利用匹配关系图的Web服务发现方法
2015-12-20傅秀芬
张 进,傅秀芬
(广东工业大学 计算机学院,广东 广州510006)
0 引 言
为避免和相似度低的Web服务进行比较,缩小服务的检索空间,一些学者提出服务聚类的思想[1-10],将功能相似的服务聚合成类,以增大服务定位的粒度。文献 [3]提出语义Web服务聚类方法,将语义功能属性赋予不同权值,根据其语义相似度进行聚类,有效地减少服务查找的空间;文献 [4]利用本体概念间的关系来生成服务的加权图,并采用图论聚类的方法对Web服务进行聚类,简化聚类的计算过程;文献 [5]综合考虑Web服务的功能性参数,采用改进的模糊聚类算法对Web服务进行模糊聚类,有效地提高聚类的精准度。上述研究通过对Web服务进行聚类,提高服务发现的效率,但通过对现有文献的分析,发现目前基于服务聚类的服务发现方法仍存在如下两方面的不足:①只注重聚类算法的分析,很少给出具体的服务发现方法:文献 [6]利用BIRCH 聚类思想进行用户情境聚类,提高聚类的准确性,但没有将服务簇作为一个整体,也没有给出具体的服务发现方法。②针对具体的服务簇进行服务发现时,将服务请求与簇中的Web服务逐一进行比较,没有利用簇中Web服务的共性:文献 [7]从功能相似和过程相似两个层面进行服务聚类和服务发现,提高服务发现效率,但在特定的服务簇中进行匹配时,其将所有Web服务依次取出进行比较,制约了发现效率的进一步提高。
针对上述问题,本文定义了簇中Web 服务的匹配关系,并提出一种利用匹配关系图的服务发现方法。首先利用功能需求的匹配条件定义了同簇中的Web 服务匹配关系,并生成了服务簇的匹配关系图。当在具体的服务簇中进行服务发现时,通过遍历匹配关系图,把多个满足服务请求功能需求的Web服务加入到候选服务集合中,减少服务匹配的次数,提高服务发现的效率。
1 基本概念
语义Web服务是一种运行在Web上自包含、可调用的应用程序,其采用对领域知识抽象描述的本体进行标注,使服务描述带有语义[11]。
定义1 Web服务。Web服务是对功能属性的抽象化描述,可以形式化定义为4 元组WS = (Wid,Wdes,I,O),其中:
(1)Wid是Web服务的名称,用来唯一标识一个服务。
(2)Wdes是Web服务的功能描述,由多个领域本体标注的概念组成。
(3)I= {i1,i2,…}是Web服务输入参数集,其中每个输入参数in都用领域本体进行标注。
(4)O= {o1,o2,…}是Web服务输出参数集,其中每个输出参数on都用领域本体进行标注。
定义2 服务请求。服务请求可形式化定义为三元组WSR= {WRdes,IR,OR},其中:
(1)WRdes是服务请求的功能描述,由多个领域本体标注的概念组成。
(2)IR= {ir1,ir2,…}是服务请求的输入参数集,其中每个输入参数irn都用领域本体进行标注。
(3)OR= {or1,or2,…}是服务请求的输出参数集,其中每个输出参数orn都用领域本体进行标注。
服务簇是通过对服务注册库中Web服务进行聚类预处理形成的Web服务集合,具有同簇之间高度相似、不同簇之间高度相异的特点[12,13],其具体定义如下:
定义3 服务簇。将Web服务集S= {s1,s2,…,sn}进行聚类操作,获得多个聚类簇,每个聚类簇则表示一个服务簇。
通过服务簇,可以避免与相关性小或者不相关的服务进行匹配,有效地减少服务发现的检索空间。当前对于服务簇生成算法已经有了许多的研究,可以直接利用其中提出的一些聚类算法。由于本文是在服务簇基础之上进行研究,不同的聚类算法,并不会产生影响。
2 Web服务匹配关系及匹配关系图
服务簇中的Web服务功能高度相似,但现有基于聚类的服务发现方法并没有利用簇中Web服务存在共性,而是把它当作独立的个体与服务请求进行逐一的比较。本文利用服务请求与Web服务在功能需求上的匹配条件来定义了簇中Web服务自身存在的关系,并对其进行图形化建模以便于统一管理。
2.1 Web服务匹配关系
服务请求与Web服务在功能需求上匹配须满足如下3个条件[7,8]:①Web服务的功能描述与服务请求的功能需求相近或者相同;②Web服务的输入参数须由服务请求提供,即服务请求须满足Web服务正常运转所需参数;③服务请求的输出参数须由Web服务提供,即服务请求者所需的功能结果可通过调用Web服务来获得。Web服务与服务请求只是服务的不同描述方式,形式化定义类似,因此可利用服务请求与Web服务的功能需求匹配条件,来定义同簇中的Web服务之间的匹配关系。
服务簇中的Web服务功能相同或者高度相似,因此同簇中的Web服务均满足匹配的第一个条件,对其进行匹配判断时,则只需满足匹配的其余两个条件。Web服务的输入输出功能属性是由本体标注的参数集组成,可通过其参数的兼容关系来进行匹配判断[7]。
定义4 概念相容性。在本体树中,概念M 相容于概念N,记为M N,须满足如下条件:
(1)M 与N 同义,或者;
(2)M 是N 的一个子类。
参数不仅包含一个概念描述,而且还含有一个数据类型属性,所以在比较两个参数的语义关系时,不仅要比较参数概念的相容性,还要比较参数类型的相容性。
定义5 参数兼容关系。参数A 兼容于参数B,记为A→B,当且仅当:
(1)概念A 相容于概念B,即A B。
(2)Type(A)≤Type(B),其中Type(P)表示参数P 的数据类型的取值范围。如Type(Short)≤Type(Int)≤Type(Double)。
由于概念相容性和数据类型相容性均存在传递的特点,可知参数兼容关系也具有传递性。下面结合服务簇中功能需求的匹配条件和参数的兼容关系给出Web服务匹配关系的定义:
定义6 同一服务簇中的Web服务匹配关系。Web服务WSa匹配于Web 服务WSb,记为WSaWSb,当且仅当:
(1)对于WSb输入参数Ib= {ib1,ib2,…}中任意一个参数ib,WSa输入参数Ia= {ia1,ia2,…}中均存在一个输入参数ia,使得ia兼容于ib,记为

(2)对于WSa输出参数Oa= {oa1,oa2,…}中任意一个参数oa,WSb输出参数Ob= {ob1,ob2,…}中均存在一个输出参数ob,使ob兼容于oa,即

2.2 匹配关系的传递特性
假设存在 Web 服务WSn、WSm,使得服务请求WSrequest匹 配 于WSn,WSn匹 配 于WSm,即WSrequestWSn,、WSnWSm。则根据匹配条件和定义6可知存在如下关系:
(1)对于输入参数有:

其形式化公式为

根据集合理论可知有-in in 关系,将其结合式(3)可得
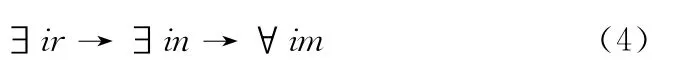
结合兼容关系的传递性有

(2)对于输出参数有:

其形式化公式为

同理上述输入参数中的推导可得如下关系

结合式 (5)、式 (7)和匹配关系的定义,服务请求WSrequest也同时匹配于WSm,即WSrequestWSm,因此Web服务匹配关系存在传递的特性,而基于其传递特性,服务请求能同时查找到多个满足要求的Web服务。
2.3 匹配关系图
一个服务簇中可能存在多个Web服务匹配关系,为了能对其进行统一的管理并充分的利用它们之间传递特性,本文将服务簇中的Web服务及其匹配关系进行图形化建模而生成一个有向图模型,该有向图模型就称为匹配关系图,其具体定义如下:
定义7 匹配关系图。匹配关系图是服务簇中Web服务及其匹配关系的有向图模型,其中节点表示Web服务,节点与节点之间的有向边表示匹配关系,如图1所示。
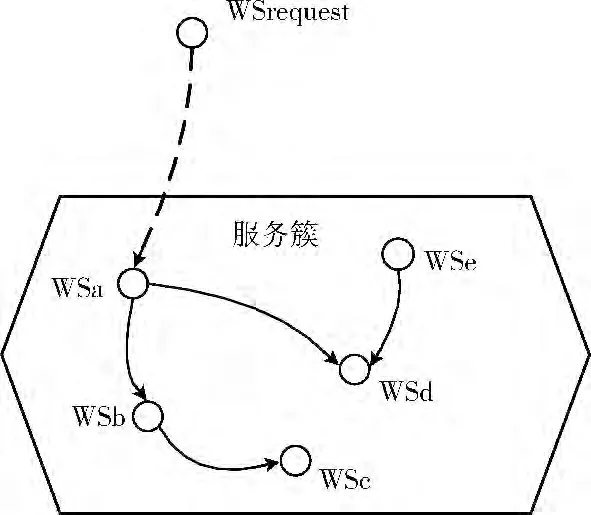
图1 匹配关系
匹配关系图是一个有向图,可用邻接矩阵或邻接链表进行存储,通过对簇中的Web服务进行两两匹配判断来构建图中的有向边。下面给出匹配关系图生成的算法,其匹配关系图采用邻接矩阵进行存储:
算法1:匹配关系图的生成算法
输入:服务簇中的Web服务
输出:服务簇的匹配关系图G
谋事要实,常怀“求是之心”。谋事要实,首在心实,端正心态,树立正确的事业观、政绩观和全局观。谋事要实,贵在情实,摸透实情,提升谋事的质量。谋事要实,重在落实,脚踏实地,做到决策符合实际情况、符合客观规律、符合科学精神。
(1)G [n][n]:=0,其中n 为服务簇中Web服务的个数。
(2)若服务簇中Web 服务已经比较完毕,则转步骤(4),否则从服务簇中依次取出WSi、WSj两个Web服务,其中i≠j。
(3)利用定义6,判断是否满足WSiWSj,若满足则将G[i][j]:=1,否则转步骤 (2)。
(4)返回匹配关系图G。
利用匹配关系图,能同时发现多个Web服务,即若服务请求匹配于服务中的某个Web服务,则也匹配于从这个Web服务节点出发,遍历匹配关系图所得到的Web服务集合,如图1所示,若服务请求WSrequest匹配于WSa,则也同时匹配于WSb、WSc和WSd。相比与传统的逐一比较的方法,利用匹配关系图能有效地减少了服务比较的次数,而在实际的应用中,匹配关系图可提前在预处理中进行生成而不会影响服务发现的效率。
3 利用匹配关系图的服务发现方法
服务簇能有效地减少服务发现的检索空间,但定位到具体服务簇中进行服务查找时,现有的匹配方法还是逐一将服务请求与簇中的Web服务进行比较。本文提出利用匹配关系图的服务发现方法 (RGSD)可通过遍历预先生成的匹配关系图来减少比较次数,提高服务发现效率。
由于匹配关系图是定义在服务簇的基础之上,为了更加有效的在利用匹配关系图和对服务簇进行统一的管理,首先给出了基于匹配关系图的服务簇形式化描述,其定义如下:
(1)Cn表示服务簇名称,来唯一标识一个服务簇。
(2)Cdes是服务簇的语义功能描述。
(3)Cw= {WS1,WS2,…WSn}表 示 服 务 簇 中 的Web服务的集合。
(4)I= {I1∪I2∪…∪In}是服务簇中Web服务的输入集合。其中Ik(1≤k≤n)是Web 服务WSk的输入参数集。
(5)O= {O1∪O2∪…∪On}是服务簇中Web服务的输出集合。其中Ok(1≤k≤n)是Web服务WSk的输出参数集。
(6)Gr表示服务簇的匹配关系图。
在服务发现过程中,首先对服务请求的功能描述WRdes和服务簇的功能描述Cdes进行语义相似度计算,来定位到具体的服务簇。由于服务功能描述都是由多个概念参数组成,并且各Web服务的参数的个数和顺序都是不同的,在计算功能描述的语义相似度时,须先根据概念语义相似度对参数进行配对的处理。
定义9 概念语义相似度[8]。其计算公式如下

式中:dis(A,B)、dismax、dismin的具体定义请参见文献[8]。
参数的配对是通过计算两组参数中的概念概率语义相似度,然后将其值为最小的配为一对。其配对过程可以转化为二分图最优配对,其具体的算法请参见文献 [14],这里不再讨论。图2 表示一个天气预报的服务描述匹配结果示例。
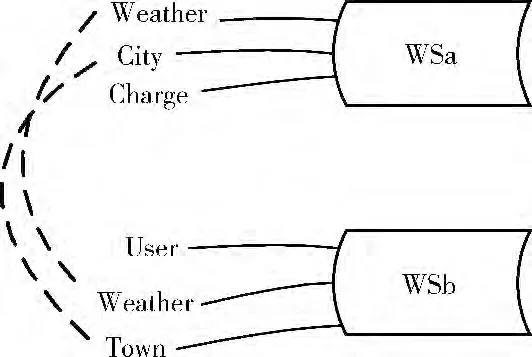
图2 匹配结果
定义10 功能描述的语义相似度。WRdes,Cdes是由参数集构成,可通过如下公式来计算其语义相似度

式中:l——WRdes、Cdes参数匹配对的个数,如图2 示例中,l=2;Dis(WRdes,Cdes)表示WRdes与Cdes之间的语义
当定位到具体的服务簇中进行服务发现时,RGSD 方法可通过如下方式来减少服务比较次数:首先从服务簇中取出的一个Web服务,如果服务请求匹配于该Web服务,从该Web服务所对应的节点出发遍历匹配关系图,把遍历所获得的Web服务节点集加入到要返回的候选服务集中,如果下次取出的Web服务已经在候选服务集中,则可直接跳过而不参与比较。下面给出其服务发现方法的具体步骤:
算法2:基于匹配关系图的服务发现
输入:服务请求WSR= {WRdes,IR,OR};
输出:候选Web服务集合S。
(1)S:= ;
(2)依次取出服务簇RGSC,如果不存在,则转步骤(7);
(3)若sim(WRdes,Cdes)<δ,其中δ为给定阀值,转步骤 (2);
(4)从Cw中取出一个Web服务WSk,若S 中已经包含WSk,则重复该步骤,若Cw中Web服务已经比较完毕则转步骤 (2);
(5)根据匹配条件,判断WSk中输入、输出参数是否满足(-ir→ ik)∧(-ok→ or)关系,若不满足则转步骤 (4);
(6)从Web服务WSk出发,遍历匹配关系图Gr,把得到的Web服务节点,加入S,转步骤 (4);
(7)输出S。
4 仿真实验
本文提出的利用匹配关系图的服务发现方法 (RGSD)是对传统逐一匹配方法所作的优化,和具体的聚类算法无关。下面将通过仿真程序从发现效率和准确率两个维度进行测试并和文献 [3]提出的基于功能需求聚类服务发现方法 (SWSC)进行比较,从而验证本文提出方法的有效性,其中仿真程序是采用java EE、Oracle 11g数据库、Jboss应用服务器进行开发,具体实验设置如下:
仿真实验数据:从seekda.com 网站上下载多个WSDL描述的Web服务,这些Web服务来自5个交叉度很低的不同领域,使得每个领域可以作为一个服务簇并且每个类别中包含300~500个Web服务。从WSDL中抽取关键概念,利用protege工具生成领域本体树。通过OWL-S Editor工具将Web服务转化OWL-S规范,最后将Web服务存入数据库中。
硬件环境:Cpu 2.13GHZ、内存2GB、操作系统Windows7。
实验1 (发现效率):每个类别从数据库中分别取出若干个Web服务,并生成其对应的匹配关系图和服务簇模型。针对若干个随机生成的服务请求,利用RGSD 方法和SWSC方法进行服务发现,记录其比较次数和匹配时间,取其平均值作为结果值,其实验结果如图3、图4所示。
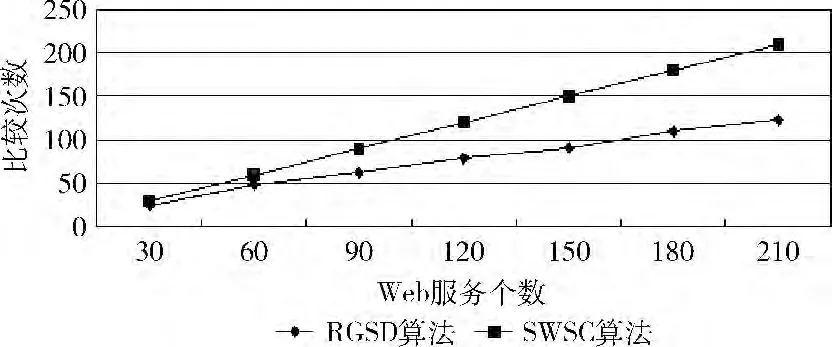
图3 服务发现匹配次数比较
从图3、图4实验结果表明,本文所提方法的匹配效率上要优于文献 [5]的SWSC 方法,并且随着Web服务个数的增加,RGSD 方法能同时匹配的Web服务个数也在增加,使得其在匹配效率上的优势更加明显。
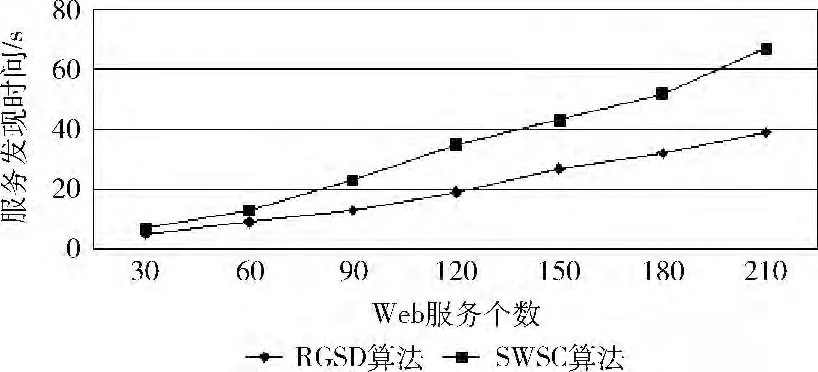
图4 服务发现时间效率比较
实验2 (准确率):每个类别从数据库中分别取出若干个Web服务,并生成其对应的匹配关系图和服务簇模型。针对每个服务簇,自定义一个服务请求,利用RGSD 和SWSC方法进行服务发现,并记录其返回符合服务请求功能需求的Web服务数与返回的Web服务总数之间的比率,取其平均值作为结果值,其实验结果如图5所示。
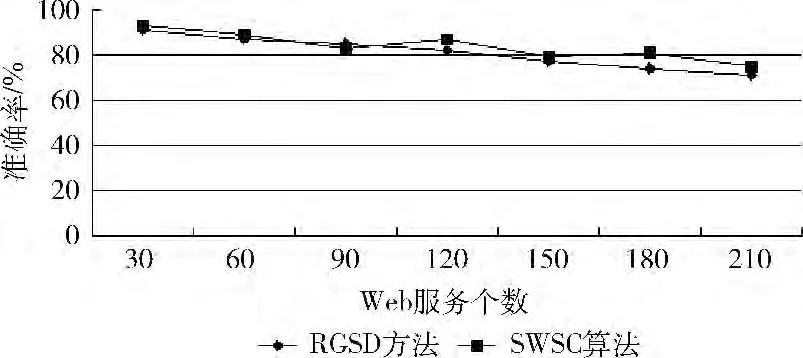
图5 准确率比较
图5实验结果表明,由于本文所提方法在服务发现过程中,一些匹配Web 服务是通过遍历匹配关系图所获得的,会带来一定的精度损失,从而造成匹配准确率要微低于文献 [4]方法,但在总体上仍然能保证较高的准确率。
5 结束语
本文定义了服务簇中Web服务之间存在的匹配关系,论证了该关系具有传递性的特点。在对特定服务簇进行Web服务检索过程中,通过遍历服务簇中的匹配关系图,服务请求可以同时匹配多个满足需求的Web服务,相对于传统的匹配方法要逐一比较的方式,有效减少了服务匹配的次数,提高了服务发现的效率。仿真实验结果表明了该算法的可行性与优越性。接下来的工作将完善匹配关系服务簇模型,将服务质量与服务过程引入服务簇模型。此外,服务的优化组合发现也将是今后的研究重点。
[1]Ngan,Le Duy,Rajaraman Kanagasabai.Semantic Web service discovery:State-of-the-art and research challenges [J].Personal and Ubiquitous Computing,2013,17 (8):1741-1752.
[2]Xu X,Yuruk N,Feng Z,et a1.SCAN:A structural clustering algorithm for networks [C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2007:824-833.
[3]Nayak R,Lee B.Web service discovery with additional semantics and clustering [C]//Proceedings of IEEE/WIC/ACM International Conference on Web Intelligence.Piscataway:IEEE,2007:555-558.
[4]XU Xiaoliang,CHEN Jinkui,WU You.Web service discovery method based on clustering opmizition [J].Computer Engineering,2011,37 (9):68-70 (in Chinese).[徐小良,陈金奎,吴优.基于聚类优化的Web服务发现方法 [J].计算机工程,2011,37 (9):68-70.]
[5]WANG Yongming,ZHANG Yingjun,XIE Binhong,et al.Semantic Web service discovery based on fuzzy clustering optimization[J].Computer Engineering,2013,37 (9):219-223 (in Chinese).[王永明,张英俊,谢斌红,等.基于模糊聚类优化的语义Web服务发现[J].计算机工程,2013,37 (9):219-223.]
[6]YANG Yueming,CHEN Lichao,XIE Binhong,et al.Study on approach of Web services discovery based on clustering of users’context information [J].Computer Engineering and Design,2012,33 (4);1442-1146 (in Chinese). [杨岳明,陈立潮,谢斌红,等.基于用户情境聚类的Web服务发现方法研究 [J].计算机工程与设计,2012,33 (4):1442-1146.]
[7]SUN Ping,JIANG Changjun.User service clustering to facilitate process-oriented semantic Web service discovery [J].Chinese Journal of Computers,2008,31 (8):1340-1353 (in Chinese).[孙萍,蒋昌俊.利用服务簇聚类优化面向过程模型的语义Web 服务发现 [J].计算机学报,2008,31 (8):1340-1353.]
[8]DENG Shiyang,DU Yuyue.Logic Petri net based model for Web service cluster [J].Journal of Computer Applications,2012,32 (8):2328-2332 (in Chinese). [邓式阳,杜玉越.基于逻辑Petri网的Web 服务簇模型 [J].计算机应用,2012,32 (8):2328-2332.]
[9]Nayak R,Lee B.Web service discovery with additional semantics and clustering [C]//Proceedings of IEEE/WIC/ACM International Conference on Web Intelligence.Piscataway:IEEE,2007:555-558.
[10]Wu J,Chen L,Zheng Z,et al.Clustering Web services to facilitate service discovery [J].Knowledge and Information Systems,2014,38 (1):207-229.
[11]WANG Jue,XIANG Chaocan,WANG Meng,et al.Survey on semamtic Web service discovery [J].Application Research of Computer,2013,30 (1):7-12 (in Chinese).[王珏,向朝参,王萌,等.语义Web服务发现研究现状与发展 [J].计算机应用研究,2013,30 (1):7-12.]
[12]CHEN Ke,CHENG Yi,XIE Mingxia,et al.Spatial information service automatic discovery based on service cluster [J].Computer Engineering,2012,38 (24):182-190 (in Chinese).[陈科,成毅,谢明霞,等.基于服务簇的空间信息服务自动发现[J].计算机工程,2012,38 (24):182-190.]
[13]LUAN Wenjing,DU Yuyue.Web service discovery method based on net unit model of service cluster[J].Computer Science,2012,33 (8):147-152(in Chinese).[栾文静,杜玉越.一种基于服务簇网元模型的Web服务发现方法 [J].计算机科学,2012,33 (8):147-152.]
[14]DENG Shuiguang,YI Jianwei,LI Ying,et al.A method of semantic Web service discovery based on bipartite graph matching [J].Chinese Journal of Computers,2008,31 (8):1364-1374 (in Chinese). [邓水光,尹建伟,李莹,等.基于二分图匹配的语义Web服务发现方法 [J].计算机学报,2008,31 (8):1364-1374.]
