基于MapReduce海量视频数据并行计算系统的设计
2016-01-19李虎俊张天凡
李 哲,李虎俊,张天凡
(1.湖北工程学院 新技术学院,湖北 孝感 432000; 2. 湖北职业技术学院 继续教育学院,湖北 孝感 432000;
3.西北工业大学 自动化学院,陕西 西安 710072)
基于MapReduce海量视频数据并行计算系统的设计
李哲1,3,李虎俊2,张天凡1,3
(1.湖北工程学院 新技术学院,湖北 孝感 432000; 2. 湖北职业技术学院 继续教育学院,湖北 孝感 432000;
3.西北工业大学 自动化学院,陕西 西安 710072)
摘要:在总结视频图像数据处理现状的基础上,针对海量视频数据的并行化处理问题,提出一种基于MapReduce的并行计算系统设计方法。该系统使用NVIDIA JETSON TK1搭建并行计算集群,在此基础上利用Hadoop实现了MapReduce。 在此平台上设计基于CUDA的并行数据处理算法对千万条文本数据进行处理,分析了其数据装载时间、处理时间和全部任务处理时间。结果表明,该系统当前加速比约为4.73,与C/S单机相比,处理速度有较大程度的提高,为实现实时海量视频图像处理奠定了良好基础。
关键词:并行计算;海量视频数据;MapReduce;Hadoop
中图分类号:TP311.11
文献标志码:码:A
文章编号:号:2095-4824(2015)06-0026-06
收稿日期:2015-09-17
基金项目:湖北工程学院自然科学基金(2013016,201515);湖北工程学院新技术学院自然科学基金(Hgxky14);湖
作者简介:李哲(1986-),男,湖北汉川人,湖北工程学院新技术学院讲师,博士研究生。
Abstract:On the summary of the status of video image processing, this paper proposes a parallel processing method for the parallel processing of massive video data which is based on parallel processing system by using the MapReduce technique. This system utilizes the NVIDIA JETSON TK1 to build parallel computation clusters and employs the Hadoop to perform the MapReduce. With the developed platform, a CUDA based parallel processing algorithm is designed to process tens of millions of text data for the analysis of the data loading time, the processing time of each task and the processing time of all tasks. The test results indicate that the acceleration rate of the system is about 4.73, which is much higher than the C/S mode in a single computer and offers a good foundation for the implementation of real-time massive video data processing.
当今,世界范围的信息化变革几乎使每个行业都面临着大数据(Big Data)问题[1]。大数据及其应用也一直是学术界关注的热点问题。由于大数据具有体量大、速度快和异构性的特点,给数据的存储、管理和分析带来了巨大挑战。特别在处理视频图像等非结构化数据方面上述问题尤为突出。因此,如何处理好视频图像数据对于大数据应用具有相当重要的意义。
1视频图像数据处理的现状分析
(1)数据存储密度不强,图像压缩算法适用性低。由于图像和视频属于非结构化数据,因此无法采用类似结构化数据的方法进行压缩。特别是视频数据带有时间三维结构,在某些应用必须保证足够的数据有效性[2]。如视频监控数据必须保证足够的清晰度,以便后期对监控内容和细节信息(如车牌号、人物特征等)进行追踪挖掘。因此,如何在保证足够清晰度及时间维度的前提下,高效存储海量视频数据一直是人们的研究热点。尽管出现了MPEG等动态图像压缩算法,但面对如“天网”工程所涉及的公共安全视频数据而言,常规的数据压缩算法仍存在明显不足。
(2)数据运算量巨大,常规CPU计算不足。图像视频数据量巨大,常规CPU面向的是通用性任务处理[3],其在处理图像视频这样密集性浮点运算时表现远不如GPU。根据文献[1]的分析表明,早在2012年,GPU的计算能力已经达到了3 gigaFLOPS,远远超出CPU的计算能力。因此,当前及未来图像数据处理的发展向着CPU-GPU混合计算方向发展。CPU与GPU计算能力的发展如图1所示。
(3)常规系统建设成本高,功耗大,使用率低。虽然如美国橡树岭实验室的“泰坦”以及我国的“天河二号”是世界最强超级计算机的代表,具有
北省公安厅自主科研项目(鄂公传发【2015】70号)
李虎俊(1958-),男,湖北汉川人,湖北职业技术学院继续教育学院副教授。
张天凡(1982-),男,湖北孝感人,湖北工程学院新技术学院讲师,博士研究生。
无与伦比的运算能力,能够满足海量数据的处理要求,但是这类超算系统往往建造成本巨大(仅“泰坦”二期升级就花费了9 000万美元),而且功耗巨大(“泰坦”全速运转功耗约为900 MW)[4],一般企业及个人用户不太可能承受如此高昂的建造和运行成本。

图1 CPU&&GPU计算能力发展
针对典型视频格式主要有三种处理平台,分别是Intel的Quick Sync Video,ADM的APP和NVIDIA的CUDA。对这三个平台进行基础的性能测试,测试结果如表1所示。

表1 视频处理加速平台常规指标测试表
注:视频源规格:1080P、H.263、码率28 Mbps、文件大小3579 MB,目标格式MP4、H.264码率4 Mbps
根据对某市“天网工程”视频监控系统的详细调查,发现每天产生的数据峰值为33TB,按上述三个方案分别需要77套、106套和160套系统以并行方式处理才能满足实时处理的要求,而所需建造系统的成本分别为37、30、75万元,总功耗方面分别为12 kW.h、9 kW.h和27 kW.h。不难看出Intel和NVIDIA具有较明显的优势,但从实际中Intel的报价来看,其建造成本相比TK1系统要高出不少,这也是本项目选用NVIDIA JETSON TK1构建计算集群的重要原因。
根据以上问题,本文研究海量数据(图像/视频)的存储和管理,为后期研究基于视频的内容分析与挖掘建立相应的技术平台。其中并行计算模型系统软件部分选择MapReduce,具体计算框架为Hadoop,硬件部分选用NVIDIA JETSON TK1(ARM处理器+NVIDIA GPU)构建并行计算集群。最后,利用CUDA技术优化海量视频数据的压缩过程。经过测试,该系统与C/S单机处理相比,能明显提高海量数据的处理速度,为后期实现实时海量视频图像处理奠定了良好基础。
2MapReduce相关技术
2.1MapReduce并行计算模型
Google于2004年提出了MapReduce,用于在大规模计算机集群上处理海量数据的并行计算[5-6]。MapReduce是一种基于键/值对的数据模型,该模型将复杂的分布式计算归结为两个阶段:Map阶段和Reduce阶段。Map阶段通常在数据存放本地进行计算,然后将Map输出结果按键值映射到相应的Reduce 任务中。Reduce 阶段对Map 阶段结果汇总计算,从而得出最终计算结果。MapReduce 模型优势在于简单易用,灵活性高,独立于云数据库系统,且容错能力强[7]。MapReduce设计了分布式文件系统DFS(Distributed File System),将数据分割成特定大小的数据块,计算节点则处理距离其最近的数据块,从而能获得更高的数据可靠性和更快的数据访问速度。MapReduce典型应用流程图如图2所示。
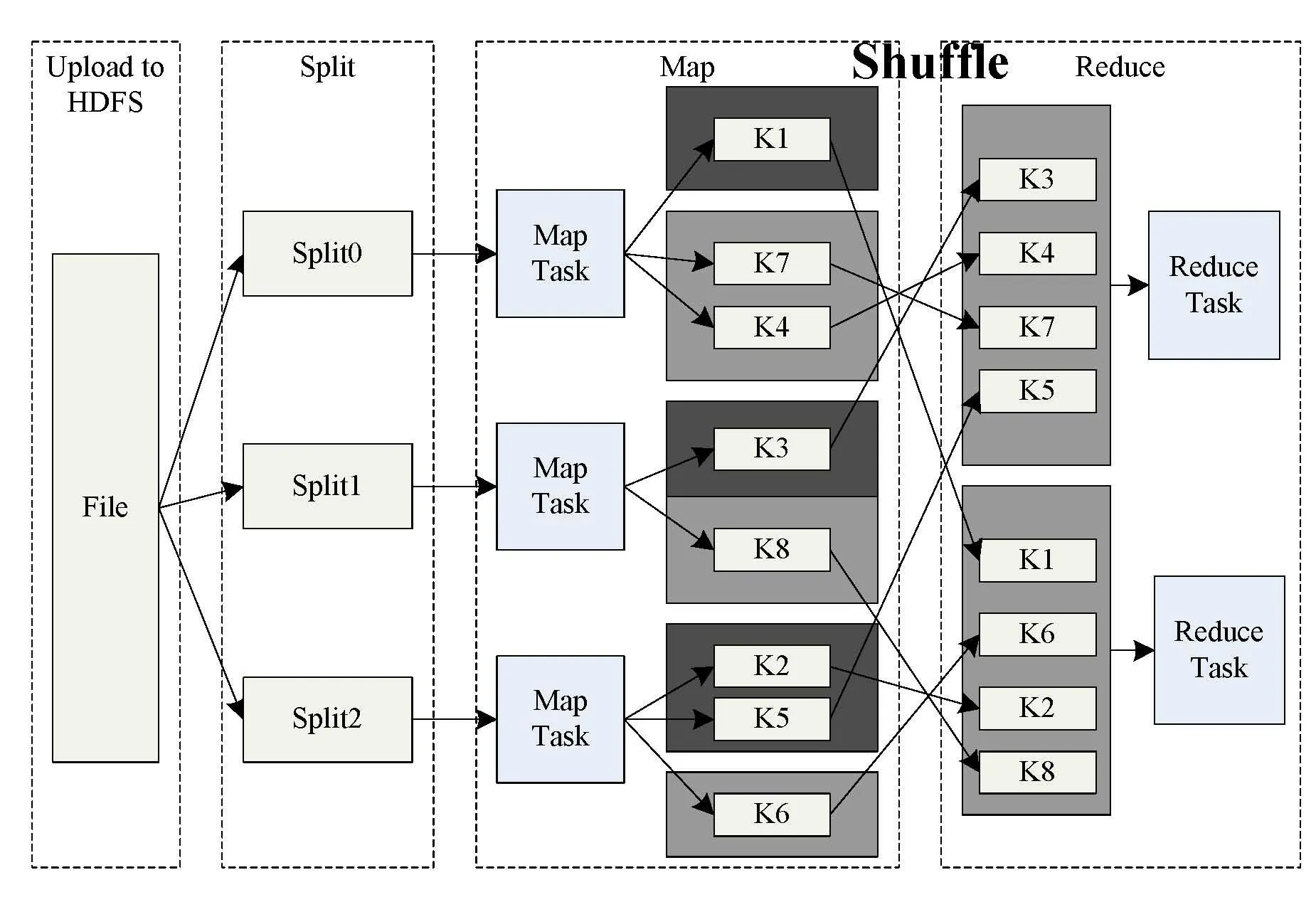
图2 典型的MapReduce应用流程图
2.2HDFS分布式存储系统
作为MapReduce的具体实现,Hadoop分别实现了分布式文件管理系统对应的Google文件系统(Google File System)、映射/规约模型、混合性大数据库系统。Hadoop的实现得到广大开源用户的支持,本系统选用了Hadoop作为MapReduce的具体实现。
尽管Hadoop实现了MapReduce,并且能够将数据和任务进行分布式部署,但分布后的任务与具体算法实现仍然需要程序员编写,因此需要在“微观“层面开发具体的数据处理程序。由于典型的处理程序要么是单线程的,要么利用多线程技术发挥多核CPU的运算能力。但面对如视频等数据密集型的非结构化数据处理,CPU的处理效率明显降低。在图像处理领域NVIDIA推出了统一计算设备架构(Compute Unified Device Architecture,CUDA),这是一种通用并行计算架构,该架构使得GPU能够解决类似图像处理等复杂的计算问题。因此在CUDA的基础上优化海量视频数据的压缩过程,能够有效应对海量视频数据的管理和压缩存储要求。
3系统设计
3.1系统框架设计
选用NVIDIA JETSON TK1搭建并行计算集群,系统硬件结构总体框架图如图3所示。

图3 系统硬件结构总体框架图
在系统硬件结构中,每个节点的核心TK1处理器部分包含四个ARM-A15内核,而GPU部分由192个CUDA组成,并且使用了与“泰坦”相同的“Kepler”超算架构。而单个TK1节点的零售价格仅为1600元,功耗低至10 W,完全满足系统设定的视频数据处理与分析的基本要求。多个节点配合监控主机和网络通讯设备构成并行计算集群,最终系统由两个子集群构成,每个集群拥有48个节点,其部署示意图如图4所示。

图4 “天网”工程双集群系统部署示意图
该系统能够有效地对视频任务进行处理,根据示范应用单位具体需求,该系统原型机已于2015年5月装配完毕,系统实物如图5所示。

图5 嵌入式并行计算系统“Medusa”原型机
为了对海量数据以及并行计算系统集群进行有效管理,该系统上选用了Google的MapReduce作为全局分布式任务管理框架,使用Hadoop的HDFS分布式文件管理系统实现海量数据的可靠存储,在该基础上编写了基于CUDA的并行数据处理算法,系统文件存储框架图如图6所示。

图6 基于HDFS的分布式数据存储框架图
3.2系统处理流程
对系统原型机基本功能进行测试,测试数据选用20 GB文本数据进行排序,排序过程在嵌入式系统上部署Hadoop的方式来进行处理。
首先,通过NameNode或者外部分发数据,将数据分发到各个处理单元。从逻辑上而言,采用从NameNode上传数据到虚拟的共享空间HDFS中;从物理上而言,实际的文件存储机器为Slave l~Slave N,namenode仅负责对整个HDFS逻辑空间的维护,并不参与存储。数据的分发存储如图7所示。

图7 数据分发存储
在数据分发过程中,将会产生两个方面的时间损耗。一是传输时间,另一个是将数据写入到每个Node的时间。但在传输的第一个时间周期过后,传输与数据写入是并行的,之后利用MapReduce框架对数据进行排序。
在Map端,结果文件优先存储在默认大小为100 MB的内存缓冲区,通过减少磁盘IO提高整体性能,直到该区溢出后才将溢出数据存放到磁盘中(见图9中双缓存机制是该机制的扩展)。当整个map过程完成后,缓冲区与磁盘中的所有临时文件将合并生成最终的结果文件,而reduce task则负责对这些以key-value形式组织的结果文件进行最终汇总。
每当缓冲区收集默认为100 MB的数据时,缓冲区的数据将会写入磁盘,然后重新利用这块缓冲区进行,这个过程被称为Spill(也叫做溢写)。该过程是一个新的线程,与原有的Map线程并行进行。默认的溢写阀值为0.8,即在默认配置下当缓冲区写入80 MB数据后,就由溢写线程将该组数据进行排序,而map task则继续使用剩余的空间。MapReduce提供了默认的排序算法,在后正理中本文将利用如Apriori算法和并行SON算法提高系统相关性能。
当Map端任务完成且将结果存放于Slave中指定的目录后,所有的reduce task将通过Job Tracker进行map task的完整性验证。如果完整,则执行merge文件合并过程,如果验证失败,则要求该Map将该任务分配给其他节点重新执行任务,直到所有任务完成。整个map-shuffer过程如图8所示。

图8 map shuffer过程
4系统测试及结果分析
4.1系统测试
(1)准备数据。原型机完成后使用千万条文本数据(约20 GB)进行全文分析。编写基于MapReduce框架下分布式数据处理程序。该程序的算法由RandomSelectMapper和RandomSelectReducer完成数据抽取,由ReudcerPatition完成数据划分,由SortMapper和SortReducer用于数据结果的输出。并行处理模型与基础模型最大的区别在于并行处理模型在接收数据的同时,就可以开始(在双缓冲数据处理功能支持下)排序(内部排序),其结构如图9所示。

图9 并行处理模型
由图9可以看出,将原有的B3、B4步骤去掉,转而将B2通过B3X直接链接到B5过程,那么B1~B3X~B6就构成一个新处理步骤,此部分速率关系为B3X=B5>B1>B6>B2,时间基准为B2,也可以得到该模型的整体时间公式为:
TD=B2+B9
(1)
根据数学模型定义式(1)可改写为:
(2)
(2)搭建嵌入式系统集群环境。当主机启动后,需在主机端使用start-all.sh命令开启hadoop分布式集群系统,当节点初始化完毕后,将逐个加入到主节点中监管,当有31个节点接入集群中时,主节点监管结果如图10所示。

图10 Hadoop Master Map/Reduce Administration
每个节点剩余外部存储空间映射到的Linux系统/usr/hadoop/tmp/dfs路径下,以分布式方式构成了56.26 GB的全局访问空间,如图11所示。
(3)任务运行监视。使用活动任务监视工具(Running Job)在主节点或监控终端的浏览器中查看当前任务执行的状态(在浏览器192.168.1.132:50070上运行Running Job),如图12所示。

图11 NameNode’Master.Hadoop:9000’

图12 主节点(Master)上查看任务执行状态
最后,当数据处理完毕后,从节点将退出处理过程并在监视终端中显示其执行结果,当Map-Reduce过程完毕后,分节点的结果数据将会汇总到主节点的output目下,如图13所示。

图13 从节点运行结果在主节点汇聚为一个结果文件
在图13中part-r-00000文件为最终结果汇总文件,而part-r-00001~00008文件是从节点文件,当数据汇总完成后从节点文件将清空,显示为0 Byte。
4.2结果分析
在C/S构架和Hadoop集群两种模型下测试,分别对三类测试数据进行测试,并通过比较数据装载时间、处理时间和全部任务处理时间进行性能分析,其中测试数据如表2所示。

表2 两类系统模型测试结果一览表
图14是数据装载时间、处理时间以及全部任务耗时对比结果。

图14 数据装载时间对比图
由图14的对比结果可知:
1)两种模式在数据传输上消耗的时间均比理想时间要多,其中C/S模型消耗的时间主要开销为网络带宽及传输控制协议的损失,而Hadoop集群在数据分割和任务分派方面消耗了较多时间;
2)在数据处理过程中,由于Hadoop采用的是并行结构,而C/S模型是单机四核四线程并行方式,Hadoop总体上要比C/S单机方式运行速度快,根据测试数据表2可得加速比如表3所示。采用Hadoop集群处理平均加速比约为4.73,与理论加速比为31/4=7.75仍有较大差距,这也是未来对算法进行改进的重要性能指标。
3)任务处理所占时间非常小,仅为整个任务处理的1%左右,因此将数据驻留在节点重复利用,可大幅度提高系统的运行效率。
4)在进行视频处理时,在任务级并行处理模式下无需将处理后的数据回传给监控主节点,从而减少数据回传给主节点造成的通信拥塞。

表3 C/S模型与Hadoop集群的加速比
5总结
本文详细阐述了组建基于MapReduce计算框架并通过Hadoop具体实现并行计算集群的过程,实现了HDFS有效将数据和数据程序分布到各节点进行处理并将处理结果反馈给主机并行处理算法,通过海量文本数据全文分析对该分布式处理模型的有效性进行了验证。结果表明,该系统加速比约为4.73,与单机处理方式相比,处理速度有较大程度的提高,为后期实现实时海量图像处理奠定了基础。
[参考文献]
[1]CCF 大数据专家委员会. 大数据热点问题与2013 年发展趋势分析[J].中国计算机学会通讯, 2012, 8(12): 40-44.
[2]于戈, 谷峪, 鲍玉斌, 等. 云计算环境下的大规模图数据处理技术[J].计算机学报, 2011, 34 (10): 1753-1767.
[3]孟小峰,余力.用社会化方法计算社会[J].中国计算机学会通讯, 2011, 7(12): 25-30.
[4]李哲,慕德俊,郭蓝天,等.嵌入式多处理器系统混合调度机制的研究[J].西北工业大学学报,2014,33(1):50-56.
[5]Lee K H, Lee Y J, Choi H, et al. Parallel data processing with MapReduce: a survey[C]//Proceedings of the ACM SIGMOD Record, 2012, 40(4): 11-20.
[6]肖韬.基于MapReduce的信息检索相关算法[D].南京:南京大学,2012.
[7]覃雄派, 王会举, 杜小勇, 等. 大数据分析——RDBMS 与 MapReduce 的竞争与共生[J].软件学报, 2012, 23(1): 32-45.
Research and Design of MapReduce Based Massive
Video Data Parallel Processing System
Li Zhe1,3,Li Hujun2,Zhang Tianfan1,3
(1.CollegeofTechnology,HubeiEngineeringUniversity,Xiaogan,Hubei432000,China;
2.SchoolofContinuingEducation,HubeiPolytechnicInstitute,Xiaogan,Hubei432000,China;
3.SchoolofAutomation,NorthwesternPolytechnicalUniversity,Xi'an,Shaanxi710072,China)
Key Words:parallel computing; massive video data; MapReduce; Hadoop
(责任编辑:张凯兵)
