基于显著性和区域比较的自动物体提取算法
2016-03-17刘兆瑞王广伟
刘兆瑞 赵 波 王广伟
(西南交通大学信息科学与技术学院 四川 成都 610031)
基于显著性和区域比较的自动物体提取算法
刘兆瑞赵波王广伟
(西南交通大学信息科学与技术学院四川 成都 610031)
摘要面对互联网时代海量的图像数据,如何自动地提取物体成为一个热点问题,为此提出一种结合超像素、显著性和区域比较的自动目标提取算法。算法首先对图像进行超像素分割,得到若干子区域;其次采用显著性检测确定出目标的初始区域;最后在子区域和初始区域的基础上,结合空间信息和颜色特征,利用区域比较法分割出最终的目标物体。对比实验结果表明,该算法能够有效地提取出目标,具有一定的鲁棒性。
关键词显著性超像素区域比较物体提取
AUTOMATIC OBJECT EXTRACTION ALGORITHM BASED ON SALIENCE AND REGIONAL CONTRAST
Liu ZhaoruiZhao BoWang Guangwei
(School of Information Science and Technology,Southwest Jiaotong University,Chengdu 610031,Sichuan,China)
AbstractFacing the massive image data in internet era, how to automatically extract the object from images becomes a hot issue. Therefore this paper proposes a novel algorithm of automatic target extraction, it combines the superpixel, salience and region contrast. First, the algorithm makes superpixel segmentation on images to get several sub-regions. Then, it uses saliency detection to determine the initial target region. At last, based on sub-regions and initial regions, it combines spatial information and colour feature and uses region comparison method to segment the final target object. Result of the contrast experiment shows that this method can extract the object effectively and has certain robustness.
KeywordsSalienceSuperpixelRegion comparisonObject extraction
0引言
目标物体提取就是利用图像的纹理、颜色和空间位置等信息从复杂背景中获取需要的物体。该过程把输入图像转化为目标区域,对进一步提取物体特征、物体检索和分类等高层处理都是十分重要的。
随着互联网的不断发展和大容量存储设备的广泛使用,图像数据呈现几何级数的增长,面对海量的图像数据,如何自动、有效地从图像中提取目标物体已经成为一个极具挑战性的课题。目标提取主要分为两类:基于单张图像和多张图像的目标提取。其中,Zhang[1]利用视频前后帧和空间信息建立分层的无回路有向图,并利用该图获得物体的初始区域,最后采用GMM模型和基于graph-cuts的优化方法提取出目标;Djelouah[2]利用同一物体的多个视角实现多张图片的协同图割,进而获得所需物体。虽然基于多张图像的目标提取算法效果较好,但在实际图像数据中,大部分图像是单张存在的,无法进行协同分割。对于单张图像的分割,研究集中于交互式分割算法。如:Boykov[3]提出的graph cut,该方法由用户指定前景和背景,然后将像素作为顶点,像素之间的关系作为边构造一个图,最后采用最大流/最小割算法获得图像的分割结果;Rother等[4]基于graph cut设计了Grabcut算法,该算法采用高斯混合模型表示颜色概率分布,并利用概率值更新像素之间的关系,最终用graph cuts方法进行迭代得到前景目标。在有用户交互的情况下,交互式分割算法表现出良好的性能,但该方法无法自动处理海量图像数据。目前,对于单张图片的自动分割研究较少,Achanta等[5]将显著性检测应用于自动目标提取,该方法首先对输入图像进行显著性检测,并利用mean-shift和自适应阈值来获取物体,由于该算法没有考虑物体的空间信息,造成一些物体不能准确分割。
针对以上算法的不足之处,本文提出一种结合显著性、超像素和区域比较的自动物体提取算法AOEA(automatic object extraction algorithm)。首先,用超像素分割和显著性检测获得目标的初始区域,实现了目标自动粗定位。然后,提出一种新的以超像素区域作为基本单位的分割算法,该算法可以对不准确的粗定位区域进行有效分割,并表现出较强的鲁棒性。同时,该算法考虑了空间分布信息,弥补了Achanta等[5]提出的FT算法的不足。实验表明,该算法提高了分割的精度,能够准确地提取出目标。
1图像预处理
图像预处理主要包含两部分:显著性检测和对图像进行超像素分割。
1.1SLIC超像素分割方法
在超像素分割步骤中,采用由Achanta等人[6]提出的简单线性迭代聚类(SLIC)算法。该方法思想简单,运行速度较快,利用CIELAB颜色空间和XY坐标构造5维的特征向量,并对图像中的像素进行局部聚类,生成排列紧密的超像素。然而,该算法需要手动设定超像素区域的个数。超像素个数越多则对物体边缘的拟合越好,局部辨别能力越强;超像素个数越少则每个区域包含的信息越多,算法鲁棒性越强。本文通过实验测试,将每张图片分割成100个左右的超像素块时,可以取得较好的分割效果。部分超像素处理结果如图1所示。
1.2基于全局对比度的显著区域检测(RC)
本文采用RC[7]算法对图像进行显著性检测,其为目前性能最好的显著性检测算法之一。RC方法对以往像素级别的显著性计算进行了拓展,以区域为单位进行更大规模的显著性计算。首先,采用efficient graph cut[8]算法将图像分为若干个区域。然后,同时考虑区域的颜色特征和空间位置来计算该区域的全局对比度,即显著值。该方法可以最大程度上克服噪声的影响,使计算结果更加准确。显著值计算方法如下所示:
(1)
其中,S(ri)为区域ri的显著值;Ds(ri,rj)为区域ri和rj的空间距离,通过两个像素块几何中心的欧式距离进行计算;w(rj)表示像素块的权重,由像素块包含的像素数量决定;Dr(ri,rj)为ri和rj在L*a*b空间的距离;δ2为空间距离权重调节系数,一般取0.4[7]。部分显著性处理结果如图1所示(从左至右分别为原图像、显著图和超像素处理图)。

图1 部分显著性处理结果
2区域特征提取及类别初始化
超像素分割后,可以获得若干个子区域。其中,ri表示第i个超像素区域,li作为类别标签,用于描述ri所属类别。
2.1区域颜色特征
本文采用量化后的HSV特征来描述区域的颜色分布。首先,提取区域内每个像素的HSV值;其次,采用8×3×3的量化方法[9]对HSV值进行量化;最后,将量化后的HSV值映射到[0,72]之间的某值G,映射方法如下所示:
G=9H+3S+V
(2)
对区域内所有的像素进行量化映射后,获得描述该区域颜色分布的72维直方图Hi={h1,h2,…,h72}[10,11]。
2.2区域所属类别初始化
对海量图片进行观察分析后,我们发现图像背景在四个角落(左上、左下、右上、右下)之间的差异很大,而各个角落内部极为相似。因此,我们对基于前景和背景两个类别的传统分割算法进行改进,提出一种针对五个类别的区域分割算法。五个类别分别为:左上背景类(类别标签为1)、左下背景类(标记为2)、右上背景类(标记为3)、右下背景类(标记为4)、前景类对应0,每个类别由Classk表示:
(3)
在对区域所属类别初始化过程中,首先对显著图进行二值化处理。本文采用速度较快的最大类间方差法(OTSU)[12]进行自适应二值化。二值化后的亮点作为前景点,暗点设为背景点,然后判断每一个区域中是否所有像素均为前景点,若成立则将li设为0(前景类),否则设为背景类,并根据该区域几何中心的空间位置判断其具体属于哪一种背景类别。初始化分类结果如图2所示(左图为原图,右图为初始分类结果,其中1,2,3,4分别对应左上背景类、左下背景类、右上背景类、右下背景类,其余部分为前景类)。

图2 初始化分类结果
3基于区域比较的图像分割
基于区域比较的分割算法指通过迭代计算区域与类别的相似度来更新每个类别,最终使得类别间的差异最大(即相似度最小)。最终状态下Class0中的区域为提取出的目标物体。
以往的研究往往专注于像素之间和区域之间的相似度,对于区域和类别之间、类别与类别之间的相似度研究较少,而高层次的特征通常具有较好的稳健性,适用网络中海量的各类图片。因此,本文提出一种适用于分割过程的区域间相似度Sim(ri,rj)计算方法,并基于Sim(ri,rj)设计了区域和类别的相似度Sim(ri,Classk)及类别之间相似度Sim(Classk1,Classk2)。其中,区域间相似度计算方法如下所示:
(4)
其中,w(rj)和Ds分别表示区域包含像素的数量和区域间的空间距离,由区域几何中心的欧式距离表示。Cr表示余弦距离,Hi为区域的颜色直方图。该计算方法同时考虑了区域的颜色特征、大小和空间距离,较好地体现了目标属性。此处采用余弦距离来计算颜色之间的相似度,主要考虑到w(rj)已经计算了区域大小,则Cr只需考虑区域的颜色分布。当采用余弦距离时,我们发现量化后的HSV特征能够十分准确地描述区域间的相似度,因而采用量化的HSV作为区域的颜色特征。
区域与类别的相似度和类别之间相似度的计算方法如式(5)和式(6)所示:
(5)
其中,w(Classk)为第k个类别所包含像素的数量。
Sim(Classk1,Classk2)=

(6)
其中,Nk1、Nk2分别表示两个类别包含区域的个数。得到类别之间的相似度后,图像分割问题可以转化为求解各个区域的类别标签,使类别之间的总体相似度取得最小值。为了能够快速求解,设计了一种简单、有效的迭代计算方法。
算法步骤如下:
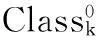
(2) 更新每个区域的类别标签li,更新方法如下:
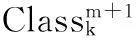
4实验
4.1实验数据集
本文随机挑选THUR15K[13]标准数据集中的10 000张图像进行检测,该数据集中图像的大小约为400×300,其中的物体种类繁多、形态各异,而且背景较为复杂,不同图像的物体之间、背景之间也有着很大的差异,这都使得目标提取变得极具挑战性,能够有效地检测AOEA算法的鲁棒性。同时,该数据集上的每张图片均有人工标注的像素级别的目标物体,能够很好地量化评价AOEA算法的性能。
4.2实验结果及分析
为了验证AOEA算法的健壮性和空间信息的有效性,分别用FT算法、GrabCut+显著图的方法和本文算法进行目标提取。GrabCut+显著图的方法为本文所提,其首先对图片进行显著性检测,然后采用 OTSU算法对显著图进行自适应二值化,最后应用GrabCut算法对前景区域进行分割,提取目标物体。图3为本文算法和对比算法的目标提取结果。
实验结果表明,当显著性检测的结果不准确时,GrabCut算法无法获得准确的初始前景区域,导致其能量函数的权重值与实际情况相差较大,最终将背景区域误当作目标信息保留下来或误将目标信息删除,提取出的目标物体不准确,如图3(b)和(c)所示。FT算法能够克服显著图效果较差的情况,能够将不属于目标的背景信息准确的除掉,但是没有考虑物体的空间信息,对于一些不同部位差异较大的物体,该算法很难获得理想的效果,往往将物体内部区域作为背景信息除掉,如图3(b)和(d)所示。本文算法综合考虑了空间信息和区域信息,成功地实现了针对单张图片的自动目标提取。AOEA将区域作为基本单位进行目标提取,减少了对物体细节的描述,增强了对物体高层特征的应用,具备较好的鲁棒性。同时,该算法考虑了物体的空间信息,一定程度上保证了目标的完整性,能够对FT算法误划分的目标信息进行正确的处理。为了定量分析AOEA进行目标提取的性能,我们采用准确率、召回率和F1值作为评价指标。

图3 目标提取结果
(7)

(8)
(9)
表1定量评估了算法的性能。从表中数据可以看出,新提出的方法与GrabCut算法在召回率相当的情况下,目标提取准确率更高。同时,AOEA算法在召回率和F1值方面均取得明显优于FT算法的性能。
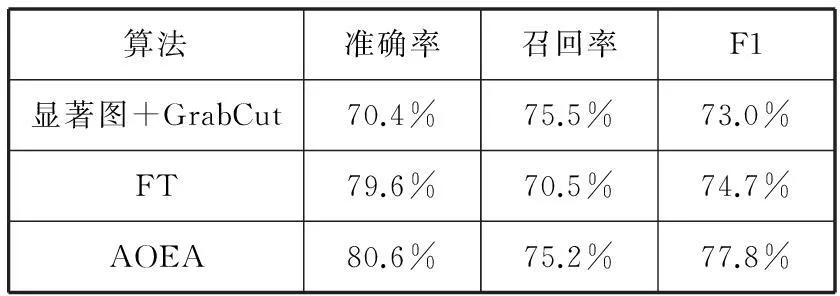
表1 算法性能
5结语
本文的主要创新点在于提出了一种基于区域比较的分割算法,并将该算法和显著性相结合,实现了对物体的自动提取。AOEA算法综合考虑了区域的颜色、空间位置和大小等信息,能够对不准确的显著区域进行有效分割,取得了明显优于传统分割算法的性能,具有较强的鲁棒性。进一步的研究工作包括将纹理特征和颜色特征相结合进行分割,以及将该算法应用到图像检索系统和基于内容的视频检索中。
参考文献
[1] Zhang D,Javed O,Shah M.Video object segmentation through spatially accurate and temporally dense extraction of primary object regions[C]//Computer Vision and Pattern Recognition (CVPR),2013 IEEE Conference on.IEEE,2013:628-635.
[2] Djelouah A,Franco J S,Boyer E,et al.Multi-view object segmentation in space and time[C]//Computer Vision (ICCV),2013 IEEE International Conference on.IEEE,2013:2640-2647.
[3] Boykov Y Y,Jolly M P.Interactive graph cuts for optimal boundary & region segmentation of objects in ND images[C]//Computer Vision,2001.ICCV 2001.Proceedings.Eighth IEEE International Conference on.IEEE,2001,1:105-112.
[4] Rother C,Kolmogorov V,Blake A.Grabcut: Interactive foreground extraction using iterated graph cuts[C]//ACM Transactions on Graphics (TOG).ACM,2004,23(3):309-314.
[5] Achanta R,Hemami S,Estrada F,et al.Frequency-tuned salient region detection[C]//Computer Vision and Pattern Recognition,2009.CVPR 2009.IEEE Conference on.IEEE,2009:1597-1604.
[6] Achanta R,Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2012,34(11):2274-2282.
[7] Cheng M M,Zhang G X,Mitra N J,et al.Global contrast based salient region detection[C]//Computer Vision and Pattern Recognition (CVPR),2011 IEEE Conference on.IEEE,2011:409-416.
[8] Felzenszwalb P F,Huttenlocher D P.Efficient graph-based image segmentation[J].International Journal of Computer Vision,2004,59(2):167-181.
[9] Smith J R,Chang S F.Tools and Techniques for Color Image Retrieval[C]//Storage and Retrieval for Image and Video Databases (SPIE),1996,2670:2-7.
[10] Kong F H.Image retrieval using both color and texture features[C]//Machine Learning and Cybernetics,2009 International Conference on.IEEE,2009,4:2228-2232.
[11] Ma J.Content-based image retrieval with HSV color space and texture features[C]//Web Information Systems and Mining,2009.WISM 2009.International Conference on.IEEE,2009:61-63.
[12] Otsu N.A threshold selection method from gray-level histograms[J].Automatica,1975,11(285-296):23-27.
[13] Cheng M M,Mitra N J,Huang X,et al.Salientshape:Group saliency in image collections[J].The Visual Computer,2014,30(4):443-453.
中图分类号TP391.4
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.037
收稿日期:2014-07-11。国家自然科学基金项目(61373121);四川省科技创新苗子工程项目(2012ZZ053)。刘兆瑞,硕士生,主研领域:计算机视觉,图像检索。赵波,博士生。王广伟,讲师。
