结合半监督与主动学习的复杂名词短语识别
2015-12-23姜亚辉姬东鸿
姜亚辉,姬东鸿
(武汉大学 计算机学院,湖北 武汉430072)
0 引 言
本文研究的目标是包含至少3个词语且不含助词 “的”的复杂名词短语。名词短语的识别在自然语言处理很多领域有着重要的应用,例如自动问答、信息检索、信息恢复[1]、机器翻译等领域。复杂名词短语包含多个名词词语,内部包含丰富的语义信息,其识别分析对句子乃至篇章的语义理解有着重要的意义。主动学习[2](active learning)是一种可以有效减少学习器对标签数据需求量的学习方法,而半监督学习[3]方法则是建立在图理论上,能够有效的利用未标签数据,在数据挖掘和机器学习上已经取得了很多成果。目前,半监督和主动学习相结合起来的算法已经应用到高光谱图像识别[4]、生物信息抽取[5]等领域,但在中文复杂名词短语的识别方面,尚有待对半监督和主动学习结合的识别方法进行探索。国内外将机器学习应用到最长名词短语识别方面的主要有:条件随机域模型、最大熵马尔科夫模型、隐马尔科夫模型等。对于外语的名词短语识别系统中:法语的最长名词短语抽取系统[6]是基于规则的,英文的最长名词短识别方面有利用有限状态分析机制[7]的识别系统以及结合统计和规则方法[8]的抽取系统。在中文领域,周强等在中文最长名词短语的识别方面做了重要的工作。传统的有监督的学习方法依赖于大量的标签数据来训练学习器,在现实中可以很容易获得大量未标签数据,而获得标签数据需要昂贵的资源,因此一个关键问题是:在学习器达到相同的性能情况下,尽可能减少标签数据的使用。
1 复杂名词短语识别
名词短语的识别工作是自然语言处理中的一重要的子任务。它的识别结果可以用来简化句子的结构,进而降低句法分析难度以及复杂度,这对句子的整体结构框架的把握,句子完整句法树的构建有着非常重要意义。例如:“我在大连理工大学工作了十五年了”,如果正确识别出 “大连理工大学”这一复杂名词短语,则能很容易把握句子的整体结构,做出正确的句法分析。
句子中名词短语按照组成结构可以分为[9]:①不包含其它名词短语的最短名词短语 (mNP);②不被其它名词短语包含的最长名词短语 (MNP);③所有不是mNP 和MNP的一般名词短语 (GNP)。
套叠现象是中文所特有的,这使得对中文最长名词的识别比英文的复杂名词短语的识别更加困难。名词短语长度越长,其识别的难度也越大。研究表明:对名词短语的识别中,在准确率方面,长度超过5的识别结果要少于不超过5的识别结果15 个百分点,召回率低了35 个百分点[9]。周强等人在研究中将复杂名词短语定义为长度大于或者等于5的MNP,本文中 “复杂名词短语”是指:包含至少3个词语且不含助词 “的”的复杂名词短语。
复杂名词短语的识别问题可以看作标注问题,每个句子形式化为:x= (x1,…,xt),其中xi为句子中的各个字,看作为输入;相应的y= (y1,…,yt)则表示对应的标记序列,目标就是找到最有可能的标记序列。
2 条件随机域
条件随机域模型 (conditional random fields,CRF)的基础是最大熵模型以及隐马尔科夫模型,是一种判别式概率无向图学习模型,它综合了最大熵模型和隐马尔科模型的优点。CRF最早的提出是针对序列数据分析的,现在已经成功应用在生物信息学、机器视觉、网络智能及自然语言处理等领域。指定的观察序列可以应用CRF得到最好的标记序列的概率。该模型最常用的是线性链结构,每一个线性链和一个有限状态机相对应,可应用于序列化数据的标注问题[10]。
令珗x=(x1,…,xT)表示需要标记的长度为T 观察序列,珗y=(y1,…,yT)表示对应于观察序列的标记序列。在本文的复杂名词短语的识别中,珗x代表一个需要标注的句子,珗y对应于词的词性的标签序列。对一个给定的输入序列珗x到状态序列珗y的条件概率,带有参数θ的线性链条件随机场模型将其定义为

式中:Z(珝x)——泛化因子,在线性链模型中,泛化因子的计算可以通过前向后向算法来计算,使用泛化因子是为了保证对给定输入序列,它所有可能的状态序列的概率和为1。fk(yt-1,yt,xt)——观察序列标记位于T 和T-1 的特征函数,特征函数值可以是0、1值,θk是特征权重,也即需要学习的参数,对应于特征函数。条件随机域可以使用最大似然估计法来训练最大后验概率,相对于传统的GIS、IIS算法,L-BFGS收敛的速度更快[11]。
对于输入序列珗x,最佳的标注序列满足

3 结合半监督学习和主动学习的复杂名词短语识别
3.1 主动学习
主动学习:从未标注的样本集中选取出含有效信息最多的样本,来进行人工标注[12]。由于选择标注的样本的价值最大,因此在相同人工标注工作量的情况下能有效提高学习器的性能,另一方面,在达到相同的学习器性能的情况下,能有效减少人工标注工作量。
不确定性抽样的方法是最常用的方法之一,该策略是选取学习器最不确定如何标注的样本进行人工标注。
熵是衡量信息量大小的一个常用的方式,熵值越大说明不确定度也就越大。因此对于一个序列,可以引入总符号熵 (total token entropy,TTE)的概念来衡量一个序列的不确定度

式中:T——输入序列珝x 的长度,m 的范围是所有可能的标签的个数。P (yt=m|θ)——在本模型下,序列中第t个位置被标记为标签m 的边缘概率。对于CRF模型,这个边缘概率可以通过前向后向算法来计算。
Culotta和McCallum 提出一种基于不确定性的策略,称为最小信任度 (least confidence,LC)[12]

式中:珗y*——对于给定的观察序列珝x 最有可能的标记序列。对于条件随机域,信任度可以通过式 (1)来计算。
随着观察序列长度的增加,机器模型对标记序列整体的确信度会逐渐减低,故LC选择策略会偏向于选择较长序列。对于中文的复杂名词短语的识别而言,由于中文句子的长短存在巨大差异,LC偏向于选择长句,而长句中可能含有大量非复杂名词短语成分,故选择长句不一定会对机器模型有很大的改进,反而会增加人工标注的工作量。因此,本文给出一种改进的选择策略(least confidence-2,LC2)
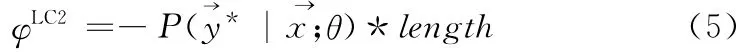
式中:length——句子的长度,使用该策略来改善LC 策略倾向于选择长句的问题。
3.2 结合半监督学习和主动学习的训练算法
半监督学习能够有效结合标签数据和未标签数据来提高监督学习的任务,目前根据半监督学习算法的目的,大致将半监督学习算法分为3类:半监督聚类、半监督回归和半监督分类,目前研究的热点是半监督分类和半监督聚类。
一方面,使用半监督方法选择出学习器比较确信标注正确的样本加入到训练样本集中[13]。使用主动学习选择出需要人工标注的序列中依然可能包含对学习器帮助不大的子序列,例如在中文中一个长句中可能包含许多非复杂名词短语的部分,而这部分内容对学习器的帮助不大,另外这部分内容是学习器也可能很容易被正确标注的,因此,引入半监督的方法,使学习器对这部分子序列采用学习器的自动标注,而人工只标注对学习器价值最大并且学习器对其标签确信度较小的子序列。
另一方面,使用半监督的方法可以作为一种启发式的主动学习样本选择策略[4]。在很多半监督学习算法中,使用学习器对一些未标记序列添加伪标记序列 (pseudo-labels)来训练新的学习器,但这种方式在选择哪些机器标注序列加入伪标注集是个难点。
基于以上,本文提出一种同时使用两种结合方式的算法 (SSAL),算法核心有两点:对于主动学习算法选择出的待标记序列 (也就是一个句子),选择一个序列中的最有价值子序列来进行人工标注,其余子序列由学习器进行标注;在每轮迭代中使用半监督学习的算法来动态更新伪标记序列。
通过对子序列标注的边缘概率的计算可以确定该子序列是采用学习器的标注,还是需要人工来标注。可以按照以下来计算
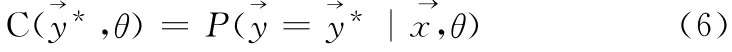
式中:珗y*——对于给定的子序列 珝x 最有可能的标记序列。如果C(珗y*,θ)超过某个置信度阈值T 则可以认为学习器标注正确,否则必须需要人工进行标注。算法如下。
半监督和主动学习相结合的算法:

(1)使用训练集L∪Spsuedo训练模型:CRF1
(2)根据Φ 选择最不确定的q个样本,对每个样本计算子序列的边缘概率C(|),更新Sq

其余子序列加入到样本集Sm
(3)使用模型CRF1标注Sm,人工标注Sq,更新训练集和未标注集

(5)使用L 训练模型CRF2,对U 进行标注,标注结果为
(6)更新伪标注集Spsuedo:

其中,步骤2根据CRF1 对未标注集的标注情况和策略Φ 选择出需要添加可信标签的序列集合,并对集合中的每个序列进一步进行划分成两部分子序列,Sm是当前学习器确信度较大并且对学习器价值不大的子序列的集合,Sq是需要人工标注的子序列的集合。步骤3是对步骤2划分出来的子序列集合分别采用机器标注和人工标注,并将它们加入到训练集中,同时更新未标注集。
4 实 验
4.1 实验数据
本文作为训练和测试数据的语料约12万字,共有2835个句子,每个句子均经过人工严格标注,标注出的复杂名都短语共8674个。例如 “经 [中国人民银行]批准, [泰康人寿保险股份有限公司等五家保险公司]正在紧张筹建中”,其中 “中国人民银行”、“泰康人寿保险股份有限公司等五家保险公司”是人工标注的复杂名词短语。
实验统计评估中,只选择含有3个及以上名词并且不含有介词 “的”的复杂名词短语进行统计,利用人工的正确标注的复杂名词短语作为评价标注来对自动识别结果进行评估,学习器的性能我们采用常用的F-score来评估。
实验结果将在两方面进行对比,一方面是在相同的人工标注样本量的情况下,学习器的性能的比较;另一方面是在学习器达到同样性能的情况下需要人工标注的样本量的比较。
4.2 实验结果
实验中,初始采用2%的标注数据来训练学习器,然后通过每次主动学习的抽样策略选2%的数据进行人工标注,共迭代24次。同时为了与主动学习对比,本文采用每次随机选择2%的数据的方法作为基准测试。置信度阈值T 设置为0.99。
本文进行5组实验,分别来实验本文提出的改进的样本选择策略 (LC2)、本文提出半监督于主动学习相结合的复杂名词短语识别算法 (SSAL)和作为对比的算法学习模型:随机抽样 (RANDOM):每次随机选择句子进行标注。不确定性抽样TTE选择策略:此策略选择熵最大的句子进行人工标记。
不确定性抽样LC选择策略:选择最不确定的句子进行标注。
表1表示在迭代结束时,采用上述各算法的学习器性能,可以看出,相当于随机选择的方式,LC 提高了5.2个百分点,LC2提高了6.8个百分点,而本文给出的半监督与主动学习相结合的算法提高了10.2个百分点。

表1 学习器性能
图1描述在相同的人工标注样本量的情况下,随着人工标注样本的增加,学习器的性能的变化。从图中可以看出,本文提出的半监督与主动学习相结合的算法的性能一直是最优的,样本选择策略LC2也优于其它的样本选择策略。例如在30%的数据作为训练集的情况下对于像 “中国人民银行昨日公布消息”这样的句子,本文给出的半监督和主动学习相结合的算法的识别结果为 “[中国人民银行]昨日公布消息”,能够正确识别出复杂名词短语 “中国人民银行”,而其它的算法的识别结果为 “[中国人民银行昨日]公布消息”错误的将 “昨日”这一词也认为是复杂名词短语的一部分。
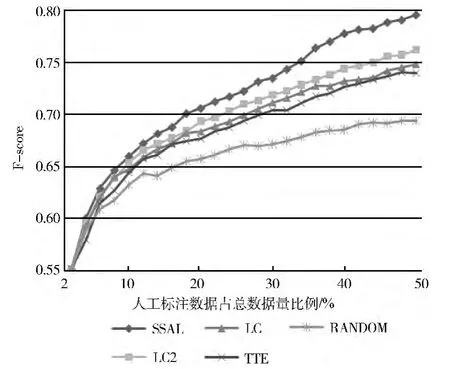
图1 各方法对测试集的F-score曲线
图2描述了当F-score达到0.69时需要人工标注数据的比例,可以看出,在达到此性能下,基于随机选择的算法需要标注48%的样本,而基于半监督和主动学习相结合的算法只需要标注16%的样本,半监督与主动学习相结合算法几乎可以减少32个百分点的人工工作量。
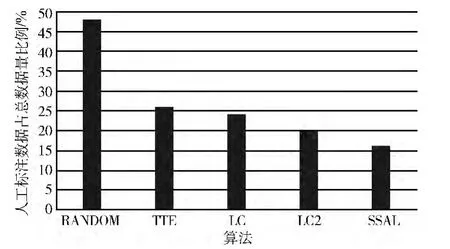
图2 当F-score达到0.69时,基准测试和各算法需要人工标注数据量
5 结束语
本文给出的一种同时在两个方面结合主动学习和半监督学习的算法,一方面启发式地选择需要人工标注样本,选择的样本更加有价值,另一方面划分句子为可以机器标注的子句以及必须需要人工标注的子句,进一步减少人工标注来标注机器容易确定的句子中部分子句,算法有效减少了学习器对人工标注的数据的需求量。在以后的工作中将在两方面进行:探索加强算法对人工错误标注的容错能力;优化置信度阈值T 的选择方式。
[1]ZHOU Qiaoli,ZHANG Ling,CAI Dongfeng,et al.Maximal-length noun phrases identification based on re-ranking using parsing [J].Journal of Computational Information Systems,2013,9 (6):2441-2449.
[2]Gregory Druck,Burr Settles,Andrew McCallum.Active learning by labeling features [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,2009:81-90.
[3]Yann Soullard,Martin Saveski,Thierry Artières.Joint semisupervised learning of hidden conditional random fields and hidden Markov models [J].Pattern Recognition Letters,2014,37:161-171.
[4]Li Mingzhi,Wang Rui,Ke Tang.Combining semi-supervised and active learning for hyperspectral image classification [C]//Proceeding of IEEE Symposium on Computational Intelligence and Data Mining,2013:89-94.
[5]Min Song,Hwanjo Yu,Wook-Shin Han.Combining active learning and semi-supervised learning techniques to extract protein interaction sentences[C]//BMC Bioinformatics,2011.
[6]Zheng Qinghua,Luo Junying,Liu Jun.Automatic term extraction from Chinese scientific texts[C]//Computer Supported Cooperative Work in Design,2011:727-734.
[7]José Aires,Gabriel Lopes,Joaquim Ferreira Silv.Efficient multi-word expressions extractor using suffix arrays and related structures[C]//Proceedings of the 2nd ACM Workshop on Improving Non English Web Searching,2008:1-8.
[8]Zhang Wen,Taketoshi Yoshida,Tang Xijin,et al.Improving effectiveness of mutual information for substantival multiword expression extraction [J].Expert Systems with Applications,2009,36 (8):10919-10930.
[9]ZHOU Qiaoli,LIU Xin,LANG Wenjing,et al.A divideand-conquer strategy for chunking [J].Journal of Chinese Information Processing,2012,26 (5):120-127 (in Chinese).[周俏丽,刘新,郎文静,等.基于分治策略的组块分析 [J].中文信息学报,2012,26 (5):120-127.]
[10]Christopher J Pal,Jerod J Weinman,Lam C Tran,et al.On learning conditional random fields for stereo[J].International Journal of Computer Vision,2012,99 (3):319-337.
[11]La The Vinh,Sungyoung Lee,Hung Xuan Le,et al.Semi-Markov conditional random fields for accelerometer-based activity recognition[J].Applied Intelligence,2011,35 (2):226-241.
[12]Burr Settles,Mark Craven.An analysis of Active Learning strategies for sequence labeling tasks [C]//Proceeding of Conference on Empirical Methods in Natural Language Processing,2008:1069-1078.
[13]Katrin Tomanek,Udo Hahn.Semi-supervised active learning for sequence labeling [C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP,2009:1039-1047.
