层次聚类分析法在水质监测点优化中的应用
2016-03-16张月霞毛金龙
张月霞,毛金龙
(1.云南省环境科学研究院,云南 昆明 650034;
2.华能澜沧江水电股份有限公司,云南 昆明 650206)
层次聚类分析法在水质监测点优化中的应用
张月霞1,毛金龙2
(1.云南省环境科学研究院,云南 昆明 650034;
2.华能澜沧江水电股份有限公司,云南 昆明 650206)
摘要:以抚仙湖湖体2014年7月 —2015年6月污染指标的监测平均值作为原始数据,采用SPSS层次聚类分析法对不同监测点进行聚类分析,确定各监测点间的亲疏关系,并结合监测点属性等实际情况,最终将原15个监测点初步优化调整为11个监测点,获得了最优化水质监测断面。
关键词:监测点;SPSS;层次聚类;优化;抚仙湖
0引 言
水质恶化是湖泊环境演变的重要研究主题,受到当今世界各国和学术界的广泛关注,由于人类活动强度的不断增加以及自然环境的变化,湖泊水质环境受到严重威胁,以富营养化、酸化和有机物污染等为代表的水质问题成为制约湖泊生态系统健康的主要因素[1-2]。水质的监测对于掌握水质的变化趋势亦变得尤为重要。而水质监测中,测量断面和测点的布置直接影响着结果的正确性,同时影响测量效率。因而在保证数据正确合理的基础上,对监测断面进行优化设计,将有助于提高测量工作人员的工作效率,节省经济支出。一般地,人们常采用数理统计方法来分析河流监测断面监测结果是否相近,以此判断监测断面是否需要优化去除。聚类分析是定量研究分类问题的一种数理统计方法,它是根据种类中的个体有较大相似性( 或变量) 之间相似度的统计,来确定样品(或变量)之间的亲疏关系,将样品(或变量)分别聚类到不同的类中[3],监测断面的聚类分析有助于确定不同断面之间的相互关系,从而明确不同类别监测断面的监控性质[4-5]。而层次聚类算法[6]是实际应用中聚类分析的支柱,在各种软件包中都能找到它的身影,使用简单且具有较高的稳定性。因此,本文以抚仙湖湖体水质监测数据为例,采用层次聚类分析的方法对监测断面进行分类,得到最优化水质监测断面。
1地域概况
抚仙湖位于云南省中部,昆明市东南约60km,北纬24°21′28″~24°38′00″,东经102°49′12″~102°57′26″。跨澄江、江川、华宁三县[7]。抚仙湖属于南盘江流域西江水系,流域面积674.69km2,水域面积约为216.6km2,湖长约31.4km,湖最宽处为11.8km,湖岸线总长100.8km,最大水深158.9m,平均水深95.2m,相应湖体水量约206.2亿m3,占云南省九大高原湖泊总蓄水量的72.8%,是我国最大的深水型淡水湖泊。抚仙湖为贫营养型湖泊,水质清澈透明,含沙量很小,湖水中各生物营养元素的含量很低,生物生产力较低,是我国为数不多的保持Ⅰ类水质的大型湖泊。然而,近年来,由于人类活动的干扰以及自然环境变化,抚仙湖水质发生变化,有机污染和营养化水平不断提高,高锰酸盐指数、TP浓度、浮游植物丰度和叶绿素a浓度有所上升,部分月份水质达到Ⅱ类,湖泊生态健康受到威胁[1]。
2数据来源与研究方法
2.1数据来源
本研究选用2014年7月—2015年6月抚仙湖湖体15个监测点的6种监测指标——pH值、溶解氧、化学需氧量、高锰酸盐指数、氨氮、总氮的月平均数据。各监测点样品的采集和分析测试由玉溪市环境监测站完成。研究区域及监测点分布情况见图1,各监测点水质指标12个月监测值月均值见表1。
2.2研究方法
为了使不同监测项指标之间具有可比性,对原始数据进行标准化预处理,转化为无量纲的污染指数,换算公式如下:

表1 抚仙湖湖体监测点主要污染物浓度 (mg/L)

一般水质因子换算公式:
Si,j=ci,j/csi
(1)
式中:Si,j——单项水质因子i在j点的标准指数;
ci,j——(i,j)点的评价因子水质浓度或水质因子i在监测点j的水质浓度,mg/L;
csj——水质评价因子i的水质评价标准限值,mg/L;
特殊水质因子:
①DO的标准指数
(2)
(3)
式中:SDO,j——DO的标准指数;
DOf——某水温、气压条件下的饱和溶解氧质量浓度,mg/L。
计算公式常采用:
DOf=486/(31.6+T)
(4)
式中:T——水温,℃;
DOj——溶解氧实测值,mg/L;
DOS——溶解氧的水质评价标准限值;
②pH值的标准指数
SpH,j=(7.0-pHj)/(7.0-pHsd)pHj≤7.0
(5)
SpH,j=(pHj-7.0)/(pHsu-7.0)pHj>7.0
(6)
式中:SpH,j——pH值的标准指数;
pHj——pH值实测值;
pHsd——《地表水环境质量标准》中规定的pH值下限值,取6;
pHsu——《地表水环境质量标准》中规定的pH值上限值,取9。
抚仙湖湖体水质评价标准值采用《GB3838-2002 地表水环境质量标准》一级标准。地表水评价标准如表2所示。
将表1中各监测点主要污染物的月均值通过(1)~(6)式进行标准化处理后,得到标准化数据矩阵如表3所示。

表2 地表水评价标准(Ⅰ类)

表3 标准化矩阵
3数据处理
将表3中各监测点数据进行模糊聚类分析,采用SPSS16.0软件计算,聚类方式选择组间平均连接法(Between groups linkage),距离测量选择欧式距离平方(Squared Euclidean Distance)。
4结果分析
计算结果如表4、表5、表6和图2所示。

表4 案例描述
由表4可得:用聚类法分析的有效案例数为15个,无遗漏值。
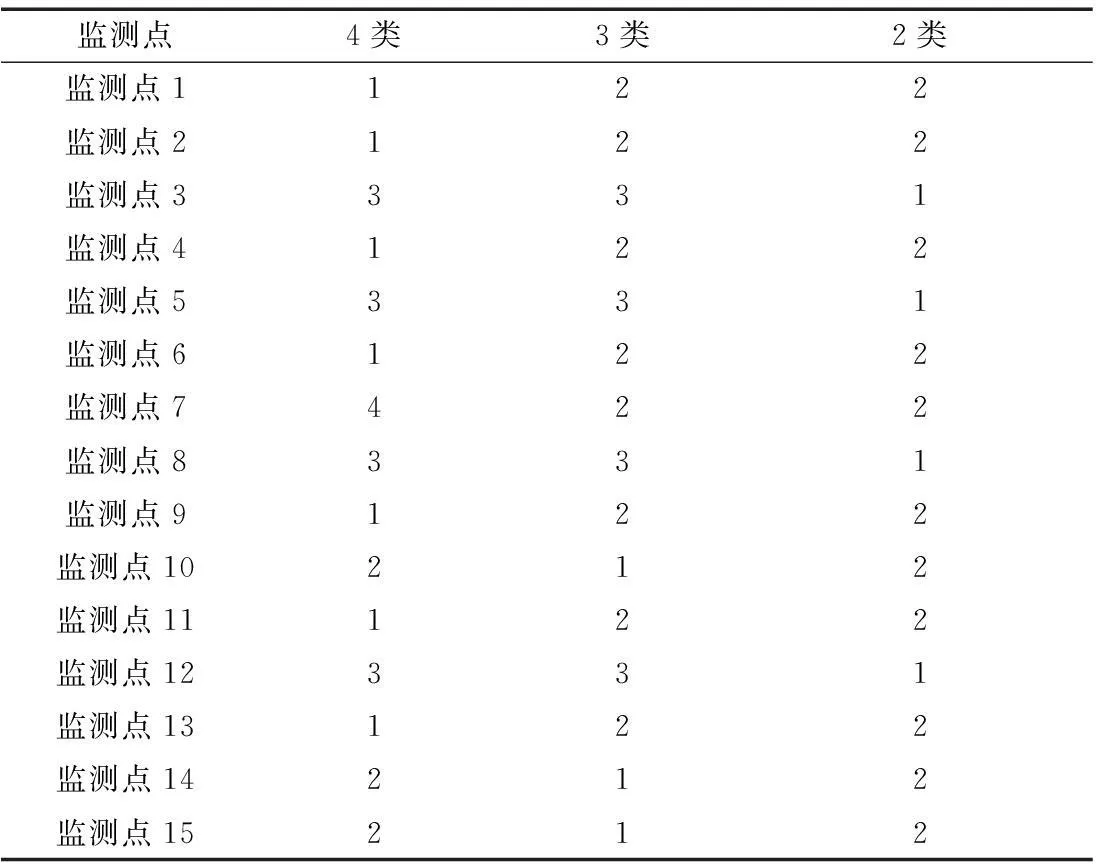
表5 聚类解(2类、3类、4类)
由表5可知:用欧式距离平方,组间平均法生成了2类、3类、4类的聚类解。如分为2类时就是Ⅰ类(监测点3、5、8、12),Ⅱ类(监测点1、2、4、6、7、9、10、11、13、14、15);分为3类就是Ⅰ类(监测点10、14、15),Ⅱ类(监测点1、2、4、6、7、9、11、13),Ⅲ类(监测点3、5、8、12);分为4类就是Ⅰ类(监测点1、2、4、6、9、11、13),Ⅱ类(监测点10、14、15),Ⅲ类(监测点3、5、8、12),Ⅳ类(监测点7)。
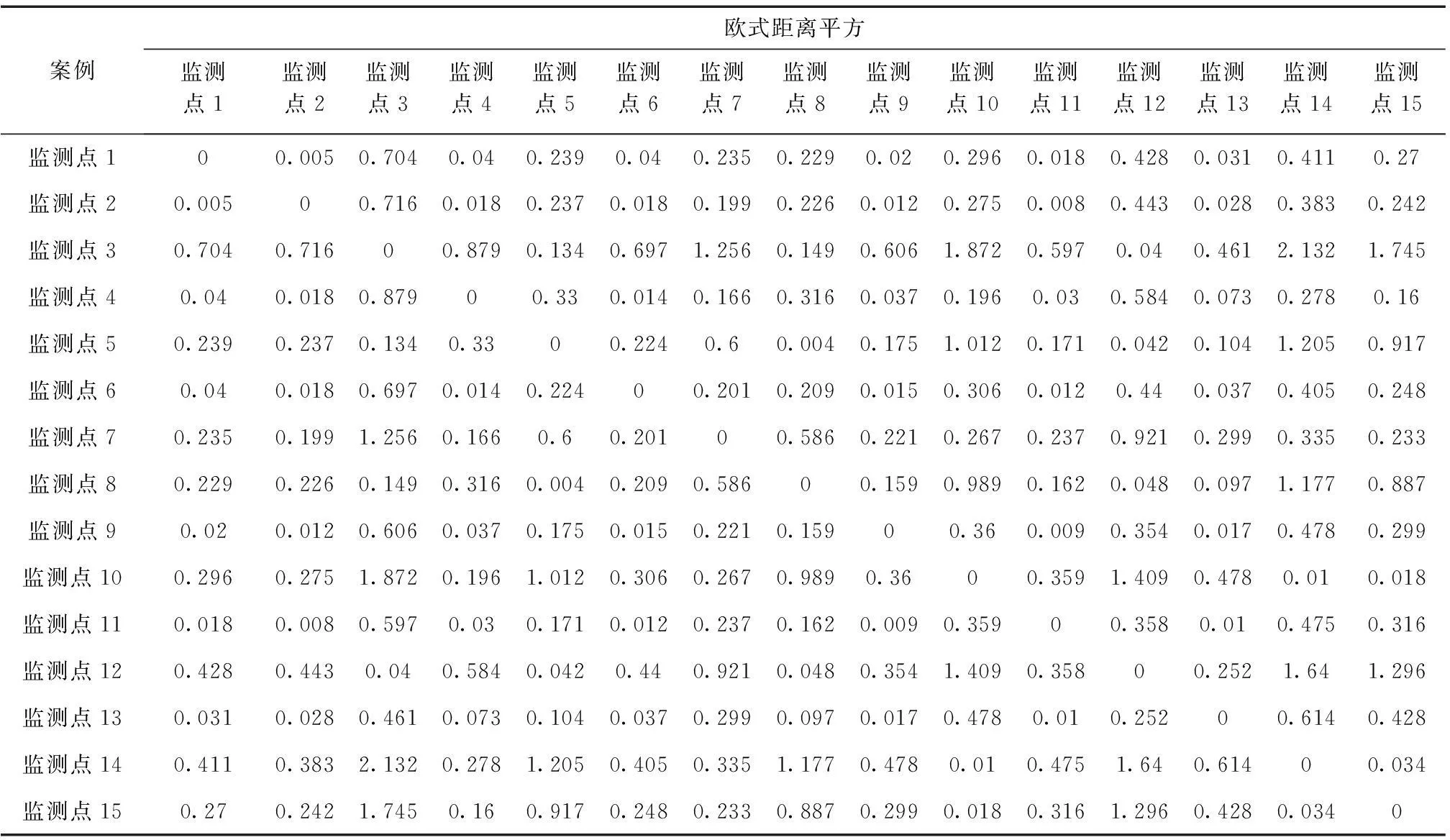
表6 相似性矩阵
表6描述的是各个监测点之间的欧式距离平方值,相同的监测点之间的欧式距离平方值为0。不同监测点之间的欧式距离平方值越小,说明监测点之间的相似程度越大,容易归为一类,反之,各监测点间的欧式距离平方值越大,其相似程度越小,不易归为一类。
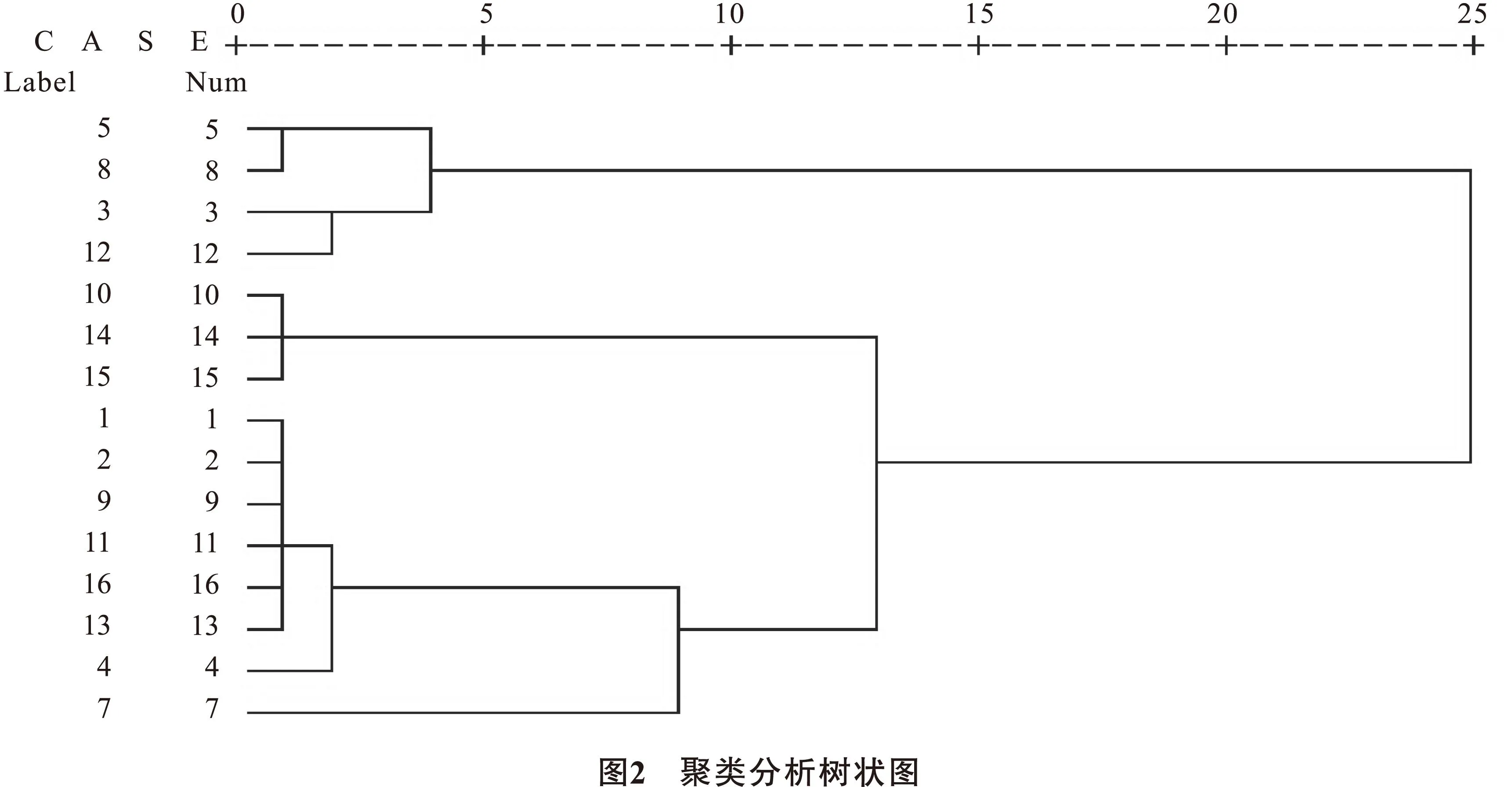
将抚仙湖15个监测点分为4类,聚类分析树状图如图2。
根据聚类分析结果,各类监测点分布示意图如图3~图6所示。
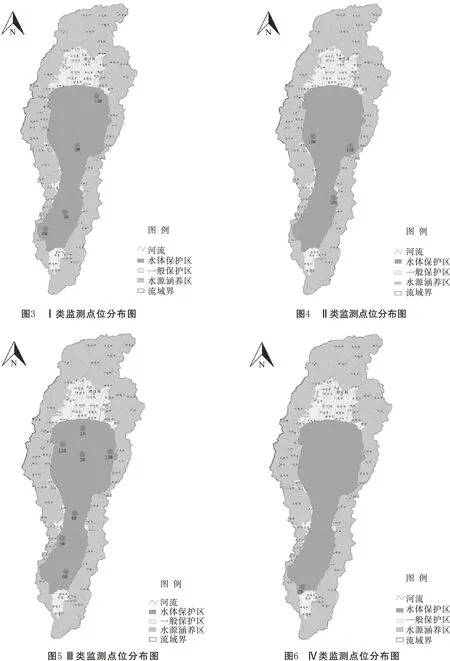
由图2可知,Ⅰ类(监测点3、5、8、12)的4个监测点中,监测点5和监测点8距离较近,可以将这2个监测点优化为1个点,优化后的监测点布设在原监测点5和监测点8之间,该点可命名为监测点16。由图4可知,Ⅱ类中的监测点10、监测点14和监测点15几乎是均匀分布在抚仙湖中,监测点14和监测点15均分布在抚仙湖东侧,可以优化为1个点,建议保留监测点14。由图5可知,Ⅲ类(监测点1、2、4、6、9、11、13)的7个监测点中,监测点1、监测点2和监测点11这3个点分布的距离较近,可以优化为1个点,优化后的监测点布设在原监测点1、监测点2和监测点11组成的三角形区域内,该点可命名为监测点17。由图6可知,第Ⅳ类仅有监测点7,无需优化。通过聚类分析优化后的监测点分布情况如图7所示。

5结论
基于抚仙湖湖体水质监测数据,采用层次聚类分析法对不同监测点进行聚类分析,可得出以下结论:
(1)Ⅰ类中的5个监测点(3、5、8、12)可优化为3个监测点(3、12、16)。
(2)Ⅱ类中的3个监测点(10、14、15)可优化为2个监测点(10、14)。
(3)Ⅲ类中的7个监测点(1、2、4、6、9、11、13)可优化为5个监测点(4、6、9、13、17)。
(4)第Ⅳ类仅有监测点7,无需优化。
参考文献:
[1]高伟,陈岩,徐敏,等.抚仙湖水质变化(1980—2011年)趋势与驱动力分析[J].湖泊科学,2013,25(5):635-642.
[2]Dodds WK,Bouska WW,Eitzmann JL et al.Eutrophication of US freshwaters: analysis of potential economic damages[J].Environmental Science & Technology,2009,43(1):12-19.
[3]张旋,王启山,于淼,等. 基于聚类分析的水质标识指数和水质评价方法[J]. 环境工程学报, 2010, 4( 2) : 476-480.
[4]张璘,郝英群,姜勇.江苏省地表水监测断面优化调整的构思[J]. 环境监控与预警, 2011, 3(2):54-56.
[5]马飞, 蒋莉.河流水质监测断面优化设置研究——以南运河为例[J].环境科学与管理,2006,31(8):171-172.
[6]陈森平,陈启买,吴志杰.基于核函数的层次聚类算法[J].暨南大学学报:自然科学版,2011,32(1):31-35.
[7]中国科学院南京地理与湖泊研究所.抚仙湖[M].北京:海洋出版社,1990.
Application of the Hierarchical Clustering Algorithm in Optimizing the Distribution of Water Quality Monitoring Points
ZHANG Yue-xia1, MAO Jin-long2
(1.Yunnan Institute of Environmental Science, Kunming Yunnan 650034 ,China)
Abstract:On the basis of the original monitoring data of pollution indices in Fuxian Lake from July of 2014 to June of 2015, the hierarchical clustering algorithm method in SPSS were applied to cluster the monitoring points. The relationships of monitoring points were studied and compared. In the end, the monitoring points were optimized from 15 to 11 in terms of the properties of the points based on the method.
Key words:monitoring site; SPSS; hierarchical clustering algorithm; optimization; Fuxian Lake
中图分类号:X52
文献标志码:A
文章编号:1673-9655(2016)01-0020-06
作者简介:张月霞,女,硕士,工程师,主要从事环境水力学及水污染治理研究。
收稿日期:2015-09-25
