基于Referer字段递归分析的网页挂马检验方法研究
2016-02-10徐国天
徐国天
(中国刑事警察学院,沈阳 110854)
基于Referer字段递归分析的网页挂马检验方法研究
徐国天
(中国刑事警察学院,沈阳 110854)
目的研究网页挂马案件的检验方法,为有效打击此类犯罪,维护信息网络安全提供技术支持。方法在染毒主机端重新浏览可疑网页,使用wireshark捕获通信数据,借助wireshark提供的文件还原功能从通信数据中还原出所有文件,再利用主流杀毒引擎对这些文件进行病毒扫描,记录下木马程序的名称和下载路径。之后利用本文的Referer字段递归分析方法还原木马完整的种植过程,找出被挂马网站和相应的页面,提取出网页中被植入的恶意代码。结果获得了被挂马网站的相关信息,准确地定位出恶意代码的存储位置,提示网站管理员除去恶意代码并增强保护措施,从源头阻断木马的传播途径。根据黑客种植恶意代码过程中在被挂马网站遗留的入侵痕迹,对挂马网站进行检验分析,获得黑客的相关线索。结论应用本文提出的Referer字段递归分析方法可以有效检验网页挂马类案件,获取相关线索。
Referer;递归分析;网页挂马;检验;GZIP
网页挂马不是一种具体的木马程序,而是一种传播木马的途径,它是指通过非法手段在网页源文件中植入恶意代码,当用户浏览这类站点时,如果其计算机系统存在相应的安全漏洞,那么网页中的这些恶意代码就会诱使用户主机下载并运行相应的木马程序[1],从而窃取该计算机的机密信息、篡改重要数据、监听语音视频通信,甚至可完全控制该染毒计算机。目前网页挂马已成为木马传播的主要途径,因此研究网页挂马的检验方法,对有效打击此类犯罪,维护信息网络安全有重要意义。
目前网页挂马类案件主要是对木马程序进行检验分析,常用的检验方法有逆向分析和数据包监听两种。逆向分析是对木马程序文件进行反汇编,通过阅读汇编代码了解程序的执行逻辑,并从中提取出黑客的相关线索,如IP地址、端口号、登录口令等等。但是这种分析方法需要具备较深的计算机基础知识,若只是短期培训难以掌握。而木马程序通常采用加壳、加密、运行后自销毁等保护措施,故单凭逆向分析方法也很难获得相关线索,甚至无法定位木马程序。另一种基于数据包监听的方法是捕获染毒主机与外界的通信数据,再从中提取出木马的相关线索,如黑客主机的IP地址、传递的监控画面等等。这种方法对远程控制类木马效果较好,原因是远程控制木马通常会主动联系黑客主机,很容易捕获其发出的通信数据,并从中提取出有关线索。但是盗号类木马通常不会主动与外界通信,只有在盗取到敏感信息后,才会在特定的时间点发送窃取信息。由于不能确定这类木马何时与外界通信,因此很难准确捕获相应的通信报文,致使无法获取相关线索。
除上述问题,目前的检验方法也不能阻断木马程序传播的源头,即未对挂马网站进行相应处理,而使广大用户避免感染木马的风险。针对这些问题,本文进行了研究,设计了对应检验方法。
1 网页挂马入侵流程及相关网络安全技术分析
网页挂马案件的入侵流程如图1所示。首先,黑客会利用网络攻击技术入侵某些有安全漏洞的网站,从而获得这些站点的控制权[2]。通常一些中等规模的站点易成为攻击对象,例如政府机关、企事业单位、高等院校的门户网站。黑客会在入侵网站的主页文件中植入一个挂马代码。当用户浏览“被挂马”网站时,若其所用IE浏览器存在相应的安全漏洞,木马就会被植入并运行而使相关主机沦为受控“肉鸡”,盗取敏感信息(如网银帐号),以及向其他主机发起DDOS攻击等。
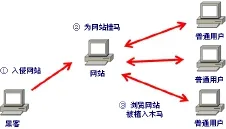
图1 网页挂马的入侵流程Fig.1 Intrusion course of webpage Trojan
1.1 入侵网站
目前最流行的攻击技术是“SQL注入攻击”和“缓冲区溢出攻击”。“SQL注入攻击”是由于开发网站的技术人员疏于防范,未对用户提交的参数严格检查,就直接提交给后台数据库运行。若这些参数含有黑客提交的恶意指令并执行时,黑客就可达到完全控制网站的目的。“缓冲区溢出攻击”是由于应用程序未对经网络接收的数据长度进行检查,就直接存放于缓冲区而导致了“缓冲区溢出”。黑客通过精心构造溢出代码,可实现其控制目的。
1.2 为网站主页挂马
用户访问网站,通常是先进入网站主页,然后再通过主页上的链接进入到自己感兴趣的页面。故主页是访问频率最高的页面,黑客为达到快速传播木马的目的,通常选择主页作为挂马的对象[3]。
下面是一段典型的挂马代码,将这句代码加入到被挂马网站主页文件的任何一处位置,即可实现网站挂马,具体语句为:。这是一种框架挂马方式,用户访问主页之后,会自动到包含木马程序的服务器上下载并浏览1.html,这个1.html会利用IE浏览器漏洞诱使用户主机自动下载并运行木马程序(例如1.exe),由于这里将框架的高度、宽度和边框粗细均设置为0,因此受害者在浏览主页时不会察觉到任何变化。故黑客不需要将1.html和1.exe上传到被挂马网站,只须修改被挂马网站的主页文件,就可实现网站挂马,因而具备很强的隐蔽性。
1.3 植入并运行木马
浏览“挂马”网站时,若用户使用的IE浏览器存在相应的安全漏洞,用户主机就会被植入木马并运行。目前黑客广泛采用的木马种类有“盗号木马”和“远程控制木马”。
“盗号木马”可以窃取用户在登录窗口内输入的敏感信息,如用户名、密码等。这类木马会造成网络用户的QQ密码、网上银行帐号信息丢失,等等。例如“红蜘蛛键盘记录木马”记录到敏感信息(如电子邮箱帐户信息)后,会将这些信息通过电子邮件发送到黑客指定的邮箱里。远程控制木马可以远程操作一台“肉鸡”,对其实施完全控制。
2 基于Referer字段递归分析的网页挂马检验方法
相对而言exe类型木马容易被杀毒软件查杀,且易被定位追踪。为了提高木马的生存几率,黑客会采用fash动画、语音、视频、图片等类型文件作为木马的载体。本节对网页木马的检验方法进行介绍。
2.1 网页木马的检验流程
如图2所示,以1.12.4版wireshark作分析检测。首先,在疑遭木马攻击的网页主机端运行wireshark,获取通信数据后,浏览可疑网页,要尽量关闭不必要的网络通信程序,减少通信流量。利用wireshark提供的数据还原功能从通信数据中提取出所有数据文件,检测其中是否有木马程序,该步可使用现有杀毒软件的扫描功能实现,宜多选几种杀毒软件,以降低错漏率;或可将可疑文件上传到专门的检测网站,如“金山火眼”,深入分析程序的执行功能。若发现木马程序文件,可以对应的数据包为起点,进行递归分析,获取完整的控制链条,形成检验结果。如果还有其它可疑页面,重复分析过程。

图2 网页挂马检验流程Fig.2 Investigation course of webpage Trojan
2.2 基于Referer字段的递归分析方法
任何类型的网页木马都是在浏览网页过程中通过HTTP协议传递到受害者主机端。而HTTP请求报文首部携带了一个Referer字段,这个字段表明当前数据包是由哪个URL链接跳转过来的。通过这个字段逐一进行递归分析,可以获得网页木马完整的控制链条。图3为举例说明。

图3 利用Referer字段递归还原通信链条Fig.3 Recursive analysis of referer feld to show the communication chain
图3中,先后浏览新浪、网易和搜狐的主页。第三个请求报文是客户访问搜狐主页时发出的HTTP-GET数据包,其Host字段表明当前访问服务器的域名为www.sohu.com。Referer字段表明上一个URL链接为news.163.com/,表示客户浏览了网易的新闻主页之后跳转于此。利用此办法可递归分析出用户浏览的次序为新浪、网易、搜狐。图4显示利用Referer字段还原网页木马的整个种植流程。调查人员首先定位到恶意文件的起始数据包,这个步骤可以使用杀毒软件和wireshark实现,具体介绍见后。通过这个报文的Referer字段向前搜索,可依次定位到每个触发报文,并同时还原出对应的网页文件。再从中提取出恶意代码,直至完成整个分析工作。
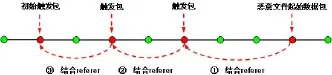
图4 递归还原控制链条Fig.4 Recursive restoration of control chain
2.3 GZIP压缩数据文件手工还原方法
HTTP协议采用两种方式进行数据传输。一种是不压缩的传输方式,将原始文件分为若干块直接传输,如html、图片、动画文件等,它适合体积较小文件的传输。另一种是压缩传输方式,适合语音、视频的实时传输,如即时语音、视频聊天等,这类数据传输之前并不知道其文件的大小,但通常较大,发送方对每一个数据块先压缩再传送。接收方收到后,需解压才能得到原始数据。目前HTTP协议常用的压缩算法是GZIP。GZIP最早由Jean-loup Gailly和Mark Adler创建,用于UNIX系统的文件压缩。在Linux中经常会看到后缀为.gz的文件,这些文件就是GZIP格式的。现在已经成为Internet上使用非常普遍的一种数据压缩格式。HTTP协议上的GZIP编码是一种用来改进web应用程序性能的技术。大流量的web站点常常使用GZIP压缩技术,此为WWW服务器安装的一个功能,当访问这台服务器上的主页时,其网页内容经压缩后再传递给客户主机,一般纯文本内容可以压缩到原大小的40 %左右。传输过程中,原始数据块被压缩为若干个GZIP数据块,每个数据块首部均有一个长度字段,用以说明这个GZIP数据块的大小。使用wireshark不能直接查看捕获的GZIP数据内容,需要借助第三方软件对其进行解码还原才行。图5显示了GZIP数据的手工还原过程。首先利用wireshark的TCP follow stream功能跟踪特定的TCP数据流,提取出完整的通信流数据,注意这里只提取单方向通信数据。若两个方向交互传递数据,则分别提取。而后使用winhex提取出组合后的GZIP数据。这些数据块首部携带长度值,需要去除,否则压缩文件无法解压。编制一个软件自动去掉这些长度字段,或以手工方式实现。调整之后的压缩数据可以直接进行解压,得到原始数据内容。
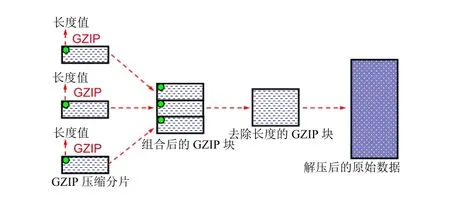
图5 GZIP压缩数据手工还原过程Fig.5 Reduction of GZIP-compressed data
3 基于Referer字段递归分析检验方法应用举例
某台计算机疑遭网页木马攻击,使用1.12.4版wireshark抓取此主机浏览可疑网页过程中产生的通信数据并作分析,确定是否存在恶意木马程序,还原完整的木马种植流程。取证软件winhex用作辅助分析,具体步骤如下:
第一步 利用wireshark自动还原所有文件。使用wireshark打开捕获数据包,选择数据自动还原功能,从捕获的HTTP通信数据中自动还原出所有的数据文件,包括网页、图片、语音、动画,等等。Wireshark自动还原功能的分析结果包括多行记录,每行记录代表一个可还原文件。例如记录“102 www. bing.com text/xml 960bytes lsp.aspx”,其第一个字段代表当前文件的起始数据包编号为102,第二个字段表示文件是从域名为www.bing.com的服务器传出,第三个字段表示文件类型为文本数据,第四个字段表示文件大小为960字节,第五个字段表示文件名称为lsp.aspx。若还原单个文件,可以选中对应记录,单击Save as,将文件保存到特定位置。如还原所有文件,则单击Save All,wireshark自动将所有文件保存到特定位置。
第二步 利用wireshark和winhex手工还原GZIP压缩数据。Wireshark虽能识别出多个GZIP压缩数据块,但是它无法将这些数据块组合、还原为原始数据文件,需要进行手工提取、还原。
(1)提取传输GZIP文件的TCP数据流。在wireshark自动还原结果中任选一个GZIP数据包,wireshark将对其自动命中。在起始报文上单击鼠标右键,选择Follow TCP Stream。图6是弹出的分析结果,其只显示所有通信数据包的应用层数据内容,并按ASCII码解析。横线上面是客户机发出的HTTP-GET请求报文,表明客户当前访问服务器名称为stand.***.com,具体域名用*代替。客户可以接收gzip和defate类型传输编码。Referer字段表明用户之前访问的是http://*** shop.com网站主页。
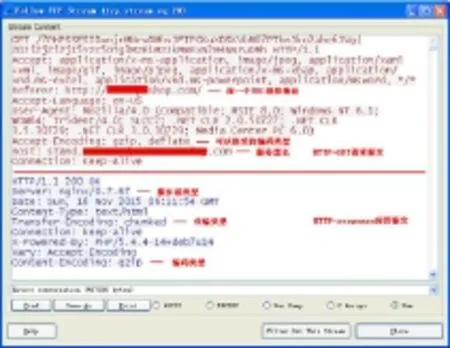
图6 确定传输类型Fig.6 Determining the types of data
横线下面是服务器返回的HTTP应答数据,表明服务器类型、访问时间、传输与编码类型等。显示的通信是双方互传数据,共497936字节。
(2)提取服务器向客户机单方向传输的通信数据。GZIP压缩通信数据虽可以双向传递,但是在客户浏览网页过程中,通常是由服务器向客户机单方向传递。因此只需要提取这个方向的通信数据,再去除头尾杂质数据即可。
(3)去除文件首尾的杂质数据,提取GZIP数据。如图7,GZIP文件的起始标志是0X1F8B,使用winhex打开上一步提取出的数据文件,搜索关键词0X1F8B,命中位置为GZIP文件的起始位置,将0X1F字节标记为起始位置[4]。

图7 定位GZIP文件的起始和结束位置Fig.7 The starting and ending positions of GZIP-drawn data
从起始位置向后搜索ASCII字符串HTTP,可以定位到下一个文件的起始位置,在它之前会出现若干个0X0D0A标记,从后向前搜索到最前面一个0X0D0A,这里就是GZIP文件的结束位置。将0X00字节标记为结束位置,将选中的数据块内容拷贝出来,保存到新文件中, GZIP数据提取完成。
(4)去除GZIP数据中夹杂的长度数据。每个GZIP压缩数据块的起始位置均有一个长度值,这个数值前后固定是0X0D0A,中间用ASCII表示十六进制的长度。如图8,第一个GZIP数据块的长度为0X32 30 30 30,对应ASCII码为2000,转换为十进制数为8192,即第一个压缩数据块长度为8192字节。
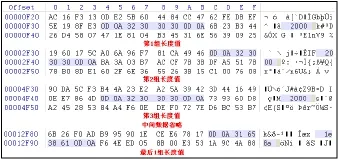
图8 去除GZIP数据中夹杂的长度值Fig.8 Impurity removal from GZIP-drawn data
利用winhex的十六进制搜索功能查找0X0D0A,可以将所有长度值依次搜索出来。选中长度值和其前后的0X0D0A,将其剪切掉,去除所有的长度标志。将得到的数据文件扩展名修改为.gz,再使用winrar软件对其进行解压缩,就还原出一个原始数据文件。在本例中观察还原出的数据,确定其应为一个html文件,核心程序代码经过加密处理,疑似存在恶意代码,需要通过进一步分析才能确定,这里将其名称修改为主页.html。
第三步 检测是否存在恶意木马程序。将还原出的所有文件都放置在一个文件夹内,使用“安全管家”对该文件夹进行扫描,在本例中发现存在三个恶意程序文件,分别是一个swf文件、一个jar文件和之前还原的“主页.html”。前两个文件为非exe类型的溢出类程序,黑客可以利用其入侵计算机系统。第三个文件是一段网页木马程序,可在用户未察觉的情况下窃取个人资料、破坏计算机系统。“金山火眼”系统可以分析特定类型程序文件的执行功能[5],支持html代码分析,将“主页.html”上传到“金山火眼”分析,其点评是创建互斥体的恶意行为。
第四步 利用Referer字段递归还原控制链条。通过上面分析,初步确定jar和swf为可疑木马程序文件,“主页.html”为恶意脚本文件。下面举例说明以swf文件为起点,反向分析其完整的控制链条。
(1)提取传输swf文件的TCP通信数据流。在wireshark的自动分析结果中选择swf文件所在记录,选择Follow TCP Stream,提取出对应的TCP数据流。
(2)还原倒数第二步URL链接。从提取的TCP数据流中单击fnd,搜索关键词swf,可以命中一个结果。这是客户主机发出的HTTP-GET请求报文,请求下载swf文件。在本例中,这个HTTPGET请求报文的Host字段表明当前服务器的域名为stand.***.com。Referer字段表明前一个URL地址为http://stand.***.com/?PHPSSESID=njrMNruDMhvJFI PGKuXDSKVbM07PThnJko2ahe6JVg | ZDJiZjZiZjI-5Yzc5OTg3MzE1MzJkMmExN2M4NNruDMh,正是此URL链接,客户主机才发出了HTTP-GET请求,下载swf文件。
(3)还原倒数第三步URL链接。以前一步获得的Referer字段作为关键词,在整个TCP数据流中进行搜索。命中一个HTTP-GET请求报文。报文的Host字段表明这个HTTP-GET请求仍是发送给stand.***.com服务器。通过前面分析可知,这里请求下载的正是“主页.html”,就是在这个恶意网页的作用下,才促使客户主机自动下载swf文件。Referer字段表明前一个URL链接为http://*** shop.com/,用户恰是浏览了这个网站的主页后,才触发了该步HTTP-GET请求报文。
(4)还原倒数第四步URL链接。由于目标服务器由stand.***.com切换到***shop.com,因此不能在之前的TCP数据流中进行搜索,需要找出客户访问***shop.com服务器主页的TCP数据流。通过wireshark提供的自动还原功能可以定位到浏览***shop. com主页的起始数据包。在该数据包上选择Follow TCP Stream,在提取出的TCP数据流中搜索关键词/,命中一个HTTP-GET请求报文。报文的Host字段表明当前访问的是***shop.com服务器,GET / 表示当前浏览的是服务器主页。在这个主页中携带了一条