交叉验证K近邻算法分类研究*
2015-12-26汪庆华刘江炜张兰兰
汪庆华,刘江炜,张兰兰
(1.西安工业大学 机电工程学院,西安710021;2.中国石油大学 理学院,北京102249)
1 K近邻算法
1.1 K近邻原理
KNN算法最早由Cover和Hart提出[7],早期研究中多被应用于文本分类.原理是对于一个待分类的样本x,计算它与训练样本集中所有样本的相似度,根据相似度找出K个与x样本最为相似的训练样本,然后依据这K个样本的最普遍的类标记作为预测值赋给待分类样本x.
KNN分类方法是依据周围有限的邻近的样本,而非判别类域的方法来确定样本所属类别,因此,对于类域的交叉或重叠较多的样本集来说,KNN方法较其他分类方法更为适合.
1.2 算法的实现
传统KNN算法使用欧氏距离为相似性度量,认为各维度特征向量权值相同[8-9].其算法的实现步骤为

②K的设定,一般采用先定一个初始值,然后根据实验测试结果进行调整.这里K初始取3.
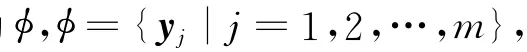

④ 对测试样本yj,在训练集中找出与yj距离最近的K个样本,用x1,x2,…,xk,表示.设离散的目标函数(分类问题)为f:Rn→ci,ci表示第i个类别标签.
3.4 个体化系统管理模式提高母乳喂养率 观察组产妇在产后半小时给予早接触、早吸吮,产后4 h给予乳房按摩催乳,及母乳喂养的指导,结果显示,观察组产妇泌乳始动时间明显早于对照组,差异有统计学意义。产后24 h体内血清PRL水平明显高于对照组,差异有统计学意义。从而为泌乳奠定了基础,保证了围产期的泌乳量,提高了母乳喂养率[13]。本文观察组产后42 d纯母乳喂养率明显高于对照组,差异有统计学意义。
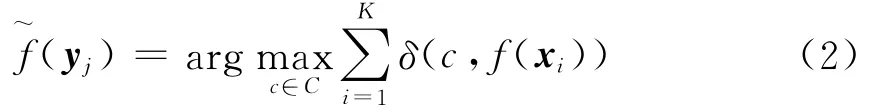
当a=b时,δ(a,b)=1;否则,δ(a,b)=0.
1.3 算法的评估
KNN算法是一个类比分类的过程,其评估方法有多种[10-11],其中常用的有平均查全率、平均查准率、宏平均、微平均、宏F1测量值、平均正确识别率、平均拒识率、误识率等.
当引入拒识个数时,评估方法将相应需采用平均拒识率,平均正确识别率和误识率进行评估.本实验中引入了拒识个数,所以将采用平均正确识别率,平均拒识率和平均误识率进行结果评估.其方法为设H为测试样本总数,其中H=Ha+Hb+Hc.Ha表示正确识别的样本个数(包含分类器判别为正例的正例个数和分类器判别为反例的反例个数),Hb表示识别为分类错误的个数;Hc表示拒绝识别的分类个数;设Rc为正确识别率,则Rc=Ha/H;设Rw表示误识率,则Rw=Hb/H;设Rr表示拒识率,则Rr=Hc/H.
2 交叉验证K近邻算法
2.1 原 理
交叉验证是常用的模型精度测量方法,是用来验证分类器的性能一种统计分析方法,在模型的可靠稳定性评估方面,它的简洁性和普遍性被认为是一种行之有效的办法,尤其是在可用的数据较少的情况下,通过对数据的有效重复利用,来测定模型精度的稳定性.交叉验证思想为[12]把在某种意义下的原始数据进行分组,一部分作为训练集,另一部分作为验证集,用训练集对分类器进行训练,再利用验证集来测试训练得到的模型,以此来做为评价分类器的性能指标.应用中常见交叉验证形式有Holdout验证,L折交叉验证和留一验证.
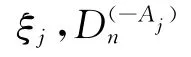
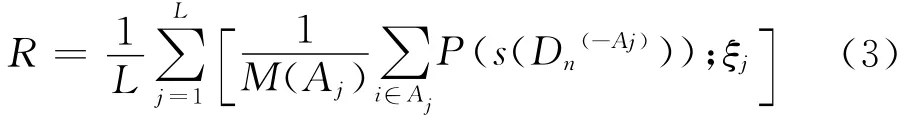
式中:P为损失函数;s为训练得到的模型.
本次实验将L折交叉验证方法和KNN分类方法进行结合并应用于模式识别,在提高模型稳定可靠性的基础上检验这种方法在模式识别应用中的准确率.其中交叉值L取5,即数据集被平均分为5份,选取一份作为测试集,剩下的4份作为训练集,共进行5次交叉实验,最后对5次交叉验证的结果取平均,得到的评估结果均为平均值.
2.2 算 法
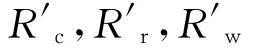
由于采用了交叉和平均的思想,通过交叉验证K近邻算法得到的评估结果可以提高评估的稳定性和可靠度.
对于最大K近邻个数的选取,如果K值等于训练集大小,则无论测试集是什么,都会识别为训练集中最多的类.这时的结果完全忽略了训练集中大量有用信息,不可取.所以,取训练集总大小的2/3作为最大K值应用于算法当中.对于λ的选取,可根据所取最大K值和要取的总K近邻个数综合考虑后选定.
3 仿真分析
3.1 UCI数据集的构建
UCI数据集是一个常用的标准测试数据集[13].本次测试调用了数据库中10个数据集进行研究,分别为 australian,breastcancer,diabetes,glass,heart,iris,letter,phoneme,satimage,wine.其数据相关信息见表1.
3.2 结果与分析
此次算法测试在4G内存,AMD Athlon(tm)ⅡX4 641Quad-Core Processor 2.79GHz以及win7Sever上进行,采用 Matlab 2012a软件编程实现.在结果分析中不可能将样本周围近邻个数依次尽数取完,这就要求挑选几个代表性K值反映出随K值变化时分类器的识别效果,为此,须确定最优K值间隔.经交叉验证K近邻算法,计算得到平均识别率,如图1所示;算法评估结果见表2.
从图1中发现K值间的间隔不能选取过密,否则只会反映局部变化趋势;选取过疏,不能反映变化趋势中的细节.在一般稳定性评估中,选取代表性特征量值时,一般是按照先密后疏的时间顺序安排的[14-15].另外,当预计变化规律随特征量值变化为递减型时,则测试间隔可先密后疏,反之,测试间隔可先疏后密.根据识别率要求依据“前密后疏”原则选取10个不同的K值进行结果分析.随着K增大,识别率随之提高,之后随着K的进一步增大,识别率趋于稳定的波动.但其中glass,iris,letter,phoneme,satimage 5组数据集上发现,随着K的进一步增大,识别率出现下降趋势较明显.为分析原因,须对这几组数据集内部分布情况进行分析.数据集iris,glass,phoneme,satimage的分布图如图2所示.

表1 实验所用UCI数据集Tab.1 UCI data set
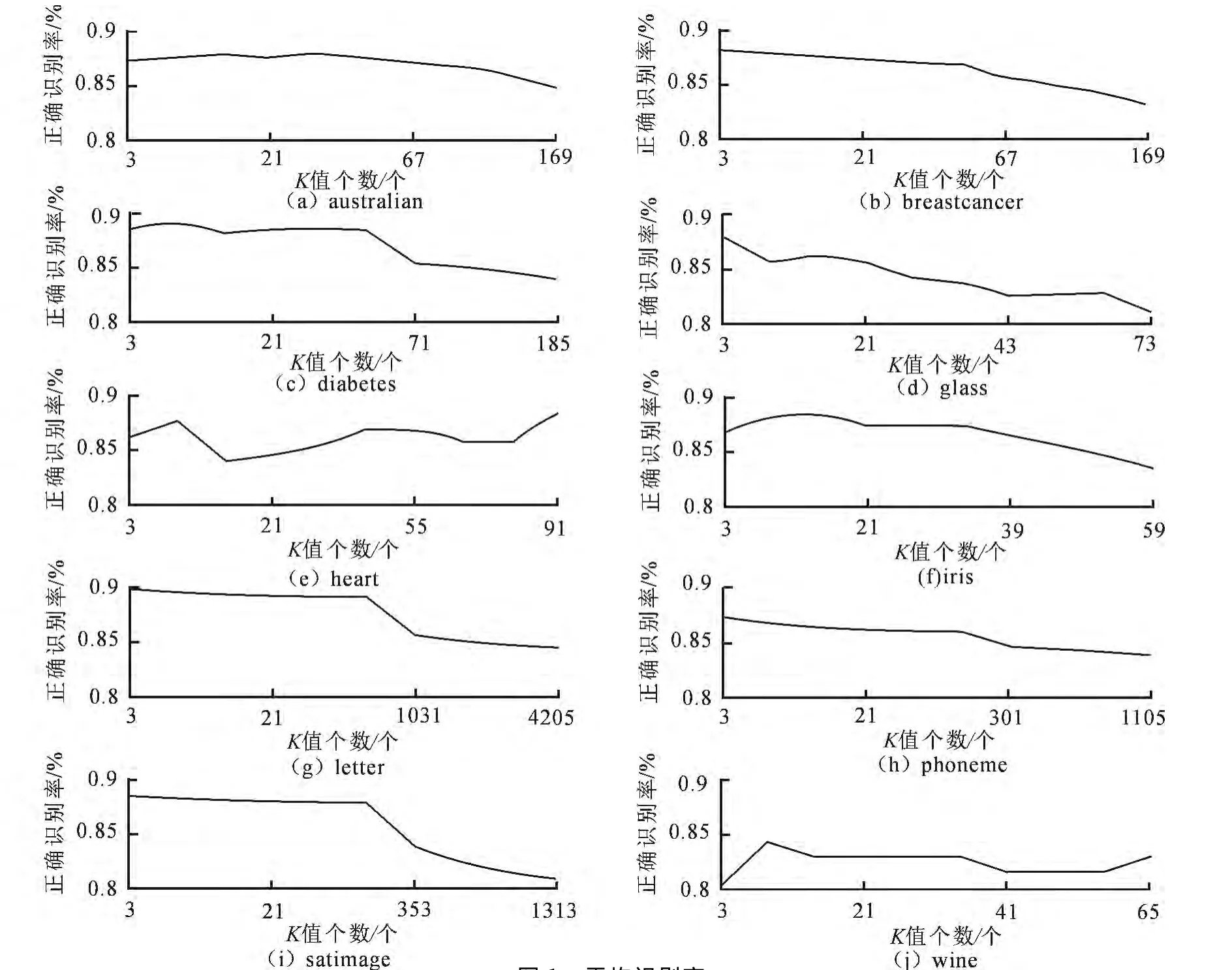
图1 平均识别率Fig.1 Average recognition rate

表2 算法评估结果Tab.2 The result evaluation
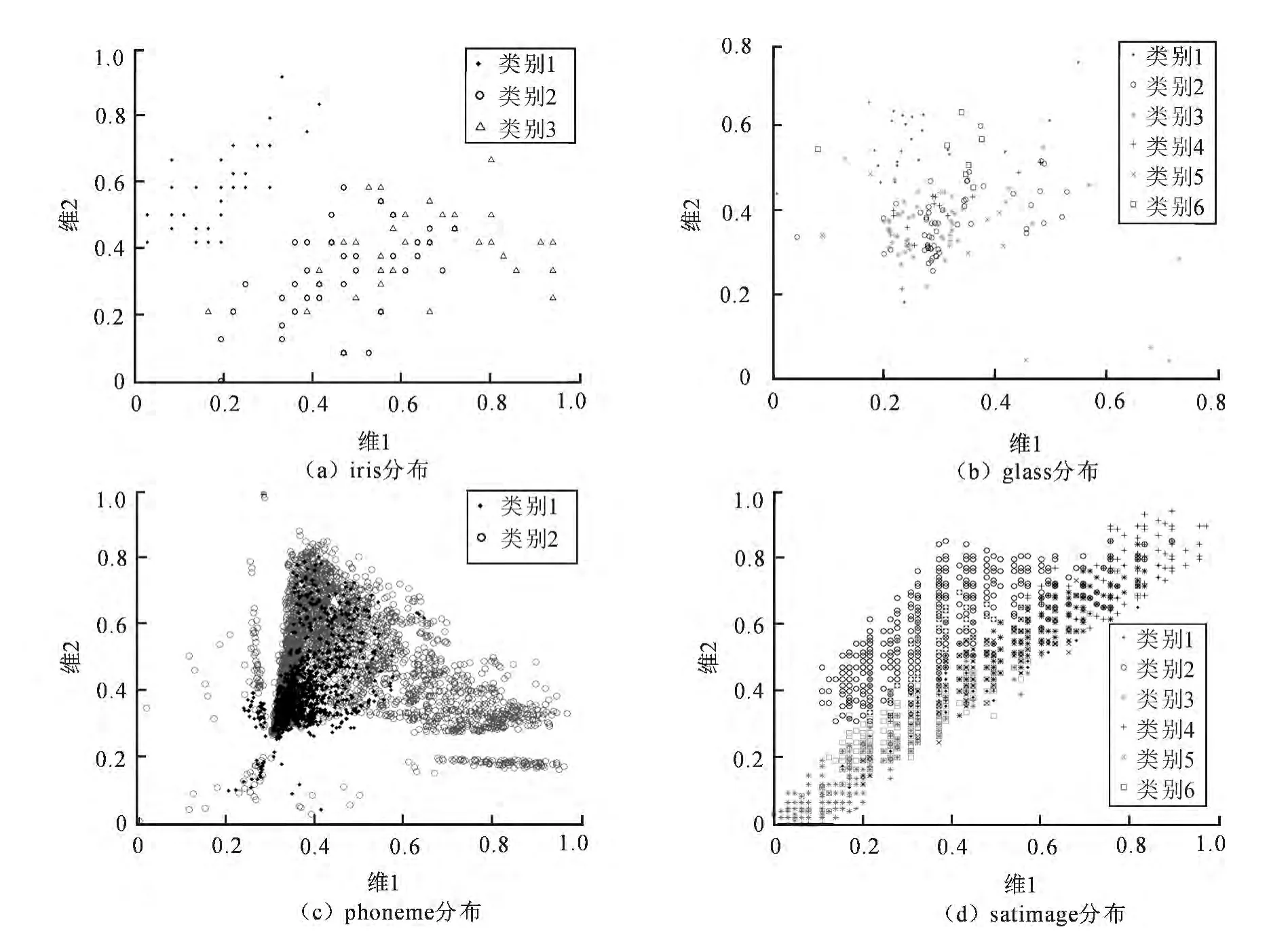
图2 数据集iris,glass,phoneme,satimage的二维分布图Fig.2 The two-dimensional distribution of UCI data sets
由于KNN算法中数据的各维数权重相同,具体二维分布图取数据集前两维数据,以代表各个样本属性.从图2可以看到4组数据分布中的每一个类,均分别存在噪音点,其中satimage中各类的噪音点已经混叠在其他类之中不太显现.
从表2可以发现,每个UCI测试数据集在特定的K值时,经交叉验证K近邻算法计算后,平均识别率较时频分析识别算法高,最低误识率较低,且最低平均拒识率都为0.这说明此时的K值在向理想的K值靠近.
通过以上分析,可以发现K值与分类结果有如下关系:当K取值较小,则从训练样本集中获得的分类信息越少,样本得到的近邻数过少,本该归属的最优类的近邻训练样本没有包含进来,则KNN算法的分类精度也相对较低.在一定范围内,KNN算法的分类精度会随着K值的增加而逐渐增加,直到适合的K个近邻时分类精度达到最好.当K值继续增大时,一些噪声数据(训练集各类别中的噪声)会不断增加进来,过多的近邻样本导致从训练样本集中获得的分类信息汇入大量噪音,进而降低分类识别率.
4 结 论
1)当测试数据集取为UCI时,在规定的K值取值区间内取不同K值时,拒识率均为0,正确识别率均大于70%,当K取最优K值时,正确识别率均在90%附近.
2)在规定的K值取值区间内,K值愈小,近邻数愈少,不能包含有用的训练样本,导致误识率增加;在规定的K值取值区间内,K值愈大,近邻数愈多,则噪声显著影响误识率.
3)通过交叉验证K近邻算法得到最优K值,使模式识别误识率达到最低.交叉验证K近邻算法为旋转机械故障诊断提供了一种新方法,特别在训练样本是多模式信息混叠的情况下效果显著.
[1] 夏均忠,苏涛,安相璧,等.滚动轴承故障模式识别方法现状分析[J].噪声与振动控制,2013,33(4):185.XIA Jun-zhong,SU Tao,AN Xiang-bi,et al.Review of Analysis Methods of Fault Pattern Recognition for Rolling Bearings[J].Noise and Vibration Control,2013,33(4):185.(in Chinese)
[2] 闫燕.数据挖掘在中国的现状和发展分析[J].科技信息,2014,2(5):292.YAN Yan.The Analysis of Current Situation and Development of Data Mining in China[J].Science and Technology Information,2014,2(5):292.(in Chinese)
[3] 钟智,朱曼龙,张晨,等.最近邻分类方法的研究[J].计算机科学与探索,2011,5(5):467.ZHONG Zhi,ZHU Man-long,ZHANG Chen,et al.Research on Nearest Neighbors Classification Techniques[J].Journal of Frontiers of Computer Science and Technology,2011,5(5):467.(in Chinese)
[4] 郭金玉,陈海彬,李元.基于在线升级主样本建模的批次过程KNN故障检测方法[J].信息与控制,2014,4(43):495.GUO Jin-yu,CHEN Hai-bin,LI Yuan.KNN Fault Detection Method for Batch Process Based on Principal Sample Modeling Upgraded Online[J].Information and Control,2014,4(43):495.(in Chinese)
[5] 刘凡,张昀,姚晓,等.基于K近邻算法的换流变压器局部放电模式识别[J].电力自动化设备,2013,33(5):89.LIU Fan,ZHANG Yun,YAO Xiao,et al.Recognition of PD Mode Based on KNN Algorithm for Converter Transformer[J].Electric Power Automation Equipment,2013,33(5):89.(in Chinese)
[6] 付文龙,周建中,李超顺,等.基于模糊K近邻支持向量数据描述的水电机组振动故障诊断研究[J].中国电机工程学报,2014,32(34):5788.FU Wen-long,ZHOU Jian-zhong,LI Chao-shun,et al.Vibrant Fault Diagnosis for Hydro-Electric Generating Unit Based on Support Vector Data Description Improved with Fuzzy K Nearest Neighbor[J].Proceedings of the CSEE,2014,32(34):5788.(in Chinese)
[7] 奉国和,吴敬学.KNN分类算法改进研究进展[J].图书情报工作,2012,56(21):97.FENG Guo-he,WU Jing-xue.A Literature Review on the Improvement of KNN Algorithm [J].Library and Information Service,2012,56(21):97.(in Chinese)
[8] 张宇.K-近邻算法的改进及实现[J].电脑开发与应用,2008,21(2):18.ZHANG Yu.Improvement and Implementation of K Nearest Neighbors Algorithm[J].Development and Application of Computer,2008,21(2):18.(in Chinese)
[9] 桑应宾,刘琼荪.改进的K-NN快速分类算法[J].计算机工程与应用,2009,45(11):145.SANG Ying-bin,LIU Qiong-sun.Improved K-Nearest Neighbor Classification Algorithm[J].Computer Engineering and Applications,2009,45(11):145.(in Chinese)
[10] 庄晶晶,张东站.基于KNN的多要素文本协调分类算法[J].研究与开发,2013,2(10):9.ZHUANG Jing-jing,ZHANG Dong-zhan.Multiple Elements Text Coordinate Classification Algorithm Based on KNN[J].Research and Development,2013,2(10):9.(in Chinese)
[11] 宋枫溪,高林.文本分类器性能评估指标[J].计算机工程,2004,30(13):107.SONG Feng-xi,GAO Lin.Performance Evaluation Metric for Text Classifiers[J].Computer Engineering,2004,30(13):107.(in Chinese)
[12] 胡局新,张功杰.基于K折交叉验证的选择性集成分类算法[J].科技通报,2013,129(12):115.HU Ju-xin,ZHANG Gong-jie.K-Fold Cross-Validation Based Selected Ensemble Classification Algorithm[J].Bulletin of Science and Technology,2013,129(12):115.(in Chinese)
[13] 刘天羽,李国正,尤鸣宇.不均衡故障诊断数据上的特征选择[J].小型微型计算机系统,2009,30(5):924.LIU Tian-yu,LI Guo-zheng,YOU Ming-yu.Feature Selection for Imbalanced Fault Diagnosis[J].Journal of Chinese Computer Systems,2009,30(5):924.(in Chinese)
[14] 王承中.实验室间比对的能力验证及稳健统计技术[J].理化检验,2004,40(10):533.WANG Cheng-zhong.The Proficiency Testing by Interlaboratory Comparisons and Robust Statistical Techniques[J].Physical Testing,2004,40(10):533.(in Chinese)
[15] 顾洪博,赵万平.数据挖掘算法性能优化的研究与应用[J].长春理工大学学报,2010,33(1):164.GU Hong-bo,ZHAO Wan-ping.The Research and Application for Optimization of Performance Based on the Data Mining Algorithm[J].Journal of Changchun University of Science and Technology,2010,33(1):164.(in Chinese)
