基于协同过滤算法的个性化图书推荐系统的研究
2016-01-19孙彦超韩凤霞北京信息科技大学教务处机电实习中心北京100192
●孙彦超,韩凤霞(北京信息科技大学 .教务处;.机电实习中心,北京 100192)
基于协同过滤算法的个性化图书推荐系统的研究
●孙彦超a,韩凤霞b(北京信息科技大学a.教务处;b.机电实习中心,北京100192)
[关键词]协同过滤;最近邻居;推荐系统
[摘要]针对传统的协同过滤推荐算法不足之处,文中引入兴趣随时间迁移函数、用户和对象相关函数及用户特性集三个方面对协同过滤算法进行优化改进,在改进后的算法中使用用户兴趣随时间的变化函数来修正用户评价矩阵,在计算用户相似度时考虑了用户和对象兴趣度,在生成最近邻居时充分考虑了用户特性相似度对推荐结果的影响。以北京信息科技大学图书管理系统中数据集进行实验,通过实验结果表明,改进后的算法在推荐的准确度上有显著的提高。
1 个性化图书推荐系统及推荐算法
所谓个性化图书推荐系统,主要是利用读者历史借阅数据预测未来读者潜在的兴趣和爱好,进而有针对性地向其提供个性化的推荐图书服务。
目前,高校图书馆通常采用的推荐算法可以分三类[1]:(1)基于关联规则的推荐算法(Association Rule-based Recommendation);(2)基于内容的推荐算法(Content-based Recommendation);(3)协同过滤推荐算法(Collaborative Filtering Recommendation)。三类算法优缺点比较如下表所示。
在图书管理系统中,知识学习的驱动力、相似的知识结构及海量的高频借阅记录数据,使得图书管理系统中存在大量相似度较高的读者借阅信息,在这些借阅信息的基础上,基于关联规则推荐算法能够分析其中隐藏的关联规则,不足是规则抽取难度大、耗时长,个性化程度较低。由于图书管理系统中数据量大、数据类型复杂及学科覆盖面跨度大,容易造成基于内容的推荐算法在数据建模时很难全面地表示图书内容特征,从而造成推荐结果的质量较低,不能满足师生对图书推荐结果的准确性及实施性要求。协同过滤算法不需要对图书资源知识内涵进行深入分析,只需要对读者的特征及借阅记录进行分析,根据读者的特征分析其兴趣及个性化图书需求。该算法的优点是能够处理基于内容推荐算法难以分析的信息,如音频、视频信息;能够利用评价矩阵对结构复杂的对象进行高质量推荐。因此,协同过滤算法被主流推荐系统广泛采用。如亚马逊及当当网都采用了协同过滤的技术来提高个性化推荐服务质量。该算法的缺点是推荐系统运行初期,采集到用户的评价信息相对有限,以此产生的稀疏评价矩阵生成的最近邻居可能不够准确。同时,该算法忽略了用户对被推荐对象的兴趣度,只考虑用户的评价数据,也就是说算法只关注用户及对象二维,忽略了其他纬度,如时间纬度等。[1]

表 三类推荐算法的比较
2 改进前的协同过滤算法
协同过滤算法的算法思想是采集用户信息,包括用户基本信息、借阅信息及评价信息,利用采集到的信息生成用户评价矩阵,使用评价矩阵计算用户相似度,生成被推荐用户的最近邻居集,根据最近邻居评价信息提供推荐服务。[2]协同过滤推荐算法主要分两大类。一是基于内存的协同过滤算法,使用相似统计的方法获取具有相似兴趣的邻居用户集,因此也称基于用户的协同过滤算法。二是基于模型的协同过滤算法,先用历史数据得到一个推荐模型,在对推荐模型评估改进优化后进行预测推荐。[2]本文所改进的协同过滤算法均为基于用户的协同过滤算法。
2.1对用户建模
收集用户相关数据信息,利用收集到的用户信息
生成一个m×n的用户评价矩阵R,其中m表示用户数,n表示被评价对象数,rij表示用户i对项目j的评分,如果评分是非数值型的信息要转化为数值,矩阵R可以表示为:

2.2生成最近邻居集
最近邻居集是指与目标用户相似度较高的用户集。利用用户评分矩阵,计算用户间的相似度,生成目标用户的相似度最高的最近邻居集合。生成最近矩阵的过程,实际上是用矩阵R计算目标用户U的一个相似性以递减排序的集合,计算目标用户的相似度主要方法有:(1)余弦相似度计算,其中相似度随着余弦值的增大而增高;(2)皮尔森相关系数法,该计算方法克服了余弦相似度方法忽略了用户评分尺度不同的问题,在一定程度上提高了算法计算出相似度的准确率;(3)修正的余弦相似度计算方法,和相关系数法一样对用户评分进行修正,从而提高计算相似度的准确性。计算出用户相似度后,生成最近邻居集合步骤如下。[3]
(1)根据前面算法计算出的其他用户与目标用户的相似度,并筛选出相似度大于制定数值(0.70)的用户集。(2)对满足条件的用户集根据和目标用户相似度按降序排列,选出前N个用户组成目标用户的最近邻居集。
2.3生成推荐结果

公式(1)中,用户i与用户j间的相似性用公式sim(i,j)表示,目标用户的一个最近邻居j对某一项目d的评分用Ri,d表示,用户i和用户j对所有项目的平均评分分别为该公式的思想是利用生成的最近邻居集合,把邻居和目标对象间的相似度作为权重,计算邻居对某一项目的评分和对所有项评分差的加权平均分,从而推断出相似用户对待评价对象的评分,进行预测目标用户对待评分项目的评价,依据预测结果选择相似度高的若干个结果进行推荐。
虽然协同过滤算法得到了业界广泛认可,但也存在一系列问题。[4](1)评价数据稀疏性问题等。用户评价较少时,对推荐结果的质量会产生较大影响,目前,基于项目的协同过滤算法可以很好地解决数据评价稀疏性问题。(2)传统协同过滤算法把用户不同时期评价按相同权重看待,忽略了用户兴趣度随时间迁移对评价结果的影响。(3)传统协同过滤算法只从用户自身或者项目本身单一纬度的相似性聚类,从而产生推荐,忽略了用户和对象相关性对推荐结果的影响。(4)忽略了用户自身特性可能对推荐结果产生一定影响,不同特性用户可能具有不同的兴趣,具有相同特性的用户可能具有相同的爱好,所以生成用户最近邻居时,考虑用户自身特性能够在很大程度上提高推荐结果的质量。[5]因此,本文从用户兴趣度随时间迁移、用户和对象相关度及用户特性三方面对传统协同过滤算法进行改进,从而更好地为个性化图书推荐系统服务。
3 改进的协同过滤推荐算法
3.1从用户兴趣度随时间迁移方面对算法进行改进
传统的协同过滤算法生成最近邻居时,没有引入时间维度,把各个时期的评价按同一权重值进行计算,忽略了用户兴趣度可能随着时间增加而衰减的特性。通常来说,由于用户的兴趣是随时间变化的,在短期内用户的兴趣基本稳定,因此,用户早期的评价在推荐算法中应具有较小的权重,近期的评价应具有较高的权重。德国心理学家艾宾浩斯通过对兴趣随时间变化研究结果表明:人类的兴趣随时间变化是非线性的。借鉴人类兴趣迁移规律,引入兴趣度随时间迁移函数。根据时间t用户对项目评分权重值逐渐衰减,兴趣度随时间迁移函数Interest(u,t)表示用户兴趣随时间迁移过程。Interest(u,t)是一个非线性递减函数,反映用户近期评价的权重值大,一般权重值在0到1范围内。当前,兴趣度随时间迁移的函数一般有线性递减函数和指数衰减函数。
如图1所示,根据兴趣度随时间迁移曲线,改进后的算法引入公式(2)考虑用户兴趣随着时间变化对推荐结果的影响。
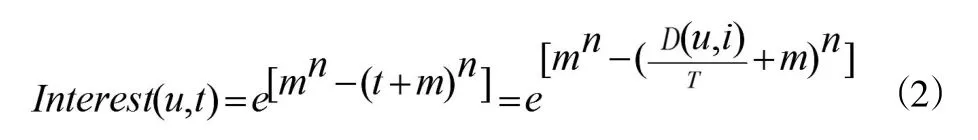
在公式(2)中,D(u,i)表示用户访问项目最近与最晚时间间隔,m和n为常数,通过调整m及n的值可以控制随时间变化兴趣度对推荐结果影响的权重值。
3.2从用户和对象相关度方面对算法改进
传统协同过滤算法忽略了用户和对象的相关性对
推荐结果的影响,仅根据用户本身或者项目单一纬度的相似度生成最近邻居,忽略了用户和对象之间的内在联系;改进后算法通过采用用户u和对象i相关度函数Relevance(u,i)来考虑用户对特定对象的兴趣度。

图1 兴趣度随时间迁移函数

假定用户U评价过的所有项目为集合Iu,假设某一项目i存在于集合Iu中,同时i和集合Iu中的项目具有高相似度,那么可以推断项目i和用户U的兴趣具有较高的相似性,在一定时间内,用户U兴趣度高的项目和i项目具有较高的相似度。也就是说,项目i对产生用户U的推荐结果具有重要参考价值。因此,定义Relevance(u,i)函数来评价项目i对用户U在某一时段的影响值,如公式(3)。在公式(3)中,sim(i,j)表示项目i和集合Iu中项目的相似性,sim(i,j)表示i和集合Iu的总体相似度,表示集合Iu中的项目数。改进后的算法引入了用户和对象相关度函数Relevance(u,i),根据特定用户对某一项目的相关度推荐,也就是按照用户对项目的兴趣度不同赋予相应的权重值。
3.3从用户特性方面对算法进行改进
不同特性的用户可能具有不同的兴趣,而具有相同特性的用户可能有一些相似的兴趣。因此,在产生最近邻居时,用户的特性是一个极其关键的因素。改进后的算法通过构建用户特性集,从而帮助提高推荐最近邻居的准确度。一方面,不同专业的读者,自身储备的知识不同,会对其兴趣带来一定影响,比如计算机专业的学生可能对IT类书籍有较高的兴趣,会计专业的学生可能对金融类书籍的兴趣度高;另一方面,相同专业的读者更可能对同一类书籍具有相似的兴趣度。所以,改进后的算法选择专业、年龄和性别作为用户特性对算法进行改进。
根据用户专业属性对协同过滤算法进行改进,首先根据用户专业将其构造成一颗倒立的专业树(见图2)。
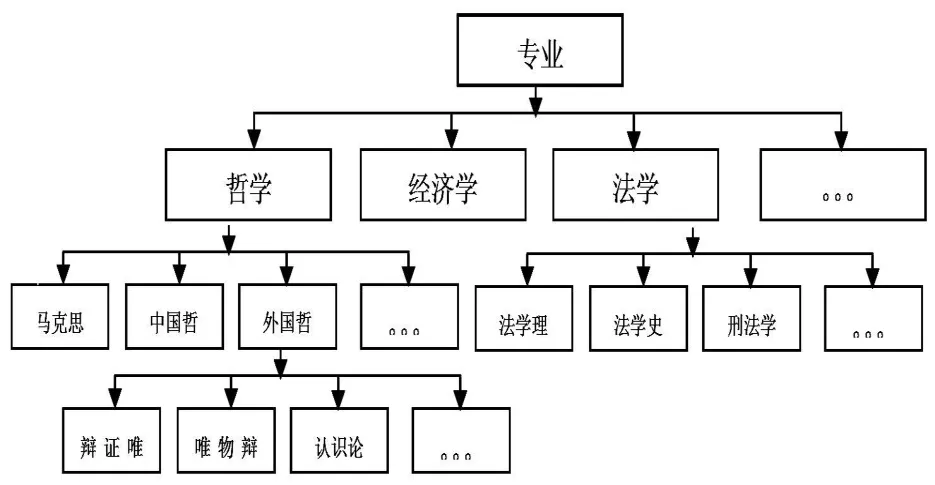
图2 专业树
假定专业树的总层数被称为专业树的高度(H),专业m,n在专业树中最近的共同父类节点被称作二者的最近父类节点,父类节点位于该树上的层次为对应的高度H(a,b),如专业马克思和认识论的高度H(马克思,认识论)为1,若专业m,n在专业树的最近共同父类节点为根节点,那么它们的高度是0。假定用户i的专业为m,用户j的专业为n,那么用户i,j在专业特性上的用户相似度为Major(i,j),如计算公式(4):

例如,某一用户i专业为马克思,用户j的专业为认识论,其共同最近父类为哲学,高度为2,专业树的高度H为4,那么Major(i,j)的值为0.5,也就是说用户在专业特性上的相似度为0.5。
根据用户性别特性对协同过滤算法改进,假定用户i、j的性别分别为m、n,则用户性别相似度Sex(i, j)可表示为:

根据用户年龄特性对协同过滤算法改进,假定用户i的年龄为m,用户j的年龄为n,则用户年龄相似度Age(i,j)可表示为:
综合考虑专业、性别及年龄特性,可以得出用户特性相似度公式(7):

公式(7)中,α,β均为小于1的正整数,作用是控制用户特性在用户特征相似度中的权重。其值的大小可以通过实验数据测试结果不断优化,最终达到最佳推荐结果。
4 改进后的算法在个性化图书推荐系统中的应用
采用改进后协同过滤推荐算法,可以通过对读者专业、性别及年龄的分析,根据用户特性计算用户特性相似度,很容易解决传统算法遇到的新用户问题。改进后的算法在推荐系统中的工作流程见图3。
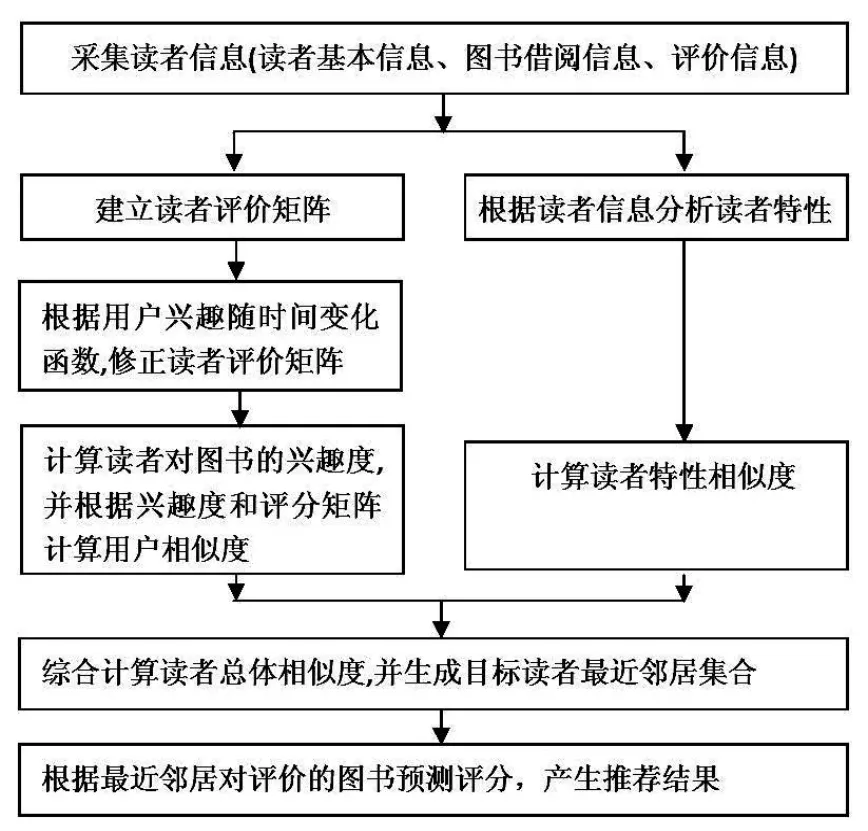
图3 改进后算法的推荐流程
ss
(1)收集读者信息,包括读者的基本信息(如学生编号、姓名、出生日期、性别、年龄、专业、爱好等)读者的借阅图书记录和用户对借阅过的图书的评价信息。(2)根据读者对借阅图书的评价信息,生成读者评价矩阵。同时根据读者基本信息生成读者特性集合。(3)根据读者兴趣随时间变化函数(公式2)对读者评价矩阵进行修正,从而在修正后的评价矩阵中考虑读者兴趣随时间变化情况。(4)根据读者对图书的相关函数(公式3)计算读者对图书的兴趣度,然后根据读者的兴趣度和评分矩阵计算用户的相似度。同时,根据读者特性利用公式(7)计算读者特性相似度。(5)综合计算读者的相似度,生成目标读者的最近邻居集合。(6)根据生成的读者最近邻居集,预测目标读者对待评价对象的评分,产生推荐结果。
5 试验与分析
实验数据为北京信息科技大学个性化图书推荐系统提供的数据集,数据包括4000名读者对10000本图书的评价,每个读者至少对10本图书进行评价,评价信息被转化为(0 1]上的值,评价值越高,表明读者对图书的兴趣度越高,并采用查准率(Precison)作为推荐算法的评价指标,其中,查准率公式(8)如下:

在公式(8)中,Hits为改进前后算法为读者推荐正确结果数,N表示读者的所有评价数,根据读者对图书评价,计算推荐图书的准确率,试验结果见图4。

图4 算法改进前后查准率对比图
试验分析结果表明,通过对传统的协同过滤算法进行改进,个性化图书推荐系统推荐结果查准率由原来的70%以下提高到了75%以上,极大地提高了推荐效果,在一定层面提高了图书的借阅率。
[参考文献]
[1]李涛.推荐系统中若干关键问题研究[D].南京:南京航空航天大学,2008.
[2]董坤.基于协同过滤算法的高校图书馆图书推荐系统研究[J].现代图书情报技术,2011(11):44-47.
[3]曹正强.网络教育作业中基于本体的智能推荐系统模型研究[J].软件导刊(教育技术),2010 (4):93-95.
[4]张富国.基于协同过滤技术的电子商务推荐系统初探[J].科技广场,2006(8):7-9.
[5]赵静.基于ebXML规范的企业间电子商务模式及关键技术研究[D].河北:石家庄铁道学院,2008.
[收稿日期]2014-08-11 [责任编辑]徐娜
[作者简介]孙彦超(1978-),男,河南南阳人,研究方向:数据库与信息系统、数据挖掘等;韩凤霞(1980-),女,河北沧州人,研究方向:教育技术。
[文章编号]1005-8214(2015)04-0099-04
[文献标志码]A
[中图分类号]G250.73;G252.8
