基于朴素贝叶斯网络的上市公司信用风险预警研究
2016-01-25傅祺炜
汪 敏 傅祺炜
基于朴素贝叶斯网络的上市公司信用风险预警研究
汪敏傅祺炜
傅祺炜(1991-),女,汉,江西吉安人,硕士研究生,研究方向:公司理财。
摘要:本文运用PCA方法提取出对信用风险具有显著影响的特征指标,同时运用EP-T方法离散样本数据并学习贝叶斯网络的结构与参数,以此建立朴素贝叶斯网络(Naive Bayesian Network,NB)信用风险预警模型;最后通过交叉验证(Cross Validation)对模型进行5次独立建模测试,并利用性能评价指标将NB模型与Logistic模型、MLP神经网络模型、RBF神经网络模型进行对比分析。实证研究结果表明,尽管四种模型均能对上市公司信用风险进行预警,但NB模型表现出了更好的预测精度与稳定性。
关键词:信用风险;NB模型;PCA;EP-T方法;交叉验证
引言
现代市场经济是建立在信用基础上的信用经济,如何提高信用风险预测精度、强化信用风险识别能力,越来越受到各国监管部门的重视。而上市公司作为我国经济发展的核心力量,一旦发生信用违约,不但会损害投资者的利益,而且会进一步降低信用评级,从而增加融资成本、限制融资渠道,严重的会使公司陷入破产的境地。因此,构建科学有效地信用风险预警模型对促进我国经济的健康发展具有重要的理论意义与实践意义。
而贝叶斯网络(Bayesian Network,BN)模型以贝叶斯理论为基础,不仅能更好地结合先验信息与样本信息,而且能挖掘数据间的因果关系,因而被广泛运用于信用风险预警中。其中,朴素贝叶斯网络(Naive Bayesian Network,NB)模型,因其网络结构的简易性以及在相关领域中的优秀表现受到了学者的广泛关注。鉴于此,本文将NB模型运用于上市公司信用风险预警研究。
一、上市公司信用风险预警方法的构建
(一)构建上市公司信用风险预警模型

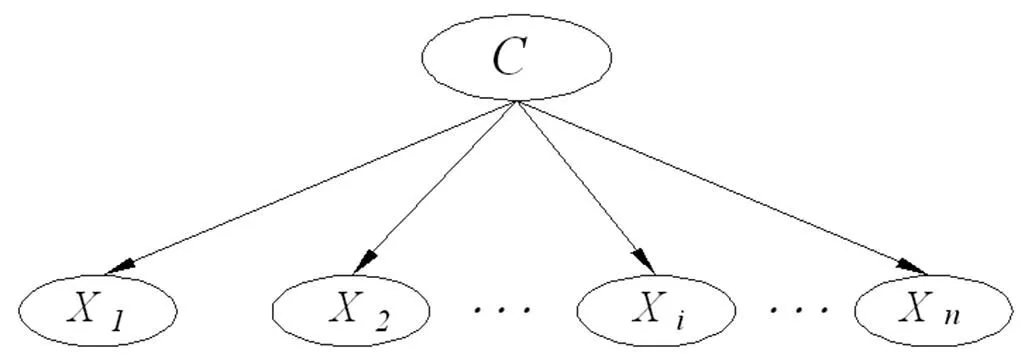
图1 朴素贝叶斯网络模型
而在NB模型中,节点变量之间的参数学习即为学习各节点的条件概率,从而构成条件概率表CPT。根据贝叶斯规则,计算有关属性节点所对应的父节点出现的概率就归结为实现最大后验概率(Maximum A Posterior,MAP),即求:
(1)
其中P(x1,x2,…,xn)是常量,因此,本文要判断上市公司是否发生信用风险,只需要根据训练集D1学习信用风险特征指标所代表的属性变量的条件概率P(xi|cm),(i=1,2,…,n)与先验概率P(cm),即可得到网络参数。
二、实证结果与分析
(一)样本选取
本文数据主要来源于CSMAR数据库。研究的样本数据为从2000年到2013年间我国A股市场因财务状况异常而被特别处理(ST)的157家上市公司作为作为信用风险样本和与其配对的789家财务正常公司作为非信用风险样本,总共946家公司作为研究样本。
(二)特征指标选取与筛选
鉴于以往的研究成果,本文选取样本第(t-2) 年而不是第(t-1)年的财务指标数据,且第(t-2)年时该ST公司并非处于ST状态作为研究依据[6,7]。基于此,初步选取了反映企业盈利能力、偿债能力和营运能力等6个类别共16个财务指标作为建模的备选指标,见表1。
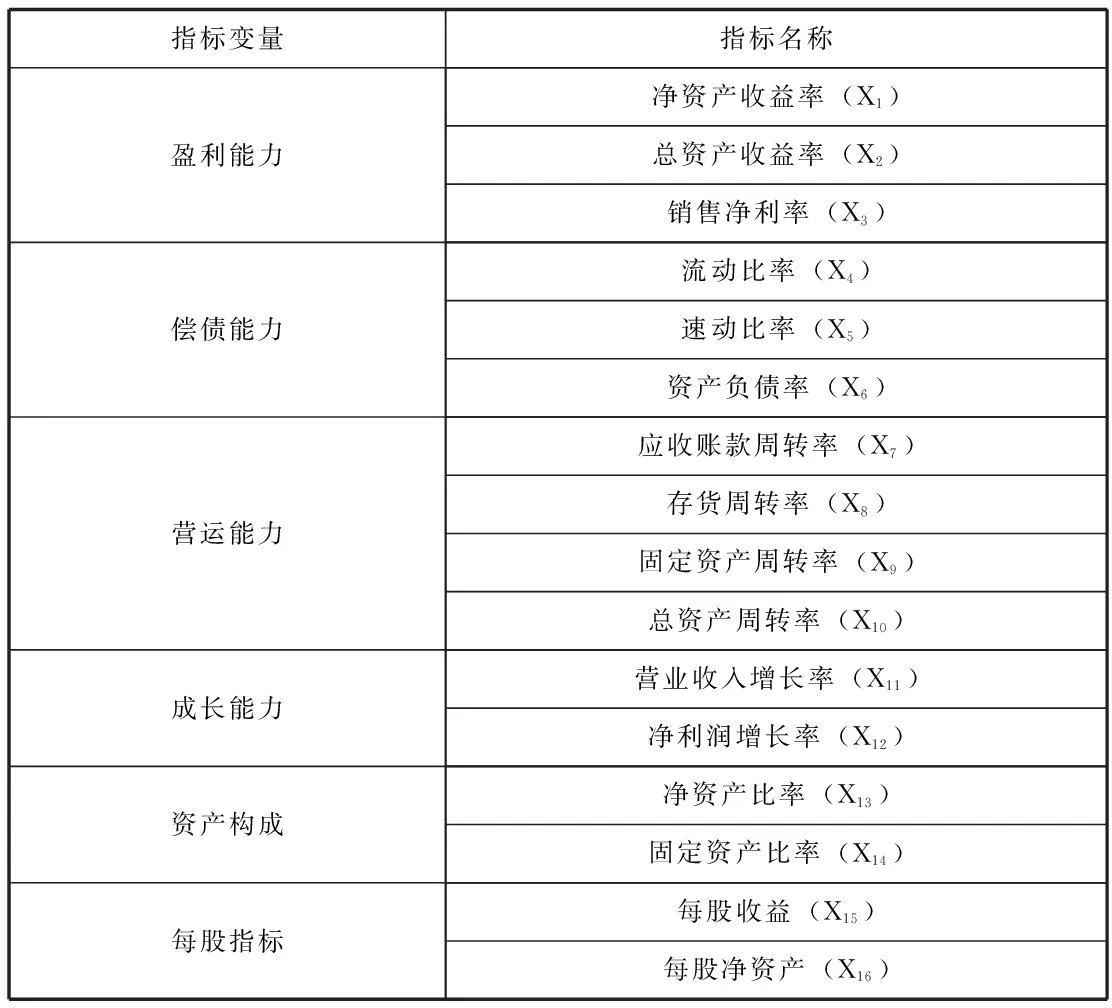
表1 待筛选预警指标变量
由表1可以看出,本文所选取的预警指标包含6个类别,每个类别都包含多个备选财务指标,考虑到财务指标之间存在高度相关性,还将运用PCA方法对备选指标进行筛选,从而降低甚至消除指标变量间的多重共线性影响。
由表2的KMO统计量和Bartlett球形检验结果看出,本文研究样本的KMO统计量为0.578>0.5,显著性水平P=0.000<0.05,说明运用PCA方法是合适的。
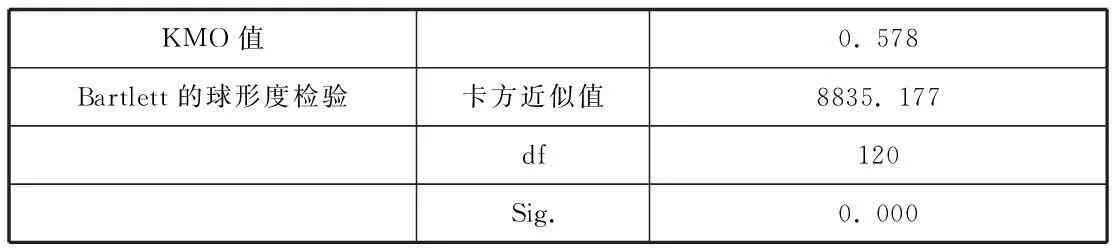
表2 KMO统计量检验和Bartlett球形检验
根据各指标的贡献率,并依据特征值大于1的原则,本文利用PCA方法提取出7个因子,其累计贡献率为85.923%,大于80%,说明所提取出的7个因子能够比较全面地反映上市公司的全部信息。最后,根据载荷因子矩阵,得到7个因子分别为净资产收益率(X1)、总资产收益率(X2)、资产负债率(X6)、总资产周转率(X10)、净资产比率(X12)、固定资产比率(X14)和每股收益(X15)。
(三)基于朴素贝叶斯网络的信用风险预警模型的确定
由于贝叶斯网络主要用来处理离散数据,而定量财务指标几乎全部为连续取值属性,鉴于多数财务指标表现出“尖峰后尾”的特点,本文采用更能捕捉这种分布特点的EP-T(Extended Pearson-Tukey)方法对筛选出的7个连续预警指标进行离散化处理。然后,模型的参数学习就可以利用网络结构并结合训练样本数据学习获得,具体结果见表3。
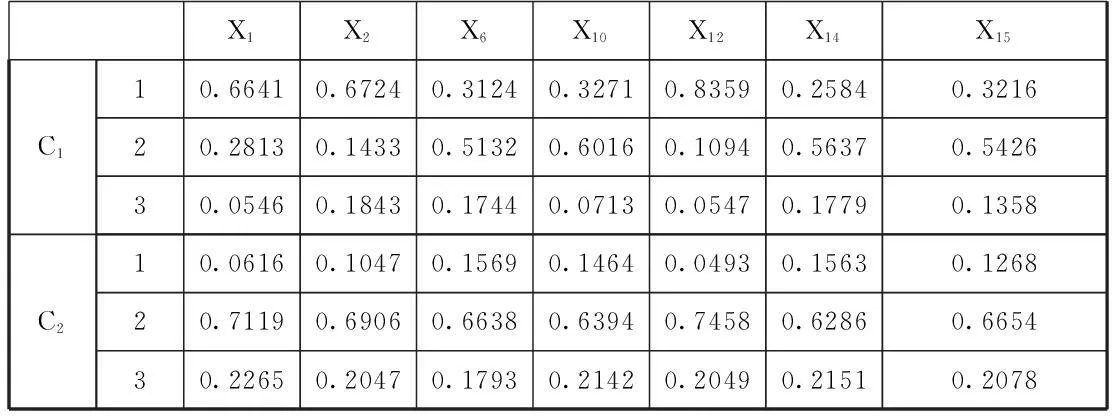
表3 条件概率表
(四)模型预测效果分析
为了增强实证研究的稳健性,本文采用交叉验证,分5次从信用风险样本和非信用风险样本中各抽取30家和140家公司组成测试样本,同时将余下的776家公司作为训练样本。利用训练样本分别建立NB模型、Logistic模型、MLP神经网络模型和RBF神经网络模型,并利用测试样本对各模型的性能评价指标进行对比分析,结果如表4所示。

表4 上市公司信用风险预警模型分类准确率
由表4可以看出,四种模型的平均整体预测分类准确率Pall都在80%以上,说明四种模型都具有较好的分类效果,但是对比而言,NB模型分类准确率相对较高,达到了91.88%;而从错误分类来看,四种模型发生第一类错误比率Perror1都相对较低,而发生第二类错误比率Perror2都相对较高,但NB模型发生两类错误比率都是最低的,尤其是发生第一类错误的比率只有2.66%。
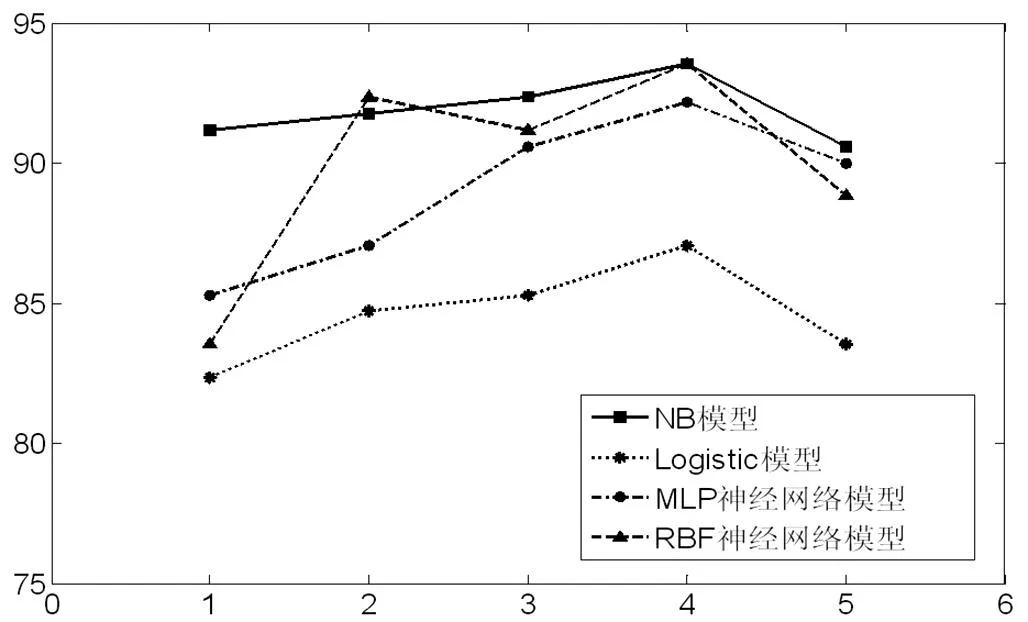
图2 四种模型的整体预测分类准确率Pall对比折线图
进一步地,从图2可以直观地看出,Logistic模型整体预测分类准确率相对较低,说明Logistic模型对信用风险的预测精度相对于其他三种模型而言较低;而将NB模型与MLP神经网络模型以及RBF神经网络模型对比发现,两种神经网络模型波动幅度都比NB模型大,尤其是RBF神经网络模型的波动幅度最大,说明神经网络模型对信用风险测度缺乏一定的稳定性。通过以上对比发现,尽管四种模型均能对上市公司的信用风险进行研究,NB模型则表现出了更高的分类准确率和稳定性。
三、结论
就整体上而言,NB模型更能够对类似信用风险这样的具有复杂非线性关系的风险管理问题进行有效预警,具有很高的实用价值。对于投资者而言,能够运用NB模型提前捕捉风险信号,进而作出合理的投资决策以规避风险带来的损失;对于相关的政府经济管理者而言,能够运用NB模型对可能发生风险问题的领域进行预测,及时制定合理的监管政策,从而稳定市场秩序,促进经济的持续健康发展。(作者单位:成都理工大学商学院)
参考文献:
[1]张鹏,曹阳.上市公司信用风险度量研究[J].财经问题研究,2012,(3):66-71
[2]Pearl J.Probabilistic reasoning in intelligent system:networks of plausible inference[J].California:Morgan Kaufman,1988,(3):383-408
[3]Heckerman D.Bayesian networks for data mining [J].Data Mining and Knowledge Discovery, 1997,(1):79-119
[4]Friedman N, Geiger D.Bayesian network classifier[J].Machine Learning,1997,(22):131-163
[5]石洪波,刘亚琴,等.贝叶斯分类器的判别式参数学习[J].计算机应用,2011,(4):1075-1078
[6]任永平,梅强.中小企业信用评级指标体系探讨[J].现代经济探讨,2001,(4):60-62
[7]刘国风.企业财务危机预警应确立的指标体体系[J].商业研究,2009,(3):153-156
[8]刘淑莲,王真,等.基于因子分析的上市公司信用评级应用研究[J].财经问题研究,2008,(7):53-60
[9]Keefer, D.L., Bodily, S.E.-Point Approximations for Continuous Random Variables [J].Management Science, 1983,(29):595-609
作者简介:汪敏(1990-),女,汉,安徽六安人,硕士研究生,研究方向:公司理财。
