纸币冠字号预处理及组合特征识别方法
2015-12-23任胜兵胡志刚
梁 杨,任胜兵,胡志刚
(中南大学 软件学院,湖南 长沙410075)
0 引 言
纸币冠字号识别作为目前模式识别领域的一项重要应用,主要涉及图像预处理、字符分割和字符识别三大模块。图像预处理是冠字号识别系统的重要基础,主要包括冠字号定位[1],旋转校正[2],二值化[3,4],去噪滤波[5]等环节。传统的图像定位方法中,有的依靠经验值对图像进行粗略截取,定位误差较大,有的通过扫描图像某些特征来截取目标区域,抗干扰性差且耗时。传统的几何坐标旋转算法虽然实现简单,但需要对每个点都进行包含乘加运算的坐标变换,非常耗时,并且待旋转图像越大其执行速度越会成为系统瓶颈。传统的二值化主要有全局阈值法和局部阈值法,全局阈值法根据图像的灰度统计确定阈值,算法速度快,但抗干扰能力差;局部阈值法需要对每个点及其邻域的灰度信息进行判断,有一定的抗噪性,但速度很慢。字符识别作为识别系统的核心,其识别率和识别速度直接影响整个系统的性能。根据特征提取方法不同,常用的识别方法有模板匹配法[6-8],小矩量法[9]和网格法[10]。文献 [6-8]介绍的模板匹配法相对简单,但比较耗时,而且识别率较低;文献 [9]利用小波矩提取的特征向量维数较高,算法收敛速度慢,识别率较低;文献 [10]介绍的网格法需要计算每个网格的统计特征,虽然网格特征容易提取,但其抗位置变化能力差,字符的倾斜、偏移会导致网格间错位,使识别率降低。
针对以上方法处理速度和准确率的不足,改进了预处理的关键算法并提出了一种组合特征识别方法。预处理阶段,提出一种几何定位算法,达到了精确性和实时性的要求;改进旋转算法,提高了执行速度;提出一种可变滑窗二值化算法和一种滤波算法,改善了二值化效果。识别阶段,通过有针对性地提取字符的必选特征和若干可选特征,采用多叉树作为分类器,高效地进行分类识别。以美元冠字号为例的测试验证了该方法可以达到较高的识别率和识别速度,满足工程应用的要求。
1 纸币冠字号码识别流程
一般地,冠字号识别流程可分为图像采集、图像预处理、字符分割、字符识别等四大步骤。其中,图像采集一般由图像传感器等硬件部分完成,本文主要研究图像采集后软件算法的改进。冠字号识别系统整体框架如图1所示。
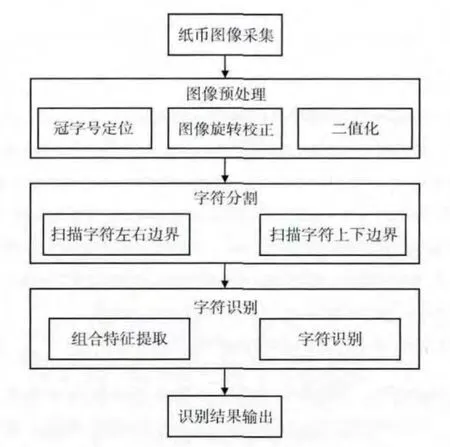
图1 冠字号识别系统整体框架
2 预处理关键算法改进
2.1 冠字号区域定位
如果对整张美元图像进行处理,很多无关信息并不需要,而且数据量大,效率低。所以定位的目的就是得到包含完整冠字号码的图片部分,尽量切掉冠字号周围无关的图像,因此首先要根据冠字号的位置特点将冠字号区域初步定位下来。本文提出一种几何定位方法,算法思想如下:
(1)采用边界找点法确定纸币图像四条边上的若干点(点的个数根据实验确定,但至少为2),以此来线性拟合出纸币的四条边界线。
(2)根据最小二乘法原理求出纸币图像四条边界线的斜率和截距。
(3)确定目标区域上边线到纸币上边界线的距离、目标区域左边线到纸币左边界线的距离、目标区域的高度和宽度。
(4)根据直线平移原理以及步骤 (3)中确定的距离、宽度和高度参数,平移四条边界线,将目标区域包含在四条直线围成的矩形区域内。
(5)求出平移后四条直线的交点,然后根据交点坐标将目标区域截取出来,即可准确地定位出包含冠字号的区域。
2.2 图像旋转校正
为了方便后续分割与识别,需要对定位后倾斜的冠字号区域进行旋转校正。旋转应先考虑到如下三方面:①为了使处理的数据量小,对目标区域旋转时超出整幅图像边界的部分需要裁剪掉;②绕图像中心进行旋转,确保冠字号不会被切割掉;③由于图像的像素坐标只能为整数,而经过坐标变换后,原图像与旋转后图像的点不是一一对应关系,旋转后点的坐标出现小数,需要估算该点的灰度值。
字符识别系统主要应用于嵌入式平台,因此针对实时性和准确性的问题,旋转算法有三点改进:
(1)采用查表法建立每一度倾角对应的正弦、余弦映射表,并把相应的正余弦值扩大为真实值的256 倍,使运算过程中只有整数没有浮点数,所有乘除运算均通过移位运算实现。
(2)只选取每行的第一个点根据式 (1)进行坐标变换,该行其余点根据式 (2)进行坐标变换

其中,θ为旋转角度,式 (1)中 (X0,Y0)为旋转前的点,(X,Y)为旋转后的点,式 (2)中 (X,Y)为前一个旋转后的点,(Xnext,Ynext)为下一个旋转后的点,式 (2)根据同一行前后两个点横坐标的关系得出。
(3)采用双线性插值法估计旋转后点的灰度值。把旋转后像素坐标 (X,Y)分解成 (x+u,y+v),其中x、y代表坐标点的整数部分,u、v 代表坐标点的小数部分。如式 (3)所示

由式 (3)可以看出,用距离点 (x+u,y+v)最近的4个点估计 (x+u,y+v)灰度值,f (x+u,y+v)的值即为旋转校正后点 (X0,Y0)的灰度值。距离点 (x+u,y+v)越近,对 (X0,Y0)灰度值影响越大。
2.3 二值化
二图像的好值坏直接影响字符特征的提取,进而影响识别率。提出了一种可变滑窗二值化算法,主要思想是:将原图像用滑动窗口分成若干子图像,再分别用OTSU 算法进行二值化,滑窗大小根据整幅图像中噪音多少自适应调整。算法简述如下:

算法1:可变滑窗二值化算法输入:原始图像F(x,y)输出:二值图像B(x,y)Begin If F(x,y)中灰度值在80到140间的点数大于常数K Then滑窗宽度WIN=COL/N1 Else 滑窗宽度WIN =COL/N2 ‘N2 <N1 EndIf For j=1:COL If(j>0)AND(j% WIN=0) Then 用OTSU 算法计算当前窗口阈值并二值化,二值化结果保存在B(x,y)中 EndIf EndFor Output B(x,y)End
2.4 滤波算法
实际应用中,二值化后的图像里难免存在噪声干扰,为进一步提高二值图像质量,提出了一种能降低离散噪声的滤波算法,主要思想是:如果该点为前景点0,并且其一周至少有3个背景点1,并且其相邻右边3个点或下面3个点不全为0时,将其置为1。算法简述如下:

算法2:滤波算法输入:二值图像B(x,y)输出:滤波图像T(x,y)Begin T(x,y)=B(x,y)For i=2:ROW-1 For j=2:COL-1 If (T(i,j)=0) AND((T(i-1,j)+T(i+1,j)+T(i,j-1)+T(i,j+1))>2) AND ((T(i+1,j)+T(i+2,j)+T(i+3,j)>0)) AND ((T(i,j+1)+B(i,j+2)+T(i,j+3)>0)) Then T(i,j)=1; EndIf EndFor EndFor Output T(x,y)End
3 特征提取与识别
3.1 组合特征提取
字符特征提取是字符识别的关键,通过研究字符的结构特征和统计特征,提出了一种高效的组合特征提取方案,具体方法如下:
(1)横竖线特征:大量实验发现,横竖线特征作为字符的一种结构特征,非常具有代表性,分类效果明显。为此,首先给出横竖线的定义,假设字符外接矩形的高度为H,宽度为W。
定义1 字符图像中,垂直线高度大于αH,称为竖线。
定义2 字符图像中,水平线宽度大于βW,称为横线。
其中,α是竖线特征比阈值,β是横线特征比阈值,0.5<α<1,0.5<β<1。
此外,规定横竖线特征向量为两位,表示为 (colFeature,rowFeature),colFeature 代表竖线特征,取值为0、1、2、3、4,分别代表:无左右竖线、仅有左竖线、仅有右竖线、仅有中竖线、两侧均有竖线;rowFeature代表横线特征,取值为0、1、2、4,分别代表:无上下横线、仅有上横线、仅有下横线、上下均有横线。
提取字符竖线特征的步骤:①从左到右扫描字符的每一列,计算该列最大连续黑色像素点的个数N。②如果N/H>=α,说明该列为竖线,如果N/H<α,说明该列不是竖线。③如果该字符所有列都不存在竖线,则colFeature=0;如果只有前三列存在竖线,则colFeature=1;如果只有后三列存在竖线,则colFeature=2;如果只有中间三列存在竖线,则colFeature=3;如果前三列和后三列同时存在竖线,则colFeature=4。
横线特征提取步骤和竖线类似,在此不再赘述。
通过提取横竖线特征,得到仅有两个特征值的二维向量,分类效率高。不仅能有效区分1和4,I和H 等结构特征差别较大的字符,也能有效区分N 和K,6和5等一些形似字符。
对训练样本集提取了不同字符的横竖线特征后,首先要进行字符集的划分。在实际应用中由于存在字符倾斜、噪声干扰等影响,可能造成同一字符对应多个特征向量的情况。由于篇幅所限,这里以特征向量 (1,0), (4,2)为例,给出对应的字符集见表1。
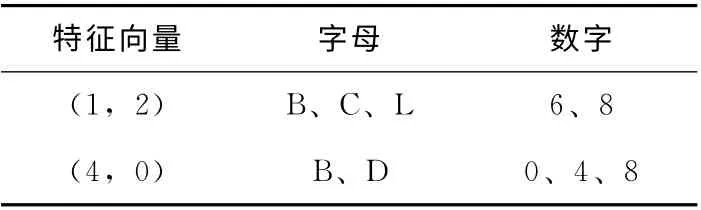
表1 字符集举例
(2)连通域特征:字符的连通域特征非常稳定,不受字符倾斜的影响,抗干扰能力强,很好地弥补了字符横竖线特征的不足。
二值图像的连通域标记是指在白色像素 (通常用1表示)和黑色像素 (通常用0表示)组成的一幅点阵图像中,把互相邻接 (一般4-邻接或8-邻接)的像素值为1的像素集合提取出来,为图像中不同的连通域填入不同的数字标记,并统计连通域的数目。
字符连通域特征的提取步骤如下:
令标记变量flag 初值为2,为方便连通域扫描,在分割完的字符四周加上一圈背景像素点1,如图2 (a)所示;
从坐标为 (0,0)的点开始顺序扫描,如果值为1,则标记为flag 的值,然后坐标先进栈,判断如果栈非空,则栈顶坐标出栈,同时遍历该出栈点4邻域内的点,如果为1,则进栈,标记为flag 的值,否则不标记。如此循环判断栈的状态,非空则出栈并进行遍历和标记。直到栈空,完成一个连通域的标记,并使flag 值加1以便标记下一个连通域;
直到该字符图像中所有点均已被标记,即不存在值为1的像素点时,所有连通域标记结束,该字符连通域个数=flag-2。
以字母D 为例,其连通域的标记如图2所示。
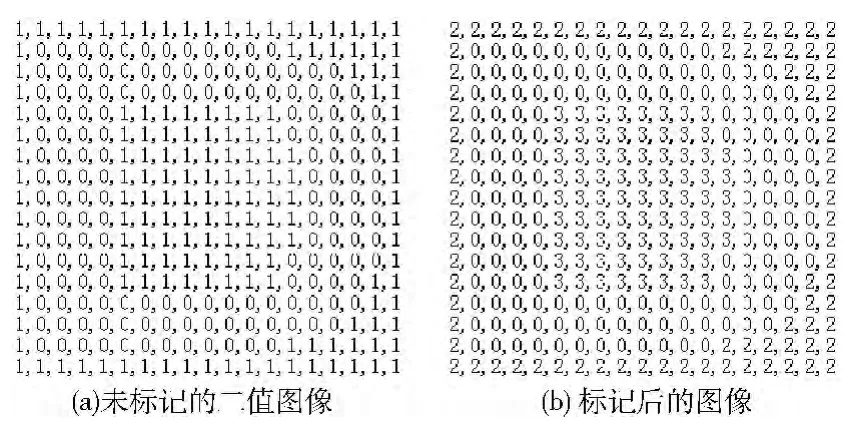
图2 字母D 的连通域标记
由图2 (b)可知,对字母D 标记完值为3 的连通域后,flag 加1变为4,此时所有点都已进行过标记,则D的连通域个数为2。因此根据连通域特征能准确进行字符分类,很好地区分外部轮廓相似而内部特征差异较大的字符,如B和D,0和8等。
(3)纵向交点数特征:不同字符在某些列纵向交点数上存在差异,如数字2和7,字母C和E,在中间几列交点数有明显不同。因此,字符的交点信息可以作为字符分类的有效信息。字符纵向交点数的提取就是扫描字符的某一列前景像素点与背景像素点相交的个数。以字母C 和E 为例,提取其中间列的交点特征如图3所示。
在图3中,C 和E 在中间列的交点数不同,可以快速识别出来。实际应用中,由于笔画偶尔会有噪音干扰或断裂情况,所以计算交点时一般会同时扫描前后相邻的几列,综合进行判定。

图3 字母C和E交点特征对比
(4)横向交点数特征:横向交点数特征的提取和纵向类似,需要扫描该字符某几行前景像素点与背景像素点相交的个数,在此不再赘述。
(5)横向交点坐标位置特征:横向交点坐标位置特征的提取是指在字符的某一行中,从左往右或者从右往左扫描,第一次碰到前景像素点时,记录该点的横坐标,然后判断此坐标是在字符的左半部分还是右半部分,进而区分具有此特征的字符。以数字2和5 为例,选择第5 行,从右往左扫描交点,如图4所示。

图4 数字2和5横向交点位置特征对比
在图4的扫描行中,第一次碰到前景像素点时,数字2的横坐标位于字符中线的右侧,数字5的位于中线的左侧。从而快速识别出结构相似的字符2和5。
(6)纵向交点坐标位置特征:纵向交点坐标位置特征的提取和横向类似,需要在字符的某一列中,从上往下或者从下往上扫描,第一次碰到前景像素点时,记录该点的纵坐标,然后根据此坐标的位置来识别字符,在此不再赘述。
(7)斜线特征:斜线特征提取首先在字符4个顶点的位置找到一个基点,然后从此基点开始寻找有无从该点延伸的斜线。斜线就是有从基点出发的前景点能往斜向 (如左上)游走两次以上的特征。以字母O 和Q 为例,基点选取的基准是在右下的3×3的框中找到1个前景像素点,使其纵、横坐标之和最大,若纵、横坐标之和相等,则取纵坐标较大的点做为基点。因此,字母Q 有从基点出发向左上角的斜线,而字母O 没有此斜线,由此可以将字母Q 和O 识别出来。
(8)环位置特征:环是指字符中由前景点围成的一个闭合区域。环位置特征适用于连通域个数相同的形似字符的识别,其特征提取需要借助连通域标记好的数字,从上往下或者从下往上扫描,第一次碰到该标记值时,记录该点的纵坐标,然后判断环位于字符的上半部还是下半部,进而识别出字符。例如数字6 和9,由于连通域个数都为2,显然环在数字6的下半部,在数字9的上半部,从而能够快速区分。
(9)环内前景点统计特征:环内前景点统计特征的提取在连通域扫描时完成,即统计环内具有同一标记的点的个数。例如,字母O 内的像素点明显要多于字母A,从而很快区分出字母O 和A。
(10)区域统计特征:区域统计特征是计算字符图像中选定矩形区域内前景点或背景点的个数,其作为字符图像重要的统计特征,具有很好的区分性和稳定性。
3.2 分类识别
采用多叉树的方法进行分类识别。首先提取待识别字符的横竖线特征进行第一次分类,如果不是最终结果,则根据分支特点继续提取其它合适的特征进行再次分类,直至识别出结果。以美元数字0-9为例,识别过程如图5所示。
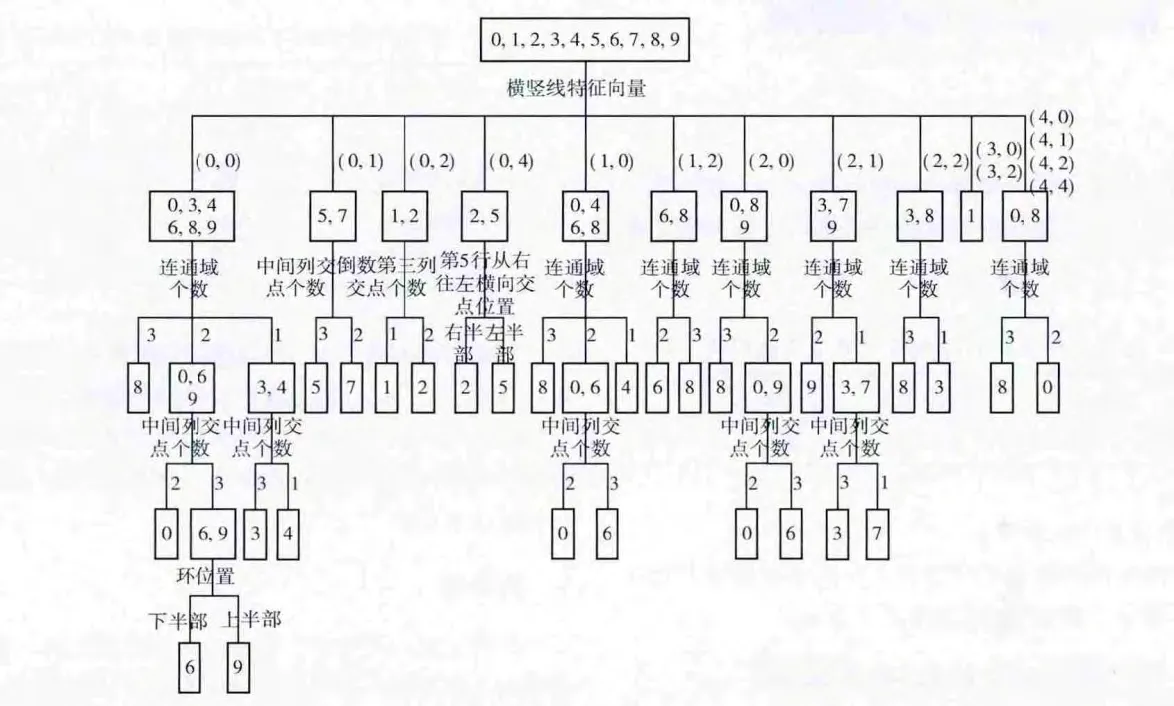
图5 数字识别过程
从图5可以看出,一般地,对单个字符而言,平均2-3次分类即可完成识别,个别字符最少需要1次分类,最多不超过4次分类。因此,组合特征提取方法灵活,针对性强,识别率高,而且字符的特征空间维度低,平均分类次数少,识别速度快。字母识别过程和数字类似,由于篇幅所限,不再赘述。
4 实验结果及分析
4.1 系统实验结果
实验环境:集成德州仪器公司DM642 芯片的开发板,Code Composer Studio V3.3 开发环境,仿真器,点钞机。用点钞机的扫描管在白光下随机扫描2000张美元图片作为测试集,全部保存为.dat格式的数据文件。在开发板上,依次导入这2000张美元图片并在线测试,实验结果表明,基于该方法的字符识别率达到96.80%,平均识别时间为22.5ms/张。
4.2 结果分析和比较
4.2.1 定位算法实验结果
以小头版的100美元为例,分别在纸币的4 个边上选取20个点进行线性拟合,根据几何定位算法定位出冠字号区域。几何定位效果如图6所示。
图6可以看出,冠字号区域在纸币上的相对位置固定,所以根据实验确定距离、宽度和高度的参数。几何定位法可以精确地定位到纸币上任意指定的区域,并且选择较少的点进行线性拟合可以明显提高算法速度。与传统的经验值定位相比,几何定位法更准确,与依靠扫描图像某些特征区域的定位方法相比,几何定位算法速度更快,抗干扰性更强。
4.2.2 旋转校正算法实验结果
以大小为240×480的图像进行旋转校正,表2给出传统几何旋转和改进旋转算法的性能比较。

图6 几何定位效果
表2结果表明,由于采用加减运算、查表法、移位运算等,代替了需要占用更多指令周期的乘除、三角和浮点运算,改进的旋转算法比传统旋转算法执行速度更快,效率更高。

表2 传统几何旋转和改进旋转算法性能对比
4.2.3 二值化算法实验结果
取一个略有噪声的冠字号图像,分别采用传统OTSU算法和可变滑窗二值化算法效果如图7所示。

图7 图像二值化效果对比
图7效果说明,由于可变滑窗二值化算法会根据噪声多少自适应调整滑窗大小,然后按其大小分块采用OTSU算法计算阈值,兼顾了全局阈值法的速度和局部阈值法的效果,与传统OTSU 算法相比,可变滑窗二值化算法抗干扰性更强,二值图像质量更好,为特征提取打下良好基础。
4.2.4 滤波算法实验结果
实验证明,提出的滤波算法能有效减少二值图像中的离散噪音点,如图8所示。
4.2.5 分类识别算法实验结果

图8 滤波前后效果对比
为检验提出的组合特征识别算法性能,在本系统中分别集成了几种传统的字符识别算法作为对比模型,选择字符的识别率和识别时间作为评价标准,对这2000张美元图片进行实验测试,见表3。
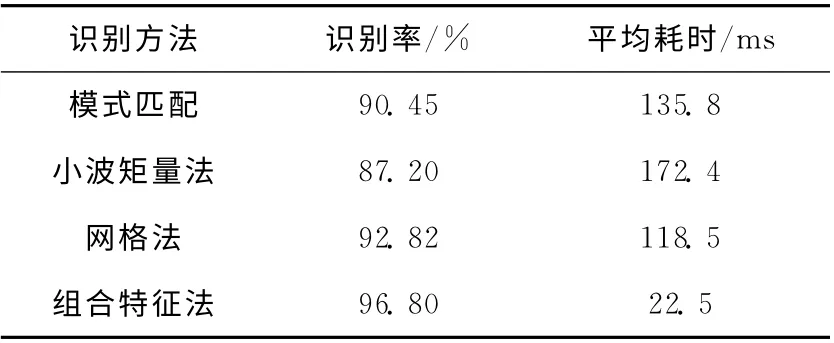
表3 组合特征识别法与传统特征识别法性能对比
实验结果表明,由于组合特征识别法不需要存储模板,占用资源少,一般只需提取包含字符横竖线特征在内的2~3个特征,即可通过多叉树分类器完成识别,因此采用组合特征的字符识别算法识别率高,识别速度快,优于其它3种传统识别算法。
5 结束语
研究了嵌入式平台上字符识别的关键算法,改进了预处理的关键算法,提出了一种组合特征识别方法。首先提出了几何定位算法,通用性强,定位精度高,速度快,稳健性强;其次改进了图像旋转算法,图像校正速度显著提高;然后提出了一种可变滑窗的二值化算法和一种滤波算法,自适应性强,二值图像质量提高,为特征提取打下了良好的基础;最后提出了一种组合特征提取方案,并采用多叉树结构进行字符分类,识别率高,速度快,鲁棒性好。对比4种分类算法的总体性能可以看出,组合特征识别方法具备识别率高和耗时短的优点,更能满足实际系统的要求。研究图像在频率域上的可用特征,丰富组合特征的提取,改进识别方法,使识别率和识别速度进一步提高是下一步的研究方向。
[1]Vinhdu Mai,Miao Duoqian,Wang Ruizhi,et al.An improved method for Vietnam license plate location,segmentation and recognition [C]//International Conference on Computational and Information Sciences,2011:212-215.
[2]Serene Banerjee,Anjaneyulu Kuchibhotla.Real-time optimal-memory image rotation for embedded systems[C]//IEEE International Conference on Image Processing,2009:3277-3280.
[3]Zhang Zhiyong,Song Yang.The license plate image binarization based on Otsu algorithm and MATLAB Realize[C]//International Conference on Industrial Control and Electronics Engineering,2012:1657-1659.
[4]Kuang Jiangming,Xu Suxiao,Zhang Shuang,et al.License plate recognition system with voice announcement based on improved Otsu pseudo binarization algorithm [C]//International Conference on System of Systems Engineering,2012:316-318.
[5]Sun Chuanwei,Liu Hong,Liu Jingao.An image enhancement method for noisy image[C]//International Conference on Audio,Language and Image Processing,2010:1144-1147.
[6]TANG Jin,LI Qing.Fast template matching algorithm [J].Journal of Computer Applications,2010,30 (6):1559-1564(in Chinese).[唐琎,李青.一种快速的模板匹配算法 [J].计算机应用,2010,30 (6):1559-1564.]
[7]Shih Bih-Yaw,Chen Chen-Yuan,Kuo Jin-Wei,et al.A pre-liminary study on design and development of template-based for license plate recognition system applying artificial coordinates auxiliary techniques[C]//IEEE International Conference on Industrial Engineering &Engineering Management,2010:80-83.
[8]Alexander Sibiryakov.Fast and high-performance template matching method [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2011:1417-1424.
[9]ZHOU Hongjun,YANG Hao,LIN Yimang.Plate characters recognition based on ICA and wavelet moments[J].Journal of Southwest China Normal University (Natural Science Edition),2010,35 (2):159-163 (in Chinese).[周虹君,杨浩,林一莽.利用独立成分分析和小波矩对车牌字符特征的识别 [J].西南师范大学学报 (自然科学版),2010,35 (2):159-163.]
[10]YANG Danfeng,LV Yue.Off-line signature verification based on combination of direction feature and grid feature[J].Journal of Image and Graphics,2012,17 (6):717-721 (in Chinese).[杨丹凤,吕岳.方向特征和网格特征融合的离线签名鉴别 [J].中国图象图形学报,2012,17(6):717-721.]
