C4.5算法在工程质量决策支持系统中的应用研究
2016-02-23侯立铎
侯立铎,叶 洁
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
C4.5算法在工程质量决策支持系统中的应用研究
侯立铎,叶 洁
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
由于传统的水利工程质量监督管理系统只是起到监管的作用,难以发现并预测工程质量上潜在的问题。针对这一现象,提出了采用决策树C4.5算法对工程质量进行决策支持的解决方案。首先概述了决策树算法和C4.5算法,然后详细阐述了决策支持系统中数据预处理、利用C4.5算法进行数据建模的过程,最后根据建立好的决策树模型开发决策支持系统。实验结果表明:用C4.5算法建立的决策树模型准确率较高,开发的决策支持系统能很好地应用到实际工程质量监督的过程中并达到了预期目的,能较好地对未来工程质量进行预测,给监督部门提供决策支持。
C4.5算法;信息熵;工程质量;Weka
0 引 言
“百年大计,质量第一”,工程质量是一个受到普遍关心和广泛重视的问题。近年来,某省的纪检监察部门所使用的水利工程管理系统大多是面向业务的,很少是面向管理决策的。而且,这些监管部门保留了大量的水利工程质量监督数据。因此,监管部门急切希望能从海量的数据中找出水利工程建设过程中容易出现的问题。文中旨在以工程质量评定数据为依据,采用C4.5决策树算法对历史数据进行分析处理,提取隐含在其中的有价值的信息[1],使纪检监察部门对全省工程有一个全方位、多角度的认识,以利于监管和决策的开展和进行。
1 决策树与C4.5算法简介
1.1 决策树算法
决策树[2]是一种分类算法,其原理是根据已有的样本数据集进行训练和学习,挖掘出一系列分类规则,然后根据这些规则对新的数据进行分类和预测。决策树分类模型呈现为一种树形结构。在决策树中,非叶子节点代表样本数据的各个测试属性,每一个非叶子节点又可以派生出多个分支,每一个分支则代表该测试属性可以选取的一个属性值。叶子节点则代表最终的分类结果,从根节点到叶子节点的每一条路径都被称为决策树的一条分类规则。目前较为经典的决策树算法有ID3算法、C4.5算法、CART算法等[3]。决策树可以处理连续或离散数据,也可以处理较高维的数据。决策树模型结构简单、直观、易于理解、准确度高[4]。决策树算法已广泛应用于各个领域,如医学、天文学、金融学、生物学等[5]。
1.2 C4.5算法
C4.5算法[6]是决策树算法中的一种,它是ID3算法[7]的改进算法。它克服了ID3算法只能处理离散数据的缺点,并以信息增益率作为测试属性选择的标准。由于决策树的生长是一个自上向下的过程,那么优先选择哪个属性作为决策树或者子树的根节点就成为了关键的问题。为解决这个问题,文中引入了信息论中的信息熵[8]概念,以此来描述信息源的不确定度。C4.5算法的原理如下:
设样本集合S中有n个样本,假定分类属性C有m个不同的取值,即Ci(i=1,2,…,m)。设ni为Ci中的样本数,那么分类属性C将样本集S划分为m个类的信息熵可以表示为:
式中,Pi表示任意样本属于分类Ci的概率,可以用ni/n来计算。
在样本的众多测试属性中,选择其中一个测试属性A。假设A有k个不同的取值,同样也可以利用测试属性A将样本集合S划分为k个类别,即Sj(j=1,2,…,k)。此时Aij(i=1,2,…,m,j=1,2,…,k)表示为既属于Sj分类又属于Ci分类的样本数量。那么属性A划分样本集S导致的期望熵可以表示为:
其中,样本子集Sj的信息熵可以表示为:
式中,Pij为Sj中的样本属于Ci分类的概率,可以用Aij/Aj来计算。
这样就可以根据以上信息来计算属性A的信息增益,如下式:
Gain(S,A)=E(S)-E(S,A)
有了测试属性的信息增益,就可以利用信息增益率这个指标来完成对测试属性的选择,信息增益率实际上就等于信息增益/熵。采用信息增益率可以防止决策树倾向于那些属性值种类较多的属性。信息增益率的计算公式如下:
其中:
最后选取信息增益率最大的测试属性作为决策树根节点,并由这个节点产生多个分支,形成决策树的子树。对于每个子树的根节点的选择,则重复之前的工作,以递归的方式最终形成一棵完整的决策树。C4.5算法采用后剪枝的技术[9]对生成的决策树进行剪枝操作,形成最终的决策树模型。根据建立好的决策树模型,生成一系列IF-THEN规则[10],实现对样本分类。
2 工程质量监督决策支持系统的应用
2.1 数据准备及数据预处理
文中研究所选取的数据为某省水利工程质量监督的历史数据。以水利工程中一个单位工程即拦河坝工程为研究对象,将该工程下的子工程作为测试属性,将该工程的评定结果作为分类属性。由于抽取的历史数据存在缺失值、错误值或者不规范等情况,因此要对数据进行数据清洗,去掉“脏数据”。
首先,在收集数据的过程中,由于机器故障或者人为的原因,难免会有缺失数据的情况发生,因此要对缺失的数据进行填充。此处采用最邻近填补法,即选取除缺失值属性以外的其他属性与被填充样本最相似的样本,以它的属性值来填充缺失值。其次在数据录入的过程中,可能会出现误将97分录入成9分等类似的情况,这部分数据也称为噪声数据。因此要清除噪声数据,以免影响最后的实验结果。将样本数据按照某一属性的值从小到大进行排列并将样本数据四等分,将每一等分点的属性值作为一个四分位数,记为Q1,Q2,Q3。一般认为,将1.5倍Q1-Q3之外的数值作为离群点,所以此处将这部分数据去除。最后,每个测试属性的取值为纪检监察部门对该子工程的评分,在此将测试属性的取值进行数值规约[11]。对于工程的施工量,根据其大小分别规约为大型、中型、小型。将子工程评分为60-80分规约为合格,将评分为80-100分规约为优良(子工程评分为60分以下的工程项目需要重新进行质量评定)。
为了方便下文表示,此处将各个子工程用代号表示,整理结果见表1。
最终整理出的质量监督数据见表2。
2.2 Weka数据挖掘平台
Weka[12]是基于Java环境下可以用于机器学习和数据挖掘的一款开源软件。它不但集成了多种经典的数据挖掘算法,而且还提供了二次开发的接口,用户可以使用自己的算法进行数据挖掘分析。分析结果以可视化的方式展示,并可以对多种算法进行性能测试,包括建模速度、准确率等。与很多软件类似,Weka处理的数据集为一个二维表,使用的数据集文件为ARFF格式的文件,这是一种ASCII文本文件,如图1所示。Weka是目前较为完备的数据挖掘工具之一,受到用户的青睐。
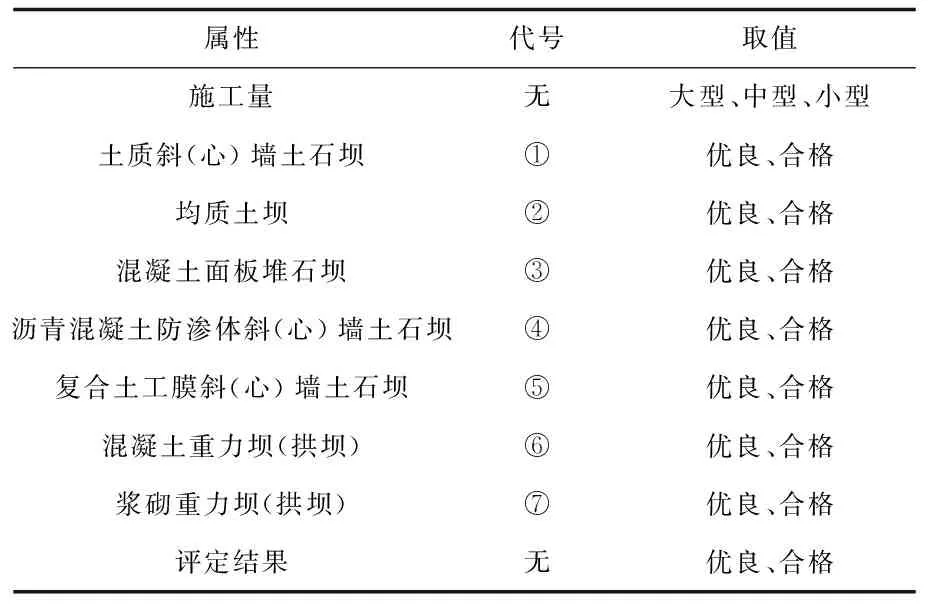
表1 样本属性及取值

表2 质量监督数据表

图1 ARFF格式文件
2.3 数据建模
在对数据进行预处理之后,在Weka平台上利用C4.5算法对数据进行数据挖掘建模。C4.5算法首先要确定决策树的根节点,套用前文所给出的公式,可以计算出每一个测试属性的信息增益率,如下所示:
GainRatio(施工量)=0.000 156 883 102 685 457
GainRatio(①)=0.038 032 058 076 706 7
GainRatio(②)=0.039 343 957 869 997 6
GainRatio(③)=0.037 491 840 623 890 4
GainRatio(④)=0.028 785 633 863 634 9
GainRatio(⑤)=0.051 133 153 135 862 1
GainRatio(⑥)=0.036 479 484 701 691 5
GainRatio(⑦)=0.032 572 342 234 994 7
通常选取信息增益率最大的属性作为决策树的根节点,所以这里决策树的根节点是代号为⑤的属性,也就是复合土工膜斜(心)墙土石坝。将此属性两个取值作为决策树的两个分支,重复之前的操作。左右两棵子树同样选出信息增益率最大的测试属性作为子树的根节点,递归生成决策树的左子树和右子树,最后采用后剪枝的技术对决策树进行剪枝。为了进一步精简决策树,此处去掉叶子节点实例数小于100的节点,来完成决策树的建模过程。
决策树模型建立完成之后,还要利用十折交叉验证[13]来测试决策树分类的准确率。即将训练数据平均分成10份,轮流将其中的1份作为测试数据,将其余的9份作为训练数据。每次试验都会得出决策树的准确率,将10次的结果取平均值,作为最终结果,以使结果更加精确。通过以上步骤建立的决策树模型如图2所示。
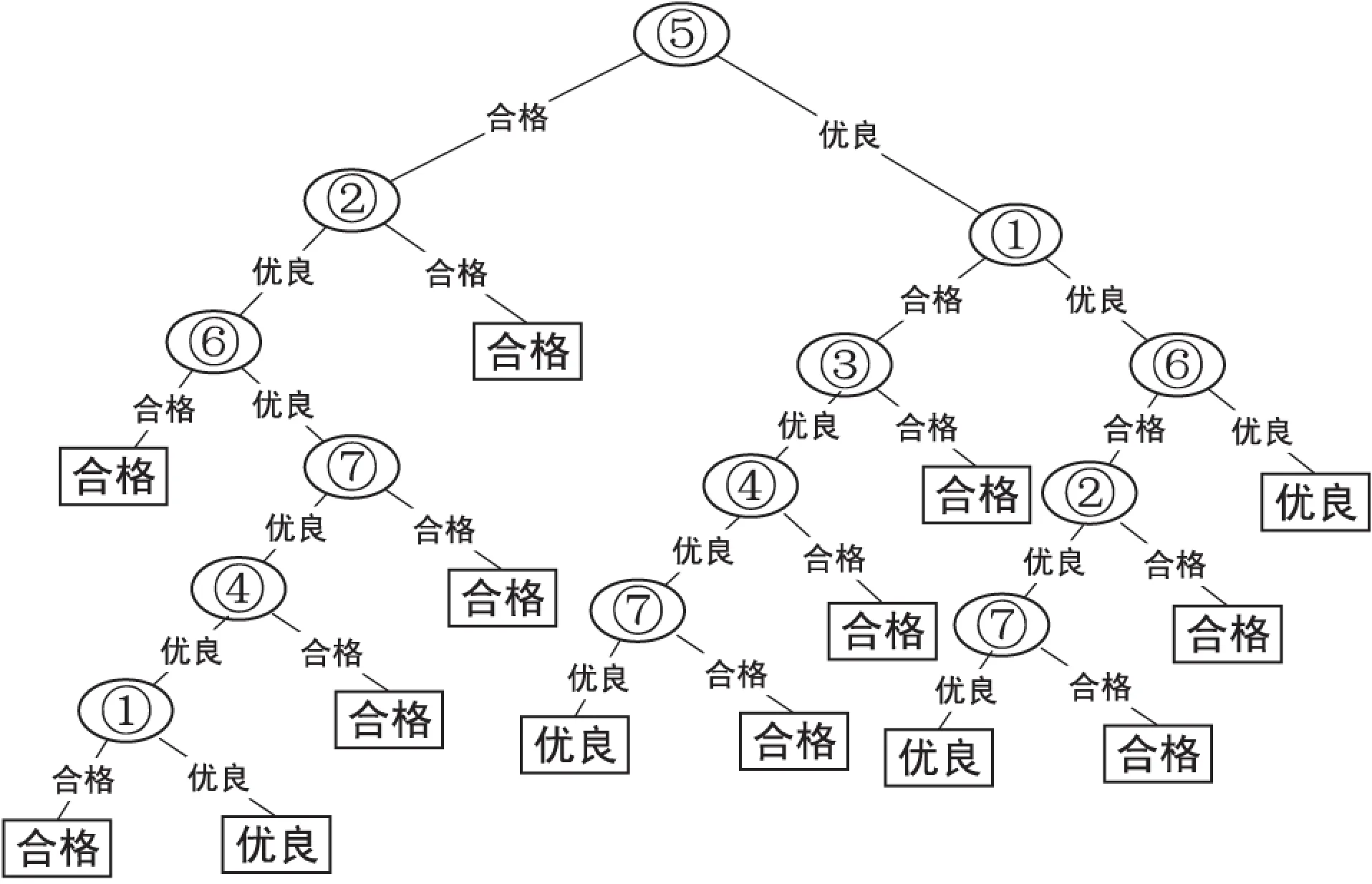
图2 决策树模型
算法的执行结果如图3所示。
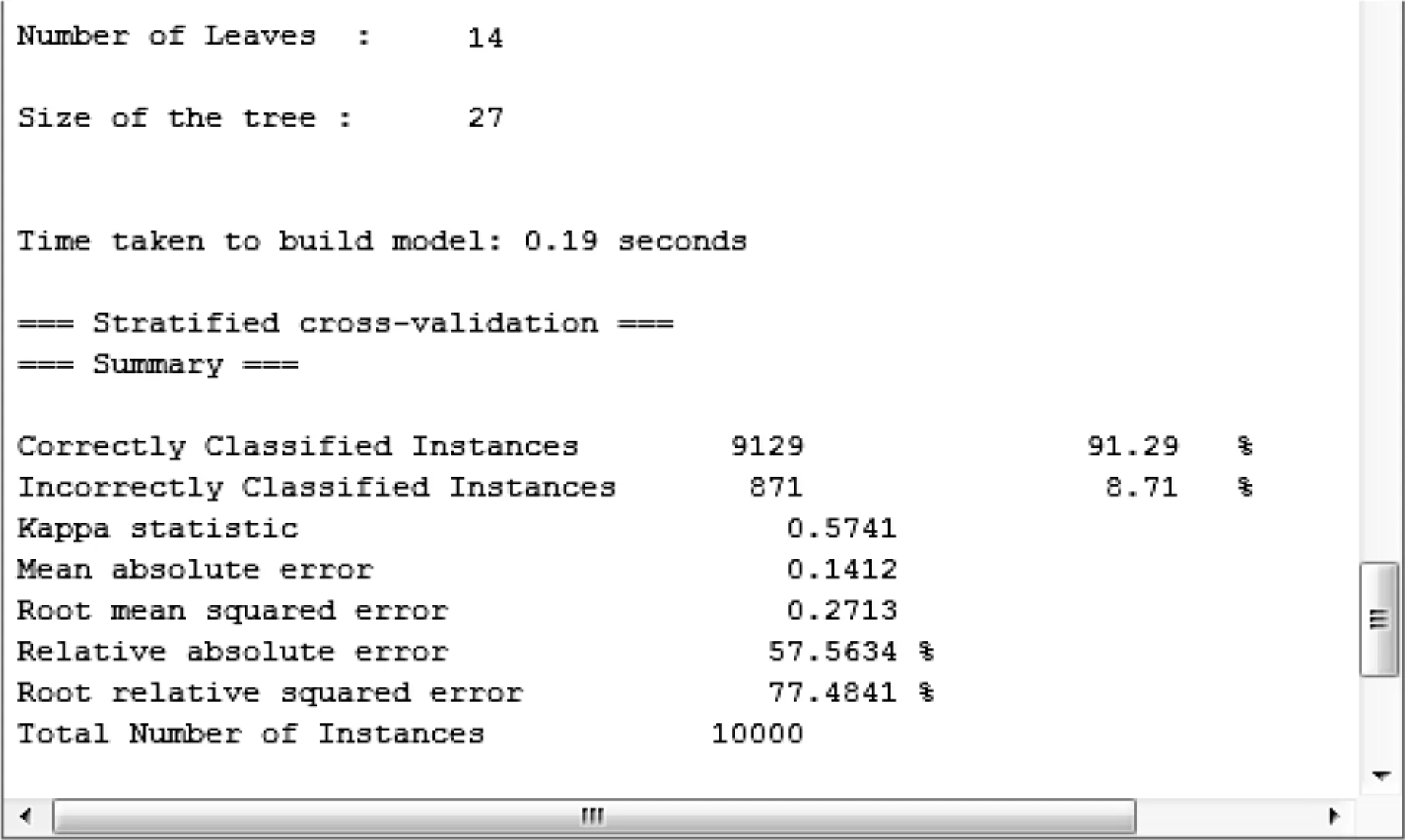
图3 算法执行结果图
结果显示:对10 000个实例进行建模,得出的决策树共有27个节点,其中叶子节点14个。正确分类的实例数为9 129个,错误的分类实例为871个,建模时间为0.19 s,模型的准确率为91.29%。
2.4 决策支持系统
工程质量监督决策支持系统[14]设计的主要目的是使施工单位能够了解到如何提高子工程的建设质量,才可以使最终的评定结果达到优良的评级。根据决策树模型得到一系列的IF-THEN规则,选取该模型中最终分类为优良的4个规则进行展示,其结果如下:
IF ⑤=合格 AND ②=优良 AND ⑥=优良 AND ⑦=优良 AND ④=优良 AND ①=优良 THEN 评定结果=优良
IF ⑤=优良 AND ①=合格 AND ③=优良 AND ④=优良 AND ⑦=优良THEN 评定结果=优良
IF ⑤=优良 AND ①=优良 AND ⑥=优良 THEN 评定结果=优良
IF ⑤=优良 AND ①=优良 AND ⑥=合格 AND ②=优良 AND ⑦=优良 THEN 评定结果=优良
根据决策树得出的IF-THEN规则进行决策支持系统的设计,其界面展示如图4所示。

图4 决策支持系统界面
监管部门只要填选相应的子工程的评定等级并点击预测按钮,即可在结果展示区域内看到预测结果。在工程建设质量的改进过程中,父节点属性的优先级要高于子节点属性的优先级。相关建设单位只要按照这一关系逐一改进子工程的工程质量,就可以使整个工程的评定结果达到优良等级,进而做到对风险的预测和避免。
3 结果分析
在创建决策树的根节点时,代号为⑤的子工程即复合土工膜斜(心)墙土石坝计算出的信息增益率最高,因此将该子工程作为决策树的根节点。也就是说该子工程相对于其他子工程来讲更为重要。并且模型最后给出的4条IF-THEN规则中,有3条是建立在该子工程评分为优良的情况下的。所以监管部分应着力加强这一子工程的建设监督,这样可以使整个工程项目朝着优良的方向发展。在生成的模型中,工程量这一测试属性并没有出现在决策树中,说明这一测试属性对整个工程质量的走向影响并不是很大,因此无论工程大小,监管部门都应一视同仁。
4 结束语
文中通过C4.5算法对水利工程质量监督的历史数据进行建模,生成的决策树模型简单易懂,准确率较高,可以有效地帮助工程建设单位改进工程质量。监管部门通过决策支持系统也可以对未来的工程质量进行预测,以达到防患于未然的目的。但C4.5算法在进行数据挖掘建模时,需要多次扫描样本集并进行排序,使得该算法在建模的速度上有一定的缺陷。今后的工作主要是针对C4.5算法的这一缺点进行改进,使之达到更好的效果。
[1] 罗 可,林睦纲,郗东妹.数据挖掘中分类算法综述[J].计算机工程,2005,31(1):3-5.
[2] 李 航.统计学习方法[M].北京:清华大学出版社,2012.
[3] 陈文伟,邓 苏,张维明.数据开采与知识发现综述[M].北京:机械工业出版社,2003.
[4] Tsang S,Kao B,Yip K Y,et al.Decision trees for uncertain data[C]//Proc of IEEE international conference on data engineering.Shanghai,IEEE,2009:441-444.
[5] 桂现才,彭 宏,王小华.C4.5算法在保险客户流失分析中的应用[J].计算机工程与应用,2005,41(17):197-199.
[6] 刘 兵.Web数据挖掘[M].俞 勇,译.北京:清华大学出版社,2009.
[7] Chen Jin,Luo Delin,Mu Fenxiang.An improved ID3 decision tree algorithm[C]//Proc of 4th international conference on IEEE computer science and education.Chengdu:IEEE,2009:127-130.
[8] Barnum H,Barrett J,Clark L O,et al.Entropy and information causality in general probabilistic theories[J].New Journal of Physics,2010,12(3):1-32.
[9] Kantardzic M.Data mining:concepts,models,and algorithms[M].New York:John Wiley and IEEE Press,2003.
[10] Zhou Chi,Xiao Weimin,Tirpak T M,et al.Evolving accurate and compact classification rules with gene expression programming[J].IEEE Transactions on Evolutionary Computation,2003,7(6):519-531.
[11] Han Jiawei,Kamber M.数据挖掘概念与技术[M].范 明,孟小峰,译.北京:机械工业出版社,2012.
[12] 孟晓明,陈慧萍,张 涛.基于WEKA平台的Web事务聚类算法的研究[J].计算机工程与设计,2009,30(6):1332-1334.
[13] 牛晓太.基于KNN算法和10折交叉验证法的支持向量选取算法[J].华中师范大学学报:自然科学版,2014,48(3):335-338.
[14] 陈文伟,廖建文.决策支持系统及其开发[M].第3版.北京:清华大学出版社,2008.
Applied Research of C4.5 Algorithm in Engineering Quality Decision Support System
HOU Li-duo,YE Jie
(College of Computer Science and Technology,Guizhou University,Guiyang 550025,China)
As traditional hydraulic engineering quality supervision and management system just playing the role of regulation,it is difficult to detect and predict potential problems on the quality of the project.Aiming at this phenomenon,a solution about using the C4.5 algorithm to make decision on project quality was proposed.First provided an overview of the algorithm and C4.5 decision tree algorithm and then elaborated data preprocessing and the process about data modeling used with C4.5 algorithm in decision support system.Finally developed the decision support system according to the decision tree model.The experimental results show that the decision tree model established by C4.5 algorithm has high accuracy.The developed decision support system can be well applied to practical engineering quality supervision process and achieves the desired results.It can be better for the future project quality prediction,providing decision support to the supervision department.
C4.5 algorithm;entropy;project quality;Weka
2015-05-25
2015-08-28
时间:2016-01-26
贵州省科技计划项目(黔科合GY字(2011)3050)作者简介:侯立铎(1988-),男,硕士研究生,研究方向为数据挖掘技术;叶 洁,副教授,研究方向为数据库与应用系统。
http://www.cnki.net/kcms/detail/61.1450.TP.20160126.1521.066.html
TP301.6
A
1673-629X(2016)02-0132-04
10.3969/j.issn.1673-629X.2016.02.030
