一种共享动态缓冲的MPNoC路由器设计
2016-02-09汪少铭廖继阳贾小权
汪少铭,廖继阳,贾小权,董 瑞,刘 峰
(1. 中国人民解放军92246部队,上海 200940;2. 海军驻哈尔滨703所代表室,哈尔滨 150078;3.中国人民解放军91315部队,辽宁116041;4.海军蚌埠士官学校机电系舰船动力教研室,安徽蚌埠 233012)
一种共享动态缓冲的MPNoC路由器设计
汪少铭1,廖继阳1,贾小权2,董 瑞3,刘 峰4
(1. 中国人民解放军92246部队,上海 200940;2. 海军驻哈尔滨703所代表室,哈尔滨 150078;3.中国人民解放军91315部队,辽宁116041;4.海军蚌埠士官学校机电系舰船动力教研室,安徽蚌埠 233012)
在片上多处理系统(Multiprocessor System-on-Chip,MPSoC)中,对路由器缓存区分配策略分析,实现缓冲区动态分配,能够有效提高嵌入式多核处理器芯片多方面的性能。本文了设计一种共享动态Buffer的MPNoC路由器,该路由器可以通过有效分配各通道缓冲资源,实现资源共享。在16节点2D-mesh网络拓扑结构下对静态路由器和本路由器进行仿真分析,实验结果表明,共享动态Buffer的MPNoC路由器与静态路由器相比,具有内存开销低、能量消耗低、平均信息延时小的特点。
片上多处理系统 路由器 动态分配 资源共享
0 引言
随着科技的迅猛发展,对嵌入式计算机提出了越来越高的性能需求。片上网络(Network-on-Chip,NoC)技术[1]解决了集成在单个芯片上的存储器、微处理器、输入/输出设备等硬件单元之间的数据通信问题。但当前的片上网络系统却存在严重的资源受限问题,主要归结为片上路由器缓冲资源利用率低,网络信息拥塞率高[2]。为了更好构建资源节约型和高性能的片上系统,就需要更加注重缓冲区的结构设计。
为了使系统网络获得较高的吞吐率和容错效果,从而高效地利用缓冲资源,在分析静态多通道路由器结构的基础上,提出一种新的多输出通道的动态缓冲结构的路由器。该路由器能够根据网络的通信需求,对缓冲资源进行动态调整,从而真正解决片上路由器资源利用率的问题。
1 片上路由器设计
片上路由器是NoC的最基本的组成部分,高集成和强运算能力的MPSoC系统强调互连线延迟、带宽、资源利用率和吞吐量等方面的问题。为了提高路由器缓冲利用效率和获得高性能,目前大量研究关注虚通道(Virtual Channel,VC)技术[3]和虫孔交换技术[4]。但高流量情况下的的VC分配和VC仲裁使网络物理缓冲区分配变得复杂,并且大量的VC增加数据传输延迟。静态对称缓冲结构资源利用率低。本文在分析静态分配缓冲资源情况下,设计了一种动态充分利用缓冲资源的共享动态Buffer的MPNoC路由器。
1.1 传统多通道路由器结构
传统路由器架构大多数为固定和静态的结构,缺乏灵活性.传统静态路由器结构如图1所示。链路控制单元负责路由器中传输数据流的调节;通过路由器的每个输入端口的FIFO关联控制逻辑中的决策单元,在既定路由算法下确定数据包的转发。通过路由器的每个输出端口的仲裁器控制信号和发送数据包。在此结构中每个端口固定了缓冲区容量,VC通道之间不能进行缓冲区交叉使用。实际使用中网络路由的缓冲区资源不能被交叉使用,严重降低了资源使用效率。因此设计一个共享动态Buffer的MPNoC路由器能够解决上述方案存在的问题。
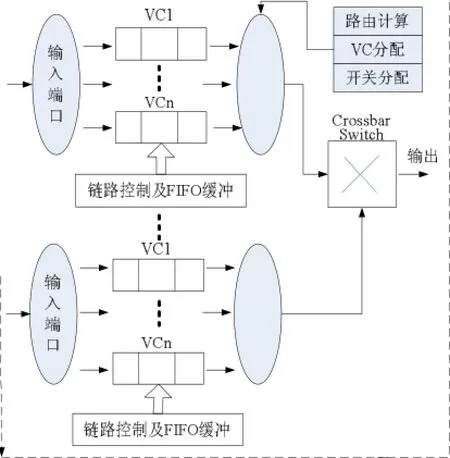
图1 传统多通道路由器结构
1.2 多通道共享动态缓冲路由器结构及工作原理
共享动态缓冲路由器结构是通过集中管理缓冲区资源,根据通道的流量情况动态分配缓冲区资源。多通道共享动态缓冲路由器结构图如图2所示。
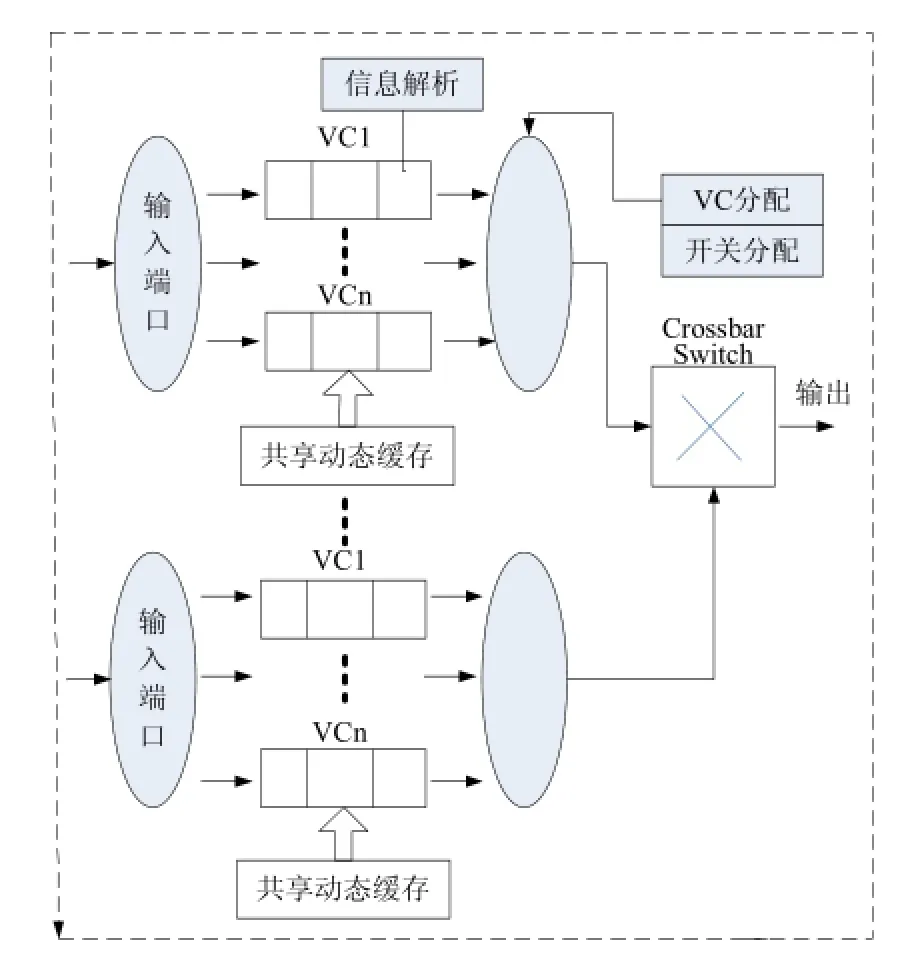
图2 多通道共享动态缓冲路由器结构图
在多通道共享动态缓冲路由器中引入基于链表[5]的方式对缓冲区进行统一管理,虚拟通道VC通过数据报文长短分配缓冲区容量,通过计算每条报文的长度灵活实现缓冲区的分配与释放。这种共享动态缓冲路由结构能够确保任何通信要求的输入通道使用所有的缓冲资源。当一条数据报文到达路由器输入端口时,根据上一节点输出端口确定当前数据报文输入端口,通过提前路由计算与报文解析,及早明确报文到达下一跳后的输出端口,从整体上简化了报文在路由器内部的多路选择仲裁过程。开关分配有效减少VC仲裁的复杂度。动态缓冲区链表结构如图3所示。
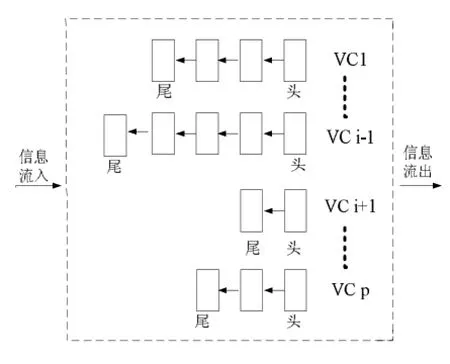
图3 动态缓冲区分配链表结构图
上述原理可描述为:根多通道原理分配N-1个通道虚通道,这N-1个通道根据报文微片流入/流出状况动态申请缓冲资源的使用。同时及时更新链表队列保存有效微片数,确定报文长度及所需缓冲区最大空间,路由器通过这种方法可有效提高NoC的服务质量。
2 实验验证及结果分析
在VHDL语言的寄存器传输级(register transfer level,RTL)和S2C公司的dual virtex-5 330 module现场可编程门阵列(FPGA)实现片上网络原型系统[6]。多通道共享动态缓冲路由器的硬件开销是比较低的。
实验中对不同大小的动态缓冲区,用S2C功耗分析工具测量分析了静态/动态缓冲路由器的内存开销和功耗比较,实验中分析出内存开销和功耗保持着相同的应对指标,具有相同的关联特性,两者的实际测试结果如图4所示。其中横坐标表示通道宽度和缓冲区大小,纵坐标表示内存开销及功耗。

图4 静态/动态缓冲路由器内存开销/功耗比较
实验结果显示共享动态缓冲路由器开销明显低于静态路由器开销。共享动态缓冲路由器中高效的内存使用取决于其内存结构,它的内存能根据流量的大小动态调整缓冲资源,实现有效分配。因此,当缓冲区的大小增加时,静态路由器的局限性,导致其内存开销和功耗明显增大。
为了进一步检验共享动态缓冲路由器体系结构的工作效率,在随机均匀流通信模式下,将它与静态路由器传输数据包服务质量进行仿真分析。实验设置如下所示:搭建16节点的2D-Mesh不同路由器拓扑结构网络,8微片缓冲大小。配合使用虫洞交换技术、XY路由算法进行实验仿真。图6给出了NoC中使用静态路由器和共享动态缓冲路由器的数据包传输率曲线图。
从图5可以得出,静态路由器NoC服务质量明显低于共享动态缓冲路由器,当静态路由器缓冲区满时,数据包会阻塞。共享动态缓冲路由器由于使用了高度灵活的缓冲区链表管理方式,能够最大限度地使用路由器中的所有缓冲资源,减小因阻塞引起的数据包传递延迟。因此在高通信负载的情况下,共享动态缓冲路由器具有更高的无阻塞传输率.
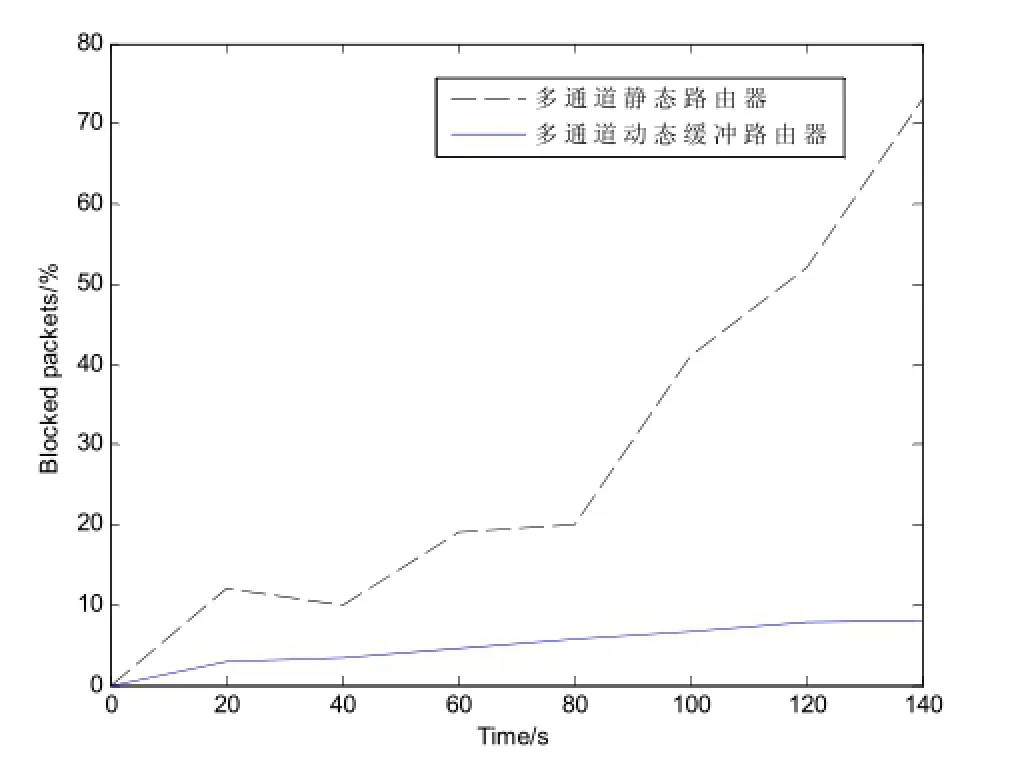
图5 静态/动态缓冲路由器数据包传输率比较
通过构建两种路由器模型的16个节点的NoC网络进行均匀流量模式和热点流量模式下平均信息延迟的比较分析。图6(a)和(b)分别给出了两种流量模式下平均信息延迟的性能曲线。平均信息延迟是指信息从产生到最后一个微片到达目的节点本地IP核所用的平均时间。
实验参数设置:网络参数均设置为16节点二维mesh网络拓扑结构,采用XY维路由策略,信息长度为8微片。路由器端口数为5,静态路由器和动态缓冲路由器的虚通道数均设置为4。
图6(a)和(b)中的横坐标表示每个节点每个周期的信息注入率,纵坐标表示平均信息延时。结果表明在轻度负载到中度负载的情况下,静态路由器和动态缓冲路由器的信息延迟差别不大。但在高流量负载情况时,动态缓冲路由器结构的信息延时明显低于静态路由器。尤其在热点流量信息注入情况下平均信息延迟性能更好。

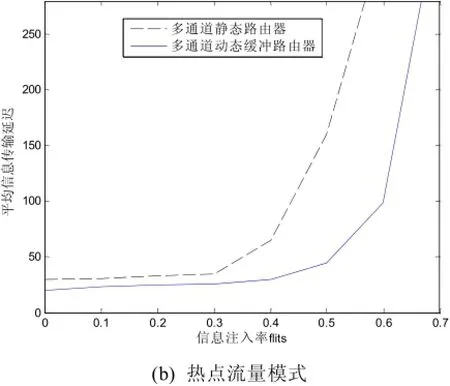
图6 两种流量模式下不同路由器平均信息延迟曲线
3 结束语
为了解决传统路由器缓冲资源相互独立,每个通道资源利用不充分或出现拥塞的情况下,本文设计了一种共享动态缓冲路由器结构。该路由器能根据每个通道运行时的通信率动态分配缓冲区,实现路由器中所有通道的缓存资源相互共享,降低信息传输拥塞状况。
实验结果表明,共享动态缓冲路由器结构对降低路由器内存开销,降低功率消耗和减少信息延迟等具有良好效果,有利于提高网络各方面性能。
[1] 高明伦, 杜高明. NoC: 下一代集成电路主流设计技术[J]. 微电子学, 2006, 36(4): 461-466.
[2] Dally W J, Towles B. Principles and practices of interconnection networks [M]. San Mateo, CA:Morgan Kaufmann, 2004.
[3] Duato J M, Yalamanchili S, Ni L. Interconnection Networks:An Engineering Approach[M].Morgan Kaufinann, 2002.
[4] 董少周. NoC路由算法及仿真模型的设计与研究[D].合肥:合肥工业大学, 2009.
[5] 赖明澈, 王志英, 郭建军等. 具有拥塞缓解策略的动态虚通道研究及其VLSI实现[J]. 计算机学报, 2008, 31(11):1~13.
[6] 朱红雷. 基于动态缓冲管理的片上网络体系结构研究[D]. 长沙:国防科学技术大学, 2010.
[7] Becker D U, et al. Adaptive Backpressure: Efficient buffer management for on-chip networks[C]//In Proceedings of the 30th IEEE International Conference on Computer Design, 2012.
[8] Hu P, Kleinrock L. An analytical model for wormhole routing with finite size input buffers[C]// 15th Intl. Teletraffic Congress, 1997.
Design of a Sharing Dynamic Buffer Router for Multiprocessor System-on-Chip
Wang Shaomin1, Liao Jiyang1, Jia Xiaoquan2, Dong Rui3, Liu Fen4
(1. Unit 92246 of PLA, Shanghai 92246, China; 2. Naval Representatives Office in 703 Research Institute, Harbin 150078, China; 3. Unit 91315 of PLA, Liaoning 116041, China; 4. Bengbu Naval Petty Officer Academy, Bengbu233012, AnHui,China)
In the multiprocessor system-on-chip, by analyzing of the router buffer allocation strategy and realizing the dynamically buffer allocation, the performances of embedded multi-core processor chip can be effectively improved. This paper designed a sharing dynamic buffer router for multiprocessor system-on-chip. The router can effectively distribute channel buffer resource and realize resources sharing. After the simulation and analysis on the static router and this designed router under the 16 node 2d-mesh network topology structure, the experimental results show that a sharing dynamic buffer router for multiprocessor system-on-chip have many advantages over static router such as low memory overhead, low energy consumption, low average information delay and so on.
multiprocessor system-on-chip; router; dynamic allocation; resources sharing
TN915.05
A
1003-4862(2016)12-0049-04
2016-08-01
汪少铭(1975.01-),男,机电业务长。研究方向:舰船动力装置。
