基于多特征的实时立体视觉检测方法
2015-12-20谭治英
刘 博,陈 剑,周 平,谭治英
(中国科学院 合肥物质科学研究院 先进制造技术研究所,江苏 常州213164)
0 引 言
当前机器人、智能移动平台已经取得了较好的发展和应用,但是在一些需要精密装配和微细操作的稍高技术场合的应用中却遇到了很大的障碍,尤其在一些工序复杂,检测精度要求高,工作效率很高的场合,传统机器人、智能移动设备几乎不可用或是很难应用,或是成本代价很高[1,2]。为解决上述问题,需要解决的关键技术就是满足实时性的高精度立体视觉检测。近年来,在机器人导航、车辆自动驾驶及基于视觉导航的移动平台等领域,国外对于立体视觉检测技术开展了大量研究工作,但大部分研究工作集中在道路、室外等大场景下目标感兴趣区域的识别[3,4]或者场景分割[5,6]。国内学者在立体视觉检测领域也开展了大量研究工作,目前已经取得了一系列的研究成果。有学者提出一种频率域和空间域相结合的方法进行3D 特征匹配[7];有学者在三维重建技术研究中,提出了一种通过硬件的并行计算解决3D 场景重建中的大规模数据处理的方法[8];吴晓军等提出一种基于可见外壳与多视图三维点云有机融合的多视图立体三维重建孔洞修复算法,用于增加三维重建算法的鲁棒性[9];李怀泽等提出了一种基于旋转多视角的立体视觉图像特征匹配方法[10];刘海涛等提出了一种基于流形学习的三维步态识别方法[11]。
然而,上述国内外研究中所提到的方法,多侧重于目标识别准确率提升方面的研究,使立体视觉检测能够达高精度,并能同时满足实时性要求的方法还比较少。本文通过使用两个低分辨率的双目立视觉相机获取目标在立体视觉下的图像,使用Harris进行角点特征提取时融合激光器特征,增加特征提取准确率,并采用基于图像轮廓方向向量的图像金字塔特征结合线激光特征的方法进行目标初步检测,然后结合立体视觉图像特征及激光位移传感器所提供的精确位移信息,控制高分辨率单目相机结合感兴趣区域的元件图像先验知识特征进行精确检测。通过分析多种不同的视觉、激光传感器的特征信息特点,提出了一种基于多特征的实时立体视觉检测方法,从而在保证较小时耗的情况下实现了立体视觉系统的精确检测。最后通过实验分析了该方法的可行性。
1 基于双目视觉及激光特征的粗略检测
基于立体视觉的检测主要包括场景3D 坐标云数据的获得以及场景的检测两部分,通过场景检测获取目标的图像位置信息,结合场景的3D 坐标云数据从而实现目标在3D空间中的立体检测。本文在检测算法不同的阶段采用了相应的特征融合方法,从而使最终的检测算法同时满足较小的时耗性和较高的检测精度。
1.1 双目立体视觉3D云数据的获取
双目立体视觉3D 信息获取是基于视差原理[12],如图1和式 (1)所示。
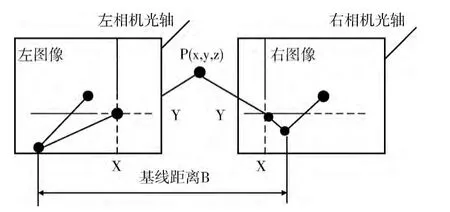
图1 双目立体成像原理

式中:ZC——物体表面特征点到左、右摄像机光心平面的垂直距离;(Xw,Yw,Zw)——特征点的世界坐标系坐标;(U0,V0)——图像中心的像素坐标;(U,V)——被测点的图像坐标系坐标;dx、dy——在水平和垂直方向上相邻像素之间的物理距离;R——一个3*3 的旋转矩阵;T——一个平移向量。
双目立体视觉3D 云数据获取过程如图2所示。
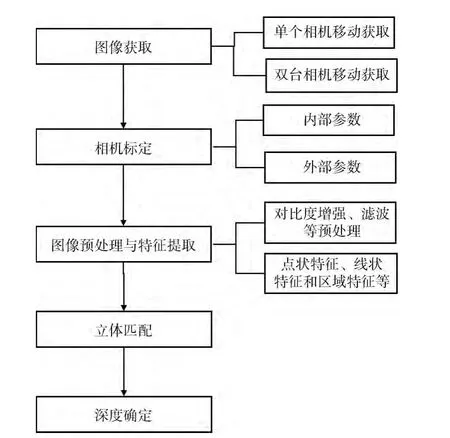
图2 双目立体视觉3D 云数据获取流程
本文采用了一种融合了激光器特征的Harris角点检测算法进行特征提取,其中Harris角点提取实现原理如下[13]

式中:Ex,y——窗口 内 的 灰 度 变 化 度 量;wx,y——窗 口 函数,一般定义为wx,y=e(x2+y2)/σ2;I——图像灰度函数。可见角点的获取主要是通过窗口内的灰度值变化获得,而像素灰度值容易受到外界环境变化的影响,从而影响角点特征提取的准确性。考虑到进行相机标定特征提取时,标定板的图像区域是黑白相间的网格图,如图3所示。

图3 双目立体视觉系统平台及相机标定设备
本文采取的方法是控制点激光器在标定板上成像,其中激光器成像在图像中有如下显著特征:在颜色特征方面,激光器在图像中的产生的标志点对于函数
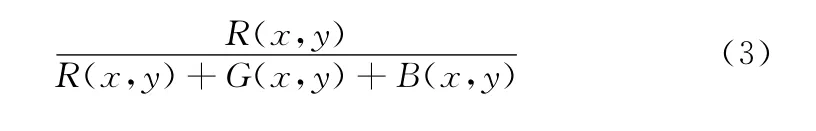
有较强响应 (其中,R、G、B 分别为图像中的颜色分量)。再结合激光标志点的形状特征,从而能够获取激光标志点在图像中位置。统计以标志点为中心的矩形框内的灰度直方图信息,如图4所示。

图4 基于激光器特征的直方图统计模型
由于标定板的网格特性,矩形框被分为多个 (图4 模型中为P1-P4这4个)黑白区域,进行区域内的直方图统计,则统计特性会出现两个明显的峰值,分别对应灰度值Imin和Imax,利用上述灰度值取Imin+μ,Imax-μ为阈值将图像进行分段二值化后再代入式 (2)进行角点检测,从而增加了颜色特征明显的像素权重,从而抑制了灰度变化的过渡区域像素对于角点位置的影响,提高角点检测的准确性。
经过相机标定后就可以获得相机的内参以及两个摄像机之间的相对位姿关系,代入式 (1)便可得到场景的3D云数据。
1.2 3D目标的识别
考虑到在一般场合下待识别的元件与背景之间存在比较明显的轮廓特征,所以本文采用了一种基于轮廓方向向量的图像金字塔特征结合线激光特征的方法进行3D 目标识别。
在目标模板创建和检测过程中,首先使用图像预处理及双边滤波的方法获取模板点与带匹配点的边缘方向向量,然后计算模板中所有点的归一化方向向量和搜索图像相应区域的归一化方向向量的点积的总和,并以此作为匹配度量值,计算公式如下所示

其中,d′= (ti,ui)T,ex,y= (vx,y,wx,y)T分别为模板和搜索区域所对应的方向向量,为匹配度量值。方法中使用了归一化处理,从而很大程度上减小线性的光照变化等外界干扰因素。
传统的图像金字塔是将图像与模板多次缩小2倍建立起来的数据结构,如图5所示。首先在图像金字塔最高层上搜索,得到模板的所有实例都将追踪到图像金子塔的最底层[14]。
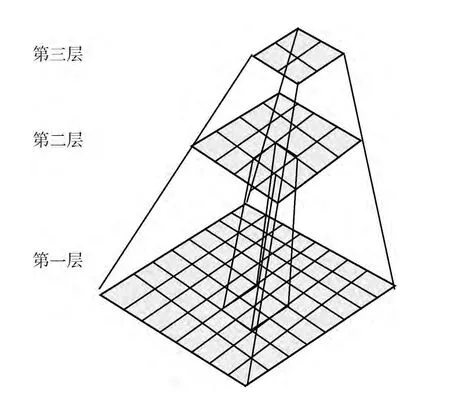
图5 图像金字塔数据结构
虽然这种做法对于较大模板的搜索区域非常小,跟踪匹配到金字塔最底层能够大大减小耗时,但对于金字塔顶层搜索时由于分辨率较低,误匹配率较高,如果所有的误匹配都跟踪到金字塔的最底层,对于匹配耗时和准确率都会产生不利影响。本文采用了图像金字塔特征与线激光特征相结合的方法,同样首先在图像金字塔的最高层进行搜索,一旦搜索到候选区域,则启动线扫描激光特征检测,如图6所示。

图6 图像金字塔搜索过程
上述A、B、C这3个候选区域包含两个误检测区域,通过线激光的特征运用形态学处理,可以排除误检测区域,如图7,图8所示。

图7 线激光特征检测平台
根据线激光在物体表面形状特征的变化,运用形态学等图像处理算法可以实现对于候选区域的检测,从而为后续模板检测提供更精确的候选区域及降低时耗性,3D 目标检测结果如图9所示。
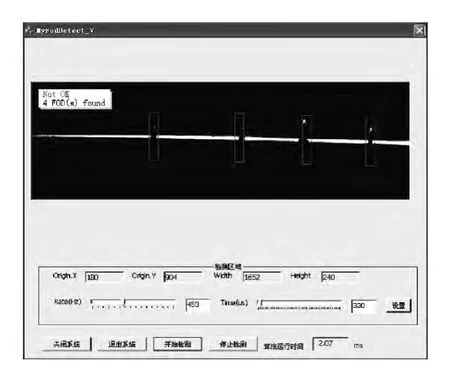
图8 线激光特征检测结果
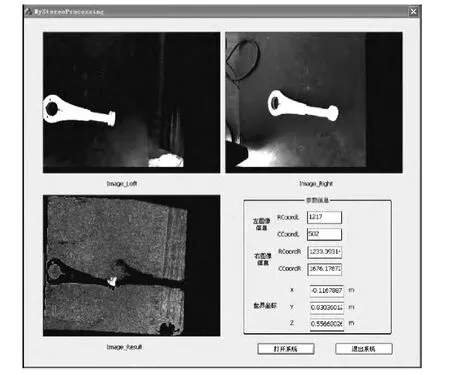
图9 双目立体视觉的3D 目标检测
其中,“Image_Left”、“Image_Right”分别为双目立体视觉系统中左、右两相机采集到的图像,”Image_Result”为在深度信息图中的3D 目标检测结果,“参数信息”中为感知过程中的参数信息及场景目标的最终坐标信息(以左相机的相机坐标系原点作为世界坐标系的原点)。
2 基于感兴趣区域的精确检测
本文使用的机器人机械控制平台如图10所示。
机器人控制系统按照粗略检测信息将固定在机器人手臂上的高分辨率单目相机移动到场景目标感兴趣区域的预设相对位置处,通过激光位移传感器提供的位移信息,从而实现目标的精确检测。
通过目标的粗略检测,可以获取目标检测元件相对小范围的感兴趣区,感兴趣区域形状结构比较单一,所以使用单目相机进行感兴趣区域检测时,根据元件形状的先验知识采用针对规则图形的特征检测算法,从而减小整个过程的时耗,例如针对前面图9中的3D 检测目标,其左侧部位有一个形状规则的元件孔,本文采用了根据元件先验知识限定参数区间的Hough圆检测方法进行感兴趣区域的检测,从而提高Hough圆检测算法精度并减少耗时。

图10 双臂机器人机械控制平台
3 实验及结果分析
进行目标初步检测的双目立体视觉系统使用两个德国AVT 公司Prosilica GC660工业相机组成,相机的分辨率为659×493,帧率119fps,像元尺寸5.6μm。镜头采用日本KOWA 工 业 千 万 分 辨 率 高 清 镜 头LM12JC10M:2/3″12mm/F1.8,10Megapixel。感兴趣区域精确感知的单目相机使用的是德国AVT 公司Prosilica GC2450工业相机,相机分辨率为2448×2050,帧率15fps,像元尺寸3.45μm。镜头使用日本 KOWA 工业千万分辨率高清镜头LM50JC10M:2/3″50mm/F2.8,10Megapixel。机器人手臂末端的激光位移传感器采用是德国SICK OD5-350W100:解析度5μm,测量范围:350±100mm,重复精度:15 μm。实验使用的工控机是研华IPC-610:Intel(R)Core i7 2600CPU,4G/500G,2千兆网口 (单目相机使用千兆网卡进行图像采集)。软件开发环境使用VS2010。
首先采用本文提出的融合了激光器特征的Harris角点检测算法进行相机参数标定,根据标定参数使用图像金字塔特征与线激光特征相结合的方法进行目标的快速粗略检测,根据检测信息及激光位移传感器提供的位移信息和元件的先验知识,通过感兴趣区域的检测从而实现对于待检测元件的实时精确检测。最后,与传统的双目相机与单目相机组合的立体检测方法进行实验对比,验证了本方法在检测精度及时耗性方面都有较大的优势。实验采用NDI Optotrak Certus动作捕捉系统进行检测目标的实际位姿测量,该系统的分辨率可以达到0.01 mm。系统的时耗情况通过计算软件代码运行的时钟周期数获得。
立体视觉目标检测精度及时耗见表1。

表1 立体视觉目标检测精度及时耗
4 结束语
本文通过分析多种不同的视觉、激光传感器的特征信息,在立体目标检测算法中进行多特征信息的融合,首先在Harris角点特征提取时融合了激光传感器特征,提高了角点检测的精确度,然后使用基于图像轮廓方向向量的图像金字塔特征结合激光线成像特征的方法进行目标粗略检测,最后通过激光位移传感器提供位移信息结合元件感兴趣区域的先验知识特征控制高分辨率的单目相机实现立体目标的高精度实时检测。实验结果表明,所提出的方法具有较高的计算效率和准确性,能够实现较为理想的实时立体视觉检测。
[1]Flores-Abad A,Ma O,Pham K,et al.A review of space robotics technologies for on-orbit servicing [J].Progress in Aerospace Sciences,2014,68:1-26.
[2]Peng J,Xu W,Wang Z,et al.Dynamic analysis of the compounded system formed by dual-arm space robot and the captured target[C]//IEEE International Conference on Robotics and Biomimetics,2013:1532-1537.
[3]Zhang Y,Song S,Tan P,et al.PanoContext:A whole-room 3Dcontext model for panoramic scene understanding [G].LNCS 8694:Springer International Publishing Computer Vision-ECCV,2014:668-686.
[4]Wojek C,Roth S,Schindler K,et al.Monocular 3dscene modeling and inference:Understanding multi-object traffic scenes[G].LNCS 6314:Computer Vision-ECCV.Springer Berlin Heidelberg,2010:467-481.
[5]Ess A,Mueller T,Grabner H,et al.Segmentation-based urban traffic scene understanding [C]//Proceedings British Machine Vision Conference,2009.
[6]Gupta S,Girshick R,Arbelaez P,et al.Learning rich features from RGB-D images for object detection and segmentation[G].LNCS 8695:Computer Vision-ECCV.Springer Interna-tional Publishing,2014:345-360.
[7]Zhao Z S,Feng X,Teng S H,et al.Multiscale point correspondence using feature distribution and frequency domain alignment[J].Mathematical Problems in Engineering,2012,17(2):632-646.
[8]Liu X,Gao W,Hu Z Y.Hybrid parallel bundle adjustment for 3Dscene reconstruction with massive points[J].Journal of Computer Science and Technology,2012,27 (6):1269-1280.
[9]WU Xiaojun,WEN Fei,WEN Peizhi.Hole-filling algorithm in multi-view stereo reconstruction [J].Journal of Computer-Aided Design & Computer Graphics,2013,24 (12):1606-1613 (in Chinese). [吴晓军,文飞,温佩芝.多视图立体三维重建中的孔洞修复算法 [J].计算机辅助设计与图形学学报,2013,24 (12):1606-1613.]
[10]LI Huaize,SHEN Huiliang,CHENG Yue.3Dreconstruction method based on turntable multiple-view registration [J].Journal of Computer Applications,2013,32 (12):3365-3368 (in Chinese).[李怀泽,沈会良,程岳.基于旋转多视角深度配准的三维重建方法 [J].计算机应用,2013,32(12):3365-3368.]
[11]LIU Haitao,WANG Zengfu,CAO Yang.3D robust gait recognition based on manifold learning [J].Pattern Recognition and Artificial Intelligence,2011,24 (4):464-472 (in Chinese).[刘海涛,汪增福,曹洋.基于流形学习的三维步态鲁棒识别方法 [J].模式识别与人工智能2011,24 (4):464-472.]
[12]YING Zai’en,LI Zhengyang,PING Xueliang,et al.Robot calibration based on binocular vision dynamic tracking [J].Application Research of Computers,2014,31 (5):1424-1427 (in Chinese).[应再恩,李正洋,平雪良,等.基于双目视觉动态跟踪的机器人标定 [J].计算机应用研究,2014,31 (5):1424-1427.]
[13]TAO Zhijiang,HUANG Hua.Fundus images mosaic based on improved Harris and SIFT algorithm [J].Computer Engineering and Design,2012,33 (9):3507-3511 (in Chinese).[陶治江,黄华.基于改进的Harris和SIFT 算法的眼底图像拼合 [J].计算机工程与设计,2012,33 (9):3507-3511.]
[14]LUO Gui’e.Some issues of depth perception and three dimention reconstruction from binocular stereo vision [D].Changsha:Central South University,2012 (in Chinese). [罗 桂娥.双目立体视觉深度感知与三维重建若干问题研究[D].长沙:中南大学,2012.]
