基于CRF和半监督学习的中文时间信息抽取
2015-12-23闫紫飞姬东鸿
闫紫飞,姬东鸿
(武汉大学 计算机学院,湖北 武汉430072)
0 引 言
在自然语言中,时间是重要的组成部分,是完整理解文章语义不可或缺的要素,在信息抽取中是一个比较重要的领域。对此进行研究,可以提高信息抽取的自动化水平,对机器翻译等人工智能领域的发展有很大促进作用。SemEval的评测中就包含时间信息的识别问题,SemEval-2013Task 1:TEMPEVAL-3 的任务中也有时间表达及时间关系的估计。目前时间信息抽取[1]的方法主要为基于规则的方法和基于机器学习的方法,一般认为,基本的时间短语都有着清晰的结构和明显的特征,通过构建完备的规则也可以覆盖到相当部分的时间信息,因此用基于规则的方法也能够表现出比较良好的效果。然而,一般的规则在处理复杂的时间信息时,不同规则之间会有一定的冲突。此外,基于规则的方法[2]在跨语言的时候,需要做一些额外的工作,比较费时费力。近年来随着标注语料库和标注工具的完善,基于机器学习的方法由于自动化程度较高、人工干预较少、移植能力比较强,开始流行起来。时间信息有显性和隐性两种,用规则的方法对时间信息进行抽取时,隐性时间的识别效果比较差,而且此方法的可移植性也不好,针对此问题,本文用统计的方法,采用条件随机场模型,利用半监督的训练,对时间信息进行识别研究,实验结果较好。
1 研究现状
时间表达的识别是开展相关时间关系推理、时间关联信息获取等应用的第一步,所以它是一种基础性的工作。Zacks认为可以通过时间的序列结构来理解事件,由此也凸显了时间识别的重要性。
在时间抽取的研究历史中,它经常作为命名实体抽取中的一部分来进行研究。在1998 年举行的MUC 会议上,首次将时间评测的要求加入到了命名实体识别的任务中[3],开了时间信息抽取研究的先河。2004 年ACE 在其子项目TERN (time expression recognition and normalization)中详细定义了时间表达式的识别评测,不仅要求识别出时间短语,而且还要对其语义进行处理,目标是以TIMEX2标注作为规范[4],分别对英文和汉语文本中的时间表达式进行识别,并进行解释。从其评测任务[5]可以看出,时间信息的抽取仍然是一个重要的研究课题。文献 [6]研究了命名实体的自动识别问题,分析了规则方法和基于统计模型识别方法的优缺点,并定义了一个中文时间框架,并制定了一个规则集,开发了一个分析器CTEMP,用于抽取和归一化中文时间短语。文献 [7]分析语料的时间关系识别时用及的各语言特征,提出了基于最大熵的方法。文献 [8]在时间识别问题中引入事件时间,通过复杂的语法分析和命名实体方法挖掘时间与事件的关系,但对包含多个事件的时间序列是不适用的。文献 [9]在基于CRF (条件随机场)的命名实体识别的实验中,对中文文本进行了原子切分,选取上下文特征、词性特征、词表外部特征等作为特征集来进行实体识别,取得了不错的结果。文献 [10]加入语义角色特征构建特征向量,然后采用CRF 进行识别。但是识别的效果不是太好。文献 [11]比较了现在流行的各种方法,证实了CRF 在命名实体识别领域中的良好效果。
2 分析模型
2.1 时间信息的分类
具体来讲,时间信息可分为显性时间信息和隐性时间信息。显性时间信息就是那种人们一看到就有比较明确时间概念的信息,是由人类通过自然界周期变化总结出来的一系列时间概念,如世纪、年、月、日、分、秒等。最简单的显性信息就是这些概念加上一些量词组成的,如:“2007年、4个月、36小时”等;然后这些简单时间信息通过任意组合,并加上一些:“前”、“后”、“从…到…”等介词或方位词就构成了复杂的时间信息,如:“2010年3月4日到7日”、“去年冬季前后”等。另外还有一些时间专有名词也属于显性这一类,比如:“春运期间”、“圣诞节”等等。可以看到,显性信息中,时间概念的特征比较明显,专有时间名词的数量有限,所以通过构建规则的方法和基于机器学习的方法都可以取得比较良好的效果。而隐性时间是诸如 “树木发芽”、“直到他做完功课”等隐藏在语义之中的信息,用规则很难全面覆盖,只能利用词性、词之间的关联和上下文等信息并通过统计学习的方法来识别。
2.2 工作准备
作者在以前参与的一个项目中,基于ontology的工具,曾建立过完备的时间词典库,并构建了一种基于迭代的规则方法,利用词典库,对时间短语进行抽取。在对结果进行的分析中,发现此方法对显性的时间短语识别效果还不错,即使是对开放语料的测试中,召回率和准确率都可达90%以上;而对隐性的时间的识别效果则比较差,召回率连80%都达不到。可以看到,时间信息特别是隐性时间信息的识别性能,还是有一定的提升空间的。所以,本文中利用统计学习的方法,基于CRF理论,通过对文本进行分词和标注,进行特征的提取,并结合半监督的训练方法,分别对显性时间、隐性时间和总体时间进行抽取,将结果与基于迭代规则的方法进行比较。
3 基于统计的时间识别及半监督学习
3.1 CRF介绍
如图1所示:以X= {x1,x2,……,xn}表示观测值序列,Y= {y1,y2,……,yn}以表示隐含的状态序列,则xi取决于产生它们的状态yi-1,yi,yi+1,图中的y1,y2,……等状态的序列还是一个马尔科夫链。在这个图中,顶点代表一个个随机变量,顶点之间的弧代表它们相互的依赖关系,通常采用一种概率分布,比如p(x1,y1)来描述,且每个状态的转移概率只取决于相邻的状态。整个条件随机场就是在给定观察序列条件下,计算整个标注序列的联合概率分布。在给定X 和Y 序列的条件下,线性链的CRF定义Y 的条件概率为
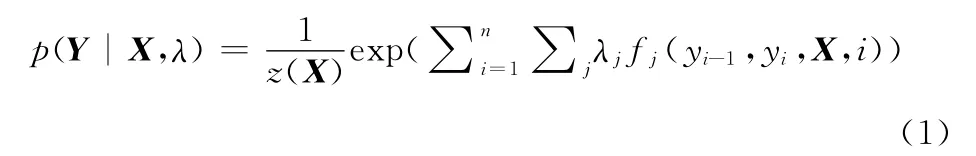
其中
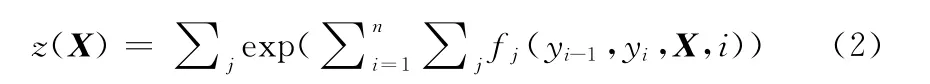
式 (2)是归一化因子,n 表示词序列的长度,fj(yi-1,yi,X,i)是特征函数,λj是第j 个特征函数的权重系数。
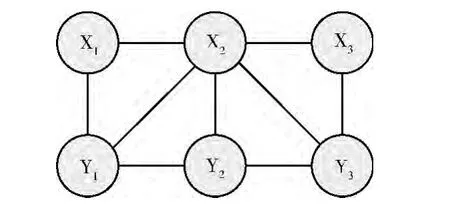
图1 一个普遍意义的条件随机场
时间信息识别问题可以转化为序列标注问题,其要求是在给定观察序列X 的条件下,估计产生标注序列y 的概率。而CRF模型可以轻易地将观察序列中的任意特征加入到模型中,从而较好的解决这一问题。
3.2 基于CRF的时间信息抽取
基于CRF的时间抽取模型如图2所示。
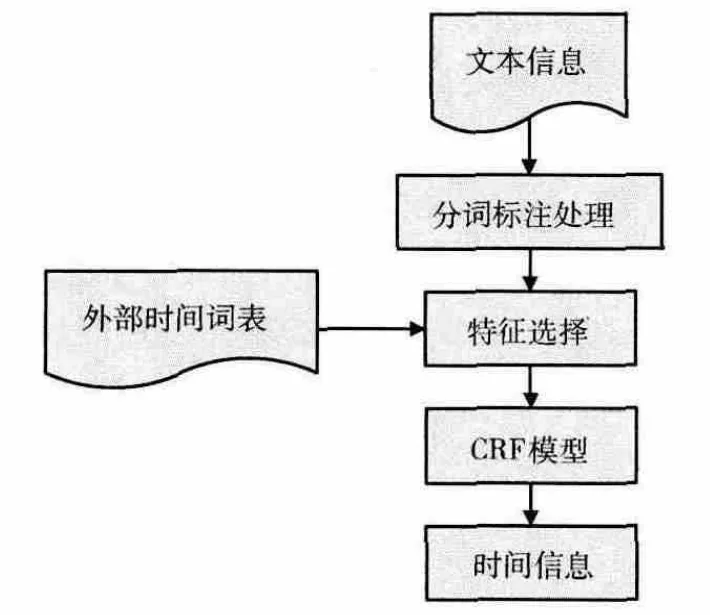
图2 基于CRF的时间抽取
3.2.1 分词和标注处理
在时间信息的识别中,为了充分利用词性和语义特征,分词是必不可少的环节。由于具有比较好的效果,作者使用中科院的ictclas分词工具对文本信息进行切词和词性标注[12]。文章使用B、I、O 标注方法来标记文本中的时间实体,句子中每个词的类型都是B、I、O 标注中的一种。如果一个时间序列由几个词组成,则B 表示第一个时间词,第二个以后的都用I表示,不是时间词的都用O 表示。例如:“昨天下午4点28分,十堰到武昌的火车到站”,标注为:“昨天/B 下午/I4点/I28分/I,/O 十堰/O 到/O 武昌/O 的/O 火车/O 到站/O”。
3.2.2 特征选择
CRF的训练中,最重要的是特征的选择,在此采用廖先桃等提出的特征模板,特征主要涉及词级特征,包括词、词性、词与其词性的组合和词的上下文特征等。
对时间信息的识别要依赖于时间触发词、时间词的前缀后缀和上下文关联词。根据语料的分词结果,通过程序和人工结合建立时间触发词表 (如:立即,当前,马上,等)、前缀词表 (如:直到,在,从,等)和后缀词表(如:左右,期间,之前,等)。除了这些词表外,我们还考虑词性、时间词的前词性特征、后词性特征,以及短语的位置特征,即该词是否在句首、是否在句尾等,这些特征见表1。我们将这些特征都抽取出来后,制作特征模板并用适当的工具训练生成模板文件。

表1 选取的特征
3.3 基于半监督的训练
统计机器学习方法的优点是智能化较高,人工干预较少,而相应的也面临着一些困难,主要就是训练数据不足,可用于命名实体研究的语料也比较缺乏,而且对于不同的领域,往往需要建立不同的语料库,比较耗时耗力,而且在时间上也不够效率。因此,本文采用了自训练 (selftraining),一种半监督的学习方法来有效利用大量的未作标注的未分类数据,从而提高时间识别在真实文本上的泛化能力。自训练的模式如图3所示。
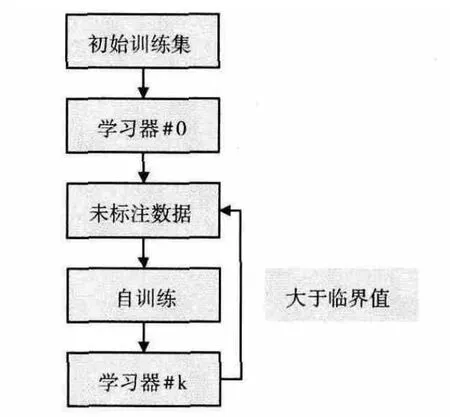
图3 自训练模式
采用的算法步骤如下:
输入:
初始训练数据集合Ds,未标注数据集合Dt,利用Ds训练出一个初始学习器#0,令i=0;
循环部分:用学习器#i对数据集合Dt进行预测,在预测结果中取置信度较高 (大于某一临界值)的数据为集合Dt’,令Ds=Ds+Dt’,Dt=Dt-Dt’,i++直到Dt’为空这一条件满足;
输出:
n个学习器#0、#1、…、#k…
每轮迭代可以得到学习器k 和新的标注数据集Ds,临界值需要在实验过程中根据预测结果的多少动态地计算求得,比如初始设定的临界值为t0,在实验过程中发现取得的数据集合Dt’过少,这样循环的次数就会无限大,在此情况下t0的值就需要设置为一个较小的数,反之则变大。这样经过n轮迭代后可以得到n 个学习器,对这n 个学习器进行组合形成最终的模型,在本次实验中我们采用选取所有的学习器给予相同的权重的方式。
4 实验结果与分析
4.1 工具及语料
本实验采用的语料来自2013年各个门户网站关于舆情部分的新闻,是用武汉大学自然语言处理实验室开发的专门处理舆情新闻的系统来抽取的。共选取了3000 篇语料,其中800篇进行了手工标注,标注结果见表2。在这800篇中,随机选择400篇作为最终的测试语料,其余400 篇和未标注的2200 篇总共2600 篇作为训练语料。CRF 使用CRF++0.58,使用Perl脚本conlleval.pl作为评测工具。

表2 语料标注结果
4.2 实验结果
实验结果采用计算精确率 (P)、召回率 (R)和Fmeasure(F1)值作为评测标准

实验分3组,分别对显性时间、隐性时间和总体时间进行实验。
4.2.1 规则抽取的实验结果
基于迭代的规则和词典相结合的方法,利用训练语料进行训练,使用其结果对规则和词典进行补充,最终对测试语料的实验结果见表3。
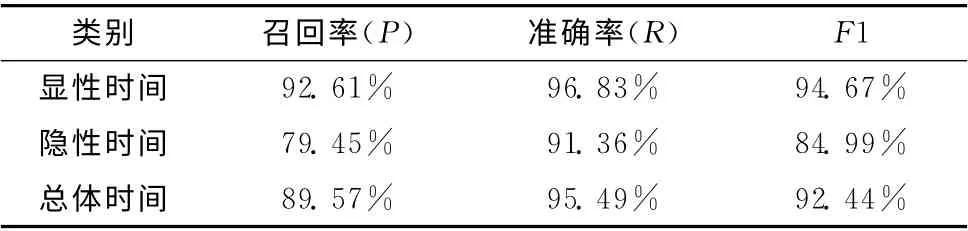
表3 基于规则的实验结果
从结果我们可以看出,规则的方法对于显性时间信息的抽取效果还不错,可以达到94.67%的F1值,但对于隐性时间,F1值只有84.99%,特别是召回率,连80%都没有达到,所以后续实验中,我们将重点关注隐性时间提升的效果。
4.2.2 半监督方法对时间信息抽取的性能提升
在2600篇训练语料中,以400篇的标注数据作为初始训练集,剩余2200篇为未标注数据,动态地计算临界值的办法,经过循环后,迭代退出得到7个学习器,分别对测试语料进行实验,得到的效果如图4~图6所示。
从图4~图6 可以看出,基于自训练模式得到的学习器,基本上在到达第4轮或第5轮迭代时,模型的性能达到最高,然后就在一个小范围的幅度内稳定地波动。同时也可以看到,性能的提升基本上只有1个百分点左右,是比较有限的,主要是因为CRF 特征选取的比较好的情况下,在对时间信息的抽取方面,原系统的性能已相当高,可提升的空间本来就有限。总体而言,半监督的训练对系统性能有一定的帮助。
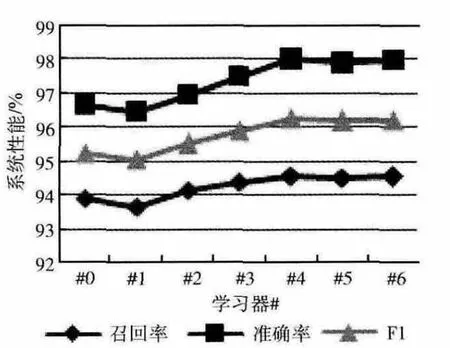
图4 显性时间抽取的自训练
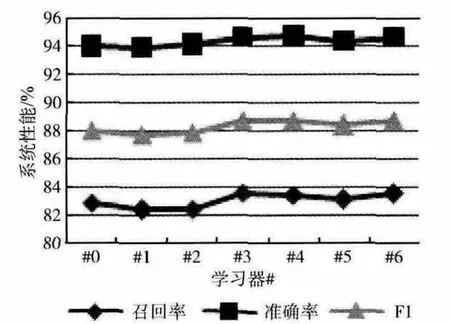
图5 隐性时间抽取的自训练
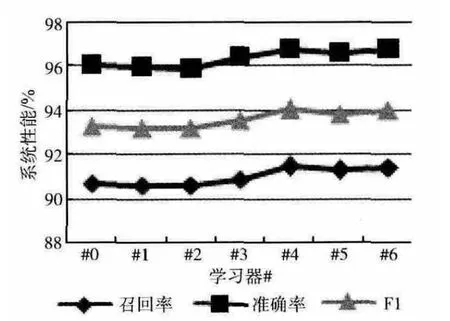
图6 总体时间抽取的自训练
4.2.3 性能比较
根据上一步得到的实验结果,我们对所有的学习器采用相同权重进行组合,即对于学习器#0、#1、#2、#3、#4、#5、#6分别给予1/7的权重,再对测试语料进行实验,最终得到的结果见表4。
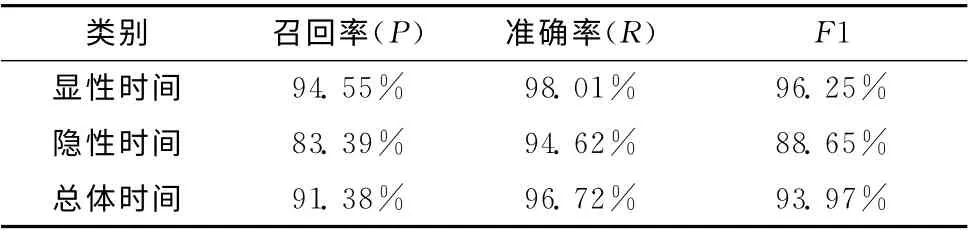
表4 自训练的组合方式的抽取结果
对比表3,我们发现,在显性时间的抽取方面,F1值略微有些提升;而对于隐性时间,F1值提升了将近4个百分点,效果还是很明显的;总体时间的F1 值提升的也不多,是因为语料中隐性时间所占的比重比较小。总体而言,自训练方法还是取得了不错的效果。
5 结束语
通过对中文时间信息的分类和时间信息抽取研究现状的分析,挖掘时间短语在文本中的语言学特征,引出了时间信息抽取的研究思路,确定了用CRF 的方法,利用BIO标注模式将时间识别问题转化为序列标注问题,并通过自学习这样一种半监督的方法对语料进行训练,最终通过对测试语料的实验,取得了较好的效果。对于显性时间的识别,由于F1 值已经达到了96.25%,所以提升余地比较小;而对于隐性时间的识别,还是有一定的提升空间的。下一步的工作主要为以下几个方面:①要进一步挖掘隐性时间的各种有效特征,对其进行研究和探讨,以最终提升总体时间的识别率;②改进半监督的学习方法,优化自训练的算法,以得到更好效果的学习器,并最终提升系统性能;③将此种基于CRF 和半监督训练的方法应用到地名、人名和组织名等其它命名实体抽取的工作中。
[1]Pawel Mazur,Robert Dale.A rule based approach to temporal expression tagging [C]//Proceeding of the International Multiconference on Computer Science and Information Technology,2007:293-303.
[2]ZHOU Xiaojia,ZHOU Qingli.The research on the extraction of temporal information from Chinese medical narrative records[C]//Zhejiang Province Ninth Annual Conference Proceedings on Medical Engineering Branch of Medical Association,2011:300-305 (in Chinese).[周小甲,周庆利.中文病历文本中时间信息自动标注 [C]//浙江省医学会医学工程学分会第九届学术年会论文汇编,2011:300-305.]
[3]Chinchor N,Brown E,Ferro L,et al.1999 Named entity recognition task definition version1.4 [EB/OL]. [2011-08-05].ftp://jaguar.ncsl.nist.gov/ace/phase1/ne99_taskdef_v1_4.pdf.
[4]Linguistic data consortium,ace(automatic content extraction)Chinese annotation guidelines for TIMEX2 [EB/OL]. [2009-12-08].http://www.ldc.upenn.edu/Projects/ACE.
[5]Past TAC (text analysis conference)data [EB/OL]. [2011-08-05].http://www.nist.gov/tac/data.
[6]JIANG Wenzhi,GU Jiaojiao,CONG Linhu.Research on CRF and rules based military named entity recognition [J].Command Control &Simulation,2011,33 (4):13-15 (in Chinese). [姜文志,顾佼佼,丛林虎.CRF与规则相结合的军事命名实体识别研究[J].指挥控制与仿真,2011,33 (4):13-15.]
[7]WANG Feng’e,TAN Hongye,QIAN Yili.Recognition of temporal relation in one sentence based on maximum entrooy[J].Computer Engineering,2012,38 (4):37-39 (in Chinese).[王风娥,谭红叶,钱揖丽.基于最大熵的句内时间关系识别 [J].计算机工程,2012,38 (4):37-39.]
[8]Li Fenghuan,Zheng Dequan,Zhao Tiejun.Event recognition based on time series characteristics[C]//Proceedings of Conference on Fuzzy Systems and Knowledge Discovery,2011:1807-1811.
[9]SHI Haifeng,YAO Jianmin.Study on CRF-based Chinese named entity recognition [D].Suzhou:Soochow University,2010 (in Chinese).[史海峰,姚建民.基于CRF的中文命名实体识别研究 [D].苏州:苏州大学,2010.]
[10]LIU Li,HE Zhongshi,XING Xinlai,et al.Chinese time expression recognition based on semantic role [J].Application Research of Computers,2011,28 (7):2543-2545 (in Chinese).[刘莉,何中市,邢欣来,等.基于语义角色的中文时间表达式识别 [J].计算机应用研究,2011,28 (7):2543-2545.]
[11]LIAO Xiantao.A study on Chinese named entity recognition[D].Harbin:Harbin Institute of Technology,2006 (in Chinese).[廖先桃.中文命名实体识别方法研究 [D].哈尔滨:哈尔滨工业大学,2006.]
[12]WANG Feng’e.Recognition of temporal relation in Chinese texts[D].Taiyuan:Shanxi University,2012 (in Chinese).[王风娥.汉语文本中的时间关系识别技术研究 [D].太原:山西大学,2012.]
