基于词项语义映射的短文本相似度算法
2015-12-23黄贤英张金鹏刘英涛赵明军
黄贤英,张金鹏,刘英涛,赵明军
(重庆理工大学 计算机科学与工程学院,重庆400054)
0 引 言
当前短文本相似度[1-6]计算方法主要包括基于词项比较的方法和基于HowNet语义词典的方法[7]。因为文本的特征主要是通过词项来反映,因此采用词项比较来量化文本之间相似度是一种常用的方法,诸如提取文本之间共有词项的比例[8]、比较文本之间词项间的逆序关系[9]、统计词项词频填充文本向量度量余弦相似度[10]。这种词项比较方法相对适用于长文本,长文本的信息量能够通过规模较大的词项数量得到较为全面的反映。对短文本而言,通过数量稀疏的词项难以全面地体现短文本的含义,因此衍生出基于HowNet语义词典的方法,如文献 [11,12]利用HowNet计算词项相似度实现句子相似度计算,文献 [13]将句子划分为主语、谓语等部分,再利用HowNet语义词典计算各句子成分之间相似度。这种基于语义词典的方法在一定程度上反映短文本中词项潜在的语义信息,但是HowNet语义词典对词项收录数量的有限性较为严重地制约着词项相似度的计算,HowNet语义词典对未在词典出现的新词项的处理能力较弱。
本文针对基于词项比较的方法和基于HowNet语义词典方法存在的缺陷,分析中文短文本表达时主要依赖名词、动词、形容词和副词4种词性,提出将短文本中词项按词性进行切分,不同词性的词项构建对应的词性库,对于某一种词性,提取待比较的两个文本中对应的词性库进行词项归并,构建相应的词性向量,词性向量中各个维度上的映射值通过取该维度对应词项和词性库中所有词项相似度最大值,各个维度上最终权值取映射值与该词项在词性库中映射词项的词频乘积,词项间相似度计算采用HowNet语义词典提供的算法,则短文本之间相似度运算转换为词性向量之间相似度运算。
1 改进的短文本相似度算法
短文本中词项较为稀疏,通过数量非常有限的词项来表现文本实为不易,词项间的相互组合关系和语义关联性在短文本表示中显得尤为重要。短文本中不同词性的词项在语义表达时的作用各不相同[14],通过将短文本中词项按词性进行切分,并利用HowNet语义词典完成词项词性向量权值映射。
1.1 短文本词性切分
对于待比较的短文本MiT _A 和MiT _B,分别对MiT _A 和MiT _B进行分词和词性标注。词性标注采用中科院的ICTCLAS工具[15],示例如图1所示。

图1 词性标注
对于词性标注后的短文本,按名词、动词、形容词和副词4 种词性提取词项并构建对应的词性库,短文本MiT _A 的词性库表示如式 (1)所示

式中:NAi——词项,TFNAi——该词项对应的词频。式(1)中其它字符含义类似。
短文本中每个词项都可以与对应的词性库中某个维度相对应,短文本MiT_B 的词性库表示与MiT_A 类似,词性与词性表示字符的对应关系见表1,只列出了本文需要考虑的名词词性、动词词性、形容词词性和副词词性。

表1 词性与词性字符表示对应
1.2 词项权值计算
通过对词性库中词项进行归并,构建词性向量。以名词词性向量为例,名词词项向量的表示如式 (2)所示

式中:|N_A|、|N_B|——名词词性向量N_A,N_B中词项,不包括词项权值,通过词性库NS_A 和词性库NS_B 中词项归并后得到,对于名词词性向量中各个维度上对应的词项权值,将词项向词性库映射完成,替代传统的基于HowNet语义词典的最佳词项相似度匹配对发现的方法。
根据TF-IDF算法的定义,词项在文本中出现的频率越大,表明该词项在文本中的重要程度越高[16]。在短文本中,这种理论同样适用,词项在短文本中出现次数越多,表明该词项对文本的表征能力越强。以MiT _A 中名词词性向量N _A 为例,对于N_A 中某个词项NAi,词项间相似度计算采用文献 [17]中算法,词项NAi向名词词性库的映射值如下所示

式中:similarity(NAi,NAj)——使用文献 [17]中算法计算得到的词项间的相似度,词项向词性库中的映射值取该词项与词性库中所有词项相似度最大值,NAj表示词项NAi在词性库中的映射词项,名词词性向量N_A 中词项NAi的最终权值如下所示
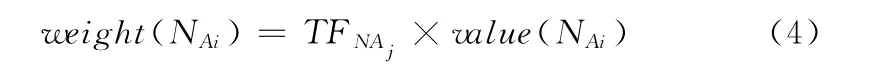
通过构建名词词性向量,名词词项向量作为整体向词性库中进行映射,若名词词性向量中词项在词性库中出现,则置映射值为1,若未出现,则映射值为该词项与词项库中所有词项的最大相似度,待比较文本中词项都映射到同一向量维度中,本方法集成了基于关键词和基于HowNet语义词典的优点,既较好地解决了HowNet词典容量有限的缺陷 (词项出现与否判断),又兼顾了词项间的语义相关性(词项间语义相似度计算),具体示例见表2。动词词性向量、形容词词性向量和副词词性向量中词项权值计算与名词词性向量中词项权值计算方法相同。

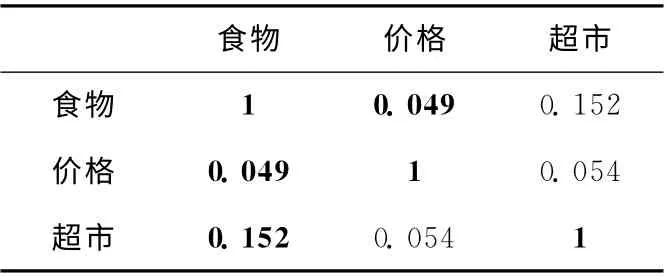
表2 词项权值映射
1.3 词性向量相似度计算
词性向量相似度计算采用经典的余弦相似度[10],本节以名词词性向量相似度计算为例,其它词性向量类似。
在图2中,表示文本的初始化处理、词性标注、词性库构建、词性向量构建和词项权值计算的过程。名词词性向量相似度计算如式下所示
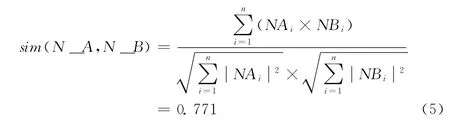

图2 名词词性向量相似度计算
1.4 文本相似度计算
文本之间的相似度运算由名词词性向量相似度、动词词性向量相似度、形容词词性向量相似度和副词词性向量相似度4部分组成,计算方法如下所示
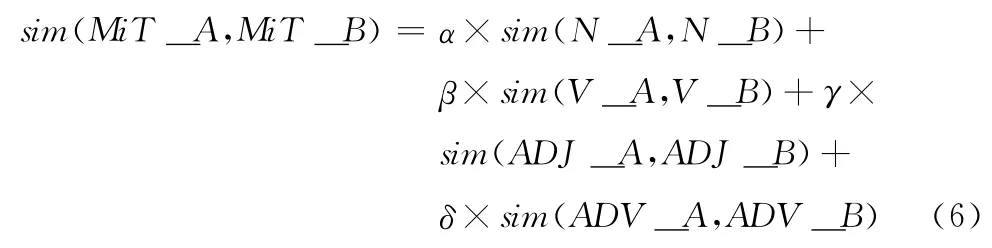
根据不同词性的词项在文本中重要程度不尽相同,在文本相似度计算时,为不同的词性向量赋予不同的权值定义,由于待比较的文本处于时刻变化中,因此相应词性向量的内容也在不断变化,示例如图3所示。
在图3中,count(N_A)表示MiT _A 中名词词性向量中词项数目,其它表示含义类似。示例1 中,名词词性向量中词项的数目远大于动词词性向量中词项的数目,此时,名词词性向量因赋予较大的权值系数,而在示例2中,名词词性向量中词项数目却远小于动词词性向量词项数目,若仍按照示例1中所取权值系数固定分配,难免会造成在相似度计算时的局部不均匀性。

图3 名词词性向量内容变化
词性向量的权值系数并非固定不变而应当随着待比较句子对的变化而变化,对词性向量的权值进行动态定义,取决于当前词性向量中词项的数目与所有词性向量词项总和的比值,如下所示

2 实验与分析
本文的实验数据来源于重庆理工大学计算机科学与工程学院的院长信箱数据,院长信箱主要用于本学院学生和学院进行教学和日常管理的一个简易FAQ (frequently asked questions)系统平台,该平台的实验数据可在“http://cs.cqut.edu.cn/DeanMail/MailList.aspx”网址处获得,数据格式见表3。
本实验选取时间段为 “2010/4/9-2013/9/11”共5992条记录,提取表3中提问内容和回复内容项作为实验时的短文本相似度比较实验数据集。
2.1 实验结果
本文采用余弦相似度算法 (similarity cosine algorithm,SCA)、关键词重叠算法(similarity overlap algorithm,SOA)、基于语义词典的算法 (similarity library algorithm,SLA)和本文算法 (similarity semantic algorithm,SSA)分别计算给定实验数据集中短文本之间的相似度。
在表4中,分别选取Top_N 条数据的相似度平均值,SCA 算法、SOA 算法和SLA 算法的相似度平均值分别保持在0.09-0.11、0.08-0.09 和0.20-0.21,而本文算法(SSA)的相似度平均值明显高于前3个算法,基本保持在0.37-0.39附近,SCA 算法和SOA 算法的相似度值平均值相对较低,SLA 算法的相似度平均值介于本文算法和SCA算法、SOA 算法之间。
表3 院长信箱数据格式
在表5中,分别比较SCA 算法、SOA 算法、SLA 算法和本文算法在不同的相似度阈值下的准确率,准确率计算方式为:相似度阈值内句子对数目/数据集中句子对总数。
通过图2中4种算法的对比图可以发现,SCA 算法和SOA 算法在相似度阈值很小的情况下,最终的相似度运算准确率仍然偏低,而此时SLA 算法和SSA 算法的性能却明显高于前两种算法,准确率都保持在非常高的水平,可以看出,在相似度阈值在0.05 以内时,SLA 算法和SSA 算法的准确率都能够保持在90%以上且SLA 算法优于SSA算法。相似度阈值在0.15时,SLA 算法的性能出现了较大幅度的降低,SSA 算法在相似度阈值为0.19时准确率首次超过SLA 算法。当相似度阈值在0.30 时,SSA 算法的性能出现了大幅度的降低,但是此时却明显优于前3种算法。因此,SSA 算法从整体上来看要优于SLA 算法,数据的分布较为平均,且整体的相似度计算时的准确性也优于前3种,这一点也可以通过表4中相似度平均值数据得到验证,而SLA 算法随着相似度阈值的递增会出现非常明显的递减。
SCA、SOA、SLA 和SSA 在不同相似度阈值下准确率如图4所示。

表4 SCA、SOA、SLA 和SSA 在TopN 条数据下相似度平均值

表5 SCA、SOA、SLA和SSA在不同相似度阈值下准确率

图4 SCA、SOA、SLA和SSA在不同相似度阈值下准确率
2.2 实验分析
本实验主要针对余弦相似度算法、关键词重叠算法、语义词典算法和本文算法在相似度计算时性能进行分析,从实验数据本身出发,数据中问答句子对基本上采用的是比较随意的表述方式,在具体的关联性方面显得并非十分匹配,因此句子对之间的相似度总保持在较低的水平,这一点可在表4数据中得到反映。
从理论上来说,余弦相似度算法和关键词重叠算法是完全基于关键词是否在文本出现而进行定义的,这在很大程度上制约了运算时的准确性,须知中文在表达时的差异性和多样性,相异的关键词也可以表达相近甚至相同的含义,语义词典算法和本文算法正是考虑了关键词之间的相互关联性,因此,语义词典算法和本文算法应当在性能上要优于余弦相似度算法和关键词重叠算法,这一点通过实验中相似度平均值和不同阈值下的准确率得到验证,语义词典算法没有考虑关键词的词性信息,收录的关键词数量也非常有限,因此,语义词典算法在相似度平均值上要低于本文算法,虽然语义词典算法在阈值较低的情况下准确率会优于本文算法,这正说明了语义词典算法计算的短文本之间相似度值偏低,在相似度阈值数值设置较低时,较多的句子对被判定为相似,从而很好的佐证了语义词典算法相似度计算的准确性不高。虽然实验数据集相对比较粗糙,但是在同等程度下,可以粗略的认为提问内容项和回复内容项具有一定的关联性 (问题-答案)。故从整体来说,本文算法要优于语义词典算法,这可以通过相似度平均值较高,相似度阈值增大时相似度准确率均优于前3种算法加以印证。
3 结束语
本文针对基于词项比较的相似度算法和基于HowNet语义词典最佳词项相似度匹配对发现的相似度算法存在的缺陷,提出一种结合词项词频和词项语义维度映射的新方法,这种方法既考虑了词项在文本中词频特性,从而避免了因该词项未被HowNet收录而出现计算误差,又兼顾了词项之间的语义关联性,实验部分也很好的佐证了本文算法稳定性较好,相似度平均值均优于另外3种算法,相似度准确率也较高且保持在较为稳定的水平。
[1]HOU Yongshuai,ZHANG Yaoyun,WANG Xiaolong,et al.Recognition and retrieval of time-sensitive question in Chinese QA system [J].Journal of Computer Research and Development,2013,50 (12):2612-2620 (in Chinese). [侯永帅,张耀允,王晓龙,等.中文问答系统中时间敏感问句的识别和检索 [J].计算机研究与发展,2013,50 (12):2612-2620.]
[2]JIANG Changjin,PENG Hong,MA Qianli,et al.Study on question parsing of restricted-domain Chinese question answering system [J].Computer Engineering and Design,2010,31(11):2589-2592 (in Chinese).[蒋昌金,彭宏,马千里,等.受限领域中文问答系统问句分析研究 [J].计算机工程与设计,2010,31 (11):2589-2592.]
[3]Rasim M Alguliev,Ramiz M Aliguliyev,Makrufa S Hajirahimova.Maximum coverage and minimum redundant text summarization model [J].Expert Systems with Applications,2011,38 (12):14514-14522.
[4]Pawan Goyal,Laxmidhar Behera,Thomas Martin McGinnity.A context-based word indexing model for document summariza-tion [J].IEEE Transactions on Knowledge and Data Engineering,2013,25 (8):1693-1705.
[5]Chu Fong,Masrah Azrifah Azmi Murad,Shyamala C Doraisamy,et al.Measuring sentence similarity from both the perspectives of commonalities and differences[C]//Proceeding of the 22nd International Conference on Tools with Artificial Intelligence,2010.
[6]Ahmed Hamza Osman,Naomie Salim,Mohammed Salem Binwahlan.An improved plagiarism detection scheme based on semantic role labeling [J].Applied Soft Computing,2012,12(5):1493-1502.
[7]HUA Xiuli,ZHU Qiaoming,LI Peifeng.Chinese text similarity method research by combining semantic analysis with statistics [J].Application Research of Computers,2012,29(3):833-836 (in Chinese).[华秀丽,朱巧明,李培峰.语义分析与词频统计相结合的中文文本相似度量方法研究 [J].计算机应用研究,2012,29 (3):833-836.]
[8]Sergio Jimenez,Claudia Becerra,Alexander Gelbukh.A parameterized similarity function for text comparison [C]//First Joint Conference on Lexical and Computational Semantics,2012.
[9]ZHOU Faguo,YANG Bingru.New method for sentence similarity computing and its application in question answering system[J].Computer Engineering and Applications,2008,44 (1):165-178 (in Chinese).[周法国,杨炳儒.句子相似度计算新方法及在问答系统中的应用 [J].计算机工程与应用,2008,44 (1):165-178.]
[10]WU Quan’e,XIONG Hailing.Method for sentence similarity computation by integrating multi-features[J].Computer Systems and Applications,2010,19 (11):110-114 (in Chinese).[吴全娥,熊海灵.一种综合多特征的句子相似度计算方法 [J].计算机系统应用,2010,19 (11):110-114.]
[11]ZHONG Maosheng,LIU Hui,ZOU Jian.The inter-sentence semantic relevancy degree calculation using the quantified correlation of words[J].Journal of Shandong University(Engineering Science),2010,40 (5):105-111 (in Chinese).[钟茂生,刘慧,邹箭.基于词语量化相关关系的句际相关度计算 [J]. 山东大学学报(工学版),2010,40 (5):105-111.]
[12]CHENG Chuanpeng,WU Zhigang.A method of sentence similarity computing based on HowNet[J].Computer Engineering and Science,2012,34 (2):172-175 (in Chinese).[程传鹏,吴志刚.一种基于知网的句子相似度计算方法[J].计算机工程与科学,2012,34 (2):172-175.]
[13]ZHENG Cheng,XIA Qingsong,SUN Changnian.Sentence similarity calculation based on composition [J].Computer Technology and Development,2012,22 (12):101-104 (in Chinese).[郑诚,夏青松,孙昌年.一种基于成分的句子相似度计算[J].计算机技术与发展,2012,22 (12):101-104.]
[14]WU Quan’e.Chinese sentences similarity computation and its application in question-answering system [D].Chongqing:Southwest University,2011(in Chinese).[吴全娥.汉语句子相似度计算及其在自动问答系统中的应用[D].重庆:西南大学,2011]
[15]ICTCLAS [EB/OL].http://www.nlpir.org/download/ICTCLAS2012-SDK-0101.rar/,2001-2009.
[16]HUANG Chenghui,YIN Jian,HOU Fang.A text similarity measurement combing word semantic information with TF-IDF method [J].Chinese Journal of Computers,2011,34 (5):856-864 (in Chinese).[黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法 [J].计算机学报,2011,34 (5):856-864.]
[17]GE Bin,LI Fangfang,GUO Silu,et al.Word’s semantic similarity computation method based on HowNet[J].Application Research of Computers,2010,27 (9):3329-3333 (in Chinese).[葛斌,李芳芳,郭丝路,等.基于知网的词汇语义相似度计算方法研究 [J].计算机应用研究,2010,27(9):3329-3333.]
