基于星形距离和LDCRF模型的在线行为识别方法
2015-12-23张玉燕马士林袁宇浩施晓东
成 立,梅 雪,张玉燕,马士林,袁宇浩,施晓东
(1.南京工业大学 自动化与电气工程学院,江苏 南京210000;2.哈尔滨工业大学 电气工程学院,黑龙江 哈尔滨150001)
0 引 言
目前在线人体行为识别技术[1]在一些方面已经取得了很大的进展,如文献 [2]利用移动设备的加速度计进行在线动作识别,文献 [3]通过人体的运动数据和相关地理位置信息特征进行在线行为识别,文献 [4]利用加速度数据和SVM 进行在线行为分类。人体行为识别研究的关键问题主要包括:①人体行为特征的选择。人们对人体运动特征描述提出了很多种方法,如光流法、轮廓法[5]、路径法和形状法[6]。②识别模型的构建。人体行为识别模型主要分为两类:基于产生式模型和基于判别式模型[7]。目前,HMM、CRF、HCRF[8]在人体行为识别中的运用已经很成熟。本文针对视频监控系统行为智能分析等需要,应用具有不变的特征和潜动态条件随机模型 (latent-dynamic conditional random,LDCRF),探讨了基于判别式模型的在线人体行为识别方法。通过星形距离来描述人体各姿态特征,利用LDCRF模型对行为数据进行建模、识别。
1 人体动作特征数据提取与处理
视频监控中的人体运动是非刚性的运动,人体运动姿态的空间尺度会随着时间尺度的变化而变化。因此选择合适的方法将具体的人体运动信息通过抽象数学参数表示出来,并保留人体动作信息,对接下来的人体行为识别十分重要。本文通过提取视频中的人体运动轮廓,计算轮廓质心到各轮廓采样点的星形距离,并对特征数据进行归一化和小波降维处理,从而得到用于识别的有效特征序列集合。
1.1 人体运动轮廓提取
利用背景减除法提取运动目标。背景减除法是一种有效的运动目标检测算法,利用背景的参数模型来近似背景图像的像素值,将当前帧与背景图像进行差分比较,对得到的前景点和背景点进行像素二值化,分割出运动目标,从而得到如图1所示的人体运动轮廓。

图1 人体运动轮廓
1.2 星形距离特征提取
轮廓特征是人体行为特征的一个重要表现,运动人体的特征提取是将视频序列中具体的人体动作用数学参数表示。对于运动特征的提取主要分为基于模型和基于非模型两种方法。本文在得到的人体轮廓上求取轮廓质心(xc,yc),并设置轮廓采样点,在人体轮廓上进行等间隔采样。从人体轮廓左上角的采样点顺时针计算轮廓采样点(xi,yi)到质心(xc,yc)的距离dci,从而得到N 维特征向量d =[dc1,dc2,…,dcN],即如图2所示的星形距离特征。
求取轮廓质心和轮廓质心到轮廓采样点的距离的公式如下
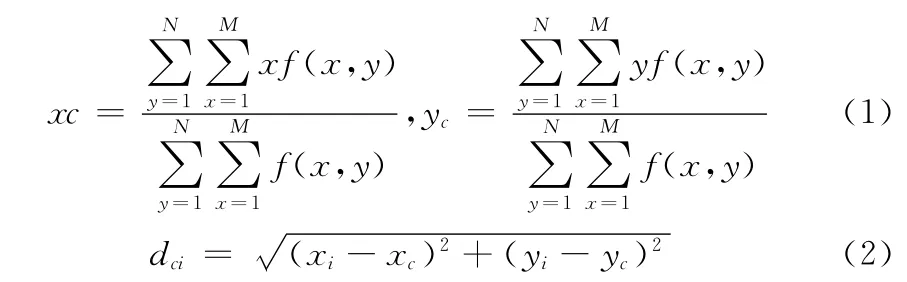
由于得到的N 维特征向量的空间尺度很大,为了确保其具有不变性,使用式 (3)对其进行数据归一化处理,以消除空间尺度对不变性的影响
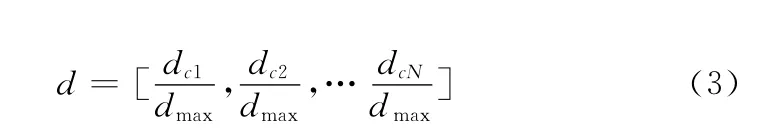
其中,dmax=max{dc1,dc2,…dcN}。
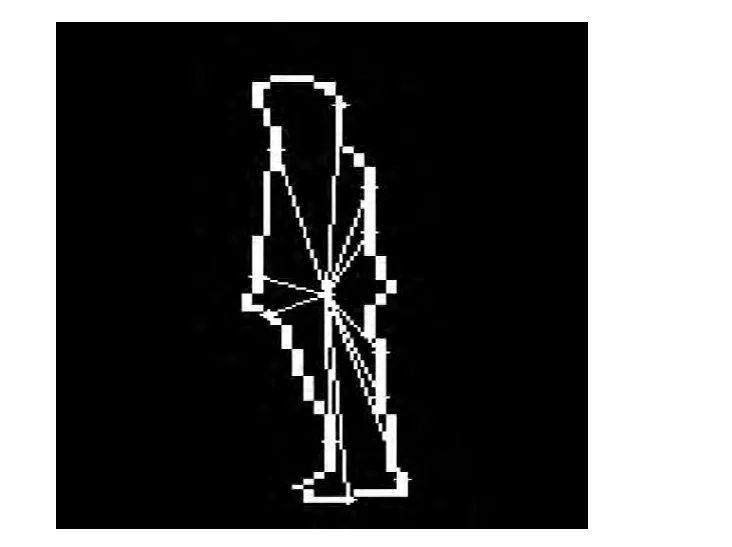
图2 质心到轮廓采样点的距离
1.3 特征向量小波变换
小波变换的基本思想是用一组小波函数或者基函数表示一个函数或者信号。对于离散信号f(k),离散小波变换的定义如下
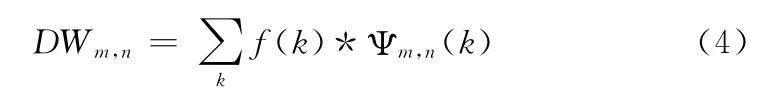
式中:m,n∈Z,Ψm,n(k)为离散小波函数,满足
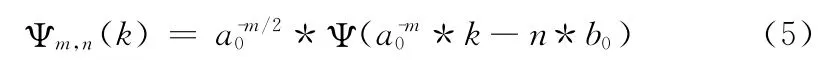
式中:Ψ(k)——满足小波变换约束条件的小波基函数;a0——尺度参数;b0——平移参数。小波变换通过平移变换母小波或者基小波获得信号的时间信息,通过缩放小波的宽度或者尺度获得信号的频率特性。人体运动特征数据的维数很高,高维数据中包含了大量的冗余信息并且隐藏了特征的相关性,特征数据的维数过高也会增加计算的复杂度,并且对识别结果产生负面的影响,因此在进行识别前,需要对高维特征数据进行降维处理。数据降维的基本原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集紧致的低维表示。本文通过小波变换对高维特征数据进行降维,小波变换降维的目的是尽可能多的去除数据中的噪声和冗余,使数据尽可能地简化,使相关的变量分离开,从而得到数据中最为重要的信息。
2 LDCRF模型建模
2.1 LDCRF模型
图3中,xj表示第j帧视频的人体动作观察序列,hj是xj相对应的隐藏状态,yj是xj的动作类标签。视频的观察序列是给定的,目标是预测每帧动作的类标签。通过得到观察序列X ={x1,x2,…,xm}和标签序列Y ={y1,y2,…,ym}之间的映射关系,从而进行行为识别。根据上述定义,定义条件概率模型为
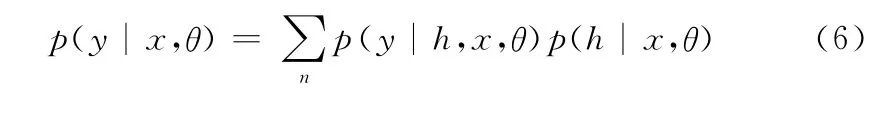
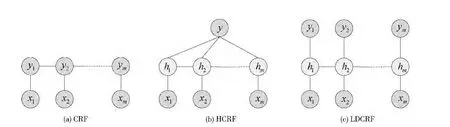
图3 3种概率图模型
式中:θ——模型的参数。
模型建立时,假设每个类标签相关的隐藏状态集彼此互不相交,这样可以降低模型训练和推理的复杂性。每个hj是类标签yj的合适的隐藏状态集Hyj中的一个成员,由于任意hjHyj,根据定义有p(y|h,x,θ)=0,则模型可以表示为
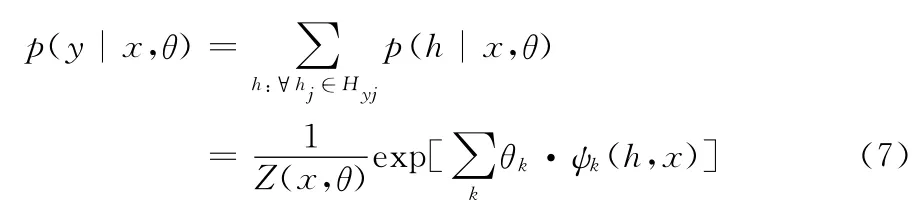
其中分布函数Z保障模型具有归一化的概率,其定义如下
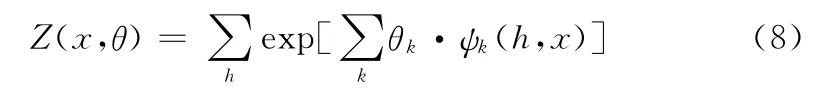
ψk定义如下
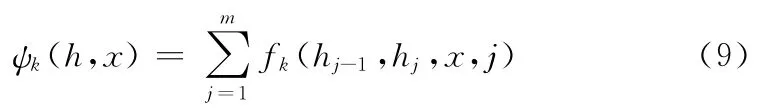
其中,fk(hj-1,hj,x,j)是特征函数,表示一个是状态函数sk(hj,x,j),或者转移函数tk(hj-1,hj,x,j)。在 型中,状态函数sk依赖于一个单独的隐藏变量,而转移函数tk则依赖一对隐藏变量。其中转移函数表示为
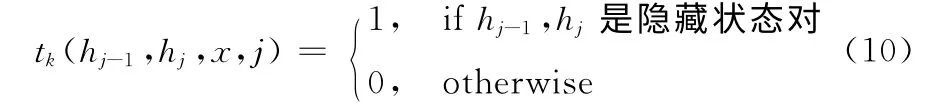
从式(10)可以得出,如果与θk相关的隐状态转移函数作用于相同的隐藏状态子集中,则可以表示出人体动作的内部动态特征;如果与θk相关的隐状态转移函数作用于不同的隐藏状态子集中,则可以表示出人体动作的外在动态特征,并且与θk相关的转移函数模型的内部和外部都是动态的。
2.2 LDCRF模型的参数训练和识别
训练集由n个标签序列(xi,yi)组成,其中i=1……n。通过下面的目标函数学习参数θ*
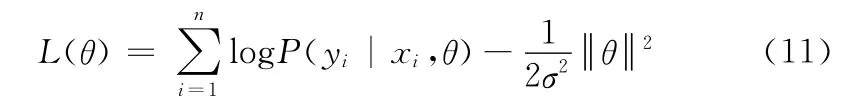
使用梯度法计算参数θ*=arg maxθL(θ)最佳值。由于通过梯度为零来求解参数θ*并不一定总是得到一个近似解,因此需要利用一些迭代计算来选择参数。在下文的实验中,我们使用BFGS优化技术来执行梯度法,使用动作序列的标签对模型进行训练,从而获得模型的参数。
在人体动作识别过程中,给定一个测试序列x,估计最有可能的标签序列y* 的最大化条件模型为

其中,参数θ* 是从训练集中学习得到的。基于LDCRF的行为识别模型,每帧图像的人体动作分类概率等于边缘概率p(yi=u|x,θ*),该概率是相关隐藏状态子集的边缘概率总和
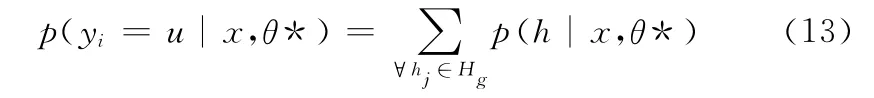
实验中,使用上述最大边缘概率方法估计每帧动作序列标签,区分连续序列的人体动作,进行人体行为识别。
3 实验与结果分析
本实验所用的动作数据来自Weizmann动作数据库,用于识别的10 种行为动作如图4 所示,分别为bend,jack,jump,pjump,run,side,skip,walk,wave1,wave2。实验中,提取每种行为动作的前60帧有效运动数据,30帧用于训练,30帧用于测试。因此分别使用30 帧*10 种动作=300帧图片进行训练和测试,其中每帧图片的特征向量为32维,模型的隐状态数为3个,通过BFGS迭代方法迭代确定模型的相关系数。由于以上动作分别由8位测试者完成,分别对10个动作进行了8组实验,最后取8组实验数据的平均值用于最终的实验结果。通过与CRF,HCRF模型进行对比实验来验证本文算法的性能。
表1为10种行为的识别结果。从表1 中看出LDCRF模型的识别率比CRF,HCRF 模型的识别率要高,体现了LDCRF模型对人体行为动作的分辨能力更强,同时LDCRF识别结果的波动性也较小,表明LDCRF 模型具有很强的识别稳定性。即使在CRF 和HCRF 对bend的平均识别率最高只有70%时,LDCRF仍然有不错的表现,体现了LDCRF模型结合行为动作在时间和空间上的信息建模的优势,说明了LDCRF 模型具有一定的抗干扰能力。在对pjump,run,wave1动作识别时,识别率达到了100%,这表明了LDCRF模型不仅对外在的动态建模,同时也能捕捉到动作的内在子结构,这就使得识别的结果更加准确。

图4 10种人体行为动作
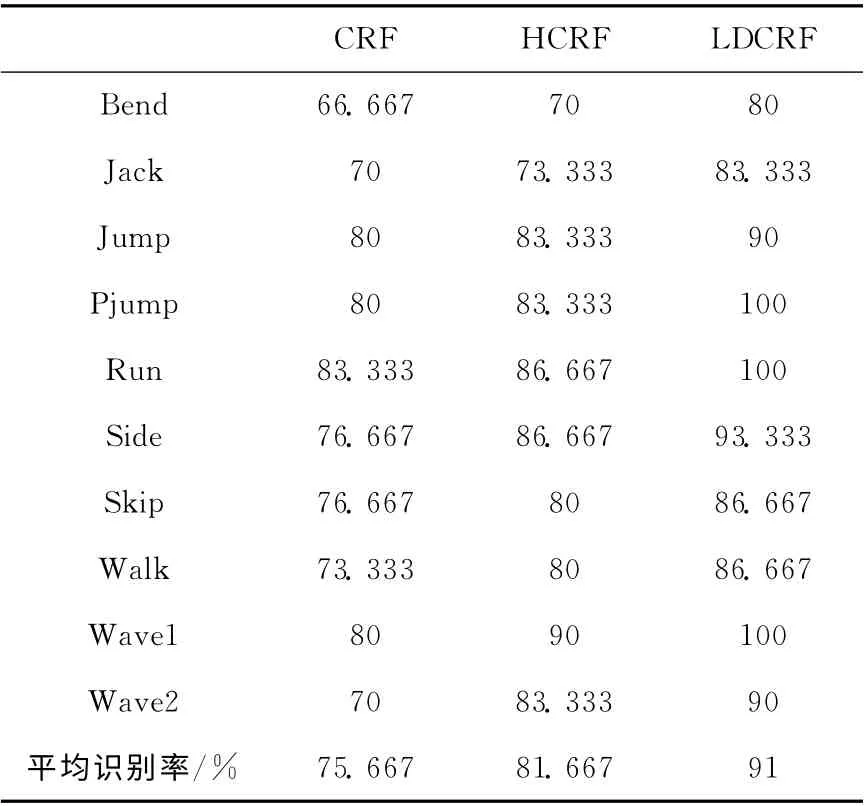
表1 10种行为识别结果/%
为了更好的测试本文算法,分别让CRF,HCRF,LDCRF模型在不同窗口下对同一未分段动作序列进行识别,识别结果如图5所示。从整体上来看LDCRF的识别正确率远比CRF 和HCRF 高,说明了LDCRF模型要比CRF 和HCRF更加稳定。在相同窗口大小的情况下LDCRF的识别率远比CRF和HCRF要高,这主要是由于LDCRF模型对动作内部和外部运动特征同时建模,形成了更好的模型识别能力。虽然在某些区域下,LDCRF模型的识别率波动较大,其主要原因是由于模型中的隐状态属性和长远相关性可能带来了冗余信息,导致了模型性能下降。随着窗口的增大,LDCRF模型的平均识别率也随之增加,但同时模型所需的计算时间和占用的资源也随之增大,并且呈线性增加,所以在进行窗口尺寸选择时要充分考虑这些问题,不能为了提高识别率而一味的增大窗口尺寸。在窗口尺寸很小的情况下,LDCRF的识别性能也表现的很不错,而且在日常的视频监控系统中我们一般都采用低于30帧/s来进行监控,这样为在线行为识别提供了可能。
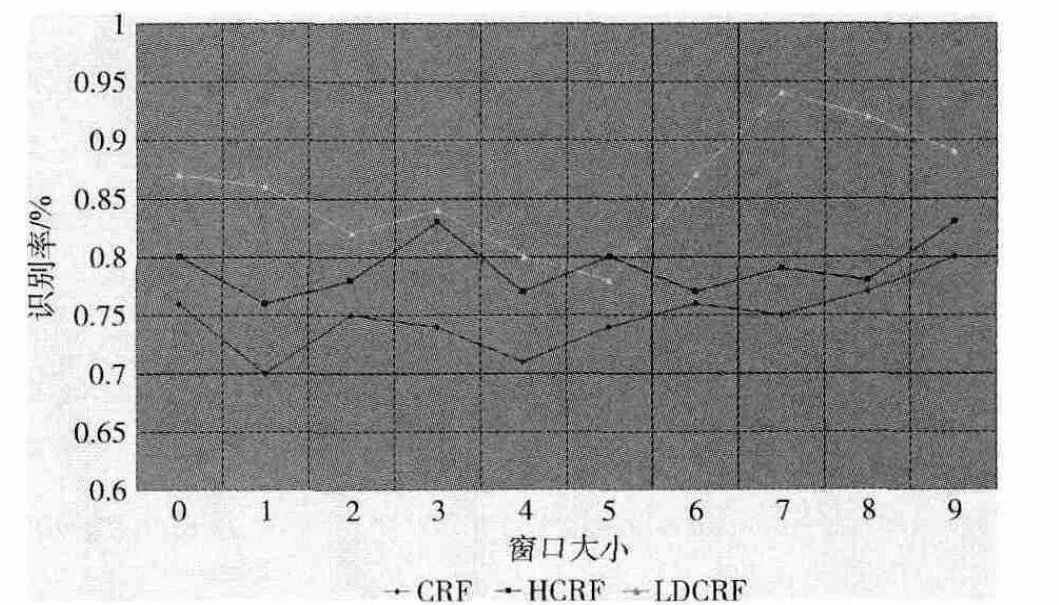
图5 不同窗口下CRF,HCRF,LDCRF的识别率
4 结束语
本文提出一种基于星形距离的LDCRF模型的人体行为识别方法,通过对人体运动图像进行轮廓提取,使用轮廓质心到轮廓边缘采样点的星形距离对人体运动特征进行描述,对人体运动姿态进行LDCRF 建模识别。通过对比CRF、HCRF和LDCRF 对未分段视频序列的行为识别结果,得出了LDCRF 在行为建模和行为识别能力上都优于CRF和HCRF,并且还具有一定的稳定性和抗干扰性。
[1]Moeslund TB,Hilton A,Kruger V.A survey of advances in vision-based human motion capture and analysis[J].Computer Vision and Image Understanding,2006,104 (23):90-126.
[2]Fuentes D,Gonzalez-Abril L,Angulo C,et al.Online motion recognition using an accelerometer in a mobile device[J].Expert Systems with Applications,2012,39 (3):2461-2465.
[3]Zhu Chun,Sheng Weihua.Motion and location based online human daily activity recognition [J].Pervasive and Mobile Computing,2011,7 (2):256-269.
[4]Andrea Mannini,Angelo Maria Sabatini.On-line classification of human activity and estimation of walk-run speed from acceleration data using support vector machines[C]//Engineering in Medicine and Biology Society,Annual International Conference of the IEEE,2011:3302-3305.
[5]Morency Louis-Philippe,Ariadna Quattoni,Trevor Darrell.Latent-dynamic discriminative models for continuous gesture recognition [C]//Computer Vision and Pattern Recognition,2007:1-8.
[6]HUANG Feiyue,XU Guangyou.Viewpoint independent action recognition [J].Journal of Software,2008,19 (7):1623-1634.
[7]HUANG Tianyu,SHI Chongde,LI Fengxia,et al.Discrimi-native random fields for online behavior recognition [J].Chinese Journal of Computers,2009,32 (2):275-281 (in Chinese).[黄天羽,石崇德,李凤霞,等.一种基于判别随机场模型的联机行为识别方法 [J].计算机学报,2009,32 (2):275-281.]
[8]Zhang Xuetao,Zheng Nanning,Wang Fei,et al.Visual recognition of driver hand-held cell phone use based on hidden CRF[C]//Vehicular Electronics and Safety,2011:248-251.
[9]LI Zheng.Mastering Matlab digital image process and identification [M].Beijing:Posts &Telecom Press,2013 (in Chinese).[李铮.精通Matlab数字图像处理与识别 [M].北京:北京人民邮电出版社,2013.]
[10]Zhang Shengjun,He Xiaohai,Teng Qizhi.Fuzzy-based latent-dynamic conditional random fields for continuous gesture recognition [J].Optical Engineering,2012,51 (6):067202-1-067202-8.
[11]Mahmoud Elmezain,Ayoub Al-Hamadi.LDCRFs-based hand gesture recognition [C]//Systems,Man,and Cybernetics,2012:2670-2675.
