利用深度玻尔兹曼机与典型相关分析的自动图像标注算法
2015-12-27刘凯张立民孙永威林雪原
刘凯,张立民,孙永威,林雪原
(海军航空工程学院信息融合研究所,264001,山东烟台)
利用深度玻尔兹曼机与典型相关分析的自动图像标注算法
刘凯,张立民,孙永威,林雪原
(海军航空工程学院信息融合研究所,264001,山东烟台)
提出一种基于深度玻尔兹曼机与典型相关分析的自动图像标注算法(DBM-CCA)。该算法利用深度玻尔兹曼机实现图像与文本的低层次特征向稀疏高层次抽象概念的转变,并通过典型相关分析建立子空间映射关系以实现标注词汇的生成。首先在深度玻尔兹曼机提取图像与文本高层特征过程中,选用伯努利分布和高斯分布分别拟合标注词汇和图像特征,然后在图像与标注词汇高层特征形成的典型变量空间内计算待标注图像与训练集图像的马氏距离并据此加权计算得到高层标注词汇特征,最后由平均场估计生成图像标注词汇。实验结果表明,所提算法对图像的标注准确率改善较好,与经典的基于监督的多类标签方法和多重伯努利相关模型相比,在Corel5K实验中平均查准率和查全查准均率分别提高了10%和5%。
自动图像标注;深度学习;深度玻尔兹曼机;典型相关分析
为提高海量图像检索管理效率,以及克服“语义鸿沟”瓶颈的制约,自动图像标注成为了图像检索领域中非常具有挑战性的任务。近年来,已有多种自动图像标注的新方法被提出[1-3]。文献[1]提出了结合潜在社区与多核学习的自动图像标注算法(latent - community and multi-kernel learning, ICMKL);文献[2]针对图像标注词间存在的噪声以及失衡问题,提出基于相似兼容性的标注滤波方法;文献[3]在此基础上设计了多样化语义图像标注方法。这些方法最大的特点是通过构建面向标注词汇与图像特征的多种模型,实现图像与标注词汇之间复合平衡的映射关联。虽然这些方法能够较好地实现图像标注,但受到模型参数影响较大,且参数较多,往往需要大量实验验证,带来实际应用的不便。
作为2013年十大突破技术之首,多种深度学习模型[4-7]被应用于跨媒体检索和多模态信息处理领域。文献[8]提出通过在图像与文本间建立多模态深度玻尔兹曼机,以解决图像与文本的检索和标注问题,但与经典的自动图像标注算法相比,其词汇模型和顶层特征融合机制仍有待改进。
目前,典型相关分析[9]作为反映两组指标之间的整体相关性的多元统计分析方法,已被用于建立两种模态信息间的关联关系,以实现不同类型信息的联合学习[10-12],但其问题在于典型相关分析往往适应于低层次信息的关联,对于抽象、稀疏的高层概念应用范围较窄,这就需要选取合适的信息特征提取方式。
为解决上述问题,鉴于深度学习的发展以及现有方法[1-3]的出发点,本文对深度学习在自动图像标注的应用进行研究,提出了结合深度玻尔兹曼机与典型相关分析的自动图像标注算法(deep Boltzmann machine-canonical correlation analysis, DBM-CCA),通过深度玻尔兹曼机(deep Boltzmann machine, DBM)提取抽象离散特征,利用典型相关分析实现图像与标注词汇的映射关系,并在Corel5K实验中取得了较好的结果。
1 DBM-CCA算法
本文提出的自动图像标注算法——DBM-CCA,其基本思想是利用深度玻尔兹曼机逐层提取不同层次特征的优势,形成图像和标注词高层抽象概念,通过典型相关分析建立图像与标注词之间高层特征的相关关系,并采用典型变量空间投影法求得标注词汇抽象特征继而生成标注词汇。
DBM-CCA算法中包含两种DBM结构,分别为面向图像特征生成图像高层特征的图像深度玻尔兹曼机(image-deep Boltzmann machine, I-DBM)和面向文本特征生成文本高层特征的文本深度玻尔兹曼机(text-deep Boltzmann machine, T-DBM),其处理的对象分别为图像集合DI和标注词集合DT,本文算法结构如图1所示。
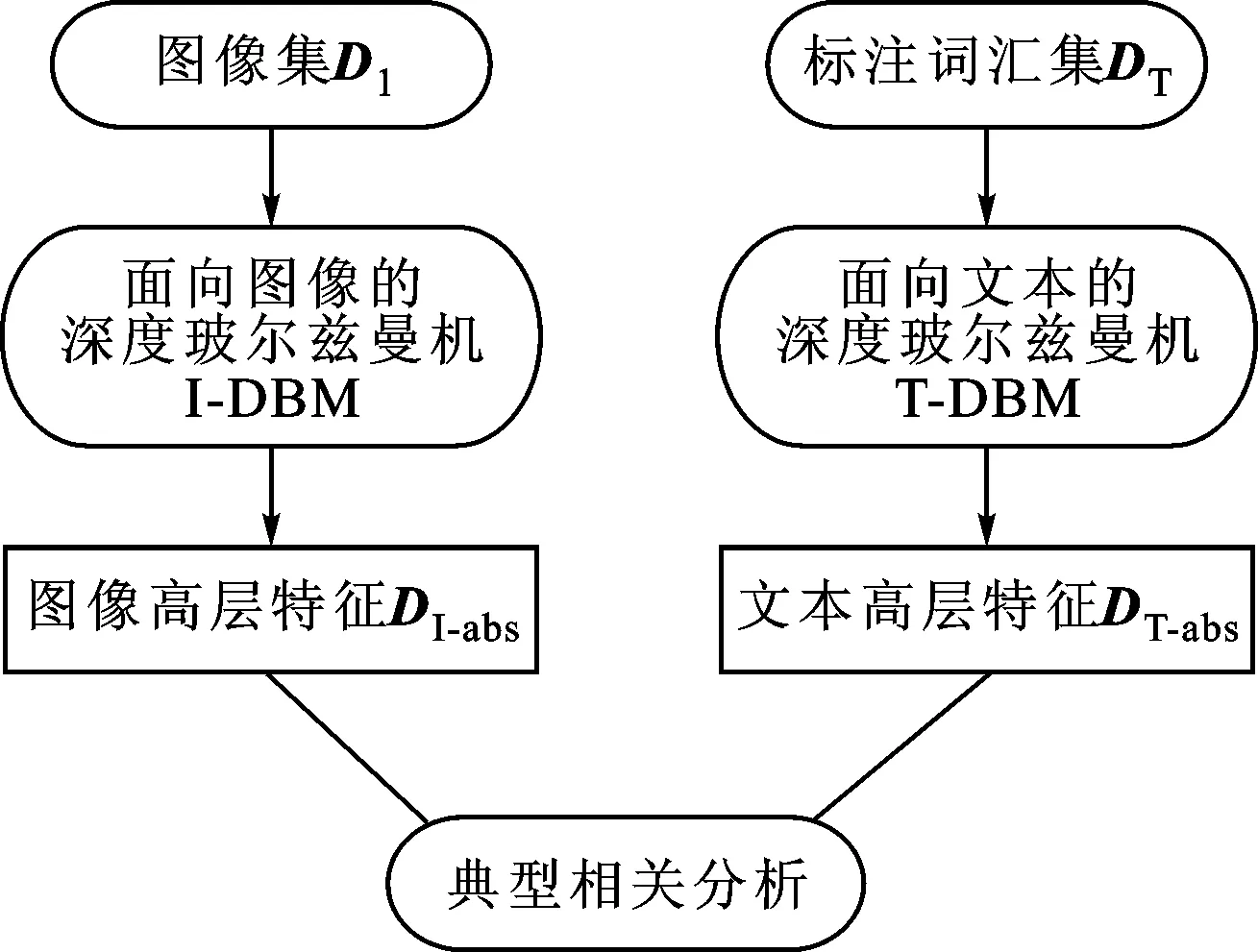
图1 DBM-CCA算法结构
1.1 基于DBM的高层特征提取
DBM是由Salakhutdinov提出的一种以RBM为基础的深度学习模型[13]。该模型不同于Hinton提出的深度信念网络(deep belief net, DBN)之处在于模型中各单元层间均为无向连接,省略了DBN中由上至下的反馈参数训练,同时使模型处理不确定性样本的健壮性更强。虽然DBM的训练时间略长,但是模型的数据泛化能力有所提高,且在多个公共训练集上的表现也优于DBN。
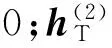
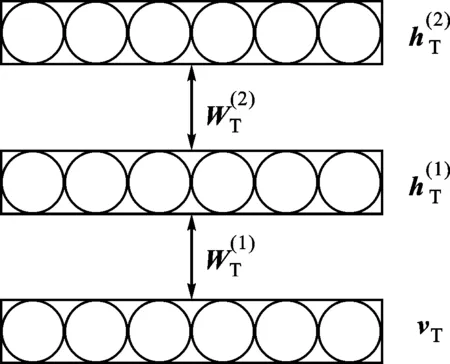
图2 3层T-DBM模型结构
T-DBM中可见单元vi的后验激活概率(vi对应的标注词汇出现的概率)为
(1)
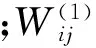
由于在图像标注任务中,通常限定图像的标注词汇个数N,因此在对图像进行标注时,待计算完成T-DBM中所有可见单元的后验激活概率以后,选取激活概率最高的前N个单词作为该图像的标注词汇。
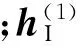
I-DBM中可见单元vi的后验激活概率为
(2)
1.2 典型变量空间
完成图像文本高层特征提取后,构建出图像高层特征集合DI-abs与标注词汇高层特征集合DT-abs。对DI-abs和DT-abs进行典型相关分析,建立典型变量空间的映射关系。以3元坐标系为例,DI-abs与DT-abs的坐标轴分别为XI-absYI-absZI-abs和XT-absYT-absZT-abs,XYZ为典型相关分析后形成的典型变量空间坐标轴,如图4所示。
从图4可以看出,通过典型相关分析,将DI-abs与DT-abs共同映射到了典型变量空间,从而使得稀疏高层次图像特征与稀疏二进制语义特征转变为同一个空间内的特征向量。对于包含N个训练样本的图像标注集合{(hI1,hT1),(hI2,hT2),…,(hIN,hTN)},hIi代表第i幅图像的I-DBM高层隐单元向量,维度为p;hTi代表对应的T-DBM高层隐单元向量,维度为q。图像标注集合分别构成两组大小为p×N和q×N的DI-abs、DT-abs。对两组矩阵DI-abs和DT-abs进行典型相关分析,将得到n组典型变量组{(ρ1,a1,b1),(ρ2,a2,b2),…,(ρn,an,bn)}(其中ρi、ai、bi(i=1,2,…,n)分别为CCA中的第i个典型变量相关系数),以及DI-abs和DT-abs对应的典型相关变量。定义AI=[a1,a2,…,an]、BT=[b1,b2,…,bn]作为hIi、hTi的投影变换矩阵。
2 图像标注流程
完成图像标注集的典型相关分析后,依据典型变量空间性质给出待标注图像的标注词汇预测方法。
2.1 投影法生成T-DBM高层特征
DBM-CCA采用典型变量空间投影的方式生成待标注图像的标注词汇:首先将图像高层特征依据CCA投影关系将其映射到典型变量空间中;然后在其空间内查找与之相邻的训练集图像,构成子集合DI-dis;最后依据距离远近,将DI-dis对应的标注词汇高层特征加权平均,构建新的文本高层特征。对于图像J={hI1,hI2,…,hIm;hT1,hT2,…,hTn},其中{hI1,hI2,…,hIm}和{hT1,hT2,…,hTn}集合分别为I-DBM、T-DBM的顶层隐单元组,则依据投影法生成T-DBM高层特征的步骤如下:
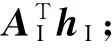
(2)在典型变量空间内查找与投影点近邻的图像样本,构成子集合DI-dis;
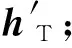
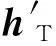
图5为DBM-CCA的图像标注流程,其中典型变量空间内黑色点代表训练集图像高层特征映射点,虚方框表示图像样本集合DI-dis。
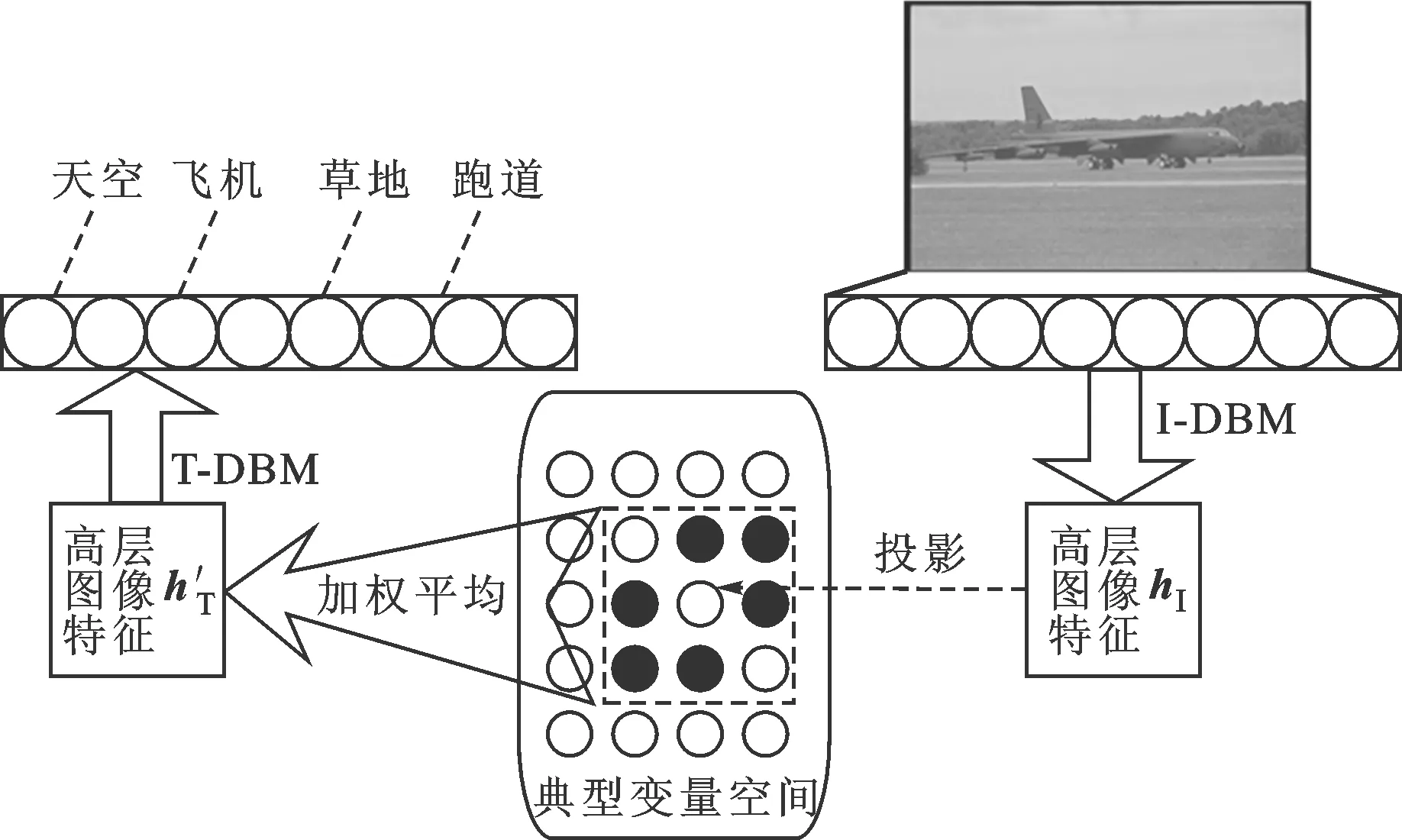
图5 DBM-CCA图像标注流程
(3)
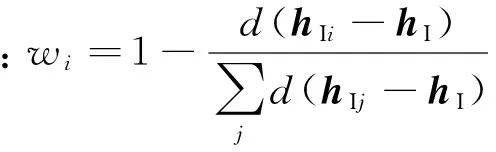
2.2 平均场估计
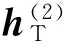
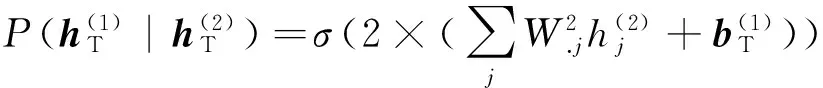
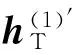
3 实验及分析
实验选用经典的自动图像标注测试集Corel5K图像集作为测试对象。选取5种视觉特征用于表征图像,分别为颜色直方图(特征向量维度为64)、边缘方向直方图(特征向量维度为73)、小波纹理(特征向量维度为128)、基于块的颜色矩(特征向量维度为225)和基于SIFT描述符的词袋模型特征(特征向量维度为500),则每幅图像由990维的向量代表,且每个维度均进行均值中心化处理。
为评估本文DBM-CCA算法在自动图像标注方面的性能,采用按照以标注词为单位的客观评价指标有:①平均查准率;②平均查全率;③查全查准均率F1为查全率与查准率的调和平均值,用于折中查全率与查准率,反映了标注算法的综合性能;④标注多样性值N+用以衡量正确标注词汇的多样性,数值为标注词出现频率大于0的次数。
实验设定:鉴于MBRM的时间开销过大,且SML模型过于复杂,因此在本文实验环境下没有进行对比实验,而是直接采用文献[14]的实验数据。本文实验设置了2种模型进行Corel5K数据集的图像标注效果对比,分别为DBM-CCA和多模态DBM,其参数设置如下(其中DBM的训练与文献[13]一致)。
(1)DBM-CCA: 设定I-DBM中可见单元数为990,第1隐单元层单元数为400,第2隐单元层单元数为400;T-DBM中可见单元数为374,第1隐单元层单元数为100,第2隐单元层单元数为100。
(2)多模态DBM: 设定以GRBM为底的DBM可见单元数为990,第1隐单元层单元数为400,第2隐单元层单元数为400;以RSM为底的DBM可见单元数为374,第1隐单元层单元数为100,第2隐单元层单元数为100;中间融合层隐单元数为400。
在DBM-CCA中选择不同参与典型变量组数和Msim的标注综合性能如图6所示。
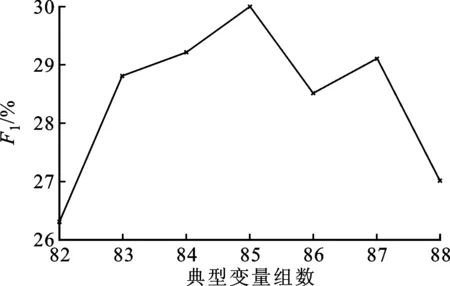
(a)Msim=2
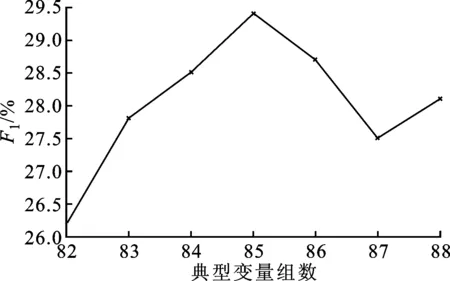
(b)Msim=3
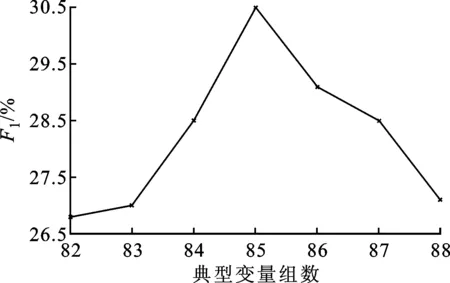
(c)Msim=4
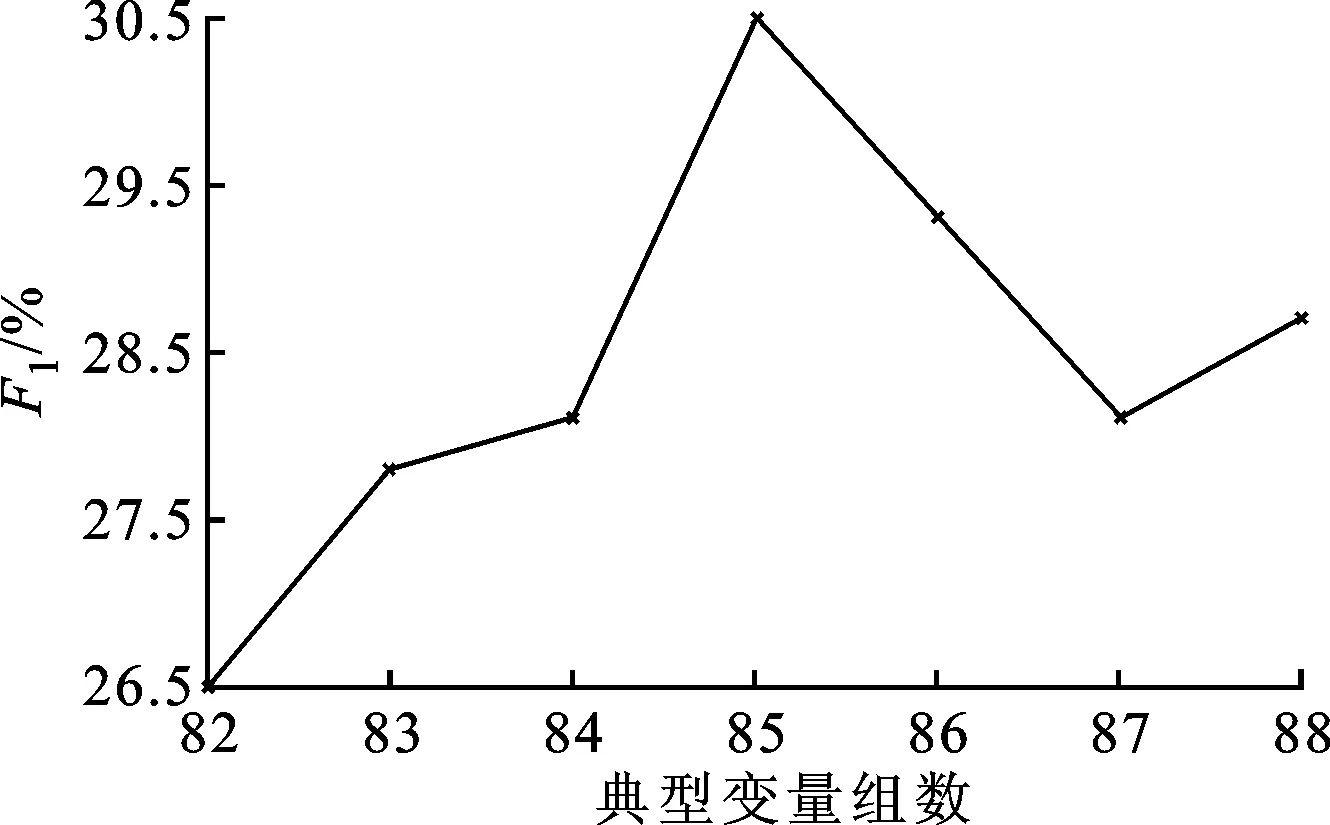
(d)Msim=5图6 不同参数下DBM-CCA算法的标注综合性能
从图6可以看出:在Msim相同的条件下,随着典型变量参与的数量增大,F1基本呈现出先增大后变小的趋势;当F1处于峰顶时,典型变量组数为85;当Msim=4时,F1值最大。从图6的实验结果可以看出,对于DBM-CCA算法中较为重要的两个参数——典型变量个数和Msim值,F1均存在峰顶,其原因在于,随着变量个数与Msim的增加,图像子集合DI-dis与待标注图像的总体相关程度增大,但平均相似度减小,同时DI-dis与待标注图像的多样化差异变大,从而使得待标注图像的标注不仅来自于训练集中相似的图像,也保证了一定的多样性。
4种模型在Corel5K实验的标注指标如表1所示。
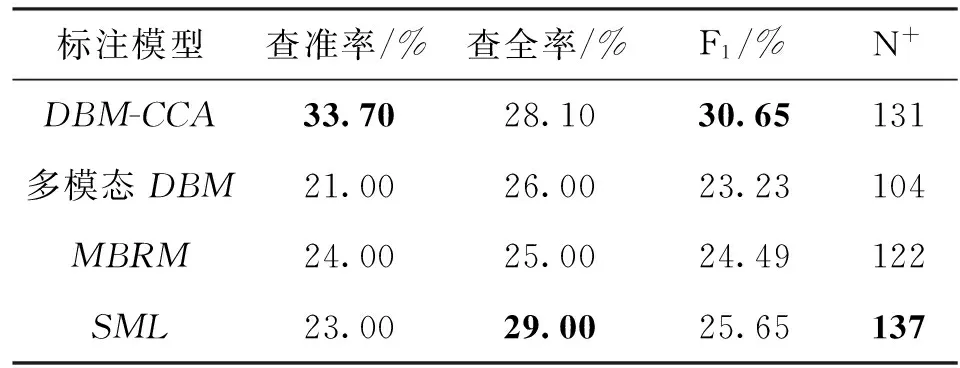
表1 DBM-CCA与其他算法的性能对比
注:黑体数据表示对应指标的最优值。
从表1中可以看出:DBM-CCA性能优于多模态DBM,体现在查准率和查全率分别提高了12%和2%;与MBRM相比,DBM-CCA的查全率提高了9%,并且查准率也略有提高,约为3%;与SML相比,DBM-CCA虽然在查全率和N+上略有不足,但在查准率上提高了10%左右。由此可以看出,DBM-CCA的优势主要体现在查准率上,同时对查全率也略有改善,其原因在于算法的主要参数Msim首先考虑的是图像子集合DI-dis的相似程度,其次通过典型变量个数与Msim的选择,改善了标注词汇与图像的多样性关系。鉴于DBM-CCA的标注过程仅需要有限个数的图像参与,其时间复杂度、空间复杂度均远远小于MBRM和SML。因此,当数据集越大时,DBM-CCA的标注效果和效率优势将越明显。
为更加形象地展示DBM与多模态DBM两种算法生成图像标注的效果,表2列出了在本实验中部分图像的标注示例,其中黑体词汇表示与人工标注相同。
表2 DBM-CCA与DBM标注示例
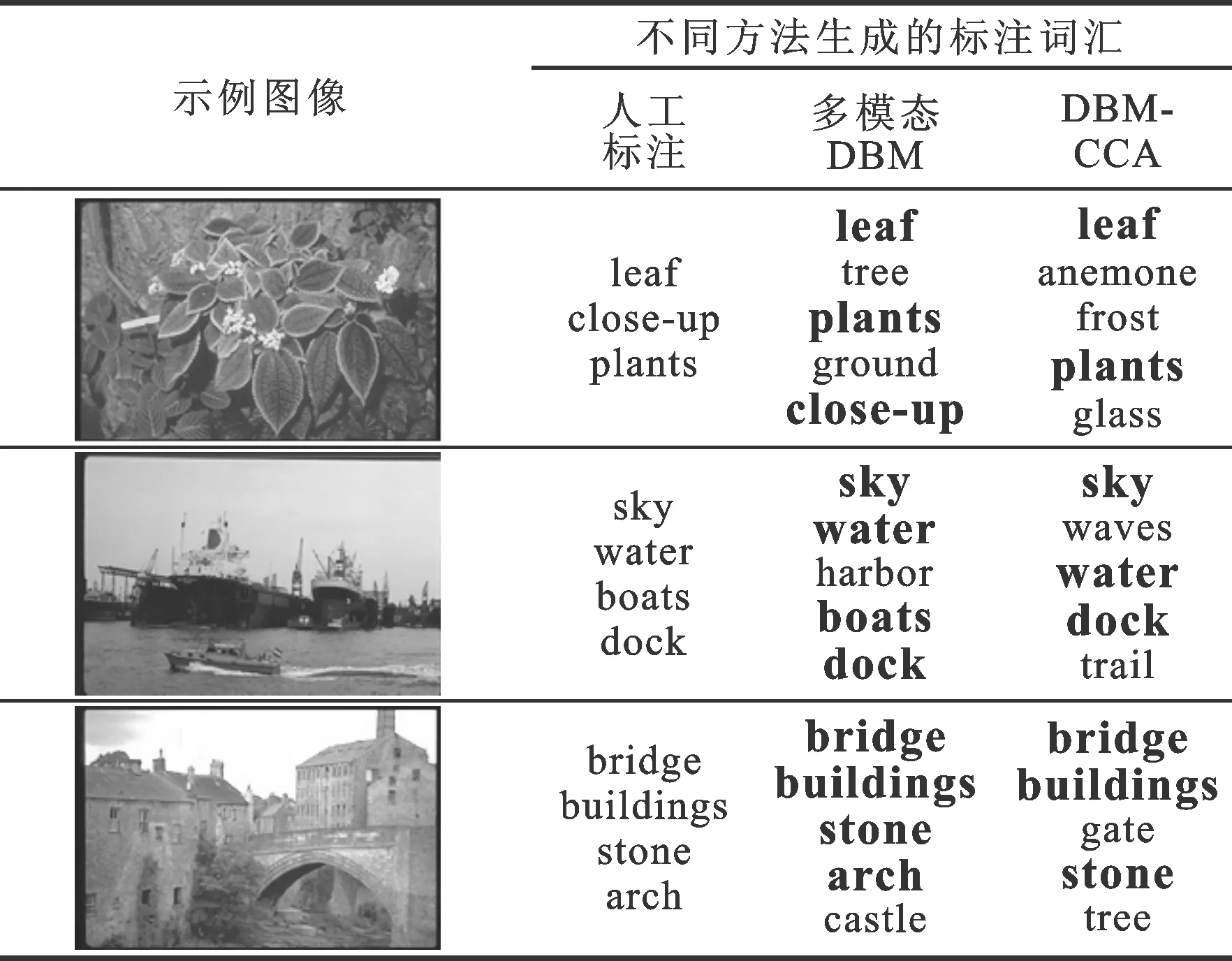
从表2中可以看出,DBM-CCA生成的标注词汇基本能够涵盖人工标注词汇,且相较于多模态DBM,DBM-CCA的标注更加准确。例如示例图像1添加的harbor和示例图像3添加的castle词汇,表明DBM-CCA能充分利用图像本身内容以完善人工标注结果。所以,DBM-CCA能够较好地完成自动图像标注任务,并对图像的语义信息也能提供较为准确的描述。
4 结 论
本文提出了一种基于DBM-CCA的自动图像标注算法,通过深度玻尔兹曼机实现图像、标注词汇高层抽象特征的提取,使用伯努利分布拟合图像的标注词汇数据,利用典型相关分析建立图像特征与标注词之间相关关系进行图像标注。Corel5K实验结果表明,本文所提出的算法在各个指标均优于多模态DBM,且能够通过算法参数的选择,改善标注词汇与图像的多样性关系,提高标注性能。
[1]LI Q, GU Y, QIAN X.LCMKL: latent-community and multi-kernel learning based image annotation [C]∥Proceedings of the 22nd ACM International Conference on Information & Knowledge Management.New York, USA: ACM, 2013: 1469-1472.
[2]QIAN X, HUA X S, HOU X.Tag filtering based on similar compatible principle [C]∥Proceedings of IEEE International Conference on Image Processing.Piscataway, NJ, USA: IEEE, 2012: 2349-2352.
[3]QIAN X, HUA X S, TANG Y Y, et al.Social image tagging with diverse semantics [J].IEEE Transactions on Cybernetics, 2014, 44(12): 2493-2508.
[4]NGIAM J, KHOSLA A, KIM M, et al.Multimodal deep learning [C]∥Proceedings of the 28th International Conference on Machine Learning.New York, USA: ACM, 2011: 689-696.
[5]OUYANG W, CHU X, WANG X.Multi-source deep learning for human pose estimation [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2014: 2337-2344.
[6]KIROS R, ZEMEL R, SALAKHUTDINOV R.Multimodal neural language models [J].Journal of Machine Learning Research, 2014, 32(1): 595-603.
[7]邱立达, 刘天键, 林南, 等.基于深度学习模型的无线传感器网络数据融合算法 [J].传感技术学报, 2014, 27(12): 1704-1709.
QIU Lida, LIU Tianjian, LIN Nan, et al.Data aggregation in wireless sensor network based on deep learning model [J].Chinese Journal of Sensors and Actuators, 2014, 27(12): 1704-1709.
[8]SRIVASTAVA N, SALAKHUTDINOV R.Multimodal learning with deep Boltzmann machines [C]∥Proceedings of Advances in Neural Information Processing Systems.Cambridge,MA,USA:MIT, 2012: 2222-2230.
[9]高军峰, 郑崇勋, 王沛.脑电信号中肌电伪差的实时去除方法研究 [J].西安交通大学学报, 2010, 44(4): 114-118.
GAO Junfeng, ZHENG Chongxun, WANG Pei.Electromyography artifact removal from electroencephalogram in real-time [J].Journal of Xi’an Jiaotong University, 2010, 44(4): 114-118.
[10]RASIWASIA N.A new approach to cross-modal multimedia retrieval [C]∥Proceedings of the 18 th ACM International Conference on Multimedia.New York, USA: ACM, 2010: 251-260.
[11]FENG F, WANG X, LI R.Cross-modal retrieval with correspondence autoencoder [C]∥Proceedings of the 22nd ACM International Conference on Multimedia.New York, USA: ACM, 2014: 7-16.
[12]GALEN A, RAMAN A, JEFF B.Deep canonical correlation analysis [J].Journal of Machine Learning Research, 2013, 28(3): 1247-1255.
[13]SALAKHUTDINOV R, HINTON G E.Deep Boltzmann machines [C]∥Proceedings of International Conference on Artificial Intelligence and Statistics 2009.Brookline, MA, USA: Microtome Publishing, 2009: 448-455.
[14]MAKADIA A, PAVLOVIC V, KUMAR S.Baselines for image annotation [J].International Journal on Computer Vision, 2010, 90(1): 88-105.
[本刊相关文献链接]
彭亚丽,刘侍刚,裘国永.一种线性迭代非刚体射影重建方法.2015,49(1):102-106.[doi:10.7652/xjtuxb201501017]
杨宏晖,王芸,孙进才,等.融合样本选择与特征选择的AdaBoost支持向量机集成算法.2014,48(12):63-68.[doi:10.7652/xjtuxb201412010]
符均,牟轩沁,季文博.亮色分离的饱和图像校正方法.2014,48(10):101-107.[doi:10.7652/xjtuxb201410016]
任茂栋,梁晋,唐正宗,等.数字图像相关法中的优化插值滤波器.2014,48(7):65-70.[doi:10.7652/xjtuxb201407012]
靳峰,冯大政.利用空间序列描述子的快速准确的图像配准算法.2014,48(6):19-24.[doi:10.7652/xjtuxb201406004]
(编辑 刘杨)
An Automatic Image Annotation Algorithm Using Deep Boltzmann Machine and Canonical Correlation Analysis
LIU Kai, ZHANG Limin, SUN Yongwei, LIN Xueyuan
(Research Institute of Information Fusion, Naval Aeronautical and Astronautical University, Yantai, Shandong 264001, China)
An automatic image annotation algorithm is proposed based on deep Boltzmann machine and canonical correlation analysis, named DBM-CCA.The algorithm utilizes DBM to transform low-level features of images and labels to sparse high-level abstract concepts, and builds subspace mapping relations by CCA in order to generate labels.The multiple Bernoulli distribution is used to fit labels and the Gaussian distribution is used to fit image features in the process of using DBM to extract high-level features of images and labels.CCA is used to establish relevant connection among image features and labeling words which form canonical variable subspace.High-level text features are calculated based on the Mahalanobis distance between images in canonical variable subspace, and image annotation words are generated by mean-field inference.Experimental results show that the proposed automatic image annotation method significantly outperforms both the traditional MBRM and the SML, and the precision ratio and recall-precision mean ratio are increased by 10% and 5%, respectively, in experiments with Corel5K image dataset.
automatic image annotation; deep learning; deep Boltzmann machine; canonical correlation analysis
2014-11-10。 作者简介:刘凯(1986—),男,博士生;张立民(通信作者),男,教授,博士生导师。 基金项目:国家自然科学基金资助项目(61032001)。
时间:2015-03-19
http:∥www.cnki.net/kcms/detail/61.1069.T.20150319.1153.003.html
10.7652/xjtuxb201506006
TP391.4
A
0253-987X(2015)06-0033-06
