基于数据驱动的置换蒸煮卡伯值在线预测
2016-02-06党世红甘文涛杨鹏飞
党世红 汤 伟 甘文涛 杨鹏飞
(1.陕西科技大学轻工与能源学院,陕西西安,710021;2.咸阳职业技术学院机电学院,陕西咸阳,712000)
·卡伯值在线预测·

基于数据驱动的置换蒸煮卡伯值在线预测
党世红1,2汤 伟1甘文涛1杨鹏飞1
(1.陕西科技大学轻工与能源学院,陕西西安,710021;2.咸阳职业技术学院机电学院,陕西咸阳,712000)
针对置换蒸煮过程中卡伯值难以在线检测、引起操作延时、导致纸浆品质下降和能耗增大的问题,研究了基于数据驱动的置换蒸煮卡伯值在线预测方法。在分析置换蒸煮过程特点的基础上,提出了基于数据驱动的置换蒸煮卡伯值在线预测框架,给出了模式匹配的优化算法,设计了基于数据驱动的卡伯值在线预测模型。仿真结果和实际生产应用证明了该方法的有效性。
数据驱动;置换蒸煮;卡伯值;操作模式优化;模糊神经网络
置换蒸煮(Displacement Digester System,简称DDS)是间歇式蒸煮的最新成果。与常规间歇式蒸煮系统相比,DDS具有很多优点,如节能效果显著,汽耗降到500~700 kg/t浆;缩短总蒸煮时间30%~50%;能在125~130℃进行深度脱木素,提高了纸浆的强度和得率;保温段的用碱量只有传统间歇蒸煮的1/3;采用从下而上置换药液,使得蒸煮更均匀等[1]。置换蒸煮系统以其突出的节能效果、优良的产品质量、广泛的适应范围和显著的经济效益已成为当前制浆企业革新改造的方向标[2]。
纸浆卡伯值表示原料经蒸煮后所得纸浆中残留的木素和其他还原性有机物的量,间接地表示纸浆脱木素程度的大小。控制好纸浆的卡伯值,不但可以稳定纸浆质量、提高纸浆得率,而且有助于减少蒸汽和化学品的消耗,降低环境污染,提高经济效益及社会效益[3]。
国内外对常规间歇蒸煮系统的卡伯值预测研究较早,国外始于20世纪70年代,大多数采用经验模型或者半经验模型,如Chari模型、Hatton模型、Kerr模型等,这些经验模型虽然易于使用,并且在稳定的初始条件和生产情况下,对于国外特定的生产过程可以取得较好的预测效果,但是存在需要精确测量的物理量较多,对蒸煮初始条件要求严格,通用性差、应用范围小和局限条件多的缺陷。对于采用不同工艺条件、不同操作情况和不同生产原料、且影响因素更多的国内生产过程,直接套用国外的蒸煮模型往往难以取得较好的测量和预测效果。国内对纸浆卡伯值预测的研究始于20世纪80年代,华南理工大学制浆造纸工程国家重点实验室对常规间歇蒸煮的卡伯值做了大量研究,提出了卡伯值软测量模型并指导实际生产[4- 6]。
因置换蒸煮和常规间歇蒸煮有许多不同点,不能简单地把常规间歇蒸煮的卡伯值预测模型生搬硬套地用在置换蒸煮中,黄俊梅等人[7]针对置换蒸煮过程提出了基于RBF和BP神经网络的卡伯值软测量模型,因其对置换蒸煮的工艺特点考虑较少,故所建模型存在一定的误差。此外,以前所有的卡伯值预测模型的校验都是用离线数据进行比对,这样必然导致延时较大、测量不准确和误差较大的缺点。随着网络技术的快速发展和自动化水平的大幅提升,在蒸煮过程中积累了大量的工业运行数据,其中包含了丰富的反映生产运行规律和工艺参数之间关系的潜在信息,为生产过程优化控制提供了有利条件。为此,本课题在分析置换蒸煮特点的基础上,充分利用生产过程长期运行积累的工业数据,提出了基于数据驱动的置换蒸煮卡伯值在线预测的方法,并通过仿真和实践来证明该方法的有效性。
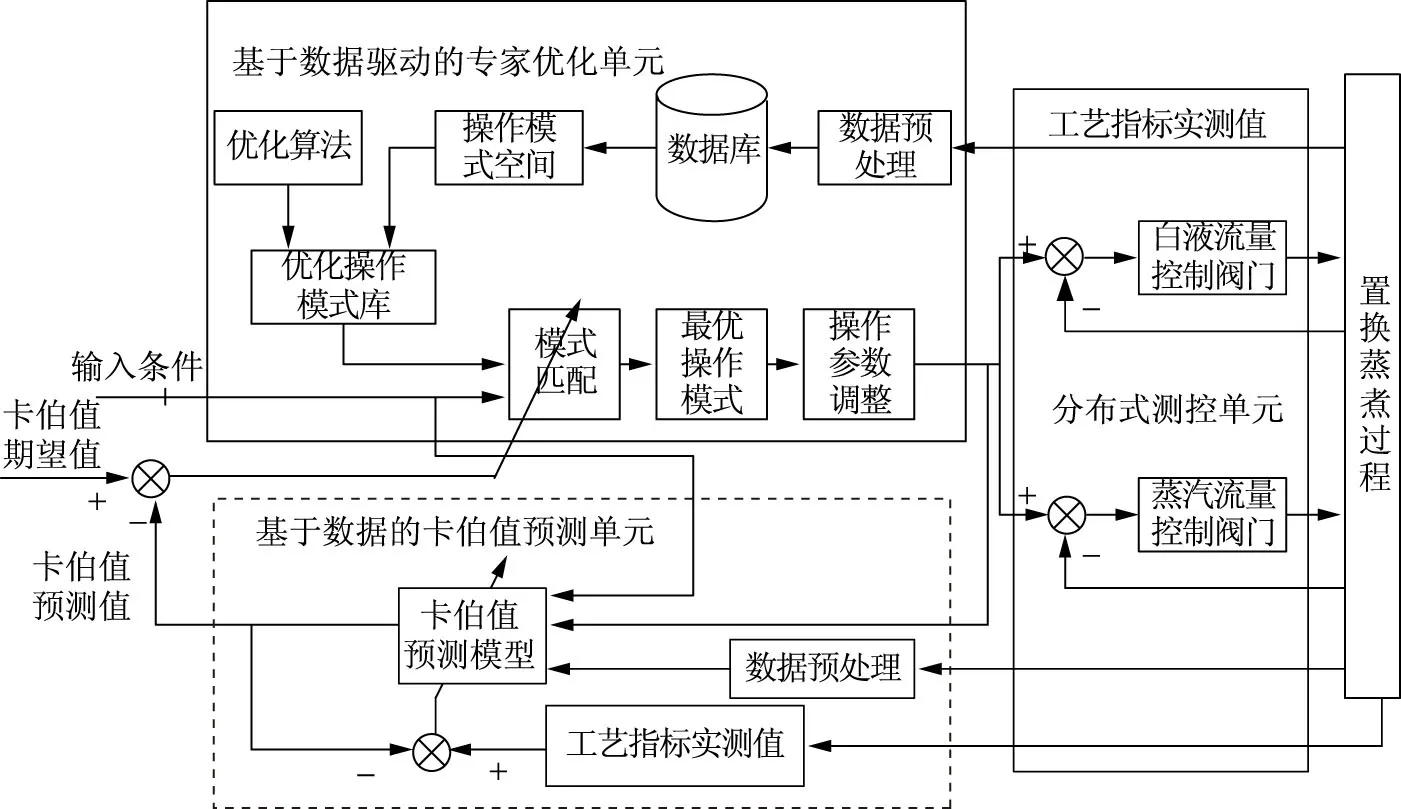
图1 基于数据驱动的置换蒸煮卡伯值在线预测的控制系统框图
1 基于数据驱动的置换蒸煮卡伯值在线预测的控制系统框图
基于数据驱动的置换蒸煮卡伯值在线预测的核心思想是:从实际置换蒸煮过程积累的大量工业运行数据中通过专家优化系统挖掘出优化操作模式库;依据当前的输入条件、工业运行状态和卡伯值的预测值从优化操作模式库中匹配出最优操作模式用于指导生产。基于数据驱动的置换蒸煮卡伯值在线预测的控制系统框图如图1所示,主要由基于数据驱动的专家优化单元、基于数据的卡伯值预测单元及分布式测控单元共3个单元组成。
基于数据驱动的专家优化单元由数据预处理、数据库、操作模式空间、优化算法、优化操作模式库、模式匹配、最优操作模式和操作参数调整等部分组成,主要功能是依据置换蒸煮过程中采集的实时数据,结合输入条件和卡伯值预测情况,通过专家系统的优化算法,进行模式匹配,产生最优操作模式,及时高效准确地指导生产。
基于数据的卡伯值预测单元主要功能是预报出准确的置换蒸煮卡伯值来指导生产。首先利用从置换蒸煮过程中采集到的实时数据(此处为硫化度、有效碱浓度和H因子),通过卡伯值预测模型求出预测值;接着将预测值与期望值比较,产生调节因子,在输入条件(指原料的种类、原料合格率和原料中杂质的含量等原始信息)和优化操作模式库的共同作用下,进行模式匹配,形成最优操作模式,调整操作参数,进而调节置换蒸煮过程中的工艺参数(如白液流量、蒸汽流量等),再次进入预测模型的输入端,如此周而复始,确保卡伯值的预测准确,最终达到稳定纸浆质量、提高纸浆得率、减少蒸汽和化学品的消耗、降低环境污染、增加经济效益的目的。
分布式测控单元是指分布在现场的控制柜和多个测控点。测控单元主要完成两大任务,一是给上位机(操作管理部分)提供实时的现场数据,二是依据上位机的指令进行相应的控制动作(如开、关阀门等)。
2 基于数据驱动的专家优化单元
应用专家优化方法进行模型匹配,首先必须获取置换蒸煮过程中专家的知识和经验。知识获取的工作主要包括以下3方面:①置换蒸煮过程中影响纸浆品质的工艺指标及其定性影响;②置换蒸煮过程中的历史数据和经验数据;③确定模式匹配的专家优化算法。
获取的知识表现为“If条件Then动作”的产生式规则,其中条件是过程的状态或者这些状态的逻辑组合,动作表示实际操作或者结论。
2.1 数据预处理
在置换蒸煮过程中,由于测量环境、测量仪器、测量方法、原料成分波动、外界干扰以及生产操作中人为主观因素等影响,采集到的原始测量数据不可避免地存在误差。如硫化度是对白液槽中的白液进行测量,而一个白液槽要供给几个蒸煮锅,存在误差;木片合格率每班测量2次,每班蒸煮5~6锅,测量使用的是网筛,误差较大。针对这些问题,一方面要加强管理,采用先进的测量仪器和方法;另一方面需要采用有效的数据预处理方法,去掉误差数据。
2.2 数据库
在置换蒸煮过程中,将多种工艺指标(如有效碱浓度、H因子、液比和木片合格率等)的实际测量值全部存放于数据库中。
2.3 操作模式空间
一定的输入条件(m维)及与之对应的操作参数(n维)所组成的m+n维向量定义为一个操作模式[8],即:
Q=[IT,PT]T=[i1,…,im,p1,…,pn]T
(1)
设Qj(j=1,2,…,k,…)为任一个操作模式,则由实际生产中所有可能出现的生产状况所对应的操作模式向量组成的空间Vm+n称为操作模式空间,即:
Vm+n=(Q1,Q2,…,Qk,…)
(2)
2.4 优化算法与优化操作模式库
综合考虑产品的产量、质量、能耗、成本和工况稳定情况等工艺指标,建立生产过程的综合评价模型,在专家系统优化算法的作用下,对相同输入条件下的操作模式进行评价,综合评价为最好的操作模式称为该输入条件下的优化操作模式;由不同输入条件下的优化操作模式组成的集合形成优化操作模式库。
2.5 最优操作模式匹配
置换蒸煮是一种特殊的间歇式蒸煮方式,整个工艺流程包括装锅、预浸、热充、升温保温、置换和卸料6个阶段,工艺指标之间往往相互影响,为了保证工艺指标,需要对各个操作参数进行实时调整,最优操作模式匹配,就是针对实际的输入条件及状态参数,从优化操作模式库中搜索出与其最相似的操作模式,并针对各个操作参数的特点,研究相关控制作用之间的关系和策略,以保证置换蒸煮系统的纸浆品质最优。
图1中的优化操作模式库中保存有大量的不同输入条件及工况参数情况下的优化操作模式,事实上相当于保存了历史上大量的优化操作专家经验。其基本思想是,利用一种智能的搜索策略,从优化操作模式库中搜索与当前工况最相似的操作模式,将其操作参数作为最优操作模式输出。但是,由于优化操作模式库中数据量很大,为提高搜索速度,采用聚类算法将优化样本空间范围缩小,然后进行模式匹配。
采用模糊c均值聚类模式匹配算法进行智能优化的具体步骤如下。
(1)Step 1建立样本库
建立置换蒸煮过程优化操作数据库,用于保存历史上典型工况下的优化操作数据。数据库中的个体样本主要由两部分构成:用于样本聚类的数据,包括木片的种类、木片的含水量、木片中杂质的含量、木片合格率、液比等;用于优化操作的数据,包括有效碱浓度、硫化度、蒸煮的温度和时间等,这些数据可以反映出在与当前工况类似的条件下专家的操作经验。当前采集获得的现场数据样本X0包含同样的内容。
(2)Step 2模糊聚类
采用模糊c均值聚类方法对优化操作数据库中的样本进行聚类,如果有新的优化操作样本加入则需要重新对样本进行聚类。聚类根据样本中木片的种类、木片的含水量、木片中杂质的含量、木片合格率、液比进行。聚类后优化操作样本分为10大类,第i类的类中心为Ci。当前工况样本与类中心之间的相似性用相似系数表示。
(3)
式中,xi、xj为两个样本,P为样本中用于聚类的元素个数。如果样本中所有元素取正数,则0 (3)Step 3判断当前工况所属类 计算现场数据样本与10个聚类类中心的相似系数,选择相似系数最大的类,作为当前工况所属的类。 (4)Step 4模式匹配 在当前类中计算现场样本与类中各个样本的相似系数,选择10个相似系数最大的样本,作为与当前工况最接近的样本。 (5)Step 5 优化算法的初始值 分别计算这10个样本的综合工况指数S,将S值最小的样本作为优良样本,将其作为操作参数优化的初始值。 (6)Step 6优化算法的输出值 将Step 5获得的优良样本作为初始值,然后采用GARPSO算法进行优化,获得优化结果,最后进行操作参数的调整。 3.1 置换蒸煮卡伯值的影响因素 置换蒸煮的卡伯值受H因子、有效碱浓度、硫化度、液比、木片合格率以及其他一些因素的影响[9]。其中的H因子、有效碱浓度、硫化度3个参量直接影响脱木素化学反应的速度和程度,对蒸煮终点卡伯值的大小起着决定性作用,其他量的影响可以忽略。 设纸浆卡伯值为因变量Y,有效碱浓度、硫化度、H因子分别为X1、X2、Xn,忽略次要影响因素,则纸浆卡伯值的数学函数为:Y=f(X1,X2,Xn)。 图2 卡伯值预测模型的结构 3.2 卡伯值预测模型 神经网络和模糊系统均是处理不确定性、非线性问题的有力工具。模糊系统中知识的抽取和表达比较方便,但是缺乏自学习和自适应能力,而神经网络则可以直接从样本中进行有效的学习,但一般不适于表达基于规则的知识。基于上述分析,将模糊逻辑与神经网络适当地结合起来,吸取两者的长处,则可组成性能良好的模糊神经网络。 由图2可知,该预测模型由前件网络和后件网络两部分组成,前件网络用来匹配模糊规则的前件,后件网络用来产生模糊规则的后件。 3.2.1 前件网络 前件网络由4层组成。第一层为输入层。它的每个节点直接与输入向量的各分量xi连接,它起着将输入值x=[x1x2x3…xn]T传送到下一层的作用。因为有H因子、有效碱浓度、硫化度3个输入量,所以这里的n=3。 (4) 式中,i=1,2,…,n;j=1,2,…,mi。n是输入向量中所包含变量的个数,mi是每一个变量xi的模糊分割数。 第三层的每个节点都代表一条模糊规则,用来匹配模糊规则的前件,计算出每条规则的适应度,即: (5) 第四层的节点总数与第三层相同,都为m。作用是实现归一化计算,即: (6) 3.2.2 后件网络 后件网络由3层节点构成。第一层是输入层,将输入变量传送到第二层。输入层中第0个节点的输入值x0=1,其作用是提供模糊规则后件中的常数项。第二层共有m个节点(本设计中取m=7),每个节点代表一条规则,该层的作用是计算每一条规则的后件,即: (7) 第三层是输出层,只有一个节点,其输出结果为: (8) 3.2.3 网络的学习算法 首先定义误差函数为: E=(t-y)2 (9) 式中,t表示网络的期望输出值,y为网络的实际输出值。需要学习的参数主要是后件网络的连接权pjl,以及前件网络第二层各节点隶属度函数的中心值cji及宽度σji。 参数pjl学习的算法公式为: (i=1,2,…,n; j=1,2,…,m) (10) 参数cji和σji的学习算法公式为: (11) (12) 3.2.4 模型的训练 在MATLAB的主命令窗口中输入“anfisedit”命令,就可以打开AnfisEditor编辑器,其界面如图3所示。 图3 Anfis Editor编辑器界面 本文将从四川某竹浆厂置换蒸煮车间采集的数据经过预处理和归一化后,直接导入MATLAB的workspace中,从样本数据中选择安装序号,每隔10组取一组出来作为检验数据,组成一个拥有20组数据的集合作为检验数据,剩下的180组数据作为训练数据。经过数据导入和数据加载,在AnfisEditor窗口的TrainFIS区域中对数据进行训练,训练完成后,在AnfisEditor窗口的TestFIS区域对系统进行测试。对系统测试时,选择训练数据与系统输出进行对比,对比结果如图4所示。 通过对比可以看出,网络的输出和实际的样本值之间的误差很小(平均误差约为0.04),预测值能准确地反映实际值。 图4 训练样本预测效果图 基于数据驱动的置换蒸煮卡伯值在线预测系统已经成功应用于四川某竹浆厂置换蒸煮系统中,图5为置换蒸煮系统卡伯值实际值与预测值的对比图,图6为生产中的预测系统界面。由图5、图6可以看出,基于数据驱动的置换蒸煮卡伯值在线预测系统较好地实现了置换蒸煮系统卡伯值的在线预测,预测结果较准确,预测精度满足实际要求。 图5 置换蒸煮系统卡伯值实际值与预测值的对比图 图6 置换蒸煮卡伯值预测系统界面 本课题分析了置换蒸煮过程的特点,针对置换蒸煮过程卡伯值无法在线测量的问题,提出了基于数据驱动的置换蒸煮卡伯值在线预测方法,给出了总体控制框图,说明了控制框图中各个组成单元的结构和作用,设计了基于数据的卡伯值在线预测模型,仿真结果和工业实际应用效果均表明该方法的有效性。随着“德国工业4.0”和“中国制造2025”的提出,基于数据驱动的置换蒸煮卡伯值在线预测方法必将不断改进,具有广阔的应用前景。 [1]SHISheng-tao,JIANGQing-sheng,JIANGYan-li.TheFeaturesofDDSCookingSystem[J].ChinaPulp&Paper, 2011, 30(9): 44. 时圣涛, 江庆生, 姜艳丽.DDS间歇置换蒸煮的特色[J]. 中国造纸, 2011, 30(9): 44. [2]CHENBin.CurrentStatusandDevelopmentofBambooPulping&PapermakingTechnology[J].ChinaPulp&Paper, 2010, 29(12): 62. 陈 彬. 竹材制浆技术发展现状[J]. 中国造纸, 2010, 29(12): 62. [3]LIUHuan-bin.TheoryandTechnologyofSoft-measurementforPulpCharacters[M].Beijing:ChinaLightIndustryPress, 2009. 刘焕彬. 纸浆性质软测量原理与技术[M]. 北京: 中国轻工业出版社, 2009. [4]ShanHong-liang,WangWen-hai,SunYou-xian.Summarizationofsoftmeasurementmodelingonbatchcookingprocess[J].TransactionsofChinaPulpandPaper, 2003, 18(2): 195. 单鸿亮, 王文海, 孙优贤. 间歇蒸煮过程软测量建模综述[J]. 中国造纸学报, 2003, 18(2): 195. [5]LiYan,ZhangJian,ZhuXue-feng,etal.NewDevelopmentandApplicationofSoftSensingMethodsofKappaNummber[J].ChinaPulp&Paper, 2003, 22(7): 41. 李 艳, 张 建, 朱学峰, 等. 纸浆卡伯值软测量模型的研究与应用[J]. 中国造纸, 2003, 22(7): 41. [6]ZHANGJian.ResearchonimprovingtheaccuracyofSoftSensorforKappaNumberEstimationinPulpCookingProcess[D].Guangzhou:SouthChinaUniversityofTechnology, 2004. 张 健. 提高制浆蒸煮过程纸浆卡伯值软测量精度的研究[D]. 广州: 华南理工大学, 2004. [7]HuangJun-mei,TangWei,XuBao-hua,etal.KappaNumberPredictionModelofCookingProcessBasedonBPNeuralNetwork[J].ControlandInstrumentsinChemicalIndustry, 2010, 37(11): 34. 黄俊梅, 汤 伟, 许保华, 等. 基于BP神经网络的蒸煮卡伯值预测模型[J]. 化工自动化及仪表, 2010, 37(11): 34. [8]WUTie-bin,YANGChun-hua,LIYong-gang,etal.FuzzyOperational-patternBasedOperatingParametersCollaborativeOptimizationofCobaltRemovalProcesswithArsenicSalt[J].ActaAutomaticaSinica, 2014, 40(8): 1690. 伍铁斌, 阳春华, 李勇刚, 等. 基于模糊操作模式的砷盐除钴过程操作参数协同优化[J]. 自动化学报, 2014, 40(8): 1690. [9]TANGWei,GANWen-tao,DANGShi-hong,etal.TheRealizationofOPCBasedKappaNumberSoftMeasurement[J].ChinaPulp&Paper, 2015, 34(2): 45. 汤 伟, 甘文涛, 党世红, 等. 基于OPC技术卡伯值软测量的实现[J]. 中国造纸, 2015, 34(2): 45.CPP (责任编辑:刘振华) Displacement Cooking Kappa Value Online Prediction Based on Data-driven DANG Shi-hong1,2,*TANG Wei1GAN Wen-tao1YANG Peng-fei1 (1.CollegeofLightIndustryandEnergy,ShaanxiUniversityofScience&Technology,Xi’an,ShaanxiProvince, 710021;2.ElectromechanicalInstitute,XianyangVocational&TechnicalCollege,Xianyang,ShaanxiProvince, 712000)(*E-mail: dangshihong@163.com) Aiming to the difficulty of Kappa value online measurement in displacement cooking, this paper proposed a data-driven method to online predict Kappa value in displacement cooking. Based on the analysis of the features of displacement cooking process, an online prediction frame of Kappa value in displacement cooking based on data-driven was proposed, a pattern-matching optimization calculation was presented and a model of data-driven Kappa value online prediction was designed. The results of simulation and production application confirmed the effectiveness of the method. data-driven; displacement cooking; Kappa value; optimization of operation mode; fuzzy neural network 2016- 05-23(修改稿) 国家国际科技合作项目(2010DFB43660);陕西省科技厅国际科技合作项目(2011KW-11(2));咸阳市科技研究项目(2014k03- 05)。 党世红先生,在读博士研究生;研究方向:工业自动化与智能控制。 TP27;TS736 A 10.11980/j.issn.0254- 508X.2016.12.0073 基于数据的卡伯值预测单元




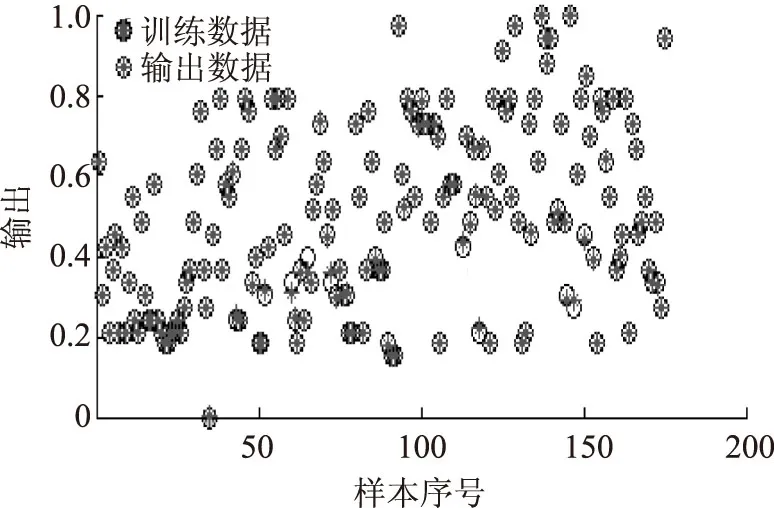
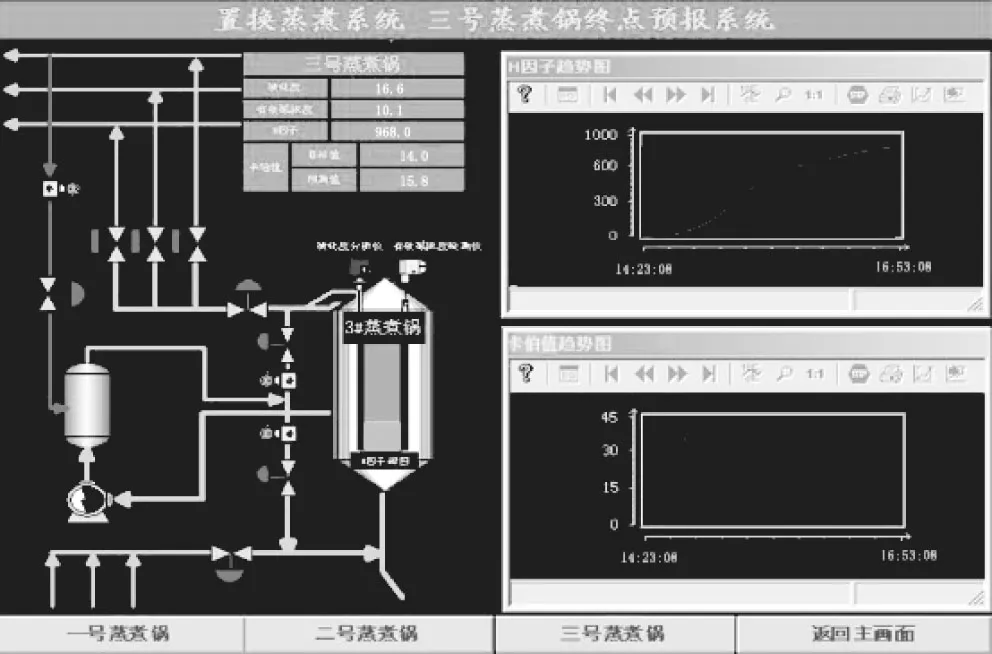
4 工业应用

5 结 语
