大数据系统架构及技术发展研究
2015-12-27曾凌静
曾凌静
(福建船政交通职业学院信息工程系,福建福州350007)
大数据系统架构及技术发展研究
曾凌静
(福建船政交通职业学院信息工程系,福建福州350007)
近几年技术的进步使得许多领域(如医疗保健传感器、客户端、互联网和金融企业、以及商业系统)产生了海量数据.相比传统数据,除了其庞大的数据量,大数据也表现出其他特性.例如,大的数据通常是非结构化的,需要更精确的实时分析.这意味着需要新的系统架构对数据进行采集、传输、存储以及大规模数据处理的机制.提出了大数据的定义和未来大数据面临的挑战,将大数据系统分为四个连续的模块,即数据生成、数据获取、数据存储和数据分析,这四个模块可以形成大数据的价值链.对研究和产业机构提出的许多方法进行了分析和总结并列出了一些大数据系统潜在的研究方向.
云计算;数据生成;数据获取;数据存储;数据分析
新兴的大数据,由于其广泛的影响,已经深刻地改变着我们的社会,未来将继续吸引来自技术专家和公众的普遍关注.很明显,随着数据量呈几何式的增长,我们正生活在海量数据的时代.例如,一个IDC报告[1]预测,2005-2020年,全球数据量将从130-40 000艾字节,相当于每两年就有两位数的增长,又如,Mckinsey的报告[2]指出,预计全球个人定位数据的潜在价值为1 000亿美元,在未来的十年,服务提供商的消费者和终端用户的数据价值将会高达7 000亿美元.“大数据”的趋势已经越来越明显.事实上,大数据已从方方面面改变着我们的社会.例如,Mckinsey的报告指出,预计全球个人定位数据的潜在价值为1 000亿美元,在未来的10年,服务提供商的消费者和终端用户的数据价值将会高达7 000亿美元.大数据的巨大潜力已迅速吸引了来自工业、政府和研究机构等不同领域研究人员的极大兴趣,例如,工业,政府和研究机构.其次,政府也在拟定新的方案,加快应对大数据挑战的脚步.最后,Nature和Science杂志也发表了相关技术难题,讨论大数据现状及其挑战.
1 大数据的基本概念
1.1 大数据的定义
关于大数据的定义是众说纷纭,尚无公认的统一定义.从根本上说,大数据不仅仅意味着大量的数据还应该具备其他特征,这就需要区分“海量数据”和“非常大的数据”两个概念.数据绝对数量的发展历史如图1所示,可以看出目前数据以达到PB和EB级别,还有明显增长的趋势.
事实上,从一些定义大数据的文献中可以发现以下3个类型的定义可以方便我们更加清楚地认识大数据:
1)属性定义:IDC是研究大数据及其影响的先驱.它在2011年由EMC(云计算的领导者)主办的会议上提出:“大数据技术描述了新一代的技术、架构和设计,从大量的数据集提取有价值的数据,从而实现快速获取、发现和分析.”这个定义界定了大数据,也就是人们常说的4V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值).在2001年的研究报告中也出现过类似的定义:META集团(现为Gartner公司)的分析师道格·兰尼指出,数据增长的挑战和机遇是三维的,即数量、速度和多样性.虽然这种描述与最初定义的大数据有所不同,但Gartner和许多行业包括IBM和一些微软的研究人员在那之后的10年依旧使用这个“3VS”模式来描述大数据.
2)比较定义:2011年,Mckinsey的报告[2]中定义大数据是“数据集的大小超出了一般数据库软件获取、存储、管理和分析的能力.”然而这个定义是主观的,没有说明数据度量的依据.
3)架构定义:美国国家标准与技术研究院(NIST)提出“大数据是数据量,采集速度或数据表示达到传统方法的上限,需要使用水平缩放处理来进行有效的分析.”特别是,大数据可以进一步分为大数据科学和大数据框架.大数据科学是“大数据的知识、现状以及评估研究,”而大数据框架是“相关算法的软件库,计算机分类处理和分析问题.”
传统数据和大数据的比较如表1所示.

图1 大数据的发展历史

表1 大数据与传统数据之间的比较
1.2 大数据处理的两种方式:流处理和批处理
大数据处理是利用强大的支持平台,分析大数据的潜在价值.根据处理时间的要求,大数据分析可分为两个方式[3]:
1)流处理:流处理方式[4]假设数据的潜在价值取决于数据的新鲜程度.由于流快速并携带庞大的数据集,只有其中一小部分被存储在有限的存储器,所以可以快速地分析数据导出结果.流传输处理的理论和技术已经研究了数十年,代表性的开源系统有Storm,S4[5]和Kafka.流处理方式是用于在线应用,通常处理时间是秒、甚至毫秒水平.
2)批处理:在批处理方式中,首先存储数据,然后进行分析数据.MapReduce[4]已成为占主导地位的批处理模式.MapReduce的核心思想是:将数据分成小块,然后把这些块并行处理,以分布方式来产生中间结果,最后将所有的中间结果组合聚集,导出最终结果.该模型计算资源接近数据源的位置,这样可以避免数据传输的通信开销.MapReduce的模式很简单,已被广泛应用于生物信息学、Web挖掘和机器学习.
两个处理方式之间有许多差异如表2所示.
2 大数据的系统架构
2.1 大数据系统:价值链的综述
一个大的数据系统是复杂的,在数据循环周期的不同阶段提供不同的功能.在这种情况下,我们采取系统工程的方法,将一个典型的大数据系统分解成连续的4个阶段,即数据生成、数据获取、数据存储和数据分析,如图2所示.

表2 流处理和批处理的比较
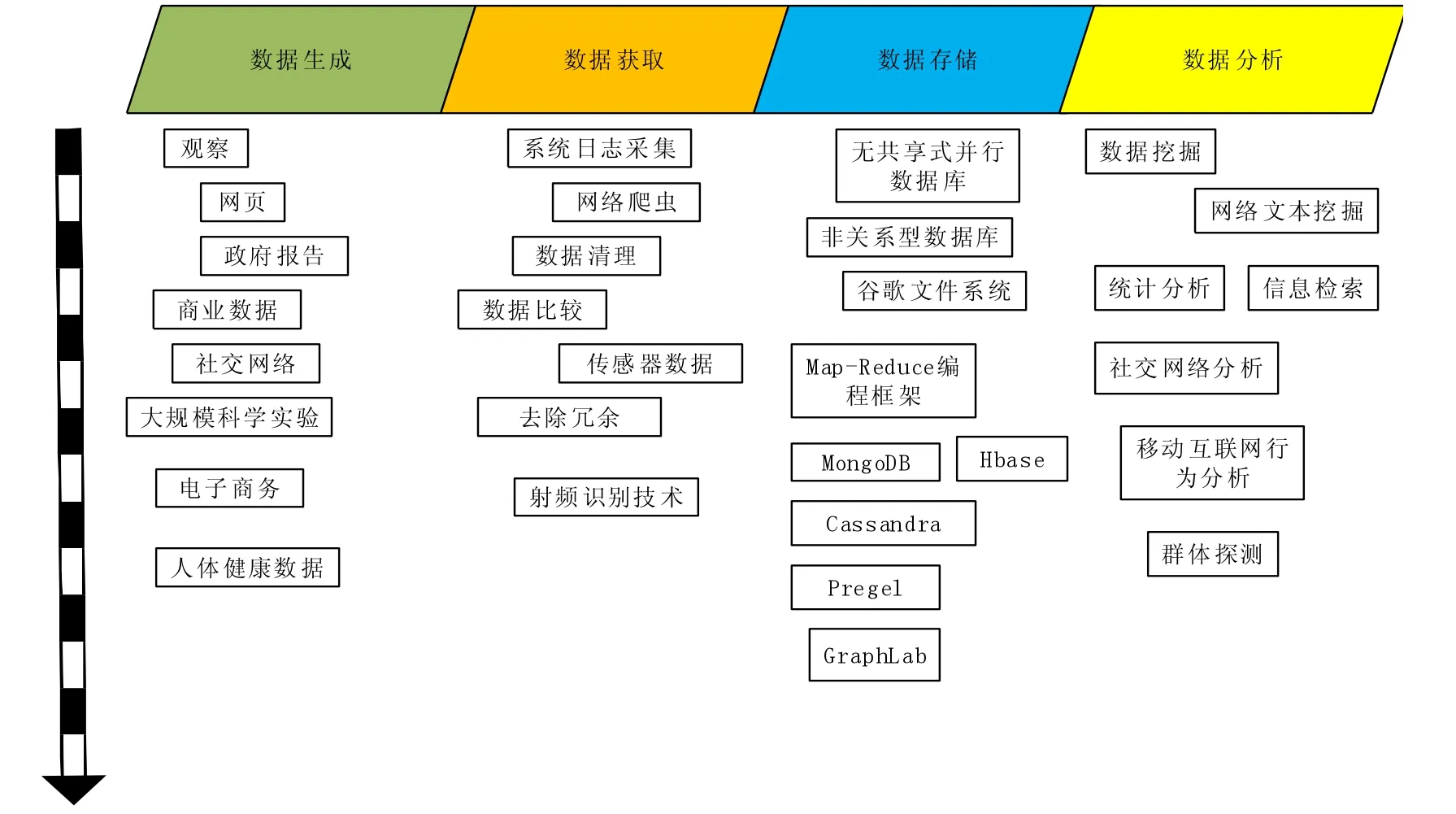
图2 大数据的价值链
2.2 大数据的分层系统
一个大数据系统是具有层状结构的.层状结构可划分成3层,即基础设施层、计算层以及应用层.各层的功能如下:
1)基础设施层包括ICT资源,它可以通过云计算和虚拟化技术实现.在该层次中,资源必须合理分配以满足大数据的需求,同时实现资源利用效率最大化,既要有节能意识也需要简化操作.
2)计算层是中间层,用来运行原始的ICT资源和封装各种数据.包括数据集成、数据管理和编程模型.数据集成将数据源不同的数据和数据集整合成统一的形式,提供必要的数据预处理操作.数据管理是指提供持久的数据存储和高效的管理,如分布式文件系统、SQL和NoSQL等数据存储工具.编程模型则利用抽象的应用程序逻辑,便于数据分析MapReduce[4],Dryad[6],Pregel[7],和Dremel[8]就是常见的编程模型.
3)应用层利用计算层提供的编程模型来实现各种数据分析功能,包括查询、统计分析、聚类和分类界面.麦肯锡提出了5种可能的大数据应用领域:医疗保健、公共部门管理、零售业、全球制造业和个人位置数据.
3 数据生成
在表3中,我们列举从应用程序的角度具有代表性的大数据源.从表3可以看出,大部分的数据源生成的都是PB级非结构化数据,这样可以对庞大用户量的需求进行快速的回应和分析.
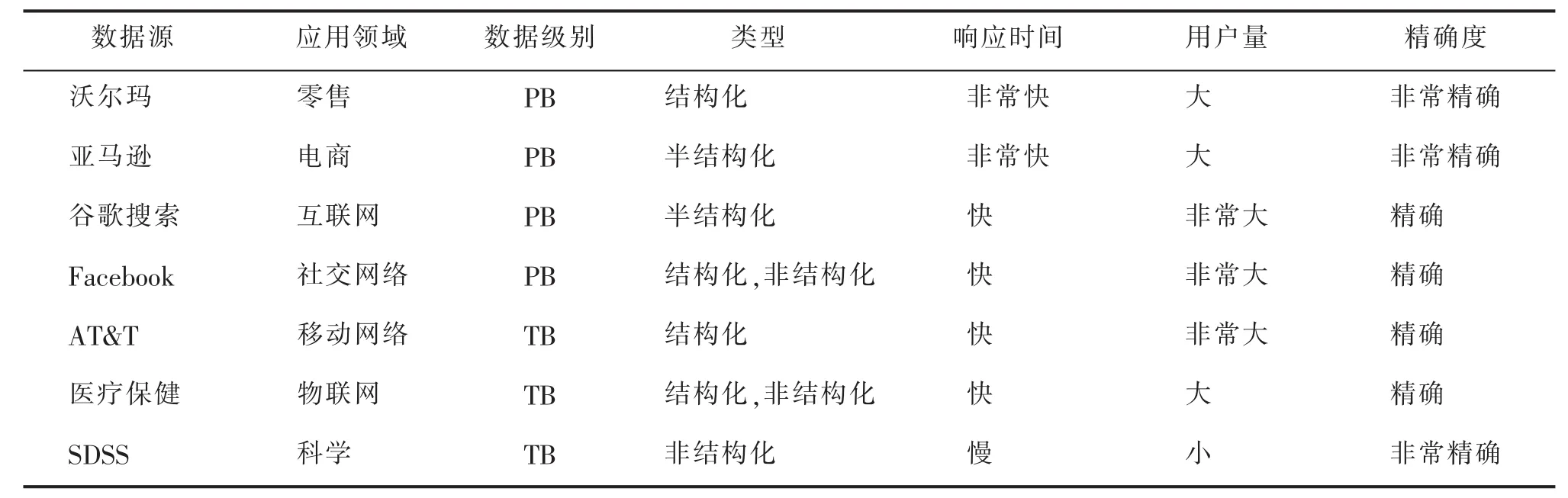
表3 典型的大数据源
4 数据获取
数据获取阶段的任务是,以数字化的形式整合信息,以便进一步存储和分析.采集过程包括3个子步骤:数据获取、数据传输以及数据预处理,如图3所示.其中,数据传输和数据预处理之间没有严格的顺序之分.表4列出了3种数据获取方法的比较.
5 数据存储
一个大数据平台的数据存储子系统需要便于数据分析和特征提取.出于这个目的,数据存储子系统应满足以下两个特点:
1)存储的基础架构必须满足可靠性和永久性.
2)数据存储子系统必须提供一个可扩展的访问接口来查询和分析数据.
5.1 存储基础架构
存储设备可以基于特定的技术进行分类:1)随机存取存储器(RAM),2)磁性磁盘和磁盘阵列,3)存储级内存.
5.2 数据管理框架
数据管理框架考虑的是如何组织信息进行有效的处理.数据管理框架分成3个层:文件系统、数据库技术和编程模型,如图4所示.
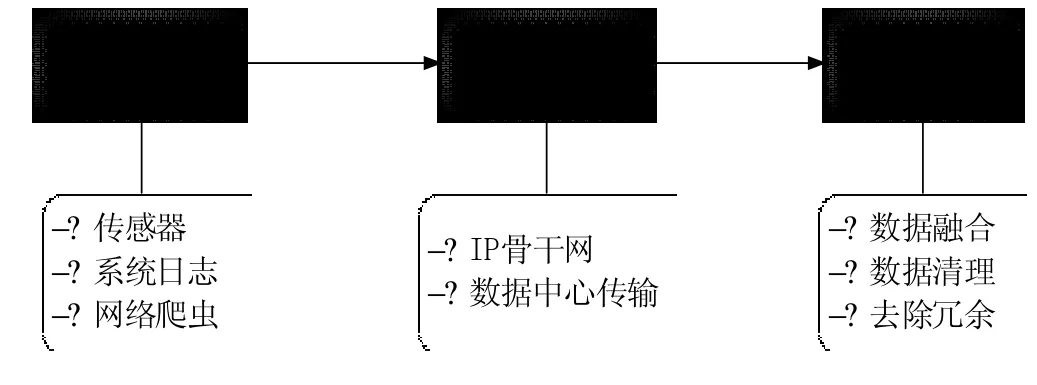
图3 数据获取步骤
6 数据分析
数据分析是大数据的价值链的最后一个,也是最重要的阶段,其目标是提取有用的数据价值,做出结论或支持决策.以下首先讨论数据分析的目的和指标,其次介绍一些在数据分析中常用的方法.
6.1 目的和指标
数据分析就是通过观察、测量以及实验获得关于感兴趣的数据信息.以下仅列出一些潜在的用途:1)进行推断和解释数据,并确定如何使用它;

表43 种数据获取方法的比较
2)检查数据是否合法;
3)提供意见及协助决策;
4)推断原因故障;
5)预测未来.
6.2 常用的方法
虽然应用领域不同,但是一些常见的数据分析方法是通用的.下面讨论3种数据分析的方法.
1)数据可视化:与图形信息密切相关.数据可视化的目标是通过图形有效地传递信息.一般来说,图表帮助人们方便快捷地了解信息.然而,随着数据量的增长,以大数据的水平,传统的电子表格不能处理巨大的数据量.可视化大数据已经成为一个活跃的研究领域,因为它可以帮助算法设计、软件开发和客户需求.
2)统计分析:是一种基于统计理论的应用数学的一个分支.在统计理论中,随机性和不确定性是用概率论建模.统计分析可以对大数据集进行描述和推理.描述性的统计分析可以总结或描述数据集合,而推论性的统计分析可以用来做有关过程的推论.更复杂的多元统计分析,有因子分析,聚类和判别分析技术.
3)数据挖掘:是在大数据中发现模式的计算过程.各种数据挖掘算法,已经在人工智能、机器学习、模式识别、统计信息和数据库等领域被提出.在2006年IEEE关于数据挖掘的国际会议上(ICDM),提出了十大最具影响力的数据挖掘算法[10].这些算法是C4.5、k均值、SVM(支持向量机)、Apriori、EM(期望最大化)、PageRank、AdaBoost、k近邻算法、朴素贝叶斯和CART.这十个算法包括分类、聚类、回归、统计学习、关联分析和连接挖掘,这些都是在数据挖掘研究中较为重要的课题.此外,还有其他先进的算法,如神经网络和遗传算法.
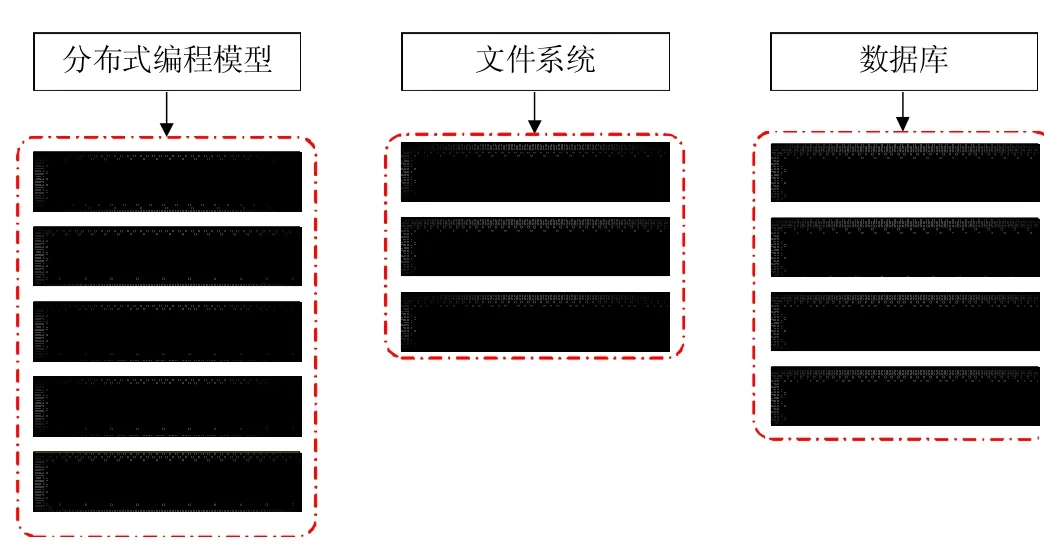
图4 数据管理技术
7 结论和未来的研究方向
7.1 结论
大数据时代的来临,带来了数据采集、管理和分析机制的迫切需要.笔者介绍了大数据的概念,并强调了大数据的价值链,涵盖了整个大数据的生命周期.大数据值链包括4个阶段:数据生成、数据采集、数据存储和数据分析.
7.2 未来研究的方向
在大数据系统的许多挑战需要进一步的研究.下面列出了覆盖大数据的整个生命周期,即从大数据平台到应用的未来研究方向:
1)大数据平台
虽然Hadoop已成为大数据分析平台的中流砥柱,但它仍然未成熟.首先,Hadoop要完成海量实时数据的采集和传输,必须提供比起批处理模式更快的处理速度.其次,Hadoop提供一个简洁的用户编程接口,同时隐藏复杂的背景执行.在某种意义上,这种简单会导致性能降低.我们应该采用类似DBMS更先进的接口,同时优化Hadoop的性能.第三,一个大规模Hadoop集群是需要数千甚至数十万台服务器,这意味着大量的能量消耗.最后,隐私和安全是在大数据时代的一个重要问题.大数据平台应该找到执行数据访问控制和数据处理之间的良好平衡.
2)处理模型
当前成熟批处理方式很难适应迅速增长的数据量和实时要求.这需要设计一个新的实时处理模型或者数据分析机制.在传统的批处理模式中,数据应先存储,然后,扫描整个数据集,以产生分析结果.很明显,数据的传输、存储和重复扫描过程中浪费了许多时间成本.未来可以采用新的实时处理模式来减少这种开销成本.
3)大数据应用
大数据的研究仍处于萌芽阶段.研究典型的大数据应用可以产生利润的业务,提高政府部门的工作效率,促进人类科学技术的发展,这些都需要加快大数据的进展.
[1]GANTZ J,REINSEL D.The Digital Universe in 2020:Big Data,Bigger Digital Shadows,and Biggest Growth in the Far East[J].IDC iView:IDC Analyze the Future,2012,2007:1-16.
[2]MANYIKA J,CHUI M,BROWN B,et al.Big Data:The Next Frontier for Innovation,Competition,and Productivity[J].2011.
[3]Marche S.Is Facebook Making us lonely[J].The Atlantic,2012,309(4).
[4]Tatbul N.Streaming Data Integration:Challenges and Opportunities[C]//Data Engineering Workshops(ICDEW),2010 IEEE 26th International Conference on.IEEE,2010:155-158.
[5]NEUMEYER L,ROBBINS B,NAIR A,et al.S4:Distributed Stream Computing Platform[C]//Data Mining Workshops(ICDMW),2010 IEEE International Conference on.IEEE,2010:170-177.
[6]ISARD M,BUDIU M,YU Y,et al.Dryad:Distributed Data-parallel Programs from Sequential Building Blocks[C]//ACM SIGOPS Operating Systems Review.ACM,2007,41(3):59-72.
[7]MALEWICZ G,AUSTERN M H,BIK A J C,et al.Pregel:a System for Large-scale Graph Processing[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data.ACM,2010:135-146.
[8]MELNIK S,GUBAREV A,LONG J J,et al.Dremel:Interactive Analysis of Web-scale Datasets[J].Proceedings of the VLDB Endowment,2010,3(1-2):330-339.
[9]LABRINIDIS A,JAGADISH H V.Challenges and Opportunities with big Data[J].Proceedings of the VLDB Endowment,2012,5(12):2032-2033.
[10]WU X,KUMAR V,QUINLAN J R,et al.Top 10 Algorithms in Data mining[J].Knowledge and Information Systems,2008,14
(1):1-37.
(责任编辑 李健飞)
A Research on the Development of Large Data System Architecture and Technology
ZENG Ling-jing
(Department of Information Engineering,Fujian Vocational College of Chuanzheng Communications,Fuzhou,Fujian 350007,China)
In recent years,the development of technology in many fields(such as medical sensors,client,Internet and financial business,and business system)has produced massive amounts of data.Compared with the traditional data,in addition to the huge amount of data,large data also show other characteristics.For example,the data are unstructured,needing real-time and precise analysis,which mean the need for a new system of collection,data transmission,storage,and the mechanism of large-scale data processing.This paper first puts forward the definition of big data and the future of big data challenges.Second,a big data system is divided into four sequential modules,namely data generation,data acquisition,data storage and data analysis;the four modules can form a large data value chain.Subsequently,many methods of research and industrial structure are analyzed and summarized.Finally,it proposes the research direction of the potential of big data system.
cloud computing;data generation;data acquisition;data storage;data analysis
TP301
:A
:1673-1972(2015)06-0038-06
2015-04-02
曾凌静(1983-),女,福建福州人,讲师,主要从事云计算研究.
