一种用于部分可观察随机域的情感计算模型
2016-03-17黄向阳王旭仁
黄向阳 张 娜 王旭仁 彭 岩
1(首都师范大学信息工程学院 北京 100048)
2(首都师范大学管理学院 北京 100048)
一种用于部分可观察随机域的情感计算模型
黄向阳1张娜1王旭仁1彭岩2
1(首都师范大学信息工程学院北京 100048)
2(首都师范大学管理学院北京 100048)
摘要在计算机游戏中,富有情感可以使非玩家角色表现得更加真实,同时增加游戏的趣味性以吸引更多的游戏爱好者参与。在部分可观察不确定环境提出一种基于规划的情感计算模型。首先,基于部分可观察马尔科夫决策过程提出一种成本约束的目标导向行为规划技术用于规划智能体行为;其次,在规划执行过程中结合评价与再评价的双层评价理论计算生成情感;最后,结合特定情境设计两组对比实验。实验表明该模型能够提高智能体的逼真度且更加吸引玩家。
关键词情感计算目标导向行为规划部分可观察马尔科夫决策过程双层评价理论
AN AFFECTIVE COMPUTING MODEL FOR PARTIALLY OBSERVABLE STOCHASTIC DOMAIN
Huang Xiangyang1Zhang Na1Wang Xuren1Peng Yan2
1(School of Information Engineering , Capital Normal University, Beijing 100048, China)2(School of Management, Capital Normal University, Beijing 100048, China)
AbstractEmbodiment of emotions can make non-player characters more realistic in computer games, and increase the fun of the game simultaneously to attract more players involved in. In the paper we present a planning-based affective computing model in partially observable uncertain environment. First, based on partially observable Markov decision processes we propose a goal-oriented action planning technique with costs-constraint for planning the actions of intelligent agents; then we use two-level theory of cognitive appraisal, appraisal and reappraisal, to calculate the emotion during planning execution process; finally we design two groups of comparative experiments in combination with specific situations. Experiments suggest that the model can improve the believability of agents and is more attractive to players.
KeywordsAffective computingGoal-oriented action planningPartially observable Markov decision processesTwo-level theory of cognitive appraisal
0引言
计算机游戏中最初出现“智能”是参与游戏的非玩家角色NPCs(None-Player Characters)被设计成“游戏逻辑”的一部分,通常是指一段“聪明”的程序。随着人们逐渐认识到人工智能在游戏领域的重要性,一些研究者认为此类非玩家角色在未来应该能够实现“自治”,即通过“虚拟躯体”与“虚拟世界”进行交互,通过各种各样的规划和学习算法来调整自身适应环境[1-3]。
此外,一些专家发现运用适当的生物学知识可以使自治角色的行为表现更加真实可信。一些研究者认为:情感无疑是真实性与可信度的关键因素,即有情感的非玩家角色表现出的行为更加真实,使游戏参与者更能体会到是与“人”而不是死板的计算机进行对峙。这不仅增加游戏的趣味性,也提高了其娱乐价值与商业价值[4]。
行为规划技术常用于智能体的物理行为选择,而情感的产生则依赖于情感评价理论。基于人脑信息处理过程的研究,智能体或机器人在复杂环境中常采用混合体系结构进行行为选择,一般分为两层:反应层和慎思层。反应层支持行为选择机制速度较快,而慎思层则支持形成最优化的行为[5]。分层理论对应的情感评价理论则是“多层情感评价理论”。
本文将智能体的物理行为和情感行为统称为行为,并基于部分可观察马尔科夫决策过程POMDP(Partially Observable Markov Decision Process)和分层理论提出一种基于规划的情感模型PEM(Planning-Emotion Model)。由于智能体一般为了某一目标而设计的,并且在实际的规划执行过程中往往会受到一些约束(时间和资源等),所以本文基于部分可观察马尔科夫决策过程提出一类成本约束的目标导向行为规划CGOAP(Costs-constrained Goal Oriented Action Planning)。该规划可以计算出智能体在某一状态时应该选择的最优动作以及未来可以到达目标的概率(目标满意度),同时根据 “观察” 计算出“动机一致性”与“责任”等评价变量的值。其中,“动机一致性”、“责任”等变量会用于计算产生反应式情感,目标满意度则会影响到再评价过程,进而计算产生慎思式情感。最后,本文运用PEM构建了情感自主角色AACs(Affective Autonomous Characters), 并结合特定场景进行实验从而对PEM的有效性进行验证。
1相关理论
1.1部分可观察马尔科夫决策过程
游戏世界中充满不确定性,如NPC突然开枪射击玩家,玩家可能被击中也可能成功躲避。另外,自主角色观察世界采用的方式与玩家一致,即依靠自己的主动性获取局部信息。针对这种行为结果的不确定性以及观察的不完整性,本文选择部分可观察马尔可夫决策过程(POMDP)进行建模。POMDP为部分可观察环境下行为规划提供了常用的框架,即自主角色即使观察到非精确信息也能预测行为动作带来的后果。POMDP可以用
T:S × A × S → [0,1]
(1)
其中由状态s执行动作a到状态s′的概率可表示为:
T(s,a,s′)=Pr(s′|s,a)
观察函数如下:
Z:S×A×O→[0,1]
(2)
其中执行动作a且结果状态是s时观察到o的概率如下:
Z(s,a,s′)=Pr(o|a,s)
奖赏或成本函数如下:
R:S×A→R
(3)
其中R(s,a)是指在状态s执行动作a所期望的奖赏或花费成本。
由于环境是不可观察的,可通过定义|S| 维“信念状态”将非马尔可夫问题转化为马尔可夫问题[6]。其中,b(s)表示状态s的概率,信念状态可以根据基本概率理论进行递归更新。对于信念状态b和动作a以及观察o(Pr(o|b,a)>0),计算出新的信念状态b′,计算公式如下:
b′(s′)=Z(s′,a,o)∑s∈Sb(s)T(s,a,s′)/Pr(o|b,a)
(4)
其中:
Pr(o|b,a)=∑s∈S∑s∈Sb(s)T(s,a,s′)Z(s′a,o)
接下来是自治角色如何根据信念状态选择执行的动作来优化性能。用Vt(b)表示在时间t和信念状态b下,角色期望未来能得到的总的折扣奖赏,根据Bellman优化理论可得:
(5)
其中:

然而,用式(5)求解无穷步规划问题时只能针对很小的问题,并且在现实世界的规划过程中会存在着一些约束,如规划时长、可用资源数量等。因此,本文在POMDP的基础上定义了一类成本约束的目标导向行为规划模型(CGOAP)来指导自主角色选择行为动作。CGOAP 针对的是部分可观察不确定环境下的有限步,含约束条件的规划问题。与传统所期望的最大化长期折扣奖赏的目标不同,CGOAP关心的是在定量成本约束下,自主角色未来到达目标的最大可能性。
1.2评价理论
大多数的情感理论都专注研究“认知”与“情感”之间的关系[7-9],并得出特定情境会激发不同的情感反应这一结论。换言之,情感反应依赖于认知评价。情感类型可以由一个或多个评价变量决定,常见的评价变量包括:目标一致性、责任和概率等。其中,概率是指未来实现目标的可能性。Chartrand等人指出认知评价并非只指复杂的认知过程,在到达某个阈值时情感可以被触发产生而非必须经过“有意识”的处理过程[10]。Lazarus理论将认知评价过程细分为三个子评价过程:基本评价、次级评价以及再评价。Smith和Lazarus更进一步划分出六个评价部分,其中两个部分包括基本评价,另外四个部分则包含次级评价[11]。
Damasio在神经学证据基础上将情感划分为主情感和次情感[12]。主情感也称为反应式情感,是人类应对外部环境尤其是危险事件时一种直接的、原始的、自适应的应急情感;次情感也称为慎思式情感,通常是建立在人们对主情感的有意识的价值判断上的,其产生需要一个过程。
由于多层情感理论与人类大脑分层处理信息过程相吻合,因此比单一的评价过程更合理且更容易解释人类生活中常见的一些情感现象。
人类很多情感的产生源于对某事件的期望,当目标事件实现的概率较高时人类会产生正向情感(积极情感),反之会产生负向情感(消极情感)。本文将CGOAP和多层情感计算相结合来创建具有情感的自主角色AACs。AACs在追寻目标的过程中,每执行一个动作,目标实现的概率(通过CGOAP计算得出)可能会发生变化,从而它的情感也会随着变化,这就是所谓的情感动力学。
2集成CGOAP的情感计算模型
本文采用主次情感的双层情感模型并结合CGOAP提出一类适用于部分可观察不确定环境的情感计算模型,如图1所示,也称之为基于规划的情感模型PEM。PEM从感知层和认知层两个层面来处理刺激,且对刺激的评估过程是由感知层上升到认知层[13]。评价过程建立在自发的感知层,再评价过程是建立在深思熟虑的认知层上的。对PEM来说,外界对角色的刺激会形成一种原始观察(基本观察),原始观察有可能会触发产生反应式情感,但未必会影响到角色的行为规划。原始观察累积会形成高级观察(抽象观察),CGOAP根据当前的信念状态以及高级观察计算出未来可以实现目标的概率。情感评价系统将利用计算出的概率对当前产生的反应式情感进行再评价从而产生次级情感,而反应式情感的产生则是依赖于CGOAP中通过基本观察计算出的“动机一致性”和“责任”。反应式情感强度大但衰减速度快,而慎思式情感强度小但衰减速度慢且可以保持到下一规划步到来。在每一个决策点,CGOAP除了计算出未来能实现目标的概率,还能计算出当前应该采取的行为。在我们的模型中行为是由基本动作序列组成,而执行每一个基本动作会对虚拟世界产生作用,继而又产生新的原始观察以及反应式情感,如此循环往复形成情感动力学。在AACs的情感表现过程中,次级情感相对比较稳定(类似于情绪),而反应式情感则是不断地打断次级情感,但消逝速度很快。

图1 集成CGOAP的情感计算模型
2.1CGOAP
本文基于POMDP提出了一种CGOAP模型,即在有限成本的基础上,计算出AACs未来实现目标的最大概率和当前应采取的最优行为。CGOAP由(S,A,T,O,Z,b0,c0,g,C)九元组表示,其中b0是初始信念状态,c0是指初始成本,n维向量g表示各个状态成为目标状态的概率,C是约束函数,其他元素的定义与POMDP相同。CGOAP中每个行为动作都有相关的成本,用C(a) > 0表示,且对于任何信念状态b可执行的动作集合均满足A(b)⊆A∪Λ,其中Λ表示在信念状态b上没有执行任何动作。依据Bellman最优化理论可得公式如下:
Vt(b,c)=maxa∈AOt(b,c,a)
(6)
π(b,c,t)=argmaxa∈AOt(b,c,a)
(7)

Ot(b,c,Λ)=b′·g
(8)
其中,c是剩余可用成本,Ot(b,c,a)表示在时刻t信念为b,且可用成本为c的情况下选择执行动作a未来可到达目标的最大概率。规划的目标是计算V0(b0,c0)的最大值以及相应的行为规划π(b,c,t)。γ<1表示随着时间的推移实现目标的难度加大。
对于复杂系统(如游戏)要想给出一个完美的因果关系律是不现实的。为了满足实时性,通常我们会在一个较高层次上建模。对于CGOAP,此时观察o是一种高级观察(抽象观察),动作a是由基本动作序列构成的一种复杂动作(行为),于是在状态s0执行动作a到达状态s可表示为:s=do(αn, …,do(α1,s0)),其中<α1,…,αn>是指构成行为a的基本动作序列。一般而言,执行完每个基本动作都会产生一个原始观察。高级观察是通过对原始观察序列分析得到的。
2.2认知评价
在计算机科学领域中,认知评价是情感生成的重要方法,如OCC模型给出了22种情感的评价方法[14]。本文基于Ekman基本情感理论运用PEM实现六类情感(快乐、悲伤、愤怒、担心、失望和惊喜)的评价。Ekman等认为人类有六类基本情感:快乐、悲伤、愤怒、担心、厌恶和惊喜。由于AACs是目标导向的,因此本文将“回避”动机相关的负面情感“厌恶”换成“趋近”动机相关的负面情感“失望”,同样的道理,将fear翻译成担心,surprise翻译成惊喜。本文在反应式情感里考虑三类情感:快乐、悲伤和愤怒;而在慎思类情感里考虑快乐、惊喜、悲伤、担心和失望五类情感。反应式情感和慎思式情感中都存在 “快乐”和“悲伤”,但却是相互区别的。相同的情感在反应式情感中一般强度较高、延续的时间短并且表现方式比较明显,而在慎思式情感中则恰恰相反。
本文用“动机一致性”和“责任”来区分反应式情感。AACs的动机是实现目标,因此可以用行为是否有利于达到目标来衡量该行为是否和动机一致。本文采用一个更简单的方法,即“达到了目标”则满足动机一致性,“没有达到目标”则不满足动机一致性。我们用“动机一致性”这一评价变量来区分“快乐”和“悲伤”,对于“愤怒”则还需考虑行为的主体,如果自己的损失是别人造成的,则产生愤怒。
对于慎思式情感,可以采用评价变量“概率”来区分。当未来到达目标的概率不低于0.5时,AACs会表现出正向情感(以快乐为基调的情感);当低于0.5时,负向情感(以悲伤为基调的情感)会产生[14-16]。OCC模型认为正向情感(快乐和惊喜)或者负向情感(悲伤、担心和失望)它们之间的区别仅仅是强度的不同,并且这些情感可以通过概率区间区分,我们用模糊变量来表示这些概率区间。本文用一个两阶段决策树来表示PEM在决策点时的情感评价过程,如图2所示(更多的反应式情感是在非决策点获得原始观察时产生的)。

图2 双层认知评价过程
2.3情感表达
情感表达的形式多种多样,如面部表情、肢体语言、行为表现和语言声音等。情感可以通过外部动作和声音直接被人察觉,另外对面部表情地特写也是常用的情感传递方式。ACCs将通过动作、声音和表情等多维度混合方式表达和传递情感。
3应用实验
基于上述情感计算模型PEM创作一段游戏动画,然后通过主观评价实验来验证PEM的有效性。
3.1故事情节
很久以前,在一个山谷里住着一群牧羊人,他们过着幸福平静的生活,然而一天夜里一个怪物突然掠走了他们所有羊群,牧民们很伤心,一位勇士决心去除掉这个怪物救回牧民的羊群。翌日,勇士循迹来到了怪物地盘,但通往怪物洞穴的路阴森迷幻,并不断有小怪物骚扰勇士,消耗勇士的体力。图3是游戏故事情节的一些片段,其中,(a)为开始阶段勇士精力充沛,有很高的概率找到怪物,因此比较乐观; (b)为在耗费了一定体力后,勇士发现能找到怪物的概率很低了,显得很担心; (c)为不可能找到怪物了,勇士很失望; (d)为在另一次游戏中,勇士找到了怪物,在同怪物的打斗中,怪物抓中了勇士,勇士很愤怒。

(a)

(b)

(c)

(d)
3.2PEM
本文用一个3×3的方格来描述实验设计(每个方格对应着一个动态生成的游戏场景相当于一个关卡),中间的方格是个阻塞区不能穿过,怪兽在右上角的方格里,除了怪兽所在方格,所有方格均难以区别,每个方格中心有一个北向指示标识。角色在每个非目标方格的中心有四个行为可以选择,分别是向北、向东、向南和向西。角色从方格中心选择任何一个行为只有80%的概率沿着该方向行走,各有10%的概率会变到与行走方向垂直的任何一个方向,如果前方是边界或者障碍物则会退回到出发方格的中心。除了在目标方格正下方的方格内选择北向行为花费是1外,其它的行为选择花费是2。定义各类慎思式情感的概率区间为:惊喜(0.8,1],快乐[0.5, 0.8],害怕(0.5,0.3),担心[0.3,0.1]和失望[0,0.1)。
3.3实验方法
本文参考Reilly的文章设计两组对比实验对角色逼真度进行评价[17]。Reilly分别从以下三个参考方面对角色逼真度进行评定(实为参与者针对三个问题进行打分):角色整体效果、角色表达人类特质效果和参与者身临其境效果。
两组对比实验分别是:第一组是无情感的角色(A)与只有反应式情感的角色(B);第二组是只有反应式情感的角色(B)和运用了PEM模型的角色(C)。每组20个同学参与评分,其中包括12名男生8名女生,年龄范围20~27岁。打分区间为0~10,随着分值的增加表示逼真度不断提高,0~2表示“非常不逼真”,3~4分表示“不逼真”, 5分代表“中立”,6~7代表“逼真”,8~10代表“非常逼真”。
进行实验之前给每个参与者发一份纸质说明,其内容包括:游戏故事情节、逼真度打分的范围以及上述逼真度参考的三个方面,确保每个参与者对上述内容清晰。为尽量减小由顺序引起的误差,每组中随机抽取6个男生和4个女生先观看各自组中某一个角色的游戏动画。同时,剩下的6个男生和4个女生观看另外一个角色的游戏动画,当参与者观看完一遍两个动画片段后,可自由选择动画片段观看直到可以得出一个结论为止,实验持续时间大约为二十分钟。最后,每个参与者分别给两个角色打分,并给出一些说明。
3.4实验结果及分析
通过统计分析,第一组实验中角色A的均值和标准差为:(3.5, 1.67),角色B的均值和标准差为(5.35, 1.81);第二组实验中角色B均值和标准差是(5.3, 1.13)和角色C的均值和标准差是(6.85,2.39),如图4所示。

(a) 第一组两个角色逼真度的均值和标准差

(b) 第二组两个角色逼真度的均值和标准差
本文采用单尾成对t检验方法对实验数据进行分析[17]。单尾成对t检验方法是对每个参与者针对该组两个角色的逼真度打分的差值(后者减去前者)进行检验,统计结果如图5所示。
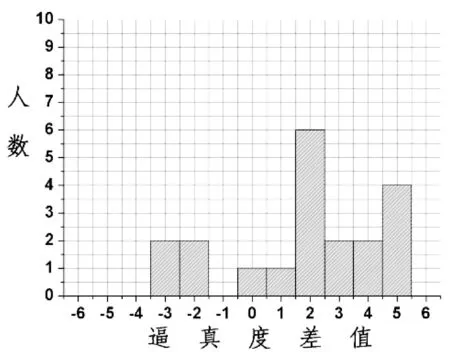
(a) 第一组逼真度差值,其等于角色B逼真度减去角色A的逼真度

(b) 第二组逼真度差值,其等于角 色C减去角色B的逼真度
检查两者的均值差是否大于0,如果95%置信区间在0值右侧,则可以宣称两者的均值差大于0(95%的可能),即后者要比前者“好”。 第一组实验P值约为0.0027且置信区间在0值右侧,表明角色B的逼真度均值大于角色A的逼真度均值,说明只有反应式情感的角色B比无情感的角色A更逼真。此实验结果与先前Reilly的研究结论是一致的。第二组实验P值约为0.015且置信区间在0值右侧,表明角色C的逼真度均值大于角色B的逼真度均值,说明使用本文提出的模型PEM的角色C比只有反应式情感的角色B更逼真。
3.5讨论
模拟情感可以提高游戏角色的逼真度,此结论在很多实验中得到验证(包括本实验)[14-16]。反应式情感是人类和动物进化的产物,而慎思式情感是人类特有的情感。第二组参与者的解释表明,通过对慎思式情感的连续模拟(一个动态的情感过程),使得参与者感觉到角色C可以关心并推理当前的处境,这为计算机游戏或动画设计提供一种更有前景的发展方向,用户或者观众更倾向与关心当前形势的游戏(动画)角色打交道。
本实验不足之处在于参与者的年龄范围和受教育程度等条件的方差较小,不利于结论的进一步推广。未来应该考虑设计更多的实验并争取更广泛的参与者。
4结语
关于人工智能的研究如果过分专注智能可能会忽略角色的行为可信度。情感是增加真实度和可信度的关键因素。本文重点是在部分可观察马尔可夫决策过程的基础上提出一种成本约束的目标导向行为规划技术(CGOAP),并结合双层认知评价理
论提出了一种可用于部分可观察不确定环境下的基于规划的情感计算模型(PEM)。PEM可用来创建具有情感的自主角色AACs,也可用于动画的自动生成。未来的工作是将更多的情感集成到PEM,以及在PEM中加入情感对行为选择的作用。
参考文献
[1] Fang Y P, Ting I H. Applying Reinforcement Learning for the AI in a Tank-Battle Game[J].Jounal of Software, 2010,5(12):1031-1034.
[2] Ji Ruan. Reasoning about Time, Action and Knowledge in Multi-Agent Systems[J].KI-Künstliche Intelligenz,2011,25(1):75-76.
[3] 许斯军, 曹奇英. 基于可视图的移动机器人路径规划[J].计算机应用与软件,2011,28(3):220-222,236.
[4] Bosse T, Zwanenburg E. Do Prospect-Based Emotions Enhance Believability of Game Characters? A Case Study in the Context of a Dice Game[J].IEEE Transactions on Affective Computing,2014,5(1):17-34.
[5] Manabu Nakao. International Conference on Intelligent Robots and Systems[J]. Piscataway,2011,29(5):1410-1415.
[6] Gomez-Estern F. Computational principles of mobile robotics[J].Automatica,2002,38(10):1833-1834.
[7] Fletcher, Garth J O, Julie F, et al. Knowledge structures in close relationships: A social psychological approach[M].5th ed. London :Psychology Press, 2014.
[8] Wyer J R S, Srull T K, Wyer Jr R S. Memory and Cognition in its social context[M].5th ed, London:Psychology Press, 2014.
[9] Lorini E, Schwarzentruber F.A logic for reasoning about counterfactual emotions[J].Artificial Intelligence,2011,175(4):814-847.
[10] Chartrand T L, R B van Baaren, J A Bargh. Linking automatic evaluation to mood and information-processing style: Consequences for experienced affect, impression formation, and stereotyping[J].Journal of Experimental Psychology, General,2006,135(1):70-77.
[11] Smith C A, Lazarus R S. Appraisal components, core relational themes, and the emotions[J].Cognition and Emotion,1993,7(3):233-269.
[12] Damasio A. Descartes’ error, emotion reason and the human brain[M].New York: Vintage , 2006.
[13] Becker-Asano C,Wachsmuth I. Affective Computing with primary and secondary emotions in a virtual human[J]. Auton Agent Multi-Agent Syst, 2010,20(1):32-49.
[14] Ortony A, Clore G L, Collins A.The Cognitive Structure of Emotions[M].2nd ed.Cambridge, UK: Cambridge University Press, 1990.
[15] Marsella S, Gratch J, Petta P.Computational models of emotion[J].A Blueprint for Affective Computing-A sourcebook and manual,2010,11(1):21-46.
[16] The Duy Bui, Dirk Heylen,Mannes Poel,et al.ParleE:An Adaptive Plan Based Event Appraisal Model of Emotions[M]//KI2002:Advances in Artifical Intelligence,Springer Berlin Heidelberg,2002:129-143.
[17] Reilly W S.Believable Social and Emotional Agents[R].Carnegie-mellon Univ Pittsburgh PA DEPT of Computer Science,1996.
中图分类号TP18
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.018
收稿日期:2014-09-12。黄向阳,副教授,主研领域:人工智能及情感计算。张娜,硕士生。王旭仁,教授。彭岩,教授。
