基于Spark平台的地理数据并行装载技术
2016-02-13贺梦洁朱美正
贺梦洁,朱美正,初 宁,杨 岗
(1. 中国电子科技集团第十五研究所,北京 100000;2. 中国电子设备系统工程公司研究所,北京 100000)
基于Spark平台的地理数据并行装载技术
贺梦洁1,朱美正1,初 宁2,杨 岗2
(1. 中国电子科技集团第十五研究所,北京 100000;2. 中国电子设备系统工程公司研究所,北京 100000)
随着地理信息系统研究的不断深入发展,其应用领域不断扩张,地理数据规模越来越大,高性能的地理数据处理成为迫切并且必然的要求。为了适应地理信息系统发展的需要,本文设计了基于Spark平台的地理数据并行处理框架,并最终设计实现了地理数据并行装载技术,使得地理数据装载效率得到显著提高,为今后实现地理数据实时更新、访问、分析等奠定了良好的基础。
Spark;地理信息系统;并行装载
0 引言
随着信息时代的来临,人们对地理数据的依赖性越来越强。如今线上贸易渗透到生活的每个角落,物流公司需要利用地理数据节约成本、提高效率;经销商需要参考地理数据做出重要的商业决策;人们出行也基本不再使用纸质地图,有地图应用可以给出详细的路线指导。可见,衣、食、住、行无不和地理数据相关,因此对地理数据的需求量逐年呈爆炸式增长,称为海量亦不为过。与此同时,对地理数据处理的性能需求也越来越高。地理数据处理包括装载、组织、查询、分析等等,传统的单个CPU的计算资源,单进程、集中式的数据处理方式已经远远无法满足目前的性能需求,为了突破传统处理方式的限制,考虑在高并发空间大数据库的基础上,采用多机、多进程、分布式的数据并行处理方式,充分利用并行计算巨大的数值计算和数据处理能力的优势,实现海量地理数据的快速装载、组织、查询、分析、更新和访问。
地理数据并行装载技术是地理数据并行处理的第一步,也是后续处理的基础。完整、正确且合理平均的将相关地理数据装载到相应的分布式存储系统,才能保证后续检索、更新和访问等处理过程的效率。因此地理数据并行装载技术对于海量地理数据高效处理的意义尤为重要。
本文将从Spark分布式并行计算平台、基于Spark平台的地理数据并行处理框架、地理数据并行装载技术等方面进行详细介绍。
1 基于Spark平台的地理数据并行处理框架
1.1 Spark分布式并行计算平台
Spark于2009年诞生于加州大学伯克利分校AMPLab[1],目前已经成为大数据领域应用最广泛、最高效的通用集群计算平台。Spark是基于MapReduce思想实现的分布式并行计算框架,继承了Hadoop的MapReduce的优点,但相比MapReduce有更多拓展应用和更高效的计算模型。
Spark创造性地提出了分布式内存存储结构弹性分布式数据集RDD的概念,在此基础上可以在Spark这个统一的框架下高效地支持包括批处理、迭代算法、交互式查询、流处理等在内的多种计算模式。
大数据计算流程往往分为多个阶段,在MapReduce中,不同计算阶段之间重用数据,需要将上一个阶段的计算结果保存到外部存储系统(如分布式文件系统HDFS)中[10],由此导致了大量的数据复制、磁盘I/O、序列化、反序列化等开销[2],大大降低了计算效率。而Spark将执行模型抽象为通用的有向无环图执行计划(DAG),可以将有多个计算阶段的任务串联或者并行执行,计算阶段的中间结果用分布式内存存储结构弹性分布式数据集RDD的形式存储在内存中,因此不同计算阶段之间只需读写内存,无需读写磁盘[8]。在内存空间不足的情况下,也可以像Hadoop一样存储在磁盘上。相对于MapReduce上的批量计算、迭代型计算以及基于Hive的SQL查询,Spark可以带来上百倍的性能提升[1]。
Spark所提供的接口非常丰富。除了提供基于Python、Java、Scala和SQL的简单易用的API以及内建的丰富的程序库之外,Spark还能和其他大数据工具密切配合使用[3]。AMPLab开发以Spark为核心的伯克利数据分析栈(BDAS)的目标是在一套软件栈内完成各种大数据计算任务。BDAS涵盖支持结构化数据SQL查询与分析的查询引擎Spark SQL和Shark,提供机器学习功能的系统MLbase及底层的分布式机器学习库MLlib、并行图计算框架GraphX、流计算框架Spark Streaming、采样近似计算查询引擎BlinkDB、内存分布式文件系统Tachyon、资源管理框架Mesos等组件[1],这些组件和Spark紧密集成,共享数据,因此可以构建出无缝整合不同处理模型的应用[9]。
以上这些优点和特性使得Spark成为目前大数据处理首选的计算平台,也是本文将Spark应用于海量地理数据处理系统的原因。
1.2 适用于并行处理的地理数据模型
数据模型是并行计算的基础,空间数据组织结构是否合理直接决定数据并行处理的性能,决定数据部署、维护、检索、获取的效率,尤其是对于海量空间数据的处理更是重要。为了实现地理数据的高效处理,需要重点研究并行计算环境下地理数据模型应该满足的要求,如空间实体对象的完整性特征,空间实体对象之间不存在紧耦合状态,彼此相互独立,其拓扑、度量等关系可动态创建等等[6]。地理数据模型及数据结构应适用于并行I/O操作,可实现基于这类数据模型的并行快速查询和迅速处理。
考虑以上特征,设计了面片,这种非结构化地理数据模型作为地理数据并行处理的对象单元。首先,地理数据按数据类别(如矢量数据、影像数据等)分类存储。某一类数据分N个面片数据集存于分布式数据库系统的各个物理存储节点上。每个面片数据集有固定的空间参考、面片划分方案、资源类型、面片类型、应用类型、面片格式。面片数据集内部又按不同级别对面片分类,每种级别对应一个确定大小的比例尺,级别越大对应的分辨率越高、比例尺越大,支持创建金字塔数据。每个级别数据集里又分为N个桶或桶集,桶集包含N个桶,按桶组织可以避免因面片数目巨大而造成管理低效,更易于部署、更新、迁移。桶里可以按多个版本区分数据,版本表示数据来源、年份等等含义。版本数据集再包含面片数据,面片数据是数据存储的最小粒度单位。桶集有桶分布位图,反映哪些桶有数据;桶有面片分布位图,反映某个桶的某个版本的面片分布情况。面片的逻辑模型如图1所示。
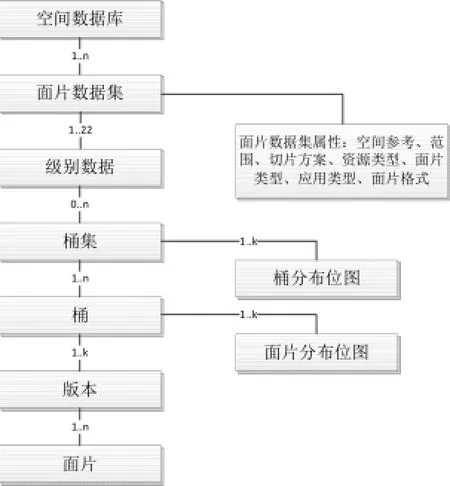
图1 面片的逻辑模型Fig.1 Piece Logical Model
面片这种数据模型互相独立,可存储于分布式数据库,适用于并行I/O操作,在此基础上可实现地理数据分布式并行处理。
1.3 地理数据并行处理框架
1.3.1 Spark开发环境及其分布式集群搭建
目前Apache Spark 支持三种分布式部署方式,分别是standalone、spark on Mesos和spark on YARN[7]。Standalone模式,即独立模式,其内部实现了容错性和资源管理,无需依赖任何其他资源管理系统。后两种则是在企业级应用和工业生产中常用的模式,部分容错性和资源管理交由统一的资源管理系统完成,让Spark运行在一个通用的资源管理系统之上,这样可以和其他计算框架共用一个集群资源,最大的好处是降低运维成本和提高资源利用率。从一定程度上来说,standalone模式是后两种模式的基础。借鉴spark开发模式,我们可以得到一种开发新的计算框架的一般思路:为了快速开发,可以暂不考虑服务(比如master/slave)的容错性,先设计出它的standalone模式(目前spark在standalone模式下没有单点故障问题,这是借助zookeeper实现的),之后在开发相应的wrapper,将standalone模式下的服务原封不动地部署到资源管理系统mesos或yarn上,由资源管理系统负责服务本身的容错。由于在项目初期,本文设计的地理数据并行处理框架就是在spark的standalone模式下实现的。
本文的实验测试环境为两台Linux测试机。集群包括一个master节点和两个worker节点,两个worker节点分别部署在两台机器上,其中一台机器同时作为master节点。每个worker节点有多个CPU,以达到多机、多进程并行处理的目的。测试使用的Spark集群如图2所示。

图2 本文测试使用的Spark集群模型及其硬件信息Fig.2 Spark Cluster Model of Test and Its Hardware Information
1.3.2 基于Spark的地理数据并行处理框架
Spark应用是用户提交的应用程序。Driver进程是Spark应用的主控进程,负责应用的解析、切分Stage并调度Task到Executor执行,包含DAGScheduler等重要对象。Spark应用的提交包含两种方式:其一,Driver进程运行在客户端,对应用进行管理监控;其二,主节点指定某个Worker节点启动Driver进程,负责整个应用的监控。本文实验采取的是第一种方式。
应用执行流程如图3所示。用户启动客户端,之后客户端运行用户程序,启动Driver进程。在Driver中启动或实例化DAGScheduler、SparkContext等组件。客户端的Driver向Master注册。Worker 向Master注册,Master命令Worker启动Executor。Worker通过创建ExecutorRunner线程,在ExecutorRunner线程内部启动ExecutorBackend进程。ExecutorBackend启动后,向客户端Driver进程内的SchedulerBackend注册,这样Driver进程就能找到计算资源。

图3 Driver进程在Client端的应用执行流程图Fig.3 The Flow Chart of Application Execution When Driver Progress in Client End
弹性分布式数据集(Resilient Distributed Dataset,RDD)是Spark的核心数据结构,可以通过一系列算子进行操作。一个操作执行完毕,RDD变转换为另一个RDD。Spark为了系统的内存不至于快速用完,使用延迟执行的方式执行。只有当RDD遇到Action算子时,将之前的所有算子形成一个有向无环图RDD DAG,由Spark Action(如count、collect等)算子触发整个RDD DAG执行。这样的过程称为一个Job。
Spark应用提交后经过一系列转换变成Job、Stage、Task几个层次被调度,转换过程如图4所示。在Spark应用程序内部,用户通过不同线程提交的Job可以并行运行。默认情况下,Spark的调度器以FIFO(first in first out)方式调度Job。RDD的Action算子触发Job提交到Spark后得到的RDD DAG,由DAGScheduler根据RDD的宽依赖关系将其分解为Stage DAG,每个Stage中产生相应的Task集合,再由TaskScheduler将各个Task分发到Executor执行。每个Task对应相应的一个数据块,使用用户定义的函数处理数据块。
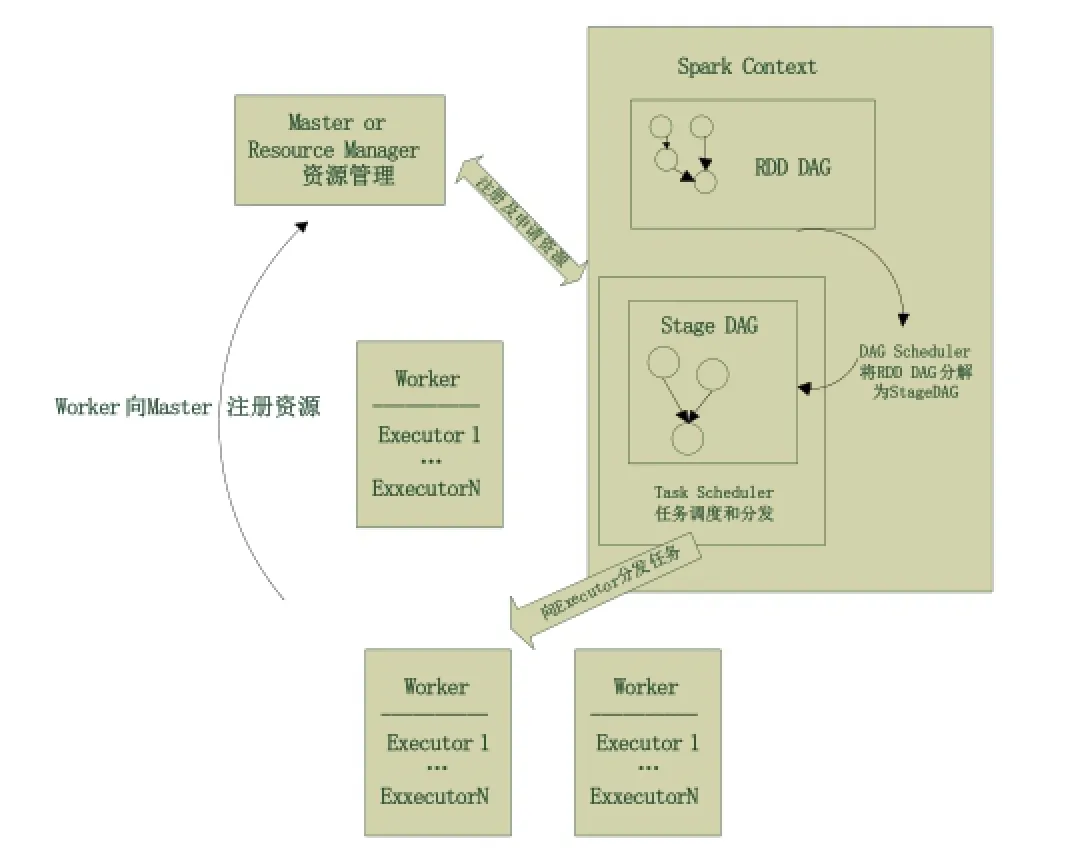
图4 Spark应用转换流程图Fig.4 Spark Application Convertion Flow Chart
2 地理数据并行装载技术
2.1 基于Spark的地理数据并行装载实现步骤
如前文所说,本文设计了面片,这种非结构化地理数据模型作为地理数据并行处理的对象单元。因此,地理数据并行装载技术要实现的目的就是把源数据转换成面片这种数据类型,并将这些面片集存入分布式数据库或分布式文件系统中。源数据通常按不同级别(对应不同的比例尺)以图幅数据文件为单位存储。
地理数据包括矢量数据、影像数据、数字高程模型数据、数字地面模型数据等等常用的数据类型,种类繁多,并行转载步骤略有差异。以矢量数据为例,在本文设计的基于Spark的地理数据并行处理框架上实现矢量数据并行装载基本步骤流程图如图5所示。
用户提交矢量入库任务并输入需要入库的矢量源数据路径。程序解析源数据路径,获得源数据包括的所有图幅文件路径。按一定的规模(地理范围大小)为单位将这些图幅文件分堆,由Driver进程随机分配给各个Worker,由各个Worker并行进行接下来的入库流程。每个Worker各自选取一堆图幅文件,加载这些图幅文件并按面片规则对其做切片处理,得到面片碎片结构的数据集,然后按照面片规则将面片各部分合并得到面片碎片集结构的数据集。判断面片碎片集是否完整,若完整,合并面片并入库;若不完整,缓存。将各节点的不完整面片碎片集再次合并,判断面片碎片集是否完整,若完整,合并面片并入库;若不完整,缓存。重复上个步骤,直到全部面片入库,入库流程结束。
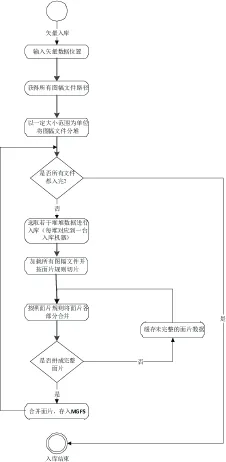
图5 矢量数据并行装载流程图Fig.5 Vector Data Parallel Loading Flow Chart
2.2 基于Spark的地理数据并行装载算法实现思路
本文的地理数据并行装载算法使用Java语言编程,结合基于Spark的地理数据并行处理框架和其算子RDD进行综合设计。算法实现思路主要分为一下两步:
Step1:源数据部分入库,得到不完整面片:使用parallelize将源数据图幅文件以JavaRDD
使用flatMap(JavaRDD
使用mapToPair(JavaRDD
使用filter(._1().startsWith(“ERROR:”)).collect-AsMap()过滤得到其中的错误信息并对其做错误处理。
Step2:面片碎片合并,完整面片入库,不完整面片做相应处理:
使用reduceByKey(_,_)将相同面片码的面片碎片合并,得到面片碎片集JavaPairRDD
判断面片是否完整,使用两个filter分别得到完整面片碎片集和不完整面片碎片集。对于完整面片碎片集,使用mapValues将碎片合并成完整面片并入库,使用Filter().collectAsMap得到错误信息集Map
基于Spark的矢量数据并行装载算法流程如图6所示。
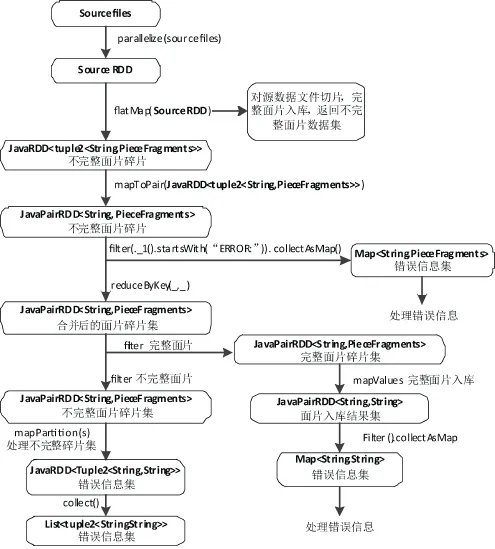
图6 基于Spark的矢量数据并行装载算法流程图Fig.6 The Flow Chart of Vector Data Parallel Loading Algorithm Based on Spark
3 矢量数据装载实验
为了测试本文提出的地理数据并行装载技术的性能,选取部分矢量源数据做装载测试。实验环境包括单机单进程矢量数据装载环境和多机多进程矢量数据并行装载环境。单机单进程矢量数据装载测试用到的机器是linux系统、16G内存、8CPU,用Java编写的矢量单机入库程序,测试时后台只启动了一个应用服务进程;多机多进程矢量数据并行装载测试用到的分布式集群如上文图2所示,集群包括一个master节点和两个worker节点,两个worker节点分别部署在两台Linux测试机上,一台机器16G内存、8CPU同时作为master节点,另一台机器12G内存、8CPU,在Spark并行计算框架下用Java编写的矢量并行入库程序,每个worker启动三个应用服务进程。测试用到的数据有:1:100万比例尺下112万平方公里的全要素矢量数据、1:25万比例尺下2万平方公里的全要素矢量数据、1:5万比例尺下24万平方公里的全要素矢量数据。
测试用的数据和测试结果如表1所示。

表1 测试数据及单机单核、双机三核并行入库时间
从测试结果可以看出,本文提出的地理数据并行装载技术明显提高了地理数据装载的速度,并且在数据规模越大的情况下,并行装载的优势越显著。在实际应用中,集群的规模可在此基础上数十倍甚至上百倍,可以预见并行装载技术的效率将非常高。
4 结束语
本文的主要成果是设计了基于Spark的地理数据并行处理框架和实现了地理数据并行装载技术。相较于传统的单机单进程的地理数据装载方式,利用地理数据并行装载技术可以使得地理数据装载效率得到显著提高,大大缩短了地理数据装载所需时间,为今后实现地理数据实时更新、访问、分析等奠定了良好的基础。
[1] 高彦杰. Spark大数据处理: 技术、应用与性能优化[M]. 机械工业出版社, 2015.01.
[2] 王迅, 冯瑞. 基于Spark的海量图像检索系统设计. 微型电脑应用, 2015, 31(11): 11-17.
[3] Karau.H等著, 王道远译. Spark快速大数据分析[M]. 北京:人民邮电出版社, 2015.09.
[4] 崔鑫. 海量空间数据的分布式存储管理及并行处理技术研究[D]. 国防科学技术大学研究生院, 2010.
[5] 金翰伟. 基于Spark的大数据清洗框架设计与实现[D]. 浙江大学计算机科学与技术学院, 2015.
[6] 张广第, 分布式环境下海量空间数据的存储和并行查询技术研究[D], 南昌: 江西理工大学, 2012.
[7] 温馨、罗侃、陈荣国等, 基于Shark/Spark的分布式空间数据分析框架[J]. 地球信息科学, 2015.4, 17(4): 401-407.
[8] 王迅、冯瑞等, 基于Spark的海量图像检索系统设计[J]。微型电脑应用, 2015, 31(11): 11-17.
[9] 方金云等, 基于Spark的空间数据实时访存技术的研究[J]。地理信息世界, 2015.12, 22(6): 24-31.
[10] 霍红卫, 林帅, 于强, 等. 基于MapReduce的模体发现算法[J]. 新型工业化, 2012, 2(9): 18-30.
Geographic Data Parallel Loading Technology Based on Spark
HE Meng-jie1, ZHU Mei-zheng2, CHU Ning3, YANG Gang3
(1. No.15 Institute of China Electronics Technology Corporation, Beijing, 100000; 2.No.15 Institute of China Electronics Technology Corporation,Beijing, 100000; 3. Institute of China Electronics System Engineering Company, Beijing, 100000)
With the deepening development of GIS research,its application domain expands unceasingly, geographic data scale grows so fast that high-performance of geographic data processing becomes a urgent and inevitable requirement. In order to meet the needs of GIS development, in this paper, geographic data parallel computing framework was designed based on Spark parallel computing platform and geographic data parallel loading was realized, on this basis, the loading efficiency of geographic data improves significantly, geographic data update, access, analysis in real time becomes possible.
Spark; GIS; Parallel loading
TP311
A
10.3969/j.issn.1003-6970.2016.12.016
贺梦洁(1992-),女,硕士研究生,主要研究方向:计算机软件与理论;朱美正(1965-),男,研究员级高级工程师,主要研究方向:地理信息系统平台技术与数据共享;初宁(1972-),男,高级工程师,主要研究方向:指挥自动化;杨岗(1972-),男,主要研究方向:指挥自动化。
本文著录格式:贺梦洁,朱美正,初宁,等. 基于Spark平台的地理数据并行装载技术[J]. 软件,2016,37(12):63-68
