校园网智能恶意软件数据检测研究
2016-02-23张亮
张亮
校园网智能恶意软件数据检测研究
张亮
随着互联网技术的不断发展,恶意软件的几何式增长和传播,传统安全软件鉴别模式已经很难适应新形势,大量的未知文件经过杀毒软件比对后,仍有很高比例无法识别。通过数据挖掘技术实现对未知文件高效、准确识别、分析和处理就有较大的实用意义。采用分类关联规则挖掘算法建立模型,并使用集成学习方法共同进行未知文件预测,对预测的恶意软件使用聚类进行归类,并提取特征代码用于鉴别。
云安全;分类;归纳学习;集成学习
0 引言
恶意软件的爆发式增长使得传统安全技术变得脆弱不堪,传统安全方案对安全领域专家个人能力依赖性较强,甚至需要进行人工特征码提取,单一主体的安全防御已经无法适应现在高校网络安全形势。国际国内高校逐渐开始尝试构建云安全[1]中心,通过大数据技术依托云计算中心进行高效的数据分析,同时运用并行计算、未知代码行为分析等技术采集恶意软件样本。研究大数据相关方法,把数据分析技术运用到智能恶意软件检测中具有较高的研究价值。
1 系统架构和算法概述
根据破坏性和传播方式,本文中提及的恶意软件一般指病毒、蠕虫、木马、后门及它们的组合。对于鉴别这些恶意软件,需要采集其静态和动态特征[2]。静态特征是在程序未运行时,提取出的指令代码等。特点是容易提取,但是对于应用变形和多态等技术的恶意软件提取后难以分析。动态特征[3]是将代码运行后监视其行为,对于变形和多态技术可以很好识别,但是操作时提取速度慢,采集样本效率低。对于新时期高校网络安全需求,特征提取过程需要自动、高效、准确,特征代码的维数应最小化。
本文采用以下步骤进行恶意软件的检测、归类、提取特征代码和查杀。
(1)构建Apriori分类器、Supportt Vector Machines分类器、决策树分类器、朴素贝叶斯分类器,对普通样本和恶意软件样本进行学习,查找恶意代码共性,提取特征和分类;
(2)使用分类集成学习方法对单个分类器的预测结果进行结论生成;
(3)对预测结果恶意软件样本经聚类方法进行归类,对每一个恶意软件簇提取相应的通用特征代码用于鉴别和查杀;
(4)如有预测结果为未知的文件交由人工处理并把结果返回分类器。
系统架构如图1所示:
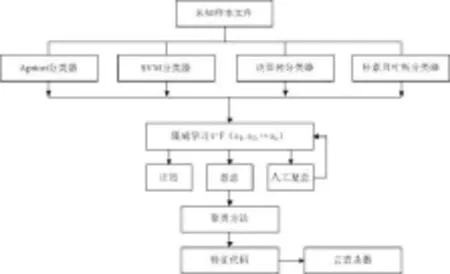
图1 恶意软件智能检测系统架构图
2 分类器集成预测
本文采用分类学习方法对进行恶意软件检测和鉴别。通过正常样本和已知恶意软件样本的数据学习,查找新产生的恶意软件源代码和记录中原恶意代码的共性,快速准确的归类并提取恶意软件的身份特征代码。
2.1 构造Apriori分类器
通过文献[4-6]知道了Apriori的两个性质,因此,假设数据表如图2所示:
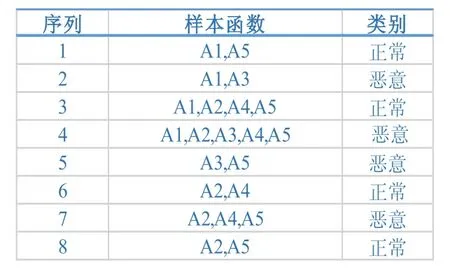
图2 样本数据表
最小支持度为25%,置信度为65%,进行恶意软件分类。对应的分类关联规则C:
C1{A3}推导类=恶意(37.5%,100%)
C2{A1,A3}推导类=恶意(25%,100%)
C3{A3,A5}推导类=正常(25%,100%)
C4{A4,A5}推导类=正常(255%,66.7%)
C5{A2,A4,A5}推导类=正常(25%,66.7%)
照此估算每次计算频繁项集过程中产生数量很大的候选项,例如长度为50就会产生20的50次方个候选,系统开销极大。本文利用频繁模式增长算法来解决这个问题,这种算法在频繁项集挖掘过程中不产生候选,也就是不存在从树根到树叶的路径,从而提高效率。
抽取样本库中5 497个样本进行测试,其中包含3 356个恶意软件,2 141个正常软件,提取到25 366个函数。设定参数最小支持度为0.294,置信度为0.98,使用频繁模式增长算法得到237条关联规则。
测试举例:
C1{2 221,378,127,116,17}推导类=恶意(支持度0.296 7,置信度0.996 7)
还原函数操作得到规则如下:
C1{打开进程;返回句柄;复制文件;关闭已经打开的进程;获取操作系统版本;获取文件路径;写文件}
符合此类操作的函数调用就可能是恶意软件调用规则,根据上述样本测试使用如上操作的软件99.7%是恶意软件操作,0.3%是正常软件操作。
2.2 构造Support Vector Machines分类器
单一特征表达方法检测的准确率很低,一般需要使用多种特征表达的方法来弥补。Support Vector Machines算法具有较好的分类精度,对于高维度数据集有较强的处理能力。根据数据的线性可分性和线性不可分性区别,对于由于样本数较高的恶意软件鉴别,本文采用采用线性Support Vector Machine分类器[7,8]构造。
2.3 构造决策树分类器
在鉴别资源特征的特征时,本文采用决策树分类器[9]算法,构造方法如下:
(1)建立树
设节点X代表划分W的元组,X的分裂属性需选择最高增益属性,那么W中的期望信息如式(1):
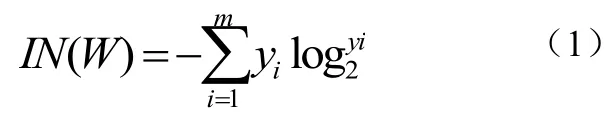
其中yi是W中任意元祖属于Ci的概率,IN(W)是识别W元组类标号需要的平均信息量,假设属性N将W分为n个子集W1,W2,……Wn为式(2):

信息增益计算就是对E划分得到的与原有的信息需求差为式(3):
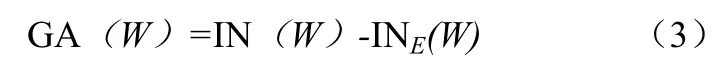
选择最高信息增益的属性为该节点分列属性。
(2)减枝
本文采用悲观错误减枝(Pessimistic Error Pruning)方法,该方法精度较高,在每个子树中最多访问一次。
2.4 构造朴素贝叶斯分类器
针对特征很长和纬度非常高的指令序列,本文采用朴素贝叶斯分类器[10]处理。该方法在此领域效果明显,性能和神经网络接近。
贝叶斯分类器应用的学习中,目标函数从有限集合K中取值,根据目标函数的训练样本和实例,预测新实例目标值,计算最可能的目标值Km,根据贝叶斯公式代入后得到式(4):
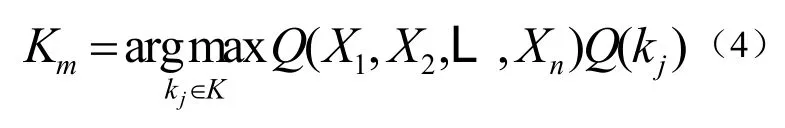
假定给定目标属性值独立,得到式(5):
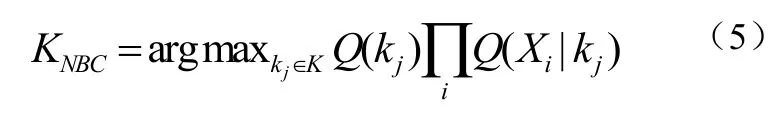
检测恶意软件是一个二分类问题,因此本文采用变形式(6):
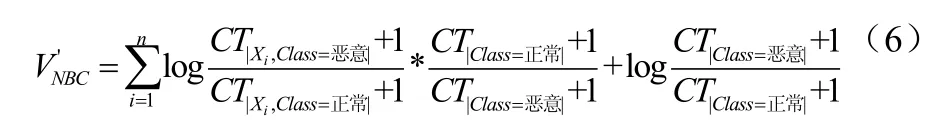
3 分类学习方法生成
集成学习是由多个个体学习器对同一问题进行学习,输出共同决定,根据恶意软件检测分类器的实际情况,本文采用个体学习器算法不同的异构集成。为了使集成学习具有更好的预测效果需要满足条件:
(1)对新数据进行函数逼近或分类,误差率比随机预测好,个体分类错误率低于0.5;
(2)对新数据进行函数逼近或分类,错误互不相关。
集成学习方法:
(1)通过策略生成具有较高正确率和差异性的集成个体,可以使用不同训练算法或者同一训练算法采用不同参数;
(2)结论生成算法一般采用投票法,用多个基本分类器分类预测后,根据权重采用一票否决、一致同意、多数决定、阈值表决等方法生成结论。当每个分类器能力不同,根据过去表现根据贝叶斯算法进行计算设定权值,这种贝叶斯投票效果更好,但是因为很难穷举整个假设,分配所有先验概率,所以无法代替普通投票法。
4 恶意软件的归类
本文采用聚类方法对恶意软件进行归类。
4.1 恶意软件的特征表达方法
文件指令频度的特征提取需要解析所有指令,统计出每条指令在恶意软件样本中出现的频率PL与拟向样本频率NYD,并进行加权。
指令频率PL定义为特定指令出现的频率,对于第j个样本中的指令有式(7):
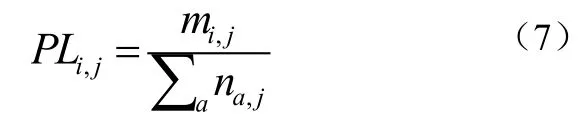
分子是该指令在j中出现的次数,分母是所有指令出现的次数和。
逆向样本频率NYD计算为式(8):
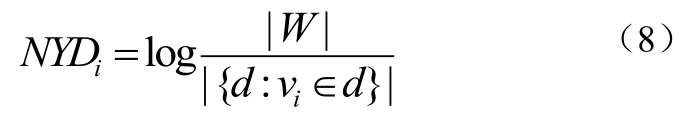
本文采用PLNYD=PLi,j*NYDi对样本j中Vi指令加权。经过样本分析发现,变种恶意软件指令频度变化曲线具有相同或相似特征。
4.2 GFS文件指令频度特征聚类
单纯采取层次方法和划分方法聚类在恶意软件中检测实验中只得到不均匀密度的结果,这种结果难以进行分析。本文采用无参数聚类方法改进FS指标,称为GFS方法为式(9):
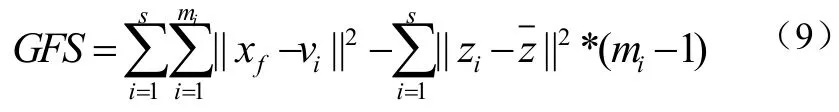
其中mi第i簇中样本数,s是簇个数,zi是i簇中心点(距离所有数据距离最小的点),是全数据中心点,是簇内紧凑度,是类间分离度。
根据以上算法GFS越小越好,并且不须考虑簇和自身的分离度,减少了相关干扰。
4.3 WKM文件指令序列特征聚类
恶意软件检测函数指令序列特征一般是高维度稀疏数据,传统聚类方法没有用武之地。本文采用WKM加权子空间聚类算法,通过聚类过程中搜索每个簇对应的指令序列子空间来实现该类数据自动归类。算法得出的聚类结果中,可能产生在本簇中出现频率高,在其他簇中出现频率低的数据,如果这类数据通过误报测试,那么这些数据就是恶意软件通用检测特征。例如A簇中指令片出现的频率为[1,1,0.66,0.34,0.34],B簇[1,0,0,1,0.4],设定的高频为0.66,低频为0.34,那么提取A簇中2、3号指令,B簇中4号指令进行误报测试,通过后即可作为恶意软件通用检测特征。
5 实验结果
使用上述方法对恶意软件检测效率进行试验,在对比组使用诺顿、卡巴斯基、Mcfee等安全软件进行测试。
在第1次测试中,统计结果本系统效率低于传统安全软件。第2次测试开始,结果开始稳定,效率也达到预期。第2次到第8次实验数据相似,两次实验的数据统计结果如表1所示:
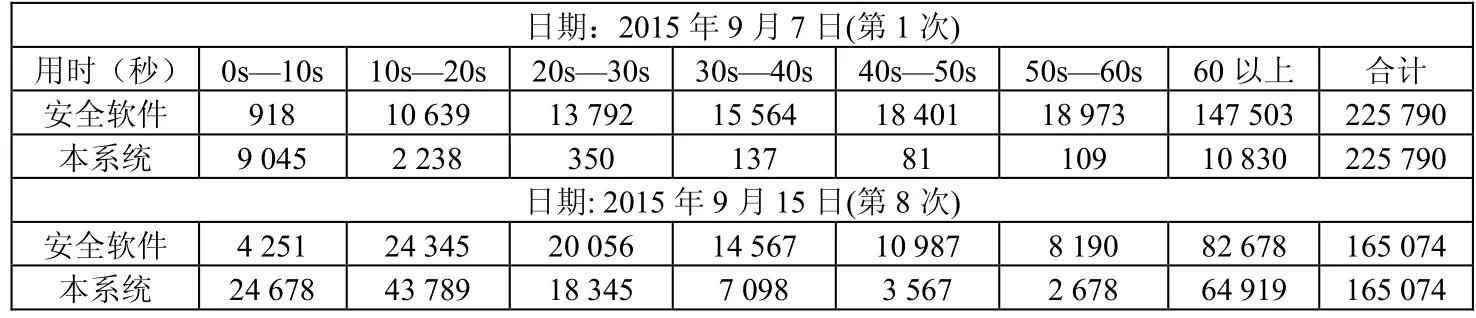
表1 实验结果统计
在前10秒的分析中,实验样本在本试验中的数据远领先于传统安全软件。
使用本文方法对恶意软件进行自动归类,并对每个恶意软件提取特征代码,对恶意软件描述举例如图3所示:
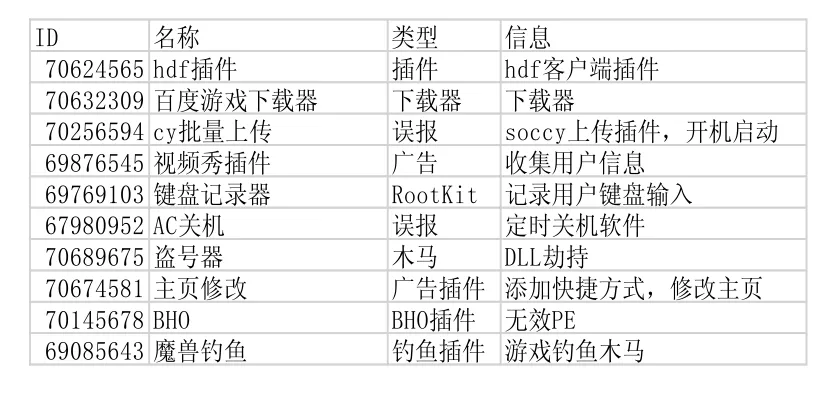
图3 归类后的恶意软件簇描述示例
例如特征ID72274856匹配到2754个恶意软件样本,其恶意特征如下:

将此ID提取的通用恶意特征分发到客户端,即可进行快速查杀。
6 总结
恶意软件的高速增长和传播,使得传统安全软件的架构难以适应新形势的要求,面对海量的未知文件难以鉴别和分类。本文通过大数据技术和数据挖掘,配合云架构进行恶意软件数据检测研究。重点研究了恶意软件的特征表达、分类以及分类集成学习在检测恶意软件中的算法,聚类方法在恶意软件检测中的应用等内容。根据实验结论,这些方法能够实现在海量未知文件样本中自动、快速、准确的识别和分析恶意软件,该研究在高校恶意软件检测和防护领域具有较强的实用性。
[1] 刘晓梅.高校中云安全技术策略分析[J].网络安全技术与应用,2014,(6):82-83.
[2] 张健飞,陈黎飞,郭躬德.检测迷惑恶意代码的层次化特征选择方法[J].计算机应用,2012,32(10):2761-2767.
[3] 管云涛,段海新.自动的恶意代码动态分析系统的设计与实现[J].小型微型计算机系统,2009,7(4):1326-1330.
[4] 赵祖应,丁勇,邓平.基于Apriori算法的购物篮关联规则分析[J].江西科学,2012,30(1):96-98.
[5] 刘华婷,郭仁祥,姜浩.关联规则挖掘Apriori算法的研究和改进[J].计算机应用与软件,2014,26(1):1-3
[6] Osmar R Zaiane,Mohammad EI-Hajj,Paul Lu.Fast Parallel Assocation Rule Mining Without Candidate Generation.[J]2001:115-126.
[7] 安元,胡卫群,夏真友.线性三类分类器[J].电脑知识与技术,2013,9(33):7625-7626.
[8] 廖周宇,谢晓兰,刘建明.云计算环境下基于SVM的数据分类[J].桂林理工大学学报,2013,4(33):765-769
[9] 丁文彬.基于决策树分类的网络异常流检测与过滤[D].成都:电子科技大学,2013:18-24.
[10] 王东,熊世桓.一种基于特征置换的朴素贝叶斯分类器[J].兰州理工大学学报,2012,4(38):93-97.
Research on Malicious Software Data Detection of Campus Network
Zhang Liang
(Network Information Center, China University of Petroleum (East China), Qingdao 266500, China)
With the continuous development of the Internet technology, the size of malicious software is growing and spreading at an incredible rate, so the traditional security software authentication mode can not adapt to the new situation. After using anti-virus software comparison, there is still a high proportion of unrecognized. Data mining technology to implement unknown files is efficient and accurate to identify and analyze for these files, so it has great practical significance. In this paper, the model is to built by classified association rule mining algorithm and integrated learning methods to carry out unknown files prediction, the prediction of malware uses cluster analysis to classify and extract the feature code for its identification.
Clould security; Classification; Inductive learning; Ensemble learning
TP393
A
1007-757X(2016)010-0044-04
2016.08.20)
中国石油大学(华东)高等教育研究基金(GJKT201502)
张 亮(1981-),男,启东,中国石油大学(华东),硕士,研究方向:计算机信息和网络技术方面的研究,青岛 266500
