加权社会网络中的个性化隐私保护算法
2016-02-23陈春玲
陈春玲,熊 晶,陈 琳,余 瀚
(南京邮电大学 计算机学院 软件学院,江苏 南京 210003)
加权社会网络中的个性化隐私保护算法
陈春玲,熊 晶,陈 琳,余 瀚
(南京邮电大学 计算机学院 软件学院,江苏 南京 210003)
针对加权社会网络中存在一部分用户不需要隐私保护或者需要某种特殊隐私保护的现象,提出了一种基于加权社会网络数据发布的个性化隐私保护方法。将社会网络中的隐私保护分为3个等级:不需保护L=0、防止权重包攻击L=1和防止敏感属性泄漏L=2。对于L≠0的节点集,通过k-度分组和修改权重包信息对节点进行匿名,使得每个分组满足权重包k-匿名;在分组过程中,对于存在L=2的分组要求其敏感属性满足l-diversity。理论分析和实验表明:攻击者不能以大于1/k的概率识别出某节点,且不能以大于1/l的概率推断出节点的敏感信息。该方法能够满足社会网络中各用户对隐私保护的要求,同时降低了社会网络图的信息损失。
加权社会网络;隐私保护;个性化;权重包;敏感属性
1 概 述
前Sun Microsystems的CEO,Scott McNealy曾说过“反正你的隐私为零,那就克服它吧”。当时这句话震惊了很多人。然而,十几年过去了,事实证明他的说法是正确的。社会网络中的用户不断增多,使得社会网络在现实生活中已非常普遍,并深刻地影响着人们的日常生活。国外的LinkedIn、Facebook、Twitter,国内的新浪微博、QQ、微信等社交平台都拥有了庞大的客户群。用户通过社会网络与他人分享个人信息,并接触到了更多的人,而用户之间的这种互动与交流必然会产生大量社会网络数据。分析数据有助于认识网络的拓扑结构和演化过程、用户的类别划分和行为倾向等,但是也会造成用户敏感信息泄漏,可能导致个人隐私受到威胁。近些年,对于社会网络的隐私保护研究已经引起了广泛的关注。
Samarati等[1]提出k-匿名隐私保护模型,但仅针对关系数据,并不适用于现在的社会网络;Terzi等[2]将节点的度作为攻击者的背景知识,提出了k-度匿名方法来防止节点再识别攻击;Zhou等[3]提出的匿名化方法使得对任意节点的邻域子图,至少有k-1个节点的邻域子图与其同构;Jiao等[4]提出了个性化的社会网络数据保护方法,允许用户根据自身要求设置隐私保护程度,同时为了保护节点的敏感属性(例如疾病、收入)不被泄漏,引入了l-diversity思想[5-7],避免同质性攻击。上述研究成果都是基于不带权值的社会网络,在现实生活中,对边的权值分析也是具有重要意义的,它可以表示社会网络中各节点之间的连接关系,如朋友网络(朋友圈)中的边权值表示联系次数,商业交易网络中的边权值表示交易次数等。Maria等[8]提出了基于加权社会网络的k-匿名保护方法,使得攻击者不能以大于1/k的概率识别出目标节点;Tsai等[9-10]通过修改权值方法,使得任意两节点之间的最短路径条数满足k1≤k≤k2,避免任意两节点之间的最短路径泄漏问题;Chen等[11]提出了k-histogram-inverse-l-diversity匿名方法,通过修改节点的权重包信息,使得同一等价类中节点的权重包信息相同;陈可等[12]提出了k-可能路径匿名模型来保护加权社会网络中的最短路径信息泄漏问题;兰丽辉等[13-14]采用向量来描述加权社会网络,通过随机分割和聚类分割两种方式将加权社会网络表示为若干个子图,用向量表示每个子图,将所有子图的向量构成的集合作为加权社会网络的发布模型,但目前还不能很好地应用于社会网络中。
现实生活中存在一种现象:只有很少一部分人需要较高级别的隐私保护;对于度相对较大的节点集,只有其中很少一部分节点需要进行较高级别的隐私保护[4]。例如,将生活中的公众人物抽象为一个节点,该节点的邻居节点会比普通节点多,聚类系数更大,但是相对来说,他们的隐私保护要求更低。在加权社会网络的隐私保护研究中,每个人对隐私保护的要求不尽相同,而目前的研究并没有考虑到用户的这一需求,而是将所有用户节点都进行同一隐私保护,导致对某些节点的隐私保护过度,同时增加了隐私保护的代价,降低了社会网络信息的有效性。因此,文中提出一种基于加权社会网络数据发布的个性化隐私保护算法。
2 相关概念
2.1 加权社会网络
为了形象地描述社会网络结构,文中将其抽象成加权图模型G=(V,E,W,S,L)。其中,V为节点集,表示社会网络中的用户;E为边集,表示社会网络中的节点关系;W为边权值集,表示节点关系的紧密程度;S为敏感标签集,表示社会网络中的用户敏感属性;L为隐私级别集,表示社会网络中的用户隐私要求。
图1为某公司员工交流中心的模型,边权值表示两节点一周内联系的次数,如果两节点没有连接,则表示他们本周没有联系过。节点的上半部分标识表示员工的薪资,属于敏感属性,下半部分标识表示隐私级别,可由节点自身进行设置。例如节点a和b本周联系了2次,a和d在本周没有联系过,且a的薪资为7.5k,隐私级别为1。
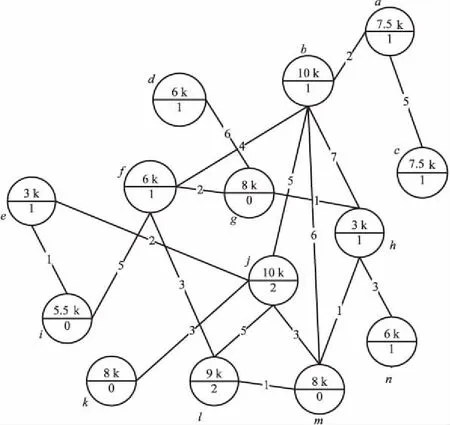
图1 某公司员工交流中心网络图
2.2 权重包匿名
权重包:节点的权重包表示与该节点关联的边的权值序列,文中将此序列按照逆序排列。图1中a的权重包为<5,2>,b的权重包为<7,6,5,4,2>。
权重包k-匿名:假设攻击者已经掌握了某个节点的权重包信息,很容易识别出目标节点。为了避免节点受到此类攻击,文中采用了权重包k-匿名的思想。通过修改权重包信息,使得每个分组中节点的权重包均一致,这样攻击者就不能以大于1/k的概率识别出目标节点[11]。
2.3 敏感属性匿名
在对节点进行分组时,可能会出现某个分组中的敏感属性值都一样的情形。而对于L=2的节点要求进行敏感属性匿名,使得攻击者不能获取敏感属性。为了满足用户的隐私保护要求,文中采用l-diversity思想[11],使得每个分组中的敏感属性值不同的节点数不小于l,因此攻击者获取目标节点的敏感属性值的概率不会大于1/l。
2.4 隐私级别
用户根据自身需求设置相应的隐私保护级别,文中将用户隐私级别L分三个等级:
(1)L=0,表示用户对隐私保护没有要求;
(2)L=1,表示用户希望攻击者不能通过其权重包识别出自己;
(3)L=2,表示用户希望攻击者不能通过其权重包识别出自己,且不能识别出自己的敏感属性。
2.5 信息损失度loss
社会网络的信息损失由三部分组成:边的添加与删除、节点的添加与删除以及权值的修改。式(1)表示信息损失度loss的计算方法。
(1)
其中,α+β+γ=1;|Δedge|为添加与删除的边总数;|Δnode|为添加与删除的节点总数;|Δweight|为权值修改的边总数。
3 加权网络的个性化隐私保护算法
3.1 分组算法
图1表示一个原始的社会网络图G,现在需要对G进行隐私保护,假设k=3,l=2。匿名算法如下:
(1)将节点(隐私级别L>0)的度按逆序排列,节点v记录为(v,v.degree,S,L),得到度序列:
P={(b,5,10k,1),(j,5,10k,2),(f,4,6k,1),(h,4,3k,1),(l,3,9k,2),(a,2,7.5k,1),(e,2,3k,1),(c,1,7.5k,1),(d,1,6k,1),(n,1,6k,1)}
(2)将节点分组,选取前k个节点为当前组,如果在该组中有L=2的节点,且不满足l-diversity,则将下一节点加入到当前组中,直到满足l-diversity,得到分组C1=(b,j,f)。
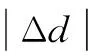
(4)重复步骤3,直到待分组的节点数小于等于k,得到分组C3=(e,c,d),C4=(n)。
(5)分组结束后,判断最后一个分组是否满足分组要求。如果不满足,则与前一分组进行合并,将C3与C4合并,得到C3=(e,c,d,n)。
故图1的分组为C1C2C3。
3.2 图匿名算法
对节点进行分组后,需要对图进行匿名,使得攻击者不能识别出目标节点。为了防止攻击者通过权重包识别出目标节点,要求每个分组满足权重包k-匿名特性。
(1)分组后,每个分组首先要求节点度相同,这样才可以达到权重包相同。故对于Δd≠0的节点需要进行k-度匿名,使得每一组的节点度都相同。对分组中的各节点进行k-度匿名会出现两种情况:
①对于Δd>0的节点集N1,优先选择在N1中的两个节点之间添加噪声边(不存在边关联),权值为0。如果|N1|=1或者N1节点集中的任意两节点都存在边,则添加噪声节点,此时噪声节点的敏感属性值与该节点相同,隐私级别L=0,噪声边权重为0。
②对于Δd<0的节点集N2,优先选择删除N2中的两个节点之间的关联边。如果依然存在Δd<0的节点,则删除其与隐私级别L=0的节点之间的关联边。如果不存在这样的边,则删除其中一条边,并将该边关联的另一节点连接到噪声节点上,权值不变。
(2)权重包的匿名:对于每个分组,根据各边权重出现的频率,选取前n个值作为该分组的权重包标准,n=avg(Ci)。修改每个节点的权重包,使得分组中的各节点权重包一致,尽量不改变原来的权值。C1的权重包为<6,5,4,3,2>,C2的权重包为<5,4,3,2>,C3的权重包为<5>。由于每条边关联了两个节点,导致修改某个边的权值后,在匿名其关联的另外一个节点权重包时,需要再次修改边的权值。为了解决这个问题,采取泛化的方法,保存多次修改后的边权值。例如,匿名节点b的权重时,将边eab的权值改为2,而在匿名节点a的权值时,需要将eab的权值改为3,故将eab的权值修改为<2,3>,即eab的权值可能为2,也可能为3。
图2为G的发布图G*。粗实线表示修改了权值的边或添加的噪声边,虚线为匿名过程中已删除的边,细实线表示原始边,节点o为添加的噪声节点。
3.3 算法分析
假设攻击者掌握了目标节点的权重包信息,在发布的社会网络图中,存在两种情况:第一,在权重包匿名过程中,权重包的信息被修改过,使得在发布的社会网络图中不存在这样的权重包,这样攻击者就识别不出目标节点,例如图2中的节点b;第二,在权重包匿名过程中,要求同一个分组中每个节点的权重包一致,这样攻击者不能以大于1/k的概率识别出目标节点。在分组过程中,如果存在某个节点的隐私级别L=2,则要求该组中敏感属性值不同的节点个数大于等于l,因此,攻击者也不能以大于1/l的概率推测出目标节点的敏感属性值。综上所述,该算法是有效的。
由于在生成节点分组的过程中需要遍历每个节点,故时间复杂度为O(n)。分组结束后,对于L≠0的节点,需要进行k-度匿名。在对Δd≠0的节点集匿名过程中,需要删除和增加边,而找到最优解的策略则需要遍历该节点集,因此进行节点k-度匿名的时间复杂度为O(n2)。例如现在需要使Δd>0的节点集满足k-度匿名,则需要遍历Δd>0节点集,判断是否存在这样的两个节点,不存在边的连接。在对权重包的匿名过程中,需要将节点的权重包修改为所在分组的标准权重包,而选择权重包的标准需要的时间复杂度为O(n)。因此,总的时间复杂度为O(n2)。
4 实 验
4.1 实验环境
实验在Windows 7操作系统上进行,CPU2.0 GHz,内存2 GB,编程工具使用Visual C++ 6.0。实验数据集来自微信(http://weixin.qq.com/),包含500个节点的网络图,1 482条边,节点平均度为5.928,各节点的隐私保护级别(0~2)由程序随机产生,各节点的敏感属性值由程序随机产生。
4.2 实验结果分析
算法考虑了现实情况,避免对不需要进行隐私保护的节点进行匿名,在满足用户的隐私要求下,减小了开销,降低了数据的损失。分组是关键,在进行分组时考虑节点满足k-匿名的同时,判断当前分组是否存在要求敏感属性值满足l-多样性的节点。k值越大,用户的隐私保护程度就越高,造成的信息损失也会越大,执行时间越长;l值越大,攻击者获取目标节点的敏感属性值概率越小;社会网络中节点的隐私级别分布比例,也会对社会网络的信息损失和执行时间产生重要影响。通过修改参数k和l,以及社会网络的隐私级别分布,从时间和信息损失两个方面对实验结果进行分析。
图3和图4分别表示了隐私级别分布比例,以及k值对算法的执行时间和信息损失度产生的影响,l=3,X∶Y∶Z表示隐私级别为L=0、L=1和L=2的节点分布比例。
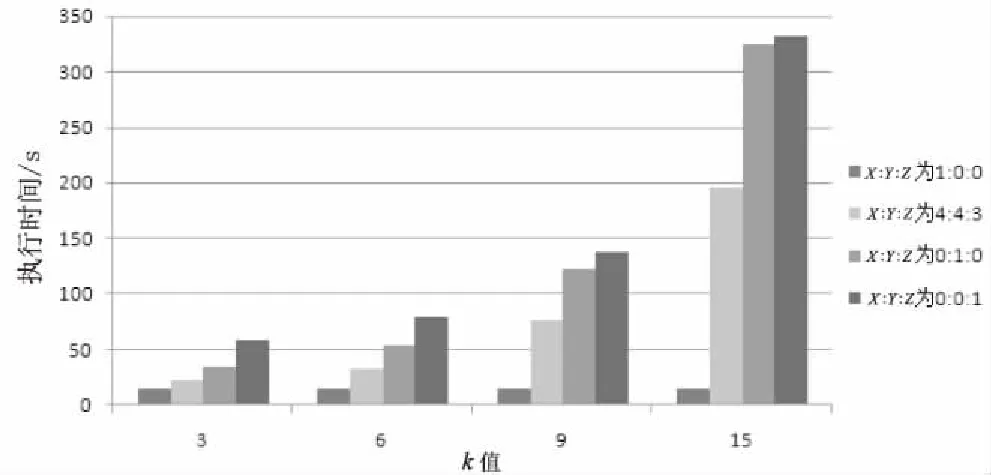
图3 执行时间比较
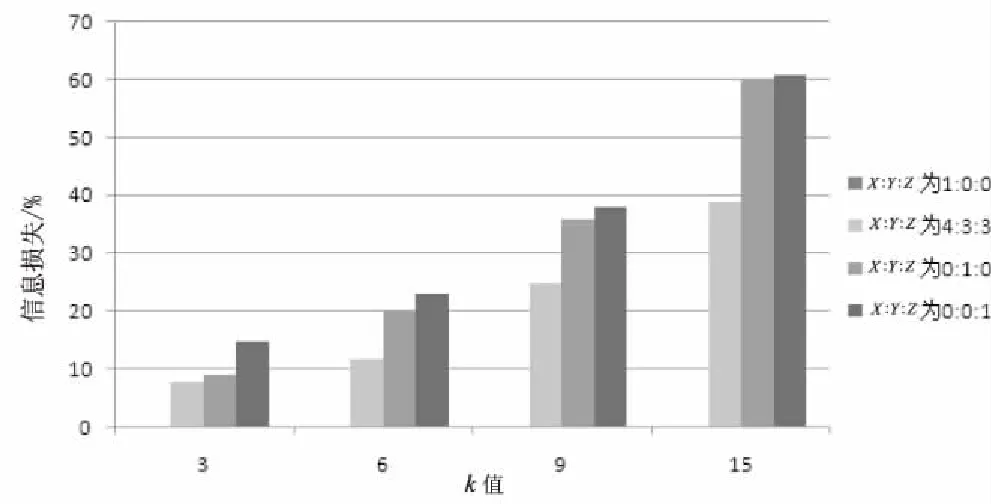
图4 信息损失度比较
当分布比例为1∶0∶0时,所有的节点均不要求进行隐私保护,因此k值的改变对执行时间和信息损失没有影响,且信息损失度为0。随着k值的增大,当分布比例为4∶3∶3,0∶1∶0以及0∶0∶1时,执行时间和信息损失不断增大。当k远大于l时,分布比例为0∶1∶0和0∶0∶1的执行时间和信息损失趋于相等。一般k值越大,分布比例为4∶4∶3的优势越能得到体现。
图5表示的是算法执行时间随l值的变化规律,其中k=6,隐私级别分布比例为4∶3∶3。随着l值的增大,执行时间不断增长,且增长比率也随之增大。当l远小于k时,l值对执行时间的影响不明显;当l接近k时,l对执行时间的影响则比较明显。
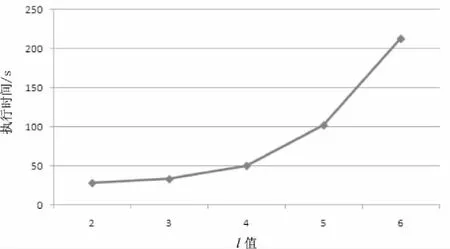
图5 执行时间
5 结束语
对于加权社会网络的隐私保护方法还处在不断研究中。文中提出了一种基于加权社会网络的个性化隐私保护方法,先除去不需要进行保护的节点,再将社会网络按照节点度分组,要求每个分组中的节点满足k-度匿名;对于存在L=2的节点所在分组,要求此分组满足l-多样性;分组结束后,对每个分组根据各边权重出现的频率,确定该分组的权重包标准;通过修改边的权值实现节点的权重包k-匿名,而对于需要重复修改权值的边,通过泛化方法保留每次修改后的权值。实验结果表明,算法在满足用户的隐私保护要求的前提下,降低了对社会网络结构信息的破坏。但在处理敏感属性满足l-多样性的过程中只考虑单一敏感属性,并且对引入的噪声节点未进行匿名处理,以后还需针对上述问题不断完善。
[1]SamaratiP,SweeneyL.Generalizingdatatoprovideanonymitywhendisclosinginformation[C]//ProceedingsoftheseventeenthACMSIGACT-SIGMOD-SIGARTsymposiumonprinciplesofdatabasesystems.[s.l.]:ACM,1998.
[2]LiuK,TerziE.Towardsidentityanonymizationongraphs[C]//ProceedingsofACMSIGMODinternationalconferenceonmanagementofdata.Vancouver:ACM,2008:93-106.
[3]ZhouB,PeiJ.Preservingprivacyinsocialnetworksagainstneighborhoodattacks[C]//ProcofIEEEinternationalconferenceondataengineering.[s.l.]:IEEEComputerSociety,2008:506-515.
[4]JiaoJ,LiuP,LiX.Apersonalizedprivacypreservingmethodforpublishingsocialnetworkdata[M]//Theoryandapplicationsofmodelsofcomputation.[s.l.]:SpringerInternationalPublishing,2014:141-157.
[5]ZhouB,PeiJ.Thek-anonymityandl-diversityapproachesforprivacypreservationinsocialnetworksagainstneighborhoodattacks[J].Knowledge&InformationSystems,2011,28(1):47-77.
[6]TripathyBK,SishodiaMS,JainS,etal.Privacyandanonymizationinsocialnetworks[M]//Socialnetworking.[s.l.]:SpringerInternationalPublishing,2014.
[7]SongY,KarrasP,XiaoQ,etal.Sensitivelabelprivacyprotectiononsocialnetworkdata[M]//Scientificandstatisticaldatabasemanagement.Berlin:Springer,2012:562-571.
[8]SkarkalaME,MaragoudakisM,GritzalisS,etal.Privacypreservationbyk-anonymizationofweightedsocialnetworks[C]//Proceedingsofthe2012internationalconferenceonadvancesinsocialnetworksanalysisandmining.[s.l.]:IEEEComputerSociety,2012:423-428.
[9]TsaiYC,WangSL,HongTP,etal.[K1,K2]-anonymizationofshortestpaths[C]//Procofinternationalconferenceonadvancesinmobilecomputing&multimedia.[s.l.]:ACM,2014:317-321.
[10]TsaiYC,WangSL,HongTP,etal.Extending[K1,K2]anonymizationofshortestpathsforsocialnetworks[M]//Multidisciplinarysocialnetworksresearch.Berlin:Springer,2015:187-199.
[11]ChenKe,ZhangHongyi,WangBin,etal.Protectingsensitivelabelsinweightedsocialnetworks[C]//Procofwebinformationsystemandapplicationconference.[s.l.]:IEEE,2013:221-226.
[12] 陈 可,刘向宇,王 斌,等.防止路径攻击的加权社会网络匿名化技术[J].计算机科学与探索,2013,7(11):961-972.
[13] 兰丽辉,鞠时光.基于向量相似的权重社会网络隐私保护[J].电子学报,2015,43(8):1568-1574.
[14] 兰丽辉,鞠时光.基于差分隐私的权重社会网络隐私保护[J].通信学报,2015,36(9):145-159.
Personalized Privacy Preservation Algorithm in Weighted Social Networks
CHEN Chun-ling,XIONG Jing,CHEN Lin,YU Han
(School of Computer Science & Technology,School of Software,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
There is a phenomenon that some users do not need privacy protections or they need special privacy protections in social networks,so a personalized privacy protection method to meet these requirements is proposed based on weighted social network.The privacy protection is divided into three levels:without protection (L=0),preventingtheweightbagsattack(L=1),andpreventingthesensitiveattributesdisclosure(L=2).FornodeswithL≠0,k-degreegroupingandweightbagmodifyingisusedtotheanonymousnodes,whichmakeseachgroupmeetsthekanonymityofweightbag.Intheprocessofgrouping,thegroupwithL=2hastoensurel-diversityforsensitiveattributes.Theoreticalanalysisandexperimentsshowthatattackerscan’tidentifyanodewiththeprobabilityover1/kandinfernode’ssensitiveattributewiththeprobabilityover1/l.Themethodsatisfiestheuser’srequirementsinweightedsocialnetwork,andtheinformationlossisreduced.
weighted social network;privacy preservation;personalization;weight bag;sensitive attributes
2015-11-18
2016-03-03
时间:2016-08-01
国家自然科学基金资助项目(11501302)
陈春玲(1961-),男,教授,硕士,CCF会员,从事软件技术及其在通信中的应用、网络信息安全等方面的教学和科研工作;熊 晶(1991-),女,硕士研究生,研究方向为信息安全与隐私保护。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0842.018.html
TP
A
1673-629X(2016)08-0088-05
10.3969/j.issn.1673-629X.2016.08.019
