一种改进查询优化算法的具体应用
2016-02-27张国华
张国华
(南京师范大学泰州学院,江苏 泰州 225300)
一种改进查询优化算法的具体应用
张国华
(南京师范大学泰州学院,江苏 泰州 225300)
我国新型农村合作医疗系统(以下简称新农合)采用了分布式数据库系统,即数据分布在不同的主管部门与不同的数据库服务器上,各个部门对于数据的查询频率及数据的反馈速度要求较高,但业务流程中在涉及查询时的数据来源复杂,传统的一些查询算法所消耗的时间代价、空间代价过高。针对上述问题,文中通过对分布式数据库系统的简化,建模出代价模型查询图,提出基于贪婪的优化算法并给出了数据查询迭代方案,解决了在分布式数据库查询连接优化的问题。实验结果表明,改进后的优化算法能明显缩短查询时间,并通过系统上线测试对比,证明该算法是有效可行的。
新农合;分布式数据库;连接优化;算法时间代价
0 引 言
新农合的分布式数据库(DBMS)[1]是把数据分散在网络的不同服务器上,而总体上属于相同系统的数据子集,它是数据库技术与网络技术结合的产物,提供了一种更高层次的大数据服务。而在新农合系统中参合数据、门诊数据、药品等数据分布在省厅、各县市乃至各镇村等医疗卫生服务部门服务器,因此对数据的查询变得复杂,对查询反馈的时间要求非常高。因此查询连接减少算法时间与空间复杂度成为分布式数据库系统中要解决与优化的一个核心问题。为解决该问题,学者们提出了很多查询优化算法。其中比较著名的有基于直接连接的查询优化、基于半连接的查询优化、基于蚁群算法[2]的智能优化。这些算法大多仅从局部某一方向做了优化。
为了更好地提高新农合系统的整体性能,解决新农合数据连接整合效率,尝试从新农合的系统总体架构入手,结合分布式数据库系统特点,文中设计了基于贪婪优化策略[3-5]的查询的连接优化算法。通过数据计算与模拟,采用多步决策,逐步处理,将新农合系统的查询节点逐一合并,力求最优。对数据库查询问题,采用查询图[6]对问题进行空间描述,通过代价估算,检验算法的优越性。
1 系统总体优化目标与方案
1.1 系统总体优化目标
新农合分布式数据库管理系统,数据分散在农村卫生服务站、医疗卫生单位、卫生行政主管单位、保险公司等部门,需要同时对多部门的节点进行数据的协同与并行处理,并采用优化策略分散一些特别负荷大的节点任务,使得系统整体顺畅运行,但该优化操作同时也会造成一些额外的通信开销。因此,系统优化的总体目标是充分发挥优势,缩减不利影响,从而达到提高新农合分布式数据库系统整体性能的目的。
结合该系统业务量大、数据分散等特点,主要从以下两方面进行考虑:
(1)系统最短响应时间[7]:系统响应用户操作时间最短。
(2)最大吞吐量:系统能同时尽量多地完成的数据处理任务。
因为新农合是一项惠民政策,要求做到即时结算报销,系统要求实时性强,因此文中主要以缩短系统响应时间作为主要目标来优化。
1.2 确定优化方案
查询优化方法主要有两类:一类是静态优化,另一类是动态规划。静态优化主要是依据数据已有目录中统计数据预先对数据做估计,一般情况下,这种估计不准确,所以这种优化质量较低。而动态规划的基本原理是按照每一步的中间结果进行逐步优化,优化质量更高,但因其边执行边优化,这种做法固然大大提高了优化质量,但其通信开销却大幅度增长。
该系统则汲取这两种方法所长,取折中方案,即先根据静态优化方法结果来执行,接着计算静态优化方案中的数据统计结果与实际数据值偏差的绝对值是否在预先设定的范围内,如超出则调用动态规划方案来取代之前的静态优化方案。如何取舍多种执行方案,前人采用了穷举的方法[8]来对所有方案进行统计对比,但其工作量巨大。文中则创新地先采用启发式规则对所有方案进行初步筛选,然后再依据消耗代价统计确定最终选择方案。
2 查询代价构成
2.1 代价构成
无论是集中式数据库管理系统,还是分布式数据库管理系统,查询消耗的代价主要指执行查询消耗的时间开销,由三部分组成:外存储器访问代价(即I/O代价);数据处理代价(即CPU代价);通信代价(即传输代价)。分布式数据库系统中,因其数据分布在网络的若干节点上,相对而言通信代价在整个查询执行代价中占比最高,是查询执行代价应该考虑的主要方面。
2.2 建模查询图
设有A,B,C,D四个关系数据库分布在网络的若干节点,它们的数据量分别为10,5,20,15,它们之间的拓扑关系及通信距离见图1。
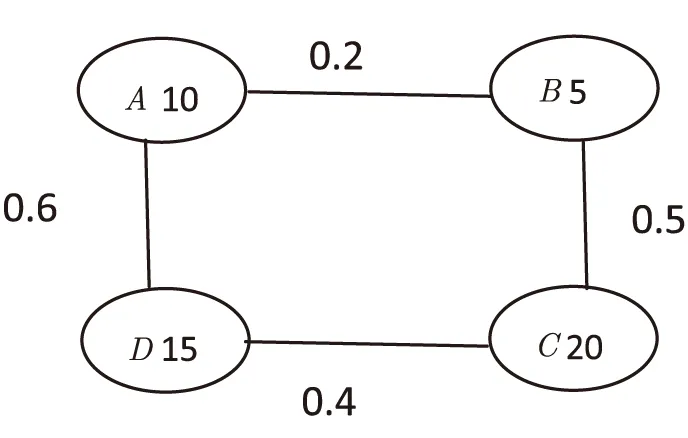
图1 建模查询图
不同网络对于查询的处理机制各不相同。大多情况,数据在网络上的通信时间要大于内部各节点通信数据处理时间,文中为简化问题,查询访问的I/O代价和CPU处理代价暂不考虑,只从通信代价方面着手研究。
2.3 通信代价模型
在传输过程中有两种影响:费用和延迟。其中费用起决定作用。按传输费用衡量是指使通信中的整个传输开销最小,即传输的数据量最小。
模型为:
CCOM(X)=C0+C1*X
其中,C0为场地间传输数据的启动所需的固定费用(启动一次),简称启动代价;C1为网络单位传输数据费用,简称单位传输代价;X为需传输的数据量。
3 基于查询图的贪婪算法
3.1 算法介绍
贪婪算法[9-11]是一种优化的分级事件处理方法,其主要核心是依据要求选择某种度量法则,将多个输入按照这种量度法则所规定的顺序进行。假如这个输入与当前构成在这种量度法则意义下的部分最优解加在一起并不能产生可行解,则舍去这个。这种能够得到在某种量度法则下最优的依次分级处理方法就是贪婪算法。文中借助此方法进一步优化该方案,即在相关部门连接查询的过程中,采用中间查询反馈的结果值来虚拟表示当前消耗的通信代价,从而在不同的分布式数据节点连接查询过程中,不断找出查询消耗最小代价的中间结果并将其合并,从而降低系统整体查询总代价[12]。
3.2 连接算法设计
依据上述的贪婪算法的总体思路,结合图1,给出具体优化操作步骤:
(1)对相邻的数据服务器节点连接时,首先找出连接所消耗代价[13]最少的连接运算。因此在图中,逐次对相邻节点做连接查询代价计算结果依次为:
CA∞B=10*5*0.2(关系A数据量*关系B数据量*通信距离)=10
CB∞C=5*20*0.5(关系B数据量*关系C数据量*通信距离)=50
CC∞D=20*15*0.4(关系C数据量*关系D数据量*通信距离)=120
CD∞A=15*10*0.6(关系D数据量*关系A数据量*通信距离)=90
根据计算结果可知,当A,B进行连接时,其查询通信代价最小,所以将这两个节点合并,合并结果见图2。新查询图中合并后节点内数值表示当前查询的中间值。
(2)按照(1)同样的方法计算。
CAB∞C=10*20*0.5(关系AB数据量*关系C数据量*通信距离)=100
CC∞D=20*15*0.4(关系C数据量*关系D数据量*通信距离)=120
CD∞AB=15*10*0.6(关系D数据量*关系AB数据量*通信距离)=90
由此看出最小的查询代价为90,应该合并AB与D得出如图3所示的查询结构图。
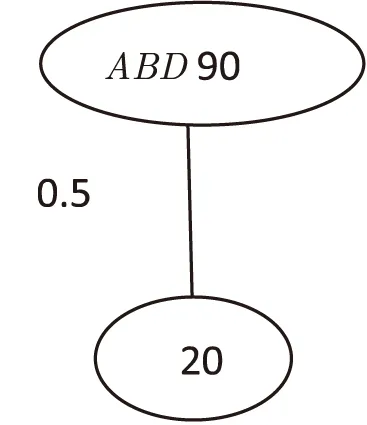
图3 ABD合并后查询图
(3)最后执行ABD与C的合并,查询代价为:
CABD∞C=90*20*0.5=900
至此整个系统的查询近似代价总和为:
CA∞B+CAB∞D+CABD∞C=10+90+900=1 000
其查询顺序因为(((A∞B)∞D)∞C),根据上述过程分步转换,查询的优化处理最后得出如图4所示的查询树结构。
3.3 算法对比及实验对比
(1)算法对比。
根据图1所示的查询图,采用不同的连接方案,所消耗的查询代价也各不相同。表1给出了通过计算所有不同连接方案所消耗的查询代价[14]。
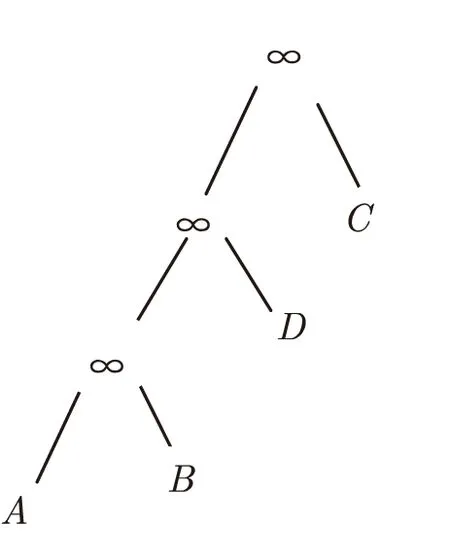
图4 优化查询树
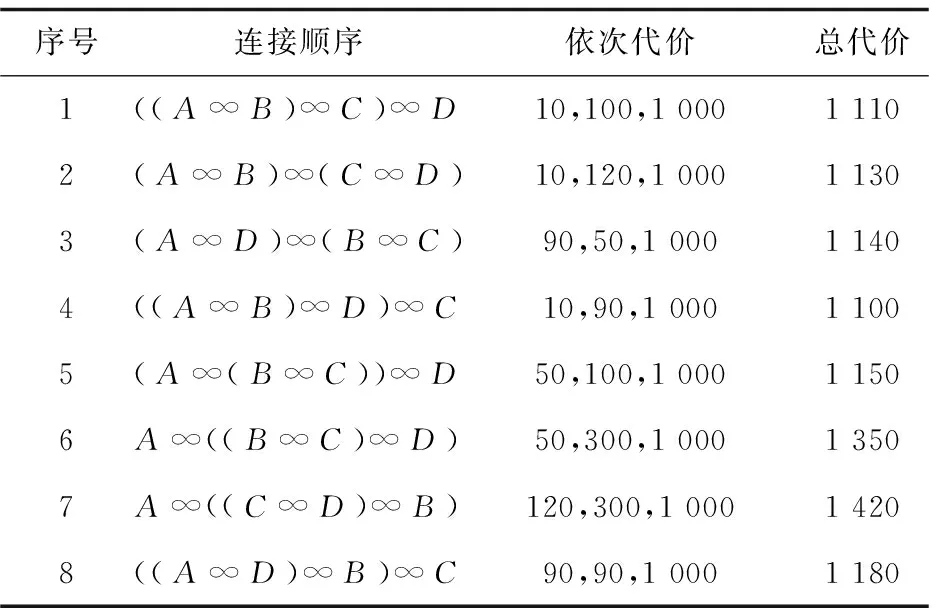
序号连接顺序依次代价总代价1((A∞B)∞C)∞D10,100,100011102(A∞B)∞(C∞D)10,120,100011303(A∞D)∞(B∞C)90,50,100011404((A∞B)∞D)∞C10,90,100011005(A∞(B∞C))∞D50,100,100011506A∞((B∞C)∞D)50,300,100013507A∞((C∞D)∞B)120,300,100014208((A∞D)∞B)∞C90,90,10001180
从表中可以看出,对于任何一种查询连接它的最后一步的中间查询代价都为1 000,对于各种不同的连接顺序,其中间消耗的查询代价都不相同,从而引起查询消耗总代价也有区别。表1数据表明,采用文中优化的查询算法的方案4的总代价为1 100,是所有方案中消耗查询总代价最小的。
(2)实验分析与测试。
此次实验利用方案4所不同地点的服务器分别为A,B,C,D。服务器的操作系统均为Windows2003Server,CPU主频为2.4GHz,内存为4GB,数据库管理系统均为SQLServer2005版本。
A服务器为基层农民参保信息采集点数据库,其存储了农民参保采集信息表(农保编号,姓名,性别,出生年月……),数据量为100 000条元组。
B服务器为某医院HIS数据库[14],其存储了农民门诊住院记录(农保编号,姓名,性别,医疗费用……),数据量为50 000条元组。
C服务器为卫生行政主管部门数据库,其存储了新农合数据统计信息表(农保编号,姓名,费用,报销总计……),数据量为200 000条元组。
D服务器为负责新农合报销的保险公司结算中心数据库,其存储了新农合报销记录表(农保编号,姓名,费用,报销时间……),数据量为150 000条元组。
A-B节点的通信距离为20,B-C节点的通信距离为50,C-D的通信距离为40,A-D之间的通信距离为60。
通过检索命令,按照表1的连接方法连接检索数据得到的实验结果见表2。

表2 实验结果表 s
上述8种情况考虑了所有的连接情况,并且方法4是采用文中算法的连接方案。实验证明,该连接算法能显著缩短查询总时间,提高查询效率。
4 结束语
在传统的分布式数据查询技术处理的基础上,文中给出了一种能在分布式数据库系统提升查询效率的方法。通过理论分析及实验对比,均能显著提升查询效率。在新农合系统分布式数据的使用中,表明其能进一步缩短数据检索响应时间,提高新农合相关单位的工作效率。
[1] 徐济惠.嵌入式数据库多连接查询优化算法的研究[J].宁波大学学报:理工版,2008,21(2):206-210.
[2] 谢文兵,戴塔根,徐祖明.基于GRWSM协议的分布式空间数据处理技术[J].计算机测量与控制,2011,19(4):981-983.
[3] 微软公司.QueryingMicrosoftSQLServer2000WithTransact-SQL[M].北京:清华大学出版社,2001.
[4] 张小波,成良玉,钟闰禄.建立动态群组的多Agent协同模型及应用[J].计算机应用,2004,24:52-53.
[5] 李瑞轩,霍晓丽,文珠穆,等.多数据库系统中的全局查询转换方法研究[J].计算机工程,2005,31(16):4-6.
[6] 姜爱福,李长云.分布式查询优化的技术实现[J].计算技术与自动化,2005,24(1):72-73.
[7] 陈 波,高秀娥,陈来杰.基于等价变换的分布式查询优化方法研究[J].计算机工程与设计,2006,27(3):390-392.
[8] 赵鹏军,刘三阳.求解复杂函数优化问题的混合蛙跳算法[J].计算机应用研究,2009,26(7):2435-2437.
[9] 陈 静,向隆刚,朱欣焰.分布式异构栅格数据的集成管理研究[J].武汉大学学报:信息科学版,2011,36(9):1094-1096.
[10] 邵佩英.分布式数据库系统及其应用[M].北京:科学出版社,2003.
[11]GilbertS,LynchN.Brewer’sconjectureandthefeasibilityofconsistent,available,partition-tolerantwebsen,ices[J].SigactNewsletter,2002,33(2):51-59.
[12]BacaR,KratkyM.TJDewey-ontheefficientpathlabelingschemeholisticapproach[M]//Databasesystemsforadvancedapplications.[s.l.]:[s.n.],2009.
[13]VogelsW.Eventuallyconsistent[J].Queue,2008,6(6):14-19.
[14]ElmasriR,NavatheSB.Fundamentalsofdatabasesystems[M].4thed.Beijing:ChinaMachinePress,2009.
A Specific Application for Improved Query Optimization Algorithm
ZHANG Guo-hua
(Taizhou College of Nanjing Normal University,Taizhou 225300,China)
China’s New Rural Cooperative Medical System (NRCMS) adopts the distributed database system.Data distribution in different authorities with different database servers,each department for the query frequency and data feedback speed has higher requirements,which involves complicated data resources in the working process,but the traditional query algorithm costs too much time and space.Aiming at these problems,through a distributed database system simplification,modeling query image of cost model,an optimization algorithm based on the greedy is proposed and the iterative scheme for data query is given,which solves the problem of connection in a distributed database query optimization.The experiments show that the improved optimization algorithm can significantly shorten the query time,and the on-line system test comparison demonstrates the algorithm is effective and feasible.
NCMS;distributed database;connection optimization;algorithm time cost
2014-12-10
2015-05-13
时间:2016-06-22
教育部Google2014年产学合作专业综合改革项目(PO640068);泰州市软科学研究计划项目(SRK20160005)
张国华(1981-),男,讲师,研究方向为分布式数据库。
http://www.cnki.net/kcms/detail/61.1450.TP.20160621.1701.002.html
TP311
A
1673-629X(2016)07-0112-04
10.3969/j.issn.1673-629X.2016.07.024
[3] 洪妍妍.手指静脉识别原型系统的设计与实现[D].济南:山东大学,2011.
[4] 余成波,秦华锋.生物特征识别技术手指静脉识别技术[M].北京:清华大学出版社,2009.
[5] 高 嵩.手指静脉图像采集装置设计[D].长春:长春理工大学,2009.
[6] 袁 智.手指静脉识别技术研究[D].哈尔滨:哈尔滨工程大学,2007.
[7] 管凤旭.基于流行学习及可拓分类器的手指静脉识别研究[D].哈尔滨:哈尔滨工程大学,2010.
[8]CrisanS,TarnovanIG,CrisanTE.Radiationoptimizationandimageprocessingalgorithmsintheidentificationofhandveinpatterns[J].ComputerStandards&Interfaces,2010,32(3):130-140.
[9]WuXiangqian,GaoEnying,TangYoubao,etal.Anovelbiometricsystembasedonhandvein[C]//Proceedingsofthe2010fifthinternationalconferenceonfrontierofcomputerscienceandtechnology.[s.l.]:[s.n.],2010:522-526.
[10]ChenHaifen,LuGuangming,WangRui.AnewpalmveinmatchingmethodbasedonICPalgorithm[C]//Proceedingsofthe2ndinternationalconferenceoninteractionsciences:informationtechnology,cultureandhuman.Seoul,Korea:IEEE,2009:1207-1211.
[11] 马文科,王 玲,何 浩.一种指纹图像的局部阈值分割算法[J].计算机工程与应用,2009,45(34):177-179.
[12] 苑玮琦,王 楠.基于局部灰度极小值的掌脉图像分割方法[J].光电子·激光,2011,22(7):1091-1096.
[13] 苑玮琦,咸 阳.非接触成像手指节纹检测算法[J].计算机系统应用,2014,23(8):144-149.
[14]YuanWeiqi,ZhangTianwen.Valleytypeedgedetectionmethodbasedonlogicjudgment[J].JournalofImageandGraphics,2001,6(6):577-581.
