改进证据分类合成方法在农作物生长环境评估中的应用*
2015-12-26叶继华聂小斯
叶继华 聂小斯
(江西师范大学计算机信息工程学院,南昌,330022)
改进证据分类合成方法在农作物生长环境评估中的应用*
叶继华 聂小斯
(江西师范大学计算机信息工程学院,南昌,330022)
针对传统D -S证据理论存在处理冲突证据的不足,基于证据间的相似度引入了信息熵属性,修正了证据分类属性,结合证据间相似度属性将证据集重新划分为可信度高证据、一般性证据和冲突证据,对分类的证据集赋予不同的重要性系数,并加以修正改进。改进后使得一般性证据和高冲突证据向可信度高的证据意见靠拢,最后利用D -S组合规则对于修正后的证据进行合成。针对农作物生长环境中多个传感器获取的数据构造其所对应证据的基本概率分配函数,利用模糊理论对基本概率分配函数进行取值。实验采用各类传感器测得的真实数据集进行实验,结果表明改进的方法既能够很好地解决冲突问题,同时能降低证据的不确定性。
证据分类;信息熵;信息融合
引 言
D -S证据理论[1]具有表达“不确定”的能力,能够在缺少先验信息的条件下处理不确定性问题。但其缺陷却也非常明显,在其证据冲突时,利用D -S组合规则会导致证据失效问题。为了克服D -S证据理论的不足,国内外一些知名学者陆续提出不少修正方法,但是文献[2]组合规则在处理低冲突证据的情况下,该组合规则比较可行。但随着证据的增加,证据都逐步地集中于不确定Θ集合,使得m(Θ)→1,这也意味着冲突证据不能提供过多的有效信息,从而该规则不具备一定的实用性。文献[3]在文献[4]的基础上利用相似度矩阵求解除证据所对应的权重,并通过权重求解加权平均取值,虽然经修正后,证据的抗干扰能力更强了,收敛速度更快了,但并不满足证据间的交换律以及结合律。文献[4]改进证据源的组合方法能够使信任度函数的收敛能力增强,但其仅仅是以相同的权重来进行计算的,其得出的结果也并不真实。文献[5]充分考虑了证据间的相识度,使结果更加可信,但未对证据自身信任度进行分析。文献[6]算法规则主要还是计算证据间两两冲突量的平均值来定义有效性系数,将总冲突按比例分为各个命题,但此方法是假定证据的可信度相同,这不合理。文献[7]主要利用证据间的相似度属性对证据集进行分类修正,并对于分类后的证据分别赋予不同的修正权值,降低证据间的冲突量,但其将所有不冲突证据的修正系数均赋为1,从而也导致结果并不精确。改进方法主要分为两类:(1)主要针对证据间的冲突重新分配。(2)主要针对证据的数据源进行修改。本文采用第二种改进方法,基于证据分类的合成算法,提出一种新的证据分类方法进行改进,之后再对各类分类证据集进行相应的权值调整,最后进行D -S融合。针对多个传感器获取的数据进行构造其所对应的基本概率分配函数是一个难点。本文利用模糊集理论能够处理不完整信息与知识的能力,结合粗糙集的数据离散化算法得到决策信息表,根据模糊隶属度函数对基本概率分配函数进行取值。结合农作物生长环境的实际应用情况,依据各类型传感器所采集到的真实数据,对农作物生长环境进行评估。
1 D -S理论和证据属性分析
定义1:辨识框架Θ,其辨识框架是关于其命题的相互独立可能命题的有限集合[1]。
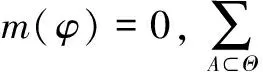
定义3:D -S规则组合式[1]:辨识框架Θ下两证据基本概率赋值(Basic probability assignment,BPA),m1,m2,则D -S组合规则为
(1)
式中:C∈2Θ,Ai∈2Θ,Bj∈2Θ;其中k表示证据之间的冲突概率
(2)
1.1 证据间相似度属性
在多传感器数据融合中,若其中某条证据被其他证据所支持程度大,可得该条证据可信度高,对融合结果的影响较大,反之,则影响较小。证据间相似度分析利用证据间的距离、冲突、夹角这几种属性进行。设识别框架Θ包含N个两两不同的命题的完备识别框架,E1和E2为Θ下的两个证据,其对应的基本概率分配函数为m1和m2,焦元分别是Ai和Bj,两证据之间的距离可以表示为
(3)
式中:D为一个2N×2N的矩阵,矩阵中的元素为
(4)
两证据间的夹角表示为
(5)
采用3个参数作为证据间相似度属性分类的一部分,主要在于任何一个参数都无法完整地衡量证据的相似度。本文基于证据分类算法,在证据间相似度属性基础上,引入证据自身信息熵属性,重新定义冲突证据、一般证据和可信度高的证据,并按照新的属性划分证据,并对冲突证据及一般性证据进行相应的修正,从而避免了证据划分的不准确性。
1.2 证据信息熵属性
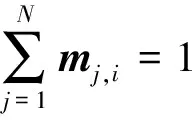
第i个证据的信息熵为
(6)
Ii(m)为证据mi的信息熵,信息熵反映了该证据中所包含信息量的大小。当某条证据的信息熵愈大,可信度越小,不确定也就愈大,反之信息熵越小,所获得不确定性也就越小,
2 基于信息熵的改进证据分类合成方法
在实际应用中,由于噪声、传感器的不稳定等干扰因素影响,证据自身也就存在一定的不确定。在数据融合过程中,每条证据的可信度权重并不完全一样,而仅仅基于证据间相似度并不能完全表征证据的综合可信度。为此利用信息熵的属性,对证据的自身可信度进行分析,将主观因素和客观因素相结合,综合考虑证据信息熵属性和证据间相似度,使一般性证据和冲突证据向可信度高的证据意见靠拢,从而进行更有效、更精确的融合。
2.1 证据间相似性属性计算
证据Ei与证据集E中其他证据的平均距离为
(7)
则证据集E间的平均距离为
(8)
同理求出证据Ei与证据集E中其他证据的平均冲突
(9)
证据集E间的平均冲突为
(10)
求出证据Ei与证据集E中其他证据的平均方向夹角为
(11)
证据集E间的平均冲突为
(12)
2.2 证据信息熵属性计算
根据信息熵属性的分析,其第i个证据的信息熵为
(13)
式中:j为目标;M为目标个数。证据集E的平均信息熵为
(14)
对于信息熵较大的证据,可以根据与平均证据比较的偏差,结合该证据的所有目标偏差,计算得出该条证据的标准偏差,再对信息熵较大的证据进行修正。
2.3 证据识别分类
本文利用证据自身的信息熵属性与证据间的相似度属性(距离、冲突量和夹角)将所有证据分为3类,分别是冲突证据、可信度高证据和一般性证据。冲突证据仅定义为在证据集中与其他证据相似度低(距离、冲突量均较大和夹角较小)且自身信息熵较小的证据。可信度高证据仅定义为除冲突证据外与其他证据相似度高(距离、冲突向量均较小和夹角较大)且自身信息熵相对较小的证据。一般性证据仅定义为信息熵较大的证据。
2.4 改进分类证据步骤
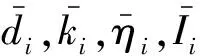
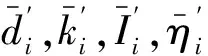
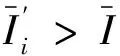
2.5 基于信息熵的原始证据修正
(1) 可信度高证据的修正方法。为了避免一票否决,若其可信度高证据中的焦元Ei满足Θ=∪Ei,则不需要做任何改进,直接融合。否则把不满足可信度高证据条件的证据归类为一般性证据和冲突证据。

(15)

(16)
则其偏差可以表示为
(17)
(18)
调整后证据为
(19)
式中:j=1,2,…,N。
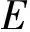
根据权值可信度分配函数调整公式,对冲突证据进行修正
(20)
经过式(20)调整,权值小的证据更多地倾向于权值大的证据。综合以上算法,利用式(14~18)对一般性证据进行修正,再对冲突证据赋予其修正系数,最后结合调整后的证据与可信度高性证据进行D -S算法规则融合。
2.6 实验测试与分析
实验通过Matlab仿真软件进行实验,并利用本文算法与文献[2-4]等的典型算例证据进行比较。已知识别框架Θ={a,b,c},5组证据E1,E2,E3,E4,E5均为单命题焦元,假设其基本可信度分配函数如下[8-9]
(21)
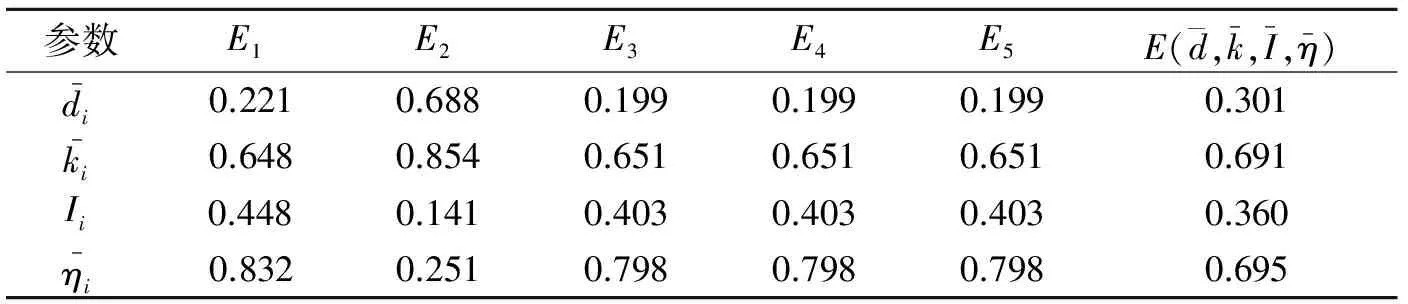
表1 证据集中的参数计算
修正算法对一般性证据和冲突证据进行修正,使得一般性证据向可信度高证据靠拢,并对冲突证据进行修正,从而达到更好的融合效果,对比如表3所示。由表3可知,D -S规则对于冲突的证据并不能达到有效的融合,整个融合过程m(a)=0,直接把a否定;文献[2]方法所得到证据m(a)=0且m(Θ)→1;

表2 非冲突证据集的参数计算

表3 几种典型改进方法比较
文献[4]规则能够识别目标,但精度并不最优;文献[6]算法规则虽然组合规则很好,但组合效率慢,需要多个证据结合才能得到不错的效果;文献[3]算法规则效果虽好,但其不满足融合的交换律和结合律;文献[9]算法规则考虑了证据的不确定性,但其通过加权后的证据来计算不确定性,带有一定的主观性;文献[10]算法规则并未对信息的可信度、不确定性加以考虑;本文同样对证据集进行3种类型证据划分,对于一般性证据,其自身信息量的不确定性较高,采用证据间的标准偏差对于其证据进行修正,并向可信度高的证据靠拢,而冲突性证据直接采用折扣系数修正的方法进行改进。综上所述对比实验结果,表明本文方法在识别目标时优于其他算法。
3 改进证据分类合成方法应用
本文以温室大棚中黄瓜为例,利用模糊理论和改进D -S证据理论对黄瓜的生长环境进行评估,以确定黄瓜环境的好坏。本文主要基于温室大棚对黄瓜生长环境评估的4种属性并结合改进的D -S证据理论的评估关系的融合模型。首先由样本数据根据粗糙集理论的数据离散化得到决策性信息表,其次根据模糊统计的隶属度计算出各传感器属性对应的基本概率分配函数。考虑到证据理论融合中的证据冲突问题,结合改进证据分类的合成算法,进行D -S融合,最终得到对于黄瓜生长环境的优良、一般、较差的属性评估。
实验通过各类型传感器采集的数据,结合Rosetta软件实现离散化处理,对于数据离散化,根据属性值由小到大顺序对决策表中实例进行排序,然后判断,对于两个相邻实例,在属性值和决策值都不同的情况下,选取两属性值的平均值作为断点值,从而为所有连续属性找到合适的断点集。其求解基本概率分配函数的具体过程如下:
(1) 首先需要对传感器测得的原始数据进行处理。假设输入M个不同信息源,样本取值N组,则该决策表应为N行,M+1列,其中决策表的M列代表条件属性,而最后一列代表决策属性。
(2) 对于输入的样本信息进行离散化处理,并最终形成决策表。
(3) 对比样本数据决策表,根据决策数据的取值,利用模糊统计法理论构建得到隶属度函数与基本概率赋值。
基于种植经验,以黄瓜结果期温度为实例,粗糙集离散化算法处理,分别得到4个属性证据的断点以及断点波动温度a,同理某时刻适宜的湿度b、土壤温度c,空气CO2浓度d,根据不同取值将连续区间离散化为定性区间:生长优良、生长一般、生长较差3部分。离散化后的决策表如表4所示。

表4 各属性决策一览表
对于D -S证据理论融合问题首要任务是如何有效地构造基本概率分配函数。而隶属度是指各种已知性能评价指标隶属于特定评价等级的概率,其能够对一个确定元素是否属于一个可变动的集合做出准确判断。因此,利用隶属度计算基本信任分配可以较好地处理模糊性及主观判断等问题。在隶属度的计算方法中,模糊统计法可以较直观地反映模糊概念中的隶属程度。
采用基于模糊统计法计算待评估的生长情况的基本信任概率分配函数,其可分为如下步骤:
(1)计算当前属性证据,待评估的生长情况为优良的数量与总的评估数量之比。得到该比值即为评估生长情况优良的隶属程度,可以表示为:u(A),同理利用模糊统计法,得到生长情况为一般和较差的隶属程度,分别表示u(B),u(C)。
(2)在基于获取的属性证据的基本概率分配函数,该取值等于隶属度为优良与隶属度为一般和较差的三者之和的比值,从而基本概率分配函数可以记作m(A),同理得到隶属度为一般和较差的基本概率分配函数,分别记作m(B)和m(C)。
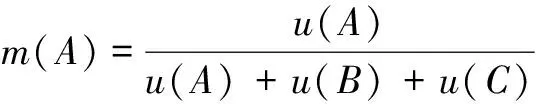
(22)
利用D -S证据理论,最终融合
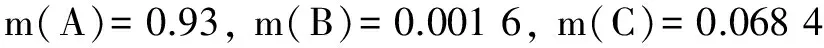
(23)
由以上计算过程可知,在无冲突证据的情况下,该修正方法相比原始D -S组合规则有一定的调整。而在产生冲突证据的情况下,基本概率分配函数如下所示
(24)
利用D -S证据理论,最终融合结果对比如表5所示。由以上步骤,可以由黄瓜生长的4种生长属性,根据模糊统计试验方法获取到隶属度函数,再接着获取属性下证据的基本概率分配函数,隶属度为生长优良与隶属度为优良、一般和较差三者之和的比值。由此方法,可获取多传感器以各自属性为标准判定目标的基本概率分配函数,从而为实际应用的评估决策打下坚实基础。
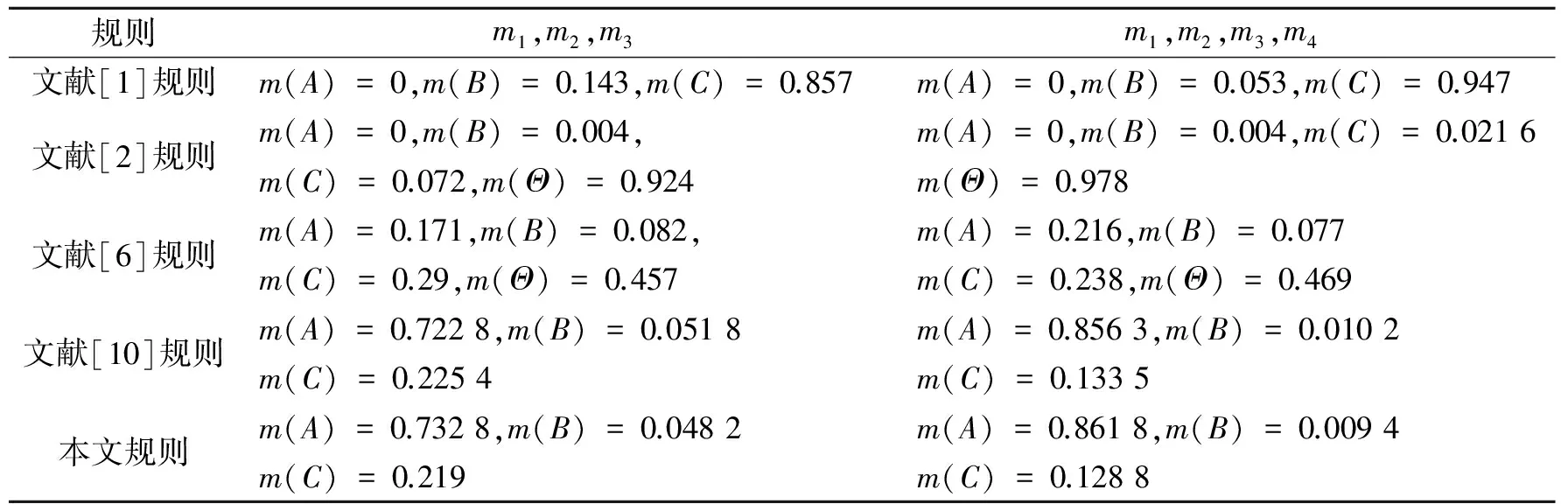
表5 实际黄瓜生长环境评估的对比
4 结束语
本文利用基于温室大棚对黄瓜生长环境评估的4种属性并结合改进的D -S证据理论的评估关系融合模型,最后结合D -S组合规则融合。改进的算法更好地解决了证据间的高冲突悖论问题以及不确定问题,在温室大棚黄瓜的生长评估中起到更好的决策作用,并对于农作物产量的提高具有极大的意义。
[1] Dempster A P. Upper and lower probabilities induced by a multi-valued mapping[J]. Annual Math Statist,1967,38(4):325-339.
[2] Yager R R. On the Dempster-Shafer framework and new combination rules[J]. Information Science,1989,41(2):93-137.
[3] 邓勇,施文康.一种有效处理冲突证据的组合方法[J]. 红外与毫米波学报,2004,23(1):27-32.
Deng Yong,Shi Wenkang ,Efficient combination approach of conflict evidence[J]. J Infrared Millim,2004,23(1):27-32.
[4] Murphy C K. Combining belief function when evidence conflicts[J]. Decision Support Systems,2000(29):1-9.
[5] 刘希亮,陈桂明,李方溪.基于距离测度的证据合成方法[J].数据采集与处理,2014,29(1):121-125.
Liu Xiliang,Chen Guiming,Li Fangxi. Approach to evidence combination based on distance measurement[J]. Journal of Data Acquisition and Processing,2014,29(1):121-125.
[6] 孙全,叶秀清. 一种新的证据组合规则[J]. 电子学报,2000,28(8):117-119.
Sun Quan,Ye Xiuqing. A new combination rules of evidence theory[J]. Acta Electronica Sinica, 2000,28(8):117-119.
[7] 彭颖,沈怀荣,马永一.一种新的冲突证据融合方法[J].兵工学报,2011,32(1):79-85.
Peng Ying,Shen Huairong,Ma Yongyi. A new fusion method for conflicting evidence[J].Acta Armamentarii,2011,32(1):79-85.
[8] 战红,谭继文,薛金亮.基于信息熵与判断矩阵的D -S证据理论改进方法在故障诊断中的应用[J].北京工业大学学报,2013,39(8);1140-1143.
Zhan Hong,Tan Jiwen,Xue Jinliang.Application of an improved D -S evidence theory based on information entropy and evaluation matrix to fault diagnosis[J]. Journal of Beijing University of Technology,2013,39(8);1140-1143.
[9] 熊彦铭,杨占平. 基于模型修正的冲突证据组合方法[J]. 控制与决策,2011,26(6):883-887.
Xiong Yanming,Yang Zhanping.Novel combination method of conflict evidence based on evidential model modification[J].Control and Decision,2011,26(6):883-887.
[10]王亮,吕卫民,滕克难,等.基于分类修正的多证据合成方法[J].控制与决策,2015,30(1):125-130.
Wang Liang,Lü Weimin,Teng Kenan,et al. Combination method of multi-evidence based on classification correction[J]. Control and Decision,2015,30(1):125-130.
Improved Evidence Classification Synthetic Method in Environment Assessment of Crop Growth
Ye Jihua,Nie Xiaosi
(Computer Information Engineering College, Jiangxi Normal University, Nanchang, 330022, China)
Considering traditional D -S evidence theory deficiencies existing in dealing with conflict evidence,the information entropy attribute is put forward based on the similarity between each evidences, which fixed the evidence classification properties. Combining the similarity attribute between each evidences, the evidence set could be divided into high credibility evidence, general evidence and conflict evidence. The sorted evidence set is given different importance coefficients, and is modified to improve. After modifying, the general evidence and high conflict evidence are closed to the high credibility of evidence opinions. Finally, D -S combination rule is utilized to synthesis for the modified evidence. It is difficult for obtaining data by multiple sensors to establish the basic probability distribution function for the evidence. For the problem, making full use of the ability that rough set theory can deal with incomplete information and knowledge, the decision information table is obtained via the attribute reduction of rough set. The function values are assigned for the basic probability by the decision information table. Combining the rough set and the improved D -S evidence theory, the real data sets are measured by all kinds of sensors.The experimental results show that the improved method can not only effectively solve the conflict problem, but also reduce the uncertainty of evidence.
evidence classification;information entropy; information fusion
国家自然科学基金(61462042)资助项目。
2015-05-06;
2015-06-26
TP301
A

叶继华(1966-),男,教授,研究方向:物联网技术,E-mail:yjhwcl@163.com。

聂小斯(1991-),男,硕士研究生,研究方向:物联网技术。
