属性A划分T的期望信息,从而根据原始信息要求Info(T)和新的信息要求的偏移量计算得出信息增益InfoGain(A)。根据样本集T中的属性值,逐一地计算出每个属性值对T进行划分的信息增益,从中选择出具有最高信息增益的属性Am作为最佳属性来划分子集合,递归整个过程直到所有集合都被正确归类。
(4)
DTI用于分析构建模型的可行性与可信度,相应地根据观察推出其逻辑表达式及结构,通过其简单清晰的逻辑推理和分割信息值,能够快捷地对大数据集进行高效的数据划分。但针对连续型数据和多类别集合,划分效率就会随复杂度的升高而降低。
1.3TW-NB算法
树加权朴素贝叶斯(TW-NB)算法是通过引入决策树归纳法(DTI)来增强朴素贝叶斯(NB)算法的预测性与可行性,增加权重参数使样本属性之间的独立性得到弱化,运用信息增益比迭代地将集合逐步精确细分,从而使得每个样本实例都能正确的被归类。
在一个给定的N维训练样本集合U中,其每一个训练样本实例Si(Si∈U)都拥有一组属性{A1,A2,…,An},且每个属性都有不同的取值{a1,a2,…,an}。同时,样本集中的类集合C={C1,C2,…,Cm}用于标记样本实例Si(i≤n)。首先,根据决策树归纳法则,将训练集U构建成未修剪的决策树Tr,集合中每个样本拥有属性值,Tr作为属性选择及计算影响样本属性Ai归类的权重值φ的决策方法。构建完Tr后,使用决策树分类器从集合U(U≠∅)中分出最影响分类的子集合Us(Us⊆U),为训练集U中每一个属性Ai初始化权重值φ(i≤n,φ≥0)。如果Ai∈U但Ai∉Tr,则设初值φ=0。计算出Tr中测试属性Ai∈Tr的最小深度D,并将属性的权重值初始化为1/D。根据式(5),将选择属性的权重值设为朴素贝叶斯(NB)后验概率计算定理的指数时,能够影响分类的条件概率估算。最终,通过Laplace定理估计出Tr中类先验概率P(Cj)(j≤m)和属性条件概率P(Ai|Cj),属性通过φ≠0而被选择出作为影响样本的最终归类,从而计算出后验概率而得出正确分类,而φ=0的属性样本将不会出现在分类集合中。
(5)
其中,权重值φ是属性值类条件概率计算及样本之间关系的影响因子,得出样本属性的所属类别需要根据决策树Tr确定其影响最终分类的属性关系。并根据先验概率和条件概率估计出最大后验概率MAP,通过递归的原则逐步重复划分子集合的过程,将错分的子集合再次重组继续划分归类,最终确定每个样本的分类集合。TW-NB算法的具体实现过程如下:
输入训练样本集U={S1,S2,…,Sn}。
1) 在集合U中去除冗余样本数据,选择出最佳分裂属性并逐步地建立未修剪的决策树Tr。
2) for (确定Tr中的每个节点Ni和分割路径Path)。
3) if (该条Path终止),将该子集合Ue确定为叶节点Ne并将其合理的分类。
4) else 将子集合Us≠∅根据Path继续划分,建立决策子树Tr-s并为每个节点添加标记Li(i≤n))。
5) for (遍历每个属性Ai(Ai∈U))。
6) if (Ai∈U但Ai∉Tr),设初权重值φ=0。
7) else 作为Tr中属性Ai(i≤n)的最小深度D,初始化权重值φ=1/D。
8) for (分别遍历U中的类别标记Cj(j≤m)和属性Ai(φ≠0))。
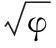
10) for (遍历每一个求出的后验概率P(Cj|Ai))。
11) 训练集U中比较每一个后验概率的值,当且仅当P(Cx|Ai)>P(Cj|Ai)(x≠j≤m),即P(Cx|Ai)为最大后验概率MAP,选取Cx作为Ai的所属类别,直到所有的子集合Us分类完毕。
输出训练集中所有样本均正确归类的分类集合UC,其中映射函数f:Cj→Ai(j≤i≤n)。
2入侵检测实验与分析
2.1KDD’99入侵检测数据集
入侵检测技术即为一种概率性预测及网络数据分类技术,将TW-NB分类器运用在该技术中来检测网络异常行为及事件数据归类达到预警功能是合理有效的。
本文实验使用KDD Cup 1999 (KDD’99)入侵检测数据集,通过实验数据来验证基于TW-NB算法的入侵检测技术的检测效率。在KDD’99数据集中,每个样本表示网络数据流中类Class的属性值A:{A1A2,…,An},每个类Class都被标记着正常Normal或攻击Attack。这些类在数据集中可被分为{Normal,DOS,U2R,R2L,Probe}五大类,其中四大入侵类又可被细分成22种攻击类型如表1所示。

表1 KDD’99数据集中的入侵类型
KDD’99数据集是由DARPA98数据集转化来的,它是对DARPA98数据进一步过滤处理后产生的。由于原始数据集的庞大以及包含过多的冗余和缺失数据,因此KDD’99数据集提供了一个500万条数据记录其中的10%的样本数据作为子集来方便数据的实验。通过实验数据的需求,本文选取了这个10% KDD’99数据子集中的样本分别作训练集Train和测试集Test数据如表2所示,同时数据集中为每次的网络连接使用的41种输入属性特征如表3所示。

表2 KDD’99数据集中训练及测试样本的数量(10%)
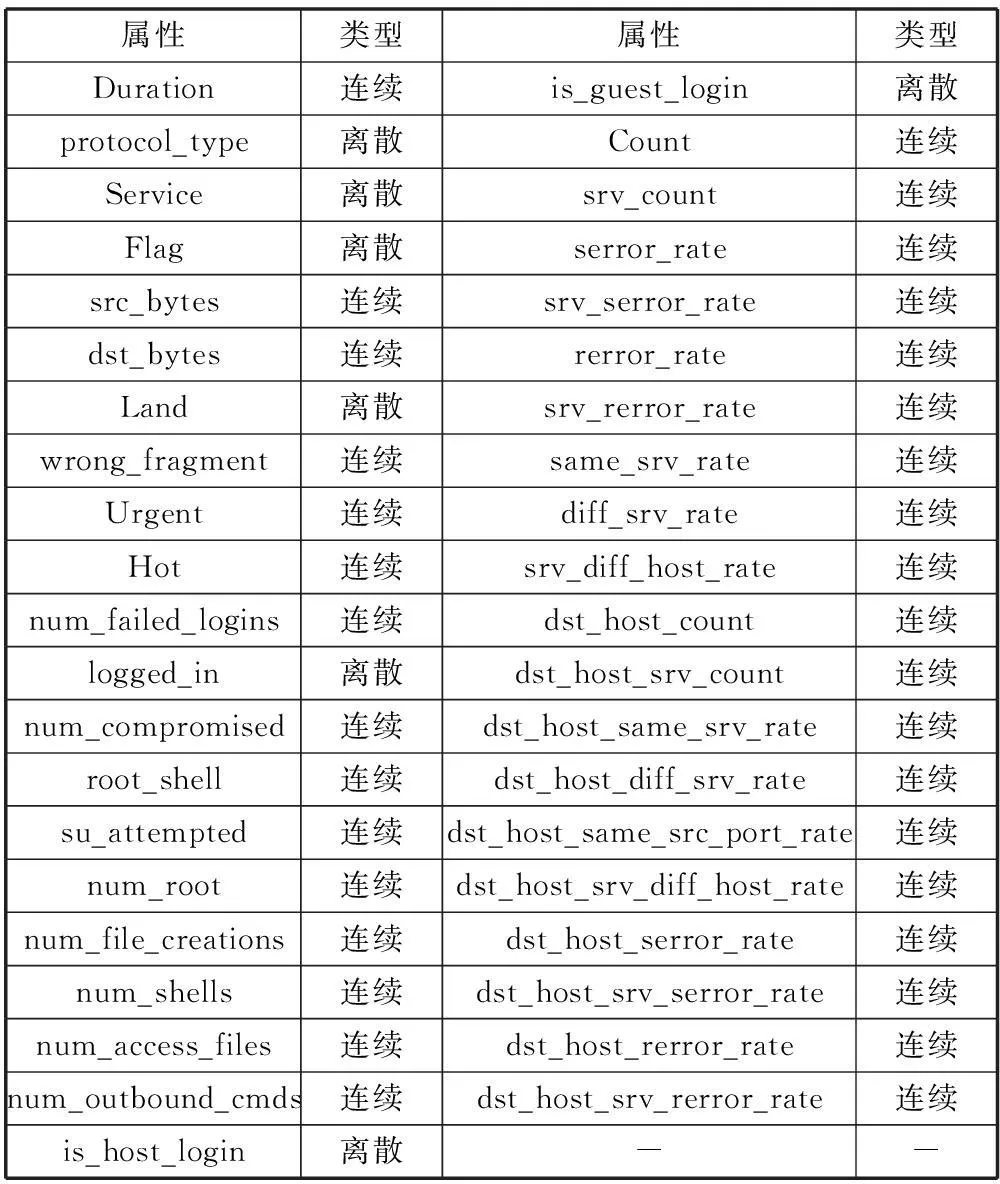
表3 KDD’99数据集中41种属性
2.2影响因素的分析与预处理
在实际的网络环境中,海量的网络访问数据由于类型和结构的不同会造成普遍的数据冗余以及一定程度的数据缺失,这些现实因素会直接影响到TW-NB算法的分类性能和预测效果。因此,数据的预处理为解决干扰问题对于验证算法的性能和健壮性是非常必要的。所关注并处理的实际影响因素主要有以下几项:
(1) 冗余数据
实际环境中数据的冗余现象是必然存在的,它直接影响着数据的质量。因此,增加数据的独立性和剔除冗余数据是测试大规模数据系统成功的前提条件。
(2) 缺失数据
数据的缺失造成了系统丢失了大量的有用信息,使系统表现出更加显著的不确定性,包含空值的数据会使分类过程陷入混乱并导致不可靠地输出。
处理以上影响TW-NB算法的分类预测因素,本文采用基于特征相似度的属性选择方法。主要步骤如下:
1) 根据式(6),在数据集合U中计算与属性Aj之间的相似度ρij。其中1≤j≤n,且Aj∈U。
2) 选择相似度ρij最大的完整属性Ai(1≤i≤n)作为缺失数据的弥补对象,用于填补数据的完整性。
3) 计算数据集合U中属性之间的方差值COV(i,j),选择方差小的属性值,方差相同的属性任选其一,从而剔除了不必要的冗余数据,提高了数据质量。
4) 输出一个完整的、低冗余度的属性集合D。
(6)
2.3实验结果分析
实验仿真环境采用Windows 7操作系统、2.8 GHz双核CPU、4 GB DDR3内存以及Weka智能分析环境,实验数据使用KDD’99入侵检测数据集中10%训练及测试样本数据。根据入侵检测仿真实验结果,基于TW-NB算法的入侵检测技术的检测效率分析以及改进前后算法性能的比较结果分别如图1所示。
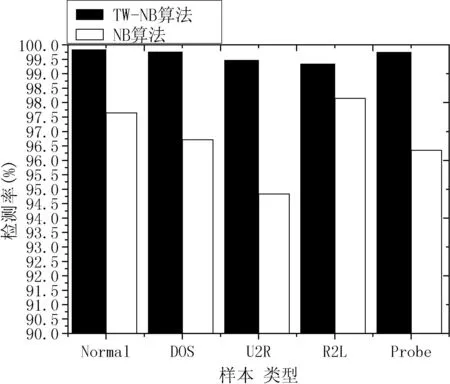
图1 改进前后算法的入侵检测率(DR)比较
从图1和图2中的实验结果可以看出,TW-NB算法在检测不同入侵数据时较NB算法在DR和FR方面都有了明显的性能提升,尤其对于DOS攻击和R2L攻击在检测率和误检率上分别有大幅度改善。由图3所示,在设置了阈值(θ=98.5%)的情况下,TW-NB算法对入侵检测数据集中的攻击数据的检测准确度Accuracy的连续值较NB算法有了普遍的提高,整体连续属性取值均高于阈值θ,最高准确值Am可达99.76%。而NB算法的检测准确度值趋于或低于阈值,最低取值降到98.12%,远远低于阈值。当准确度取值A<θ时,则值A为不期望值。
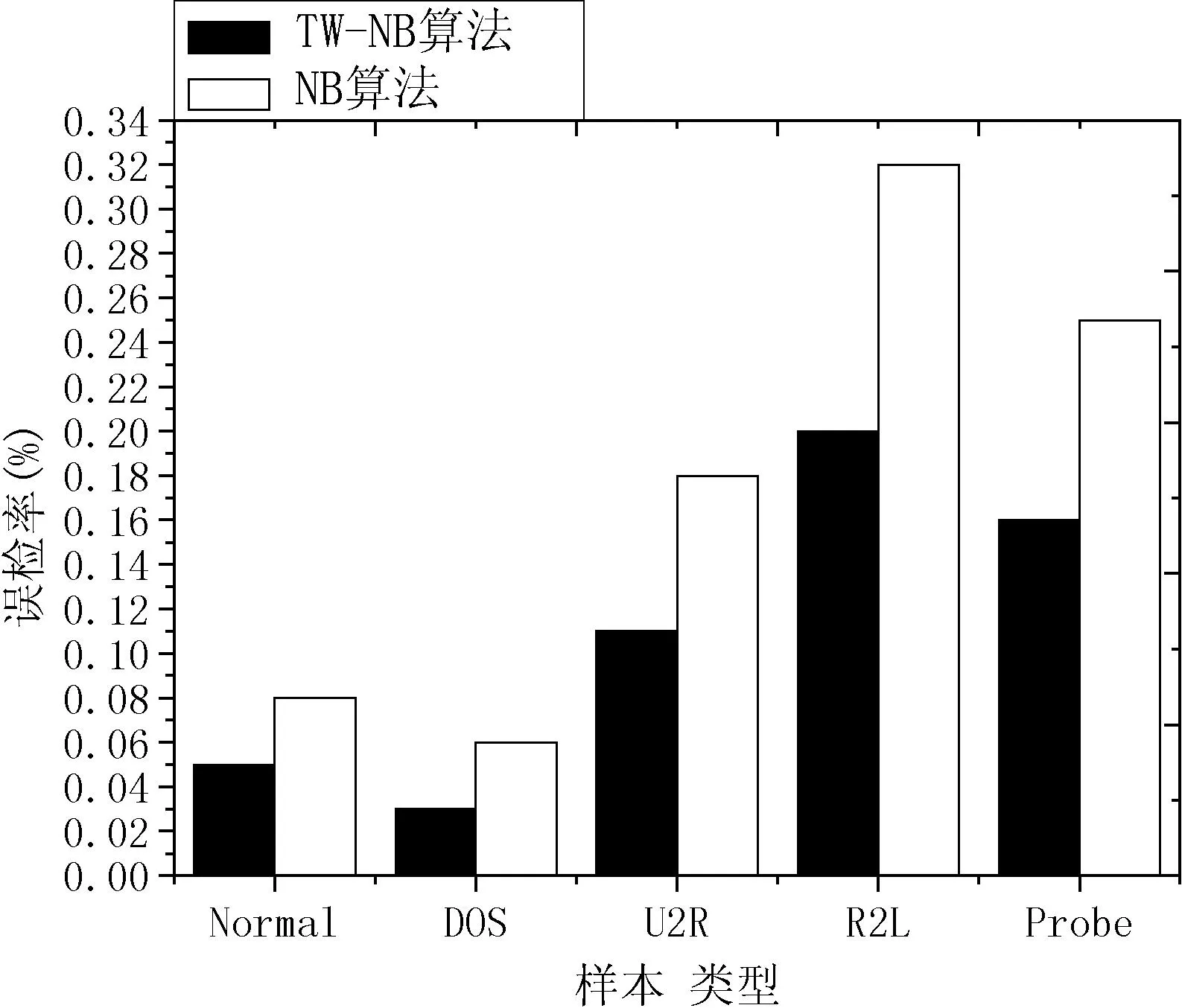
图2 改进前后算法的入侵误检率(FR)比较

图3 算法在入侵检测数据集中的准确度
结合实验结果与数据分析,本文将TW-NB算法分别与网络入侵检测领域中的其他流行的数据挖掘算法(C4.5、SVM、K-means)以及改进的NB算法(HNB、RSNB、AODE)进行检测性能的比较,比较结果分别如表4和表5所示。
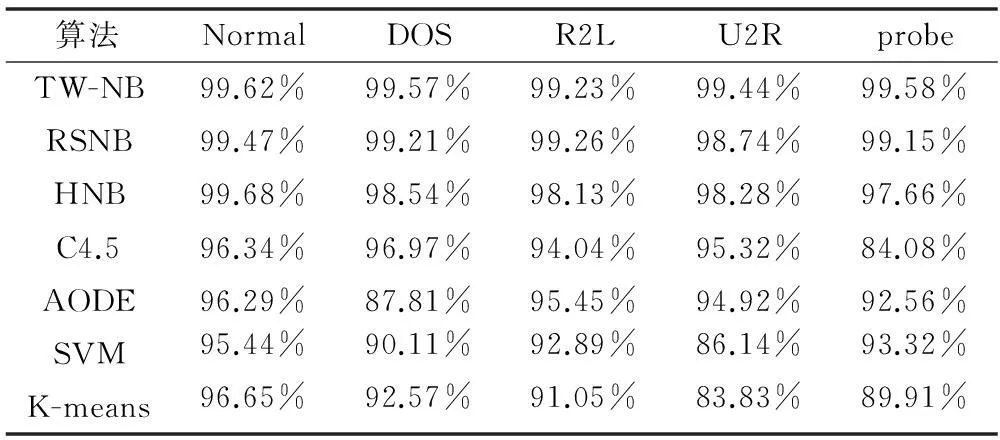
表4 TW-NB算法与相关算法检测率(DR)的比较
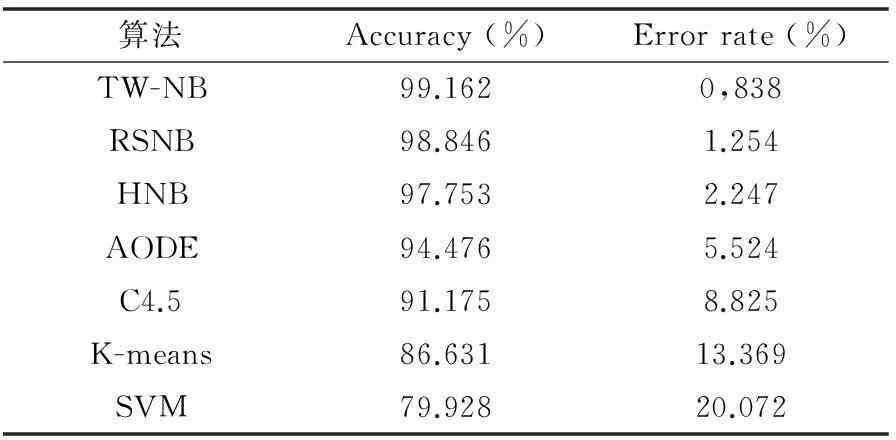
表5 相关算法入侵检测准确度(Accuracy)的比较
根据表4、表5的数据比较结果,本文的改进算法TW-NB在检测率(DR)和分类准确度(Accuracy)方面较其他流行的数据挖掘算法以及改进算法均有明显的提升和改善。从其他实验结果可分析,TW-NB算法的平均入侵检测率可达99.49%,平均准确度较其他算法可提升到99.162%,平均错误分类率较其他算法可降到0.838%,检测性能具有比较显著的改进。
3结语
针对现代网络环境中复杂多变的网络入侵行为,本文借鉴朴素贝叶斯理论,提出了改进的NB算法——TW-NB算法,并运用在入侵检测技术当中,将攻击数据从海量数据中划分出来并进行攻击预测。TW-NB算法通过引入决策归纳法(DTI),设计权重参数φ以及决策准则来进一步控制朴素贝叶斯(NB)的分类,从而更加提高了NB算法的分类准确度。实验中,首先运用Weka智能分析环境和KDD’99入侵检测数据集中的大量数据验证了算法的可行性,并分析实验结果得到不同效果的实验图和表。在今后的研究工作中,将进一步深入优化并提升TW-NB算法的分类性能。由于该算法对冗余数据复杂度及计算资源状况较为敏感,因此在下一步的计划当中,将引入数据预处理的相关方法再度提高TW-NB算法的鲁棒性和适用性。
参考文献
[1] 史志才,夏永祥.高速网络环境下的入侵检测技术研究综述[J].计算机应用研究,2010,27(5):1606-1610.
[2] Yang Li,Li Guo.An active learning based TCM-KNN algorithm for supervised network intrusion detection[J].Computers & Security,2007,26(7):459-467.
[3] Levent Koc,Thomas A Mazzuchi,Shahram Sarkani.A network intrusion detection system based on a Hidden Naïve Bayes multiclass classifier[J].Expert Systems with Applications,2012,39(18):13492-13500.
[4] 谭爱平,陈浩,吴伯桥.基于SVM的网络入侵检测集成学习算法[J].计算机科学,2014,41(2):197-200.
[5] Reda M Elbasiony,Elsayed A Sallam.A hybrid network intrusion detection framework based on random forests and weighted k-means[J].Ain Shams Engineering Journal,2013,4(4):753-762.
[6] Jiang Liangxiao,Zhang H,Cai Zhihua.A novel Bayes model: hidden naive Bayes[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(10):1361-1371.
[7] 李晶辉,张小刚.一种改进隐朴素贝叶斯算法的研究[J].小型微型计算机系统,2013,34(7):1654-1658.
[8] Liangxiao Jiang,Zhihua Cai,Harry Zhang.Not so greedy:Randomly Selected Naive Bayes[J].Expert Systems with Applications,2012,39(12):11022-11028.
[9] M Julia Flores,José A Gámez,Ana M Martínez.Domains of competence of the semi-naive Bayesian network classifiers[J].2014,260(1):120-148.
[10] 王双成,杜瑞杰,刘颖.连续属性完全贝叶斯分类器的学习与优化[J].计算机学报,2012,35(10):2129-2138.
[11] 李方,刘琼荪.基于改进属性加权的朴素贝叶斯分类模型[J].计算机工程与应用,2010,46(4):132-141.
[12] 贾娴,刘培玉,公伟.基于改进属性加权的朴素贝叶斯入侵取证研究[J].计算机工程与应用,2013,49(7):81-84.
中图分类号TP311
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.068
收稿日期:2014-06-20。国家自然科学基金项目(51174263);教育部博士点基金项目(20124116120004);河南省教育厅科学技术研究重点项目(13A510325)。王辉,副教授,主研领域:计算机网络及网络安全,无线传感器网络。陈泓予,硕士生。杨姗姗,硕士生。
