一种团购商品的个性化推荐算法研究
2016-02-24闫晓珊米红娟
闫晓珊 米红娟
一种团购商品的个性化推荐算法研究
闫晓珊 米红娟
兰州财经大学信息工程学院,兰州 730020
团购商品凭借其价格优惠和能够亲身体验的优势越来越得到人们的青睐。为帮助团购网站实现个性化营销,将用户购物过程中的上下文环境因素融入到传统的推荐算法中,提出了一种基于上下文感知的推荐算法,基于用户相似和物品相似中加入上下文信息相似,构造了计算商品预测评分的公式,进而得到推荐列表,使个性化推荐体现得更加充分。
团购;推荐;上下文感知
引言
近年来,上下文感知推荐系统(Contextaware Recommender System,简称CARS)已成为国外各大学和研究机构在推荐系统方面研究的热点。G.Adomavicius[1]等人提出把上下文信息融入到推荐过程中存在三种情况——上下文信息预过滤,上下文信息后过滤和上下文信息建模。H.Negar[2]等人提出的交互式推荐系统可以根据用户的动态行为探测和适应上下文的变化生成匹配用户最近偏好的推荐。Augusto Q.Macedo[3]等人提出了一种综合了社区信息,项目自身的属性信息,地理位置信息和时间信息四种信息维度的推荐方法,有效地解决了项目冷启动的问题。
目前,国内在上下文感知推荐方面的研究还处于实验阶段,不过已经涉及到了推荐系统应用的许多方面。比如,北京邮电大学的李晟[4]研究了一个基于上下文因素的电影推荐模型,用用户性别、用户类型、用户心情三种上下文信息计算用户的观影偏好度,根据其大小给出推荐列表;上海交通大学的陈杰[5]设计了一个应用于大型购物中心的推荐系统,根据人口统计学信息和时间因素生成用户的偏好模型,利用历史购物信息过滤掉热门商户,最后应用规则引擎,进行偏好模型匹配。但是在团购商品的个性化推荐应用方面,还很少有人涉及。
自从世界首家团购网站美国Groupon问世以来,团购销售模式立即博得了电商企业的关注。各家企业为了获得最大的用户满意度和忠诚度,都在不断努力提高网站的服务质量。本文结合用户的多种上下文信息,研究一种个性化推荐方法,以帮助团购网站提高服务质量,增加客户流量和用户忠诚度。
1 相关知识介绍
1.1 上下文感知相关理论
在电子商务应用领域,上下文信息的获取有多种方式,主要包括显式获取,隐式获取和推理获取。传统的推荐系统主要在于构造一个二维评分预测模型R:User×Item→Rating,给用户推荐评分最高的项目,其中Rating表示用户项目评分矩阵,矩阵的两个维度分别是User和Item。随着上下文信息的融入,将传统的二维模型扩展到一个三维空间范围上,构造一个三维评分预测模型 R:User×Item×Context→Rating,其中Rating表示用户项目评分矩阵,矩阵中的元素代表某个User对某个Item在特定Context中的评分,上下文在融入到推荐过程中可分为三种情况,即上下文信息预过滤,上下文信息后过滤和上下文信息建模。
上下文信息预过滤是在推荐之前利用上下文信息筛选出最相关的用户项目数据,然后在筛选出的结果数据上采用传统的推荐方法产生推荐。在这种方法里上下文信息作为检索而发挥作用,其优点是可直接应用任何传统的推荐方法。但是,如果信息太过精确,可能会漏掉一部分有用的用户项目数据,为了得到更高的推荐准确度,往往使用相对泛化的上下文信息。泛化预过滤方法[6]就是以这种思路来解决这个问题的。
上下文信息后过滤是在产生推荐结果之后利用上下文信息调整推荐列表的方法,一般有两种作用:一是过滤掉和上下文不相关的推荐;二是调整推荐列表的排名顺序。和上下文信息预过滤方法一样,上下文信息后过滤方法也可以直接应用任何传统推荐方法。
上下文信息建模是把上下文信息直接融入到推荐模型中的方法。预过滤和后过滤都可以应用传统的二维推荐模型,但是建模的方法是处理真正的多维数据问题。建模可分为两种类型:启发式方法和基于模型的方法。比如:A.Ansari[7]等人在传统的二维推荐方法上是把用户和项目信息结合到基于贝叶斯分层回归的偏好模型中,之后把这种方法扩展到三维空间,把用户、项目和上下文信息结合到偏好模型中。
1.2 协同过滤推荐算法
协同过滤算法[8]的出现标志着推荐系统的产生,分为两大类:基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。
基于用户的协同过滤推荐算法:假设如果两个用户对同一个项目的评分相似,那么他们对其它项目也具有相似的评分。算法主要包括两个步骤:(1)计算用户相似度找到和目标用户相似的用户集合;(2)找到相似用户喜欢的项目集合,并且把没有和目标用户交互过的项目推荐给目标用户。这种方法最大的不足之处是如果相似用户只对很少的项目给了评分或者目标用户为新用户时将大大降低推荐性能,即数据稀疏性问题和冷启动问题对推荐结果的影响很大。
基于项目的协同过滤推荐算法:基于项目的协同过滤推荐算法是给用户推荐那些和他们之前喜欢的项目相似的项目,也分为两个步骤进行:(1)计算项目间的相似度;(2)根据项目相似度和用户的历史评分信息来生成推荐列表。由于用户历史信息在推荐过程中发挥较大作用,所以这种方法不适用于为新用户进行推荐。
2 基于上下文感知的协同过滤推荐算法
用户在团购过程中的上下文信息可以分为两种类型,一种是用户的属性信息,来自于人口统计学数据;另一种是用户的偏好信息,一部分是对商品的偏好,一部分是对外部环境因素的偏好。偏好的存在是因为每个人都有自己与生俱来的个性,就像有的人喜欢红颜色,有的人喜欢蓝颜色,应用到商品和环境上也是如此。传统的协同过滤推荐方法是通过计算相似度,生成推荐列表两步完成。
本文对传统方法的两个步骤分别加以改进,首先基于用户属性信息对用户进行聚类,然后以每个用户类为处理单元,计算候选商品的得分,最后通过比较得分的大小生成推荐结果。
2.1 用户聚类
根据用户属性信息计算相似用户基于一个假设:属性信息相似的用户更倾向于购买相似的商品。通过对用户的人口统计学数据进行聚类得到若干个用户群体,处于同一个用户群的用户,用户属性信息接近,更容易购买相似的商品,而处于不同用户群的用户,属性信息差别大,相应地,购买的商品相似度小。
2.2 预测商品得分
在把用户分为不同的类别之后,和目标用户处于同一类的用户购买的商品都作为给目标用户推荐的候选商品。同一类中的用户行为的不同主要受到用户偏好信息的影响,偏好信息越接近,用户行为也就越相似。
2.2.1 计算相似物品
根据商品属性信息得到购买相似商品的用户基于假设:购买过相似物品的用户的购买行为相似。商品根据自身的类别、价格、网站评分等信息可以大致分类,类别代表了消费者的购物习惯,价格代表了消费者的购物能力,网站评分说明了商品的热门程度,属于同一类别、同一价格范围和同一评分范围的商品可以看作是相似商品。假设整个用户商品集合共有n个商品,记为{Y1,Y2……Yn},每个商品有m个特征属性,即Yi={Yi1,Yi2,Yi3……Yim},商品间相似性的计算采用余弦相似性,即
其中Ya和Yb表示两个不同的商品向量,‖Ya‖与‖Yb‖分别为它们的长度,上式分子表示这两个商品向量的内积,分母表示这两个商品向量长度的乘积,对每个商品选择k个相似度最大的商品构成其最近邻集合。
2.2.2 计算相似上下文
地域性团购商品和其他电子商务商品最大的不同就是用户的消费过程是在线下完成的,因此人们出行的种种因素均会影响到用户选购商品的过程,比如某个用户通过浏览商品信息,找到了比较满意的商品,但是碍于商家店铺距离较远,很可能放弃这个商品。同样,根据上下文信息得到购买行为发生在相似上下文下的用户基于一个假设:在相似上下文下发生过购买行为的用户的购买行为相似,这里的上下文主要考虑外部环境因素,比如:时间,距离,天气等。给定两个不同的上下文向量Za和Zb,用余弦相似性计算上下文相似度,即
2.2.3 计算预测评分
根据用户属性信息将数据集分为k个子集,之后的推荐工作在目标用户所处的子集上进行。设目标用户的相似用户集合为U={u1,u2……un}(n为用户数量),将U中每个用户购买的商品集中起来,构成商品集合I,I={i1,i2,i3……im}(m为商品数量)。
假设目标用户购买了商品j,通过计算相似物品,在集合I中寻找与j相似的商品;再通过计算相似上下文,寻找与目标用户购买商品j时的上下文相似的上下文,以及在该上下文下发生购买行为的用户和购买的商品。通过这两步,目的是筛选出在同时考虑商品属性和上下文信息时,与目标用户购买的商品相似性大的商品,同时减少候选集合I里的商品数目。
经过以上处理,分别得到两个商品集合,取两集合的交集,构成候选推荐商品集合M,然后基于M中商品i与目标用户购买的商品j之间的相似度,以及对应的上下文相似度,构造相对于目标用户购买的商品j的M中商品i的预测评分的计算式:
其中,sim(yi,yj)表示商品i与目标用户购买的商品j的相似度,sim(zi,zj)表示相应的上下文相似度,p表示商品i在团购网站的评分,p0表示目标用户所处的子集上的所有用户购买的商品在团购网站上评分的均值,w表示购买i的用户对其本次购买行为的满意度评价,w0表示目标用户所处的子集上的所有用户对其购买行为满意度评价的均值。
商品评分和满意度评价与它们的均值相比,一方面表示两个相似度的权重,另一方面可减少因人为因素造成的偏置,比如在五分制的评级中,有的人不愿意给5分,更乐意给4分,将评分与均值相比减少了类似情况造成的影响。
2.3 生成推荐
经过以上工作,得到候选商品集合中的每个商品的预测评分,按从高到低的顺序对候选商品进行排序,生成推荐列表,然后将排在列表前面的商品推荐给用户。
3 实验与分析
本文的实验数据来自自主设计的调查问卷,共回收有效答卷350份,采集到了关于团购消费者的三个维度上的信息,用户基本信息包括年龄、婚姻、受教育程度、收入、职业;商品信息包括商品类型、价格区间和在团购网站上的评分;上下文信息包括商家位置、路上用时、天气、交通便利情况、消费时间、陪同人及陪同人数,除此之外,还收集了用户对本次消费的满意度评价信息。
实验工具为SPSS 21.0和MATLAB 2012b,用户聚类在SPSS 21.0中完成,相似度和商品预测评分的计算在MATLAB 2012b中完成。
3.1 两步聚类
聚类的方法有很多种,但是大多数都只能处理数值类型的数据,用户的人口统计学信息属于分类属性的数据,SPSS中的两步聚类分析方法[7]可以同时处理连续变量和分类变量,分别使用凝聚聚类方法和分裂聚类方法,对数据进行两次聚类,聚类的性能较好,而且可以自动选择最优化的聚类个数。聚类结果如图1所示。
可看出两步聚类方法将所有用户分为两类,第一类用户有106个,第二类用户有244个,聚类质量尚好。
3.2 计算商品的预测评分矩阵
选择第一类用户,分别提取商品信息和上下文信息,计算两者的相似度矩阵的MATLAB代码如下:
根据公式(1)计算第一类用户的商品预测评分矩阵的MATLAB代码如下:
假设目标用户是序号为1的用户,该用户购买的商品品名为电脑,将商品预测评分矩阵的第一列排序,得分最高的前5个用户信息如表1所示;如果将商品相似矩阵的第一列排序,即按照传统的协同过滤方法生成推荐,得分最高的前5个用户信息如表2所示。

表1 基于商品预测评分矩阵的推荐列表
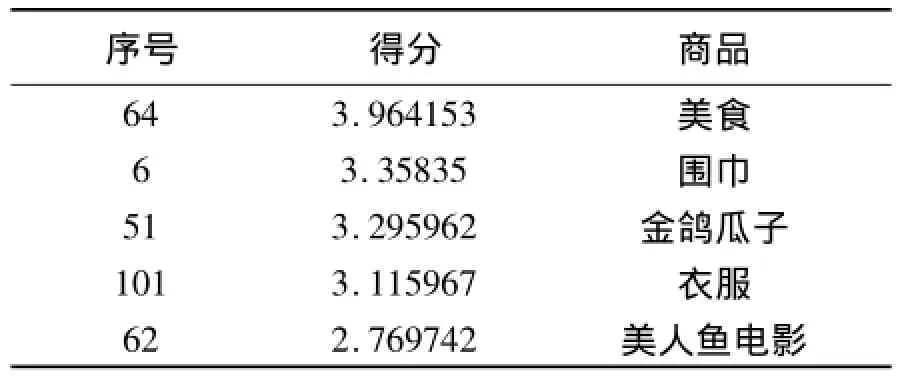
表2 基于商品相似矩阵的推荐列表
3.3 结论
比较表1和表2可以发现,表1中的商品种类多样,表2的商品大部分属于电子设备类,所以将上下文信息融入到推荐算法中,有利于挖掘长尾商品,更大程度地满足用户的个性化需求。用户的需求是多样性的,不可能在团购网站中只购买同种类型的商品,因此,对于团购商品而言,基于上下文感知的推荐算法与传统的推荐算法相比,表现出了更好的推荐性能。
4 结束语
本文提出了一种基于上下文的团购商品个性化推荐方法,和传统的只考虑用户和商品两种信息的算法比较,表现出了较好的推荐性能。因此,融合上下文信息对进行个性化推荐有一定的帮助,不仅有利于挖掘长尾商品,而且能在一定程度上缓解传统方法的数据稀疏性问题。本文所提到的团购商品仅限于地域性商品,并不适用目前各大电子商务网站上的商品推荐。
[1]Adomavicius G,Tuzhilin A.Context-aware recommender systems.Recommender Systems Handbook. Springer-Verlag, 2011, 217-253.
[2]Hariri N,Mobasher B,Burke R.Context adaptation in interactive recommender systems.In:Proc.of the RecSys 2014.New York:ACM Press,2014,41-48.
[3]Augusto Q.Macedo,Leandro B.Marinho,Rodrygo L.T.Santos.Context-aware event recommendation in event-based social networks.In:Proc.of the RecSys 2015.New York:ACM Press,2015,123-130.
[4]李晟.基于情境感知的个性化电影推荐[D].北京:北京邮电大学,2012.
[5]陈杰.智能购物中心情境下上下文感知推荐系统研究与开发[D].上海:上海交通大学,2013.
[6]Adomavicius G,Sankaranarayanan R,Sen S,et al.Incorporating contextual information in recommender systems using a multidimensional approach.ACM Transactions on Information Systems (TOIS),2005,23(1),103-145.
[7]Ansari A,Essegaier S,Kohli R.Internet recommendation systems.Journal of Marketing Research,2000,37(3),363-375.
[8]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[9]吴志强,杨江丽.两步聚类分析在图书馆门禁数据挖掘中的研究[J].四川图书馆学报,2012(3):13-17.
[10]刘超峰,叶枫.团购商品的个性化协同过滤推荐方法[J].经营与管理,2012(11): 121-124.
[11]王立才,孟祥武,张玉洁.上下文感知推荐系统研究[J].软件学报,2012,23(1): 1-20.
A Personalized Recommendation Algorithm Research of Group Purchase Goods
Yan Xiaoshan Mi Hongjuan
Information Engineering College,Lanzhou University of Finance and Economics,Lanzhou Gansu 730020,China
Group purchase goods increasingly get the favor of people by virtue of its concessions and personally experiencing.To help group-buying websites realize personalized marketing and improve their quality,a recommendation algorithm based on context-aware that puts users’shopping context factors into the traditional recommendation algorithm to get the recommend list is realized.This algorithm can join context similarity on the basis of user’s similarity and items similarity and make personalized reflected more fully.
group purchase;recommend;context-aware
TN391.1
A
1672-464X(2016)2-45-06
(责任编辑:张卷美)
闫晓珊(1992-),女,山西,兰州财经大学,硕士研究生,主要研究方向:机器学习,数据挖掘。
