涉及地名的句子相似度计算方法的改进
2016-01-19黄洪,丰旭
黄 洪,丰 旭
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
涉及地名的句子相似度计算方法的改进
黄洪,丰旭
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
摘要:在计算涉及地名的句子相似度时,地名有着特别的重要性.如果不恰当地对地名进行处理,不体现出地名对于句子的重要性以及地名间的差异性,会导致相似度计算结果不甚合理.提出了一种改进的句子相似度计算方法.该方法在计算地名词语相似度时利用了地名在地理树中的层次关系以及从百度地图API获得的经纬度坐标,在计算非地名词语相似度时则利用了HowNet知识库,通过对地名词语和非地名词语赋予不同的权重来体现地名的重要性,并计算出句子的整体语义相似度,再结合句子结构的相似度计算出句子的综合相似度.实验表明:改进后的新方法对于计算涉及地名的句子相似度可以取得更理想的结果.
关键词:句子相似度;地名;地理树;经纬度
An improved calculation method for sentence similarity with
place names involved
HUANG Hong, FENG Xu
(College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China)
Abstract:Place names are of special importance when the similarity of sentences involving place names is calculated. The calculation results will not be reasonable if an algorithm improperly deal with place names. This paper proposes an improved method of Chinese sentence similarity calculation. This method uses the latitude and longitude coordinates obtained by Baidu map API and the hierarchical relationship in geographical tree when the similarity of place names is calculated. The HowNet is used to calculate the similarity between non-place names words. Then it gives different weights to place name words and non-place name words in order to obtain the semantic similarity of sentences. Finally the similarity of two Chinese sentences is calculated combining the sentences’ semantic similarity with structure similarity. Experiments show that this improved method can achieve better results for the calculation of the sentence similarity involving place names.
Key words:sentence similarity; place names; geographical tree; coordinates
相似度计算一直是人工智能和自然语言处理领域的一个研究热点[1],句子相似度计算在自然语言处理的很多领域都有着十分广泛的应用,如:问答系统、文本分类等,句子相似度主要是指两个句子在语法、语义和语用等方面的相似程度.在理解涉及地名的句子时,地名往往具有特别的重要性.由于地名间的天然关系,在计算涉及地名的句子相似度时,也需要对地名进行特殊处理.我们在研究旅游问答系统时发现:地名间的相似度是反映句子相似度的一个重要因素.但是,在现有的句子相似度研究中,还没有考虑到地名的特殊性和重要性.目前,中文句子相似度的计算方法大致可以分为以下几类:第一类为基于特征词的方法,该方法从两个句子中分别提取特征词,通过它们的特征词间的相似度来反映两个句子的相似度,程志强等[2]提出建立领域特征集,利用向量空间模型的方法计算句子相似度.第二类为基于语义词典的方法,通过词语相似度来反映句子相似度的,而词语相似度的计算需要依赖于比较完备的大型语义词典,秦兵等[3]提出利用HowNet知识库对两个句子中所有词语两两之间进行相似度计算,将相似度最高的两个词语作为最优匹配对,最后将所有最优匹配的词语对的相似度进行加权平均得到句子语义相似度.第三类为基于句法结构的方法,通过对两个句子进行句法结构分析来计算两个句子在句法结构上的相似性,HU Jinzhu等[4]认为通过两个句子的词性序列获得最优匹配的相同词性序列后,利用句子的词性相似度和词形相似度来反映句子结构相似度.
在计算涉及地名的句子的相似度时,三类方法没有很好地对地名进行处理,例如:对于“南京有哪些好玩的地方”和“杭州有哪些好玩的地方”两个句子,三类方法的计算结果都为1.0,实际上“南京”和“杭州”在地理位置上比较接近,文化环境较为相似,因此两个句子具有一定的相似性,但是并不完全相同,计算结果为1.0是不符合主观判断的.导致这种情况的原因主要有以下几种:第一类方法只考虑了词语在句中出现的频率,没有考虑词语的语义信息;第二类方法虽然考虑了语义信息,但是在HowNet常识知识库中地名的收集不够全面,并且没有对地名进行明确的区分,使得已存在HowNet知识库中的大部分地名间的相似度都为1.0,而不存在HowNet知识库中的大部分地名间的相似度为0.0;第三类方法只考虑了句子结构的相似度,没有考虑词语语义信息,只要结构相同,两个句子相似度就相同.因此针对地名构建了一个以中国为根节点的地理树,同时获取所有地名的经纬度坐标作为对此地理树的一个补充,最后提出了一种新的涉及地名的句子相似度计算方法.该方法通过句子的词类信息将句子分成地名词语集合和非地名词语集合,分别计算两个句子对应集合间的相似度,同时赋予地名词语和非地名词语不同的权重,获得句子整体语义相似度,再结合句子的结构相似度,最终得到句子的整体相似度.实验结果表明,该方法在计算涉及地名的句子相似度时更符合人们的主观判断.
1涉及地名的句子相似度算法的改进
考虑到地名在句中的重要性和特殊性,将地名术语和非地名术语分离出来,分别计算地名词语相似度和非地名词语相似度,同时考虑到句子结构对于句子相似度存在一定的影响,将句子结构相似度融入到句子相似度中.主要做了以下几个方面的工作.
1.1地名词语相似度计算
在自然语言处理的很多应用中,经常会出现许多地名术语.如果利用基于HowNet的方法计算地名术语相似度,由于HowNet知识库中存放的地名太少,且没有具体区分,使得许多尚未记录在HowNet知识库中的地名间的相似度为0.0,而已存在HowNet知识库中的地名间的相似度大部分为1.0,这样的结果是不符合人的主观判断的;如果利用传统的基于字符串匹配的方法计算这些术语的相似度则得到的结果大多为0.0,但是实际上,这些地名术语在地理位置、文化环境上都是存在一定相似性的.利用《中国地名录》以及由数据堂提供的“全国地名地物词典”等资料构建了一个地理树,以中国为根节点,利用地名间的下属关系将每个地名表示成树中的节点,部分地理树如图1所示.
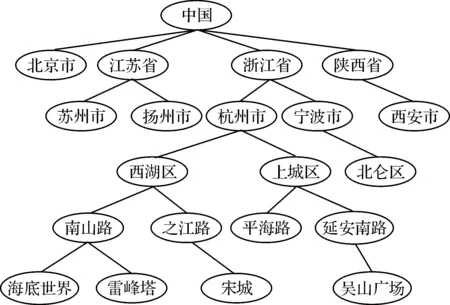
图1 地理树部分结构图Fig.1 The part of geography tree structure
在计算两个地名间的相似度时,由于考虑到地理树中子节点是父节点的一个分支,两节点间距离、公共节点深度以及两节点深度差三个要素对两地名节点间的相似度计算存在着重要的影响,地名gi和地名gj在地理树中的相似度计算式为
(1)
式中:deep(gi∩gj)为地名gi和地名gj在地理树中的最近公共父节点距离根节点的路径长度;deep(gi)为地名gi在地理树中距离根节点的路径长度,假设初始根节点的路径长度deep(中国)为1.
利用地理树的层次关系计算两地名间的相似度在一定程度上能达到较好的效果,但是对于计算同一父节点下的所有地名中任意两地名间的相似度结果都相同,因此,在研究了相关地理信息系统GIS[5]后,考虑引入地名的经纬度坐标作为地理树的一个重要补充.地名的经纬度坐标通常可以通过一些定位查询软件[6]进行获取,百度地图API[7]是一套为开发者免费提供的基于百度地图的应用程序接口,提供基本地图展现、搜索、定位、路线规划、LBS云存储与检索等功能.通过利用百度地图API的接口获得每一个地名的经纬度,最后将经纬度作为地名gi和gj的向量坐标,利用余弦值来表示两个地名在经纬度上的相似度,计算式为
(2)
式中:xi为地名gi的经度值;yi为地名gi的纬度值.
利用上述对地名术语相似度计算有着重要影响的两个因素:地理树层次关系以及地名经纬度坐标,得到计算地名术语整体相似度的公式为
Sim(gi,gj)=αSimg(gi,gj)+βSiml(gi,gj)
(3)
式中α和β为调节参数,α+β=1.经多次实验发现,当α=0.6,β=0.4时计算结果能够体现地名间的差异性,也较为符合人们主观判断.
如果待比较的句子中获得的地名在地理树中存在歧义,例如“海底世界有哪些好玩的东西”经过分词后会得到一个地名“海底世界”,但是句中并没有其他地名明确指出这是哪个地名下的“海底世界”,那么这个“海底世界”可能是杭州的“海底世界”,也可能是南京的“海底世界”,或者其他地方的“海底世界”,即“海底世界”无法在地理树中获得一个惟一的值.考虑到人们主观上通常询问的都是两个较为相近的地名之间的比较,例如:“海底世界”和“杭州海洋公园”,主观上人们会认为询问的是“杭州海底世界”和“杭州海洋公园”的比较,因此可以通过以下方法来计算地名不惟一时两个待比较的地名gi和gj的相似度:
1) 当gi惟一,gj不惟一时,即gi在地理树中获得相对应的地名Gi,gj在地理树中获得若干个相对应的地名{G1j,…,Gtj},通过式(3)将Gi和{G1j,…,Gtj}中的每一个地名进行相似度计算,取相似度值最大的两个地名的相似度作为gi和gj的相似度并用于句子的相似度计算.
2) 当gi不惟一,gj也不惟一时,取gi在地理树中对应的歧义地名集合{G1i,…,Gni},gj在地理树中对应的歧义地名集合{G1j,…,Gtj},通过式(3)将{G1i,…,Gni}中的每一个地名和{G1j,…,Gtj}中的每一个地名两两进行相似度计算,取最大值作为gi和gj的相似度值并用于句子相似度的计算.
1.2非地名词语相似度计算
国内外对词语相似度的计算方法大致可以分为两类:基于统计的方法和基于语义词典的方法.基于统计的方法是通过计算两个词语所处的上下文环境的相似度来度量两个词语的相似度的,王石等[8]通过利用词语的搭配词作为其上下文来计算词语的相似度,该方法建立在大规模语料库的基础上,属于经验主义方法.基于语义词典的方法是利用已有的语义词典中概念的上下位关系,通过计算两个概念在树状层次体系中的距离来得到词语相似度,属于理性主义方法,例如:基于WordNet语义词典,AHSAEEMG等[9]和KIMTANIDK等[10]通过计算两个概念节点之间的最短路径来计算词语间的相似度;基于HowNet的语义词典结构,刘群等[11]、江敏等[12]、王小林等[13]和崔淑洁等[14]提出了通过义原树中的上下位关系计算相似度的方法;基于同义词词林,YUZhengtao等[15]和田久乐等[16]提出了利用树形图中的节点间路径距离获得相似度的方法.
直接使用刘群等[11]提出的利用HowNet计算词语相似度的方法,计算词语相似度公式为
(4)
式中:W1和W2为两个词语;C1i为词语W1中的某个义项;C2j为词语W2中的某个义项,词语相似度是利用两个词语的所有义项之间相似度的最大值来表示的.
1.3句子结构相似度计算
句子结构相似度反映了两个句子在整体结构上的相似程度,是影响句子相似度的一个重要因素.王荣波等[17]利用词类信息经过正向匹配和反向匹配后获得两个句子结构的词类最优匹配序列,从而得到句子的结构相似度;LANYanling等[18]将两个句子的词性信息组成词性矩阵,利用对应词间距获得结构相似度.在计算句子结构相似度时只考虑句长相似度和词序相似度.句长相似度反映了句子在整体长度上的相似程度,计算公式为

(5)
式中:S为长句;T为短句;Len(S)为长句S分词后词语的个数;Len(T)为短句T分词后词语的个数.词序相似度反映了两个句子的相同词语在顺序关系上的相似程度,计算公式为
(6)
式中:假设两个句子的相同词语在长句S中的顺序为正序,则RevOrd为相同词语序列在短句S中的逆序数;MaxRevOrd为相同词语序列的最大逆序数.
1.4实现语句相似度改进算法的具体步骤
定义1相似度矩阵:两个句子对应集合中所有词语两两配对进行词语相似度计算,将计算结果存放到矩阵中,矩阵初始化为0.
首先,假设两个句子S和T分词后对应的词类序列为SPOS和TPOS.
SPOS:S0,S1,S2,…,Si,…,Sn-1
TPOS:T0,T1,T2,…,Tj,…,Tm-1
式中:Si表示句子S中下标为i的词语的词类,Tj表示句子T中下标为j的词语的词类.
算法具体步骤如下:
1) 根据词类信息存放词语,去除修饰性地名术语:遍历句子T中每个词类Tj,判断Tj是否属于地名词类ns:如果不属于ns,则将该词类Tj对应的词语存放到非地名集合中;如果属于ns,则判断该词类的下一个词类Tj+1是否属于ns:如果Tj+1不属于ns,则将Tj对应的词语存放到地名集合中,如果Tj+1属于ns,则判断Tj+1对应的地名是否是Tj对应的地名的下属,如果不是其下属,则将Tj对应的词语存放到地名集合中,如果是其下属,则返回继续遍历下一个词类Tj+1.同理,对句子S进行相同的步骤.
2) 对地名词语进行相似度计算:经过步骤1)将句子分词后的词语分别存放到了地名集合和非地名集合中,利用公式(3)计算得到两个句子对应地名集合中每个地名术语之间两两配对的相似度矩阵,从相似度矩阵中获得地名术语的最佳配对结果.
3) 对非地名词语进行相似度计算:利用公式(4)得到两个句子对应非地名集合中每个词语之间两两配对的相似度矩阵,从中获得词语的最佳配对结果.
4) 经过上述三个步骤后,对于两个句子S和T,可以得到地名术语的最佳配对结果和非地名词语的最佳配对结果,由这些最佳配对结果可以获得句子整体的语义相似度,计算公式为
(7)
式中:n为两个句子的地名集合中获得的最佳配对地名的对数;gi1为配对地名中句子S的地名;gi2为配对地名中句子T的地名;m为两个句子的非地名集合中获得的最佳配对词语的对数;Wj1为配对词语中句子S的词语;Wj2为配对词语中句子T的词语;w1为赋予地名词语的权重;w2为赋予非地名词语的权重,w1+w2=1.经过多次实验发现,当w1=0.7,w2=0.3时获得的相似度值能够体现两个句子在语义上的相似程度,较为符合人们的主观判断.
5) 根据式(5,6)计算句子的句长相似度和词序相似度,获得句子的结构相似度,计算公式为
Simstru(S,T)=w3SimLen(S,T)+w4SimOrd(S,T)
(8)
式中:w3为句子长度相似的权重;w4为句子词序相似的权重,w3+w4=1.经过多次实验发现,当w3=0.6,w4=0.4时获得的相似度值能够体现两个句子在结构上的相似程度,也较为符合人们的主观判断.
6) 将句子整体的语义相似度与句子结构相似度相结合,得到句子整体相似度,计算公式为
Sim(S,T)=λ1Simsem(S,T)+λ2Simstru(S,T)
(9)
式中:λ1为句子语义相似度的权重;λ2为句子结构相似度的权重,λ1+λ2=1.经过实验对比分析发现,当λ1=0.9,λ2=0.1时计算结果较为符合人们的主观判断.
2实验及结果分析
在实验中,使用中科院的分词系统ICTCLAS2011对句子进行分词和词性标注处理,中科院的分词系统ICTCLAS2011所使用的汉语词性标注集将词类分为22个一类、66个二类和11个三类,由于该分词系统对于地名的识别还不是十分完整,笔者将整理出来的地理树知识作为参考资料存放到系统的用户导入文件中,以便于在分词时能够更好的识别出地名.由于目前还没有可用于中文句子相似度测试的标准化测试集,鉴于本实验重点研究的是地名对于语句相似度的影响,而旅游领域问答系统的问句通常会涉及到地名,因此实验例句使用除地名不同外其他词语都基本相同的旅游领域的典型句子.本次实验还邀请了35名学历本科以上、身心健康的同学对这些实验例句进行主观评分,分数取值为0到1之间的任意小数,分数越接近0说明相似度越低,分数越接近1说明相似度越高,最后将所有同学的主观数据进行加权平均,得到的结果存放在表1的“主观”一列中,作为标准数据用于和其他四种方法的计算结果进行比较.方法1是基于特征词的方法[2],方法2是基于HowNet语义词典的方法[3],方法3是基于句法结构的方法[4],方法4是笔者的方法.由于篇幅有限,部分实验结果如表1所示.
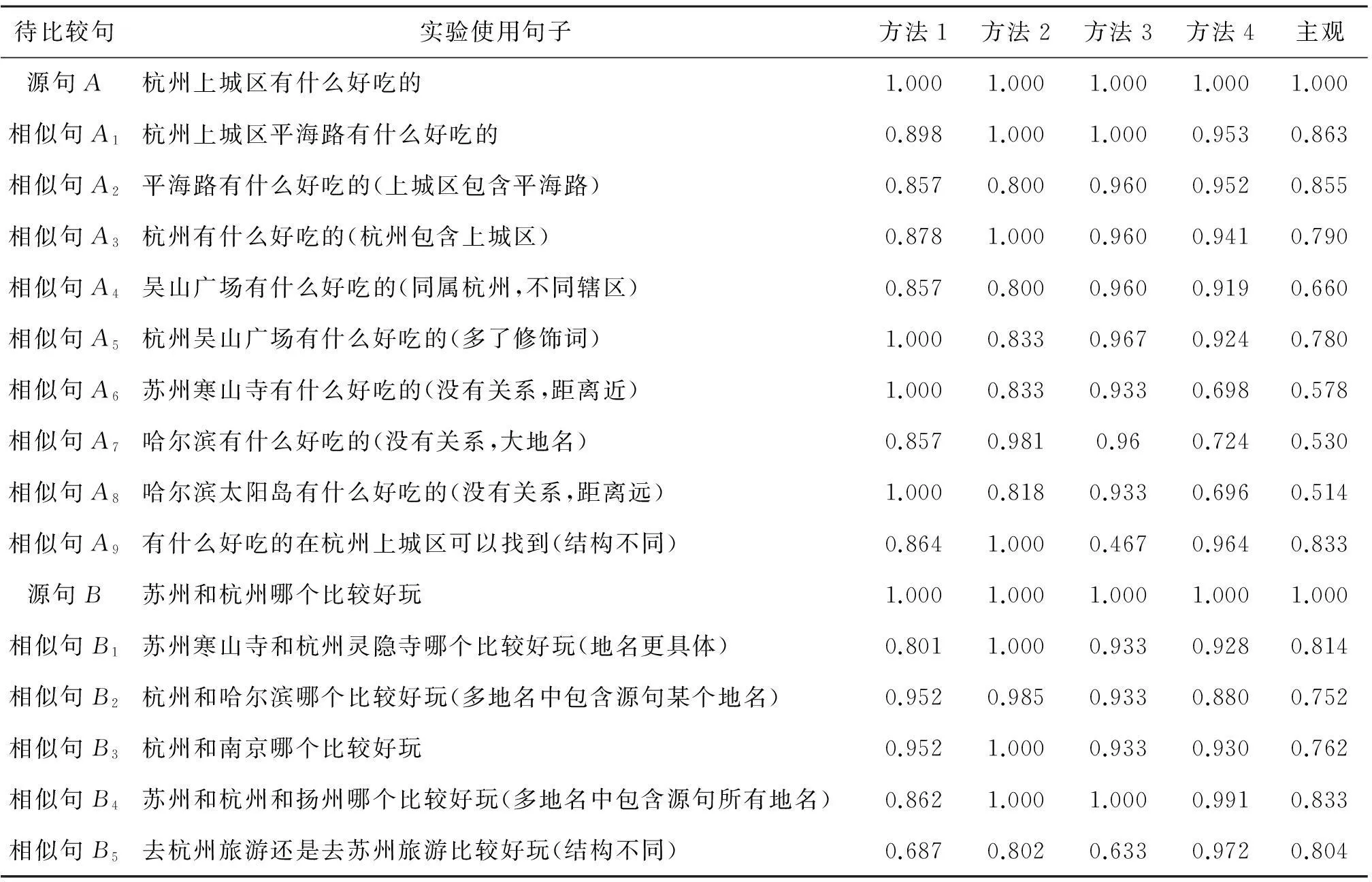
表1 部分句子相似度计算实验结果
表1给出了两组实验例句,从表1中可以看出:相似句A5、A6和A8在方法1下与源句A的相似度计算结果都为1.0,但是实际上,“吴山广场”和“上城区”只是同属于杭州,“苏州寒山寺”和“北京天坛”与“上城区”没有关系,只是距离远近的区别,两个地方距离越近,城市文化和气候差异就越小.由此可以看出:相似句A5和源句A的相似度应该高于相似句A6和源句A的相似度,相似句A8和源句A的相似度应该最低,而且这些相似句和源句A都不相同,因此实验结果是不符合主观判断的.相似句B1、B3和B4在方法2下与源句B的相似度计算结果都为1.0,但是三个相似句与源句B都不是完全相同的,相似句B1比较的是“寒山寺”和“灵隐寺”,相似句B3比较的是“杭州”和“南京”,相似句B4比较的是“苏州”、“杭州”和“扬州”,所以相似句B4和源句B的相似度应该高于相似句B1、B3和源句B的相似度,因为B4中会包含源句B的“苏州”和“杭州”的比较,故实验结果是不符合主观判断的.相似句A2和A3在方法3下与源句A的相似度计算结果都为0.96,但是相似句A2的地名“平海路”被包含在源句A的地名“上城区”中,相似句A3的地名“杭州”包含了源句A的地名“上城区”,因此A2和A3与源句A的相似度应该是不同的,故实验结果并不符合主观判断.而且在第一组实验例句中,相似句A9与源句A最接近,相似度也应该是最高的.可见三种典型算法都有着各自的缺点,它们的计算结果不太符合主观判断.
但是,从方法4的计算结果中可以看出:相似句A5,A6,A8和源句A在方法4下的相似度计算结果互相比较时,A5的相似度高于A6的相似度,A8相似度是最低的,这较好地体现了方法4的地名相似度计算中的经纬度相似度计算对没有包含关系的地名进行了距离远近的区分.同理,相似句B3的相似度要高于相似句B2与源句B的相似度.同时,相似句A1和源句A在方法4下的计算结果不为1.0,这也反映了方法4的地名相似度计算中的地理树相似度计算对具有包含关系的地名的区分起到了一定的作用.相似句A9和源句A的相似度不为1.0,这说明方法4还考虑到了句子结构对于句子的影响.将四个方法的计算结果和主观判断结果进行方差计算,得到的结果如表2所示.

表2 方差计算结果比较
从表2容易看出:方法4的计算结果在总体上是最接近主观判断结果的,而且在邀请的35名同学中有86%的同学都认为方法4的计算结果是四个方法中最好的.
3结论
提出了一种改进的涉及地名的句子相似度计算方法,通过构建地名地理树和获取地名经纬度来计算地名词语间的相似度,在计算句子相似度时通过对地名词语和非地名词语赋予不同的权重来体现地名对于计算句子相似度的重要性,并考虑了句子结构的因素.实验表明:改进后的方法在计算涉及地名的句子相似度时比传统方法更加合理,计算结果更符合人们的主观判断.
参考文献:
[1]徐彩虹,刘志,潘翔,等.一种基于实例学习的三维模型检索匹配方法[J].浙江工业大学学报,2012,40(3):326-330.
[2]程志强,闵华松.一种基于向量词序的句子相似度算法研究[J].计算机仿真,2014,31(7):419-424.
[3]秦兵,刘挺,王洋,等.基于常问问题集的中文问答系统研究[J].哈尔滨工业大学学报,2003,35(10):1179-1182.
[4]HU Jinzhu, XU Ting, SHU Jiangbo, et al. A kind of calculation method of Chinese sentence structure similarity[C]//International Conference on Advanced Computer Theory and Engineering(ICACTE). Chengdu: International Conference on IEEE,2010:344-347.
[5]刘俊萍,董飞龙,邵佳伟.GIS支持下的海塘工程信息管理[J].浙江工业大学学报,2014,42(2):199-203.
[6]徐志江,庄壮,孟利民.一种基于Android智能手机的车载定位查询软件[J].浙江工业大学学报,2013,41(6):655-659.
[7]百度.百度地图API[EB/OL].[2015-06-10].http://developer.baidu.com/map/.
[8]王石,曹存根,裴亚军,等.一种基于搭配的中文词汇语义相似度计算方法[J].中文信息学报,2013,27(1):7-14.
[9]AHSAEE M G, NAGHIBZADEH M, NAEINI S E Y. Semantic similarity assessment of words using weighted WordNet[J]. International Journal of Machine Learning and Cybernetics,2014,5(3):479-490.
[10]KIMTANI D K, CHOUDHURY J, CHAKRABARTY A. Improvement in word sense disambiguation by introducing enhancements in English WordNet structure[J]. International Journal on Computer Science and Engineering,2013,2(5):435-438.
[11]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[12]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
[13]王小林,王义.改进的基于知网的词语相似度算法[J].计算机应用,2011,31(11):3075-3077.
[14]崔淑洁.句子相似度算法研究及其在中文问答系统中的应用[D].杭州:浙江工业大学,2014.
[15]YU Zhengtao, HU Lei, HUANG Li, et al. Similarity computation of Chinese question based on chunk[C]//Proceedings of the Fifth International Conference on Machine Learning and Cybernetics.Dalian:International Conference on IEEE,2006:17-22.
[16]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报,2010,28(6):602-608.
[17]王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2005,19(1):21-29.
[18]LAN Yanling, CHEN Jianchao. Chinese sentence structures similarity computation based on POS and POS dependency[J].Computer Engineering,2011,37(10):47-49.
(责任编辑:陈石平)
文章编号:1006-4303(2015)06-0624-06
中图分类号:TP391
文献标志码:A
作者简介:黄洪(1964—),男,江西丰城人,教授,研究方向为软件开发方法、智能电子商务和自然语言处理等,E-mail:huanghong@zjut.edu.cn.
收稿日期:2015-06-12
