以主观线索为特征的主观性文本识别
2015-12-20刘勇华李爱萍段利国王鸿翔
刘勇华,李爱萍,段利国,邸 鹏,王鸿翔
(太原理工大学 计算机科学与技术学院,山西 太原030024)
0 引 言
文本情感分析的前提是对文本中主观成分的识别和提取。例如:在文本情感分析中[1],处理的文本类型就是主观性文本。事先对文本进行主观性判别是很有必要的,不仅可以有效地减少分析的范围,还可以提高分析的速度和精确度。主观文本识别主要有两种方法,基于词典和基于统计。基于词典的方法利用事先建立的情感词典 (可以人工标注或是机器统计),统计文本中的词语是否含有情感,再进一步判别文本主客观性[2],这种方法非常依赖情感词典。基于统计的方法利用训练好的数据模型,采用机器学习的方法,对待测文本进行判别[3]。常用的机器学习方法有:朴素贝叶斯 (NB)、支持向量机 (SVM)、决策树、K最近邻、最大熵模型等。这种方法在训练数据的标注、特征选取、分类器的选取等方面具有一定的局限性。目前,学者们为了得到更高的准确率和更快的分类效率,大多数采用基于词典和基于统计相结合的方法进行文本主观识别[4-6,9-11]。针 对 包 含 丰 富 情 感 信 息 的 主 观 线 索 研 究 还 较 少,比如复杂句式的关联词特征研究较为缺乏。因此,本文将关联词、情感词以及指示性动词、感叹词、程度副词、带有情感色彩的标点符号等6种主观线索成分作为分类特征,建立主观线索特征词表,用朴素贝叶斯分类器对文本的主客观性进行判别。
1 相关知识
1.1 主客观文本定义
(1)主观性文本是指作者对于非事实的描述的文本,通常带有一定的个人情感色彩。主观性文本主要分为两类:评价和推测[4]。
目前,主客观文本分类方面,主要是针对评价型的文本进行研究。例如:“我认为iPhone挺好,值得拥有。”。
(2)客 观 性 文 本 定 义 请 参 见 文 献 [5]。例 如:“iPhone4永远是一部经典,无法超越。”。
中文主观性文本和客观性文本之间存在很大的区别,主观性文本一般表达人们的情感、看法或是态度,表达的形式也是多样化,不是规范型的文本,时常出现不规范的词语和结构等。主观性文本识别主要以情感词为主,利用各种文本特征表示方法和分类器 (一般采用朴素贝叶斯分类器)进行分类识别[7]。
1.2 文本分类过程
文本分类过程如图1所示。

图1 文本分类过程
其中预处理环节包含中文分词、分句、去停用词等过程。特征表示包括特征选择、特征提取及特征值计算。
1.3 朴素贝叶斯
朴素贝叶斯(Naive Bayes,NB)定义请参见文献[4]。
对需测试文本D= {T1,T2,…,Tn},由于NB是基于特征相互独立的假设下,判别其属于主观、客观类别C={CS,CO},分类算法如式 (1)所示
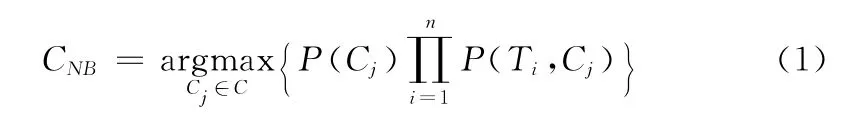
其中,P(Cj)表示类别Cj的先验概率,P(Ti,Cj)表示特征Ti出现在类别Cj中的后验概率。
先验概率P(Cj)的计算公式如式 (2)所示

式中:D(Cj)——类别Cj中的文本数。
后验概率P(Ti,Cj)是特征Ti出现在类别Cj中的概率,并且为防止0概率的出现进行平滑调整,计算公式如式 (3)所示

其中,P(Ti,Cj)为特征项Ti在类别Cj的文本中出现的次数,式 (4)中M 为特征项Ti在所有类别的文本中出现的次数总和。
2 主观线索特征
主观线索特征包括情感词、第一或第二人称代词、不规范的标点符号、带有情感色彩的标点符号、感叹词、程度副词、发表看法或意见的动词 (指示性动词)、不精确的数字或日期、关联词等9种特征。本文选取关联词、情感词以及与指示性动词、感叹词、程度副词、带有情感色彩的标点符号等6种主观线索特征作为主观性文本识别依据。下面具体介绍每种特征以及特征提取算法。
2.1 情感词
具有情感的词的统称为情感词,以带有情感的动词和形容词居多。当人们陈述的句子中出现正、负面的情感词语或评价词语时,这个句子是主观句的可能性很大。例如:“我喜欢iPhone。”、“iPhone外观好看。”。本文所用的情感词是HowNet情感分析用词语集中中文正负面情感词语和正负面评价词语,其分布情况见表1。

表1 情感词分布情况
算法1:情感词提取算法
输入:给定的文本D
输出:情感词集合q
步骤1 对给定的文本分句、分词并进行词性标注处理后得到文本特征词序列集合

步骤2 利用HowNet情感分析用词语集中中文正负面情感词语和正负面评价词语建立情感词表Q,Q 可用如式(6)表示
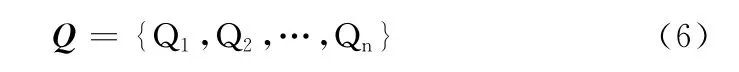
步骤3 利用建立好的情感词表Q 统计给定的文本D中的情感词,得到情感词集合q

2.2 指示性动词
当人们对于某种事物表述自己的观点或态度时,往往会采用一些诸如 “感觉”、 “认为”等一类的主张词语,并且这些主张词语往往会伴随第一、第二和第三人称代词一起出现,那么这一类的句子是主观句的可能性很大。例如:“我感觉iPhone真心不错,你值得拥有。”。本文使用的指示性动词是HowNet情感分析用词语集中中文主张词语,其分布情况见表2。

表2 指示性动词分布情况
算法2:指示性动词提取算法输入:给定的文本D
输出:指示性动词集合z
步骤1 与算法1的步骤1相同;
步骤2 利用HowNet情感分析用词语集中中文主张词语建立指示性动词表Z,Z 可用如式 (8)表示
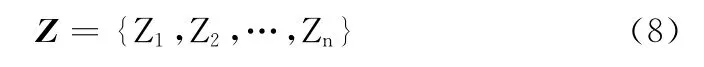
步骤3 利用建立好的指示性动词表Z 统计给定的文本D 中的指示性动词,得到指示性动词集合z
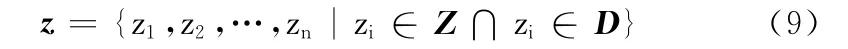
2.3 感叹词
感叹词是用于表达各种感情的词,它与后面句子的其余成分没有语法联系,并且能更好地帮助人们表达自身的情感倾向。当某个句子中出现 “啊”、“哎呀”、“天呀”等的感叹词时,这个句子很可能是主观句。例如:“哎呀,我把iPhone落家了。”。本文通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的感叹词,具体分布情况见表3。

表3 感叹词分布情况
算法3:感叹词提取算法
输入:给定的文本D
输出:感叹词集合g
步骤1 与算法1的步骤1相同;
步骤2 通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的感叹词,建立感叹词表G,G 可用如式 (10)表示

步骤3 利用建立好的感叹词表G 统计给定的文本D中的感叹词,得到感叹词集合g

2.4 程度副词
通常,人们为了增强自己表达的情感,往往会使用一些程度副词加以修饰。当某个句子中含有如 “非常”、“很”、“相当”等之类的程度副词时,这个句子是主观句的可能性很大。例如: “iPhone性能相当好,我非常喜欢。”。本文使用的程度副词是HowNet情感分析用词语集中中文程度级别词语,具体的分布情况见表4。

表4 程度副词分布情况
算法4:程度副词提取算法
输入:给定的文本D
输出:程度副词集合cd
步骤1 与算法1的步骤1相同
步骤2 利用HowNet情感分析用词语集中中文程度级别词语建立程度副词表CD,CD 可用如式 (12)表示

步骤3 利用建立好的程度副词表CD 统计给定的文本D 中的程度副词,得到程度副词集合cd
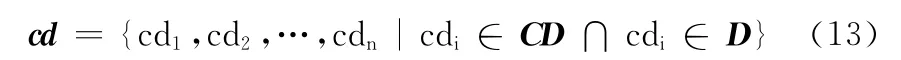
2.5 带有情感色彩的标点符号
句子中问号的出现表示人们在质疑某事物,带有不确定性;而感叹号的出现则表示人们对事物吃惊、喜悦、叹息等的态度,带有一定的情感。这两种标点符号都能表达人们内心的情感。由于这两者在主观性文本中出现频率居多,很少在客观性文本中出现,因此,本文将带有情感色彩的标点符号作为识别主观性文本的一种特征。例如:“iPhone各个方面都挺好,难道你不想拥有一部吗?”、“iPhone音质真好!”。而在有些句子中经常会出现问号、感叹号连用的现象,表达更为强烈的情感,例如:“iPhone各个方面都挺好,难道你不想拥有一部吗???”、“iPhone音质真好!!!”。本文通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的带有情感色彩的标点符号,具体分布见表5。
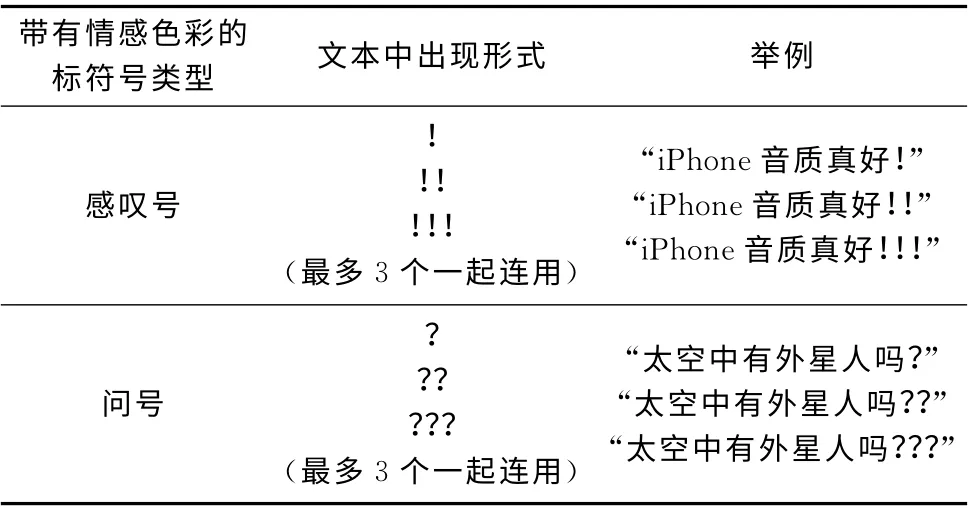
表5 带有情感色彩的标点符号分布情况
算法5:带有情感色彩的标点符号提取算法
输入:给定的文本D
输出:带有情感色彩的标点符号集合bd
步骤1 与算法1的步骤1相同
步骤2 通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的带有情感色彩的标点符号,建立带有情感色彩的标点符号表BD,BD 可用如式(14)表示

步骤3 利用建立好的带有情感色彩的标点符号表BD统计给定的文本D 中的带有情感色彩的标点符号,得到带有情感色彩的标点符号集合bd

2.6 关联词
复句、分句的定义请参见文献 [8]。本文研究的是以关联词所表示的复句类型,关联词表达人的逻辑认知,具有一定的主观性。人们对于客观事实根据自己所要表达的意思来选择用或不用关联词、用哪一种关联词,这种选择性表达就是一种主观性。
本文从以下两个方面来分析关联词语的主观性:
(1)文章中关联词的使用率:本文选择中国经济网的时政新闻 《外交部:越南冲击我警戒区及船只1416艘次》、九九文章网的影评书评 《〈水煮三国〉读后感》两篇文章为代表分析关联词的主观性。通过对文章中的句子总数、复句数、关联词组数进行统计,分析关联词对主观句的影响,结果见表6。
由表6的统计结果可知,在新闻体裁的文章中复句的使用率很高,而关联词的使用率较低;在书评体裁的文章中,复句的使用率相对比较低,而关联词的使用率却很高。新闻体裁的文章讲述的是客观事实,一般比较客观;书评体裁的文章是评价型的文章,一般带有作者的观点、态度或是意见,主观性比较强。从上述两种体裁关联词的使用来看,比较客观的文体关联词的使用率低,主观性强的文本关联词的使用率较高。由此可得,关联词对主观性的表达具有一定的影响。

表6 两文章中复句和关联词组使用比例
(2)对同一客观事实使用不同的关联词:对于同一个客观事实,表达的方式可以使用单句,还可以使用复句,其中复句可以是关联词的复句,也可以不使用关联词。对于同一个客观事实,想要表达不同的主观认知,就会使用不同的关联词。比如对于客观事实 “天阴了,要下雨”,没有关联词的连接就是一个表达客观事实的复句,而使用不同的关联词将其连接就构成了不同类型的复句:
因为天阴了,所以要下雨。
不仅天阴了,而且要下雨。
只有天阴了,才要下雨。
如果天阴了,就要下雨。
上述例句涉及4 种类型的复句,分别是因果、递进、条件、假设关系的复句。利用关联词,可以使分句间的意义关系明确地表达出来。换句话说,句子中本来就包含分句间的意义关系,而使用关联词之后使分句间的逻辑关系更加凸显出来。对于同一客观事实来说,理论上只存在一种意义关系,在使用不同的关联词连接后却表达了不同的意义。由此可以说明关联词带有一定的主观性。
综上所述,关联词的使用一般会带有使用者的主观逻辑认知,对主观句的识别具有一定的作用。本文通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的关联词。一般来说,文本中的关联词都是成对出现,常用的关联词分布情况见表7。
算法6:关联词提取算法
输入:给定的文本D
输出:关联词集合gl
步骤1 与算法1的步骤1相同
步骤2 通过对训练语料中大量主观性文本的观察与研究,统计出适合主观性文本识别的关联词,建立关联词表GL,GL 可用如式 (16)表示
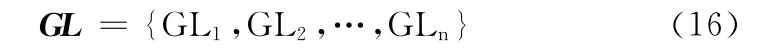
步骤3 利用建立好的关联词表GL 统计给定的文本D中的关联词,得到关联词集合gl


表7 常用关联词分布情况
上述论述特征对主观句具有一定的识别作用,本文利用这6种特征建立一个主观线索特征词表ZG,如式 (18)所示,将主观线索特征词表ZG 中包含的各个特征作为识别主观性文本的特征,再利用朴素贝叶斯分类器进行主观性文本识别
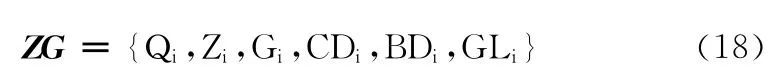
3 实验及实验结果分析
3.1 实验语料库
本文实验数据采用了2008年中文倾向性分析评测提供的 中 文 语 料 集COAE2008。COAE2008 (Chinese opinion analysis evaluation,COAE2008)语料集是第一届中文倾向性分析评测的训练语料,由中科院计算所和洛阳外国语学院共同整理和标注完成,近40000 篇文本,其中具有观点倾向性文本数量超过4000 篇,语料涉及的领域有影视娱乐、财经、教育、房产、电脑、手机等领域的网页,提取后整理成txt纯文本形式,文章从几个句子到上百个句子不等。
本文利用主观线索特征词表中包含的各个特征作为主观文本识别特征,通过人工标注筛选的方法,从COAE2008语料集中选取主观性和客观性明确的文本各500个,其中300个主观文本和300个客观文本作为训练数据,另外的200个主观文本和200 个客观文本作为测试数据。表8为训练和测试数据的分布情况。

表8 训练和测试数据分布情况
3.2 实验步骤
(1)数据预处理:本文利用哈工大社会计算与信息检索研究中心编制的语言技术平台 (LTP)分句工具对数据进行分句,中科院计算机所编制的中文分词 (ICTCLAS)工具对数据进行分词,再借助停用词表去停用词。
(2)特征表示:特征表示包括特征选择、提取及其值的计算,常用的特征提取算法有信息增益、文档频率、CHI统计、相对熵和互信息等。本文利用文档频率的方法对主观性文本进行特征提取,将文本向量化表示,具体步骤如下:
步骤1 对给定的文本分句、分词并进行词性标注处理后,得到文本特征词序列集合,形式如式 (19)所示
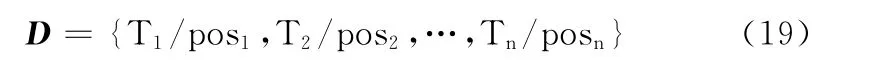
其中,Ti为特征词,posi为特征词的词性。
步骤2 利用主观线索词表ZG 统计文本中各个特征出现的次数,得到主管线索特征集合X
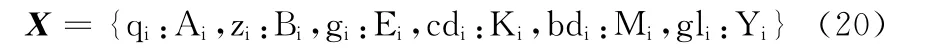
其中,i=1,2,…,n,Ai,Bi,Ei,Ki,Mi,Yi分别表示特征qi,zi,gi,cdi,bdi,gli出现的次数。
步骤3 利用文档频率的方法分别计算P(qi),P(zi),P(gi),P(cdi),P(bdi),P(gli)计算公式如式 (21)所示

其中,N 为文本中所有特征数总和,由于P(qi),P(zi),P(gi),P(cdi),P(bdi),P(gli)计算方法一样,计算时只需将式 (21)的分子替换成其它主观线索特征出现的次数。步骤4 将文本向量化表示成式 (22)所示的形式

(3)训练分类器:利用向量化的训练数据训练朴素贝叶斯分类器,生成分类模型。
(4)测试数据:利用上述分类模型对测试数据进行分类。
3.3 实验结果分析
实验环境是使用MyEclipse 8.5进行实验,实验时所用的机器型号是联想Y480,机器的主要配置为intel酷睿i5 3210 M 处理器,4G 内存,2.5GHz主频。实验所采用的评价指标是准确率P

式中:Tr(Cj)——分类正确的文本数,N(Cj)——属于类别Cj的文本数。
本文总共做了3组实验,分别为采用传统朴素贝叶斯进行实验、用朴素贝叶斯+主观线索 (不含关联词)进行实验、本文提出的方法进行实验。表9 为3 组实验统计结果。

表9 实验统计结果
最后,本文对3组实验进行对比,得出3组实验对比结果见表10。
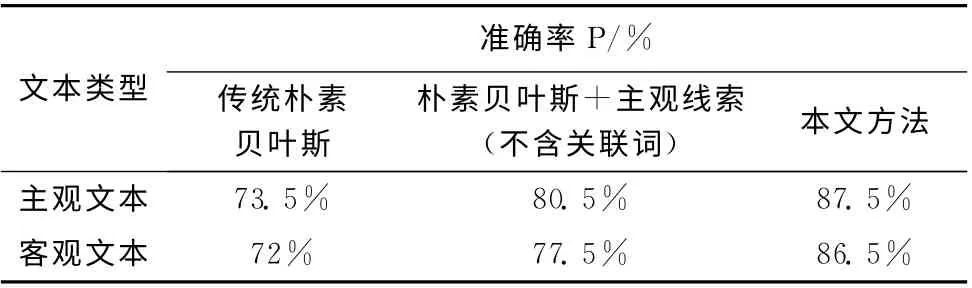
表10 3组实验对比结果
由表10的3组实验对比结果可以看出,主观线索特征的加入对分类性能有一定的提升,而含有关联词的主观线索特征的加入对分类性能的提升更加明显。实验表明,主观线索对主观性文本识别有一定的帮助,含有关联词的主观线索特征比不含有关联词的主观线索特征识别性能要好些。
4 结束语
本文分析了关联词对主观性文本识别的作用,并将关联词加入到主观线索特征中,作为主观性文本识别的特征。实验结果表明,主观线索对主观性文本识别有一定的帮助,含有关联词的主观线索特征比不含有关联词的主观线索特征分类性能要好些。本文主要针对主观性文本识别进行研究,对如何准确有效识别出主观性文本进行分析,提出关联词、情感词以及与指示性动词、感叹词、程度副词、带有情感色彩的标点符号等6种主观线索成分作为主观性文本识别依据,建立主观线索特征词表,用朴素贝叶斯分类器对主观性文本进行识别,为解决主观性文本识别提供可行的方法。
今后的研究工作从两个方面展开:①提高分词和分句的准确率,现有的分词和分句工具准确率不高,这对主观线索的判别有很大影响。②继续探讨其它的可以作为主观性文本识别的主观线索特征。
[1]ZHAO Yanyan,QIN Bing,LIU Ting.Sentiment analysis[J].Journal of Software,2010,21 (8):1834-1848 (in Chinese). [赵妍妍,秦兵,刘挺.文本情感分析 [J].软件学报,2010,21 (8):1834-1848.]
[2]YANG Jiang,HOU Min,WANG Ning.Sentiment polarity analysis of reviews based on shallow text structure[J].Journal of Chinese Information Processing,2011,25 (2):83-88 (in Chinese).[杨江,侯敏,王宁.基于浅层篇章结构的评论文倾向性分析 [J].中文信息学报,2011,25 (2):83-88.]
[3]LIAO Xiangwen,LI Yihong.Identification of chinese opinion sentences based on n-gram hyperkernel function [J].Journal of Chinese Information Processing,2011,25 (5):89-93 (in Chinese).[廖祥文,李艺红.基于N-gram 超核的中文倾向性句子识别 [J].中文信息学报,2011,25 (5):89-93.]
[4]YANG Wu,SONG Jingjing,TANG Jiqiang.A study on the classification approach for Chinese MicroBlog subjective and objective sentences [J].Journal of Chongqing University of Technology (Natural Science),2013,27 (1):51-56 (in Chinese).[杨武,宋静静,唐继强.中文微博情感分析中主客观句分类方法 [J].重庆理工大学学报 (自然科学),2013,27(1):51-56.]
[5]YAO Tianfang,PENG Siwei.A study of the classification approach for Chinese subjective and objective texts [C]//The Third National Information Retrieval and Content Security Conference Proceedings,2007 (in Chinese). [姚天昉,彭思崴.汉语主客观文本分类方法的研究 [C]//第三届全国信息检索与内容安全学术会议论文集,2007.]
[6]GUO Yunlong,PAN Yubin,ZHANG Zeyu,et al.Multipleclassifiers opinion sentence recognition in Chinese micro-blog based on D-S theory [J].Computer Engineering,2014,40(4):159-163 (in Chinese).[郭云龙,潘玉斌,张泽宇,等.基于证据理论的多分类器中文微博观点句识别 [J].计算机工程,2014,40 (4):159-163.]
[7]LI Xiaojun,DAI Lin,SHI Hanxiao,et al.Survey on sentiment orientation analysis of texts[J].Journal of Zhejiang University (Engineering Science),2011,45 (7):1165-1173 (in Chinese).[厉小军,戴霖,施寒潇,等.文本倾向性分析综述 [J]. 浙 江 大 学 学 报 (工 学 版),2011,45 (7):1165-1173.]
[8]WANG Wenqi.The subjectivity of connectives of chinese complex sentences[J].Journal of Shanxi Datong University (Social Science),2012,26 (2):80-83 (in Chinese). [王文琦.复句中关联词语的主观性考察 [J].山西大同大学学报 (社会科学版),2012,26 (2):80-83.]
[9]WEI Xiangfeng,ZHANG Quan,MIAO Jianming,et al.Event sentiment analysis based on semantic chunks[J].Journal of Chinese Information Processing,2012,26 (3):44-48 (in Chinese).[韦向峰,张全,缪建明,等.基于语义块的事件倾向性分析研究[J].中文信息学报,2012,26 (3):44-48.]
[10]DANG Lei,ZHANG Lei.Method of discriminant for Chinese sentence sentiment orientation based on HowNet[J].Applica-tion Research of Computers,2010,27 (4):1370-1372 (in Chinese).[党蕾,张蕾.一种基于知网的中文句子情感倾向判别方法[J].计算机应用研究,2010,27 (4):1370-1372.]
[11]SUN Jianwang,LV Xueqiang,ZHANG Leihan.Short text classification based on semantics and maximum matching degree[J].Computer Engineering and Design,2013,34 (10):3613-3618 (in Chinese).[孙建旺,吕学强,张雷瀚.基于语义与最大匹配度的短文本分类研究 [J].计算机工程与设计,2013,34 (10):3613-3618.]
[12]Taboada M,Brooke J,Tofiloski M,et al.Lexicon-based methods for sentiment analysis [J].Computational linguistics,2011,37 (2):267-307.
