基于网络的浏览器内容取证还原技术
2015-12-20王文奇郑秋生关云云
王文奇,潘 恒,郑秋生,关云云
(1.中原工学院 计算机信息系统安全评估河南省工程实验室,河南 郑州450007;2.中原工学院 郑州市计算机网络安全评估重点实验室,河南 郑州450007;3.中原工学院图书馆,河南 郑州450007)
0 引 言
网络取证[1]近年网络取证逐渐成为研究的热点。国内如田志宏等针对证据推理网络实时取证进行了研究[2];杨珺等基于人工免疫原理对过滤网络证据进行了研究[3];杨化志等利用Linux的防火墙机制对在线还原基于HTTP 协议的文件进行了研究[4];王文奇等提出网络取证的完整性技术并对网络取证的规则进行了探讨[5];国外研究方面,Pilli E.S等提出了网络取证的通用模型及对应的工具,其侧重点是研究网络取证的特征[6];Palomoa等则采用自组织映射技术对网络数据特征进行了研究[7]。国内外对浏览器内容取证研究相对较少。
目前已开发的网络监控取证工具相对较多,网络监控仅仅监控犯罪嫌疑人访问的链接,应用于取证存在如下问题:①由于页面可能随时更新,无法获得其访问网页原始内容;②许多Web服务 (如各类色情网站)返回的页面内容需要客户提供用户和密码,之后客户端及与服务器端会话依靠Cookie来维持,而Cookie是有生存周期的,仅靠监控链接无法获取其浏览内容。因此有必要针对网络犯罪,如何获取其网络数据并还原网络内容进行研究。
在前期研究中,主要是为保证取证网络会话的完整性,设计了基于二维链表的多队列高速网络数据缓存算法[5],解决了高效缓存网络数据的关键问题。因此本次研究是在前期研究的基础上进行网络取证研究,包括捕获的网络数据高效匹配算法、网络数据重组和HTTP数据还原恢复技术。通过还原被取证用户的浏览器活动过程和活动现场,为司法单位相关部门提供新的追踪犯罪分子、侦破违法事件的手段和方法。
1 系统框架设计
1.1 取证可行性分析
当使用浏览器浏览页面时,作为浏览器作为客户端访问服务器过程如下:浏览器析取URL (uniform resource locator)地址中主机域名,利用DNS协议访问DNS服务器并获取其IP地址,基于HTTP 协议利用GET 命令向服务器发送获取访问页面请求。对于静态页面,服务器端将存储于服务器端对应的页面文件传回;对于动态页面 (如需要用户登录的邮箱系统、论坛等页面),服务器端则依据会话的cookie,自动生成动态页面并传回客户端。客户端浏览器获取Web 页面的HTML 文本后解析并缓存于本地,Web页面一般不是只有文字组成,而且包含图片、音频、视频以及PHP、CGI、JSP甚至是HTML 等脚本语言构成的内嵌文件,这些资源在Web页面中以链接的形式内嵌。浏览器解析这些链接后再次利用GET 命令获得对应的服务器端文件,直至获得Web 页面中所有内嵌资源,并根据HTML脚本描述显示,从而呈现丰富多彩的页面内容。客户端向服务器提交内容时,则通过POST、PUT 命令提交。因此,由中间监控者看来,浏览器访问服务器并显示Web页面的过程,实际上就是客户端利用HTTP 协议的GET命令不断获取服务文件,以及少量POST、PUT 命令向服务器提交内容的过程。
由于IPSEC等安全协议的复杂性 (如需要服务器及客户端证书),除少数电子商务性质涉及金融交易的网络服务外,为方便用户的访问,实际应用中,当前提供Web服务的网络几乎全部采用明文传输,甚至这些门户网站 (如新浪、网易等)提供的邮件传输服务也是明文传输,对特定用户提供Web服务的各种论坛、OA 系统等网站,也绝大部分采用明文传输,明文传输的特征为实时取证及根据内容恢复网页提供了可能。
在文献 [5]中,我们定义了网络取证模型,以及网络取证必须遵循证据的客观性规则、完整性规则。在此基础上,我们认为,由于网络数据的易逝性、通信的复杂性及电子数据易修改特征,网络证据还必须遵循证据的有效性规则,为此有以下规则:
网络证据有效性规则:一个由网络数据包构成的网络证据集合只有同时包含以下两部分,网络证据才是有效的:
网络证据:E= {S∪C};其中:E 表示网络数据包组成的证据集;S由会话内容组成的网络数据包集;C 网络控制的数据包集,是在网络内容传输过程中产生的必要的网络控制数据包集,包含了丰富的控制信息,且难以完整地伪造,用于证明S并能够形成一条完整的证据链。
如在进行浏览器进行网页浏览时,基于DNS协议客户端需要先获得服务器的IP 地址,基于TCP 协议双方需要先进行三次握手协议,会产生大量的网络控制信息;基于HTTP协议,客户端使用GET 命令获取服务器资源时,双方需要交换大量相关信息。这些数据包是获得网页内容过程中必要的网络通信,不包含证据内容,但可以用于证明网络数据的真实性,从而间接证明网络数据的司法有效性。
1.2 取证框架
根据网络取证的对象,网络取证可以分为两种:特定主机监控取证、关键词分析取证。特定主机监控取证,需将该主机所有网络数据取证保存,适用于已掌握取证对象主机的取证,取证方式较为简单。关键词取证分析,适用于根据关键词在特定的网络段内监控海量网络数据包,从中实时分析网络数据取证,设计相对较为复杂。
针对后者,设计如图1所示的网络取证框架。

图1 网络取证框架
框架系统描述如下:
(1)零拷贝技术
其主要功能是从网络中提取链路层原始网络数据。由于取证网络数据一般是从高速网络中提取,WinPcap在高速网络下存在一定的丢包现象[8],基于此,采用零拷贝技术捕获链路层网络数据,以尽量减少丢包。
(2)高速网络数据缓存系统
由于网络数据包的易逝性,当判断到网络数据需要取证时,之前相关网络数据包早已流过,造成网络数据不完整而无法将网络数据还原到应用层。为此利用计算机资源尽可能地缓存网络数据包,需要取证时,再把相关网络数据保存到证据库。
(3)关键词取证分析系统
先查看该会话是否处于取证会话列表,如是则直接取证保存;否则,将捕获的链路层数据还原到应用层,根据预设的关键词判断是否需要取证,如果需要取证则将该会话信息及其它相关会话信息加入取证会话列表,并通知高速网络数据缓存系统,将所有相关的网络数据包保存到证据库,高速网络数据缓存系统不再缓存这些相关会话。
(4)证据库保存系统
采用加密签名技术,对原始网络证据加密签名,以防止网络证据保存、复制及传输过程中被篡改,保证其司法有效性。由于捕获的是链路层数据,保存数据格式采用tcpdump等工具使用的通用网络数据存储格式。
(5)还原显示系统
将捕获的链路层数据根据TCP/IP 协议将链路层数据还原到应用层,还原浏览器使用过程及内容,并以可视的方式呈现给取证用户。
上述系统中,零拷贝技术已是相对成熟技术;证据保存技术也采用成熟的加密签名技术及通用存储格式;高速网络数据缓存系统已在文献 [5]中进行描述和论证。因此本文主要就其它两个系统中未解决的关键问题进行分析和论述。
2 关键词取证分析系统设计
2.1 系统分析
关键词取证分析系统是根据取证关键词对海量高速网络数据析取分析,从而判断网络数据是否为要取证网络数据。其主要目标是识别与证据相关网络数据。
基于1.1分析,访问一次Web页面需要客户端/服务器端 多 次GET 会 话 交 互 完 成,经 对IE (6.0 以 上)、Chrome(20.0以上)及Mozilla等测试分析,HTTP 层多次GET 会话在TCP 层可能是同一个TCP 会话 (源/目的IP地址,源/目的端口号),也可能是不同TCP会话 (并行实现GET 命令)。监控端表现为仅是客户端端口号不同,取证分析就是尽量将这些相关会话分析出来以便保存。
根据HTTP协议,服务器向客户端传输数据过程中,可以采用多种编码方式如UTF 系列编码、GB2312、BIG5等,因此不能直接对网络数据包进行关键词匹配,为提高匹配速度,先把取证关键词转换成不同编码,根据会话的编码方式,提取对应编码的取证关键词匹配分析。对于以明文传输的网络数据,可以直接对每一个网络数据包进行取证关键词匹配;对于压缩网络数据,则需要将整个会话缓存后,解压再匹配取证关键词。
2.2 哈希函数设计
对网络数据的处理是以TCP 层网络会话为单位处理,需要保存网络会话的相关信息,高速网络下可能保存大量的会话,为尽快定位到相关会话,设计哈希函数定位。
TCP层网络会话一般通过4个域标识:目的/源IP 地址、目的/源端口号。由于Web 服务器端口号一般为80,所以只考虑另外3个域。取证系统针对某一网段监控取证时,IP地址的中高位部分即网络地址部分变化较小,所以可以舍弃不予考虑,客户端端口号一般是由客户端操作系统根据当前运行情况自动生成,一般是连续的,即表示端口号的二进制字段中低位更富于变化。
基于以上分析,设计IP哈希函数如图2所示,首先是客户端和服务器端IP地址低2字节相异或,然后与客户端的端口号交错异或,这是由于IP地址、端口号均在低字节变化性更强,有助于将TCP会话均匀分布到目的空间。

图2 哈希函数设计
2.3 算法描述
当捕获到链路层数据包后,解析出IP层数据包,根据报头中上层协议标识,抛弃非TCP 协议网络数据,解析TCP包头,抛弃不含80端口网络数据。解析会话信息,如果属于取证会话列表则直接取证,否则在应用层匹配分析,其中取证会话列表的定位采用上述哈希函数。
应用层匹配时,根据分析会话列表查看会话状态,如果列表中没有该会话信息,先根据HTTP协议析取该会话客户端相关信息,这时应该获得GET 命令请求数据包。当匹配网络数据应用层前4个字符 “GET” (包含空格)时,判断为客户端GET 请求,根据其各个域的值获得客户端相关信息,如图3为利用GET 请求访问163服务器图片文件的HTTP头信息。利用服务器对客户端的响应获取服务器的相关信息。根据这些头信息可以获取以下会话相关信息:传输方式、是否压缩传输、压缩算法、双方采用的编码方式、浏览器类型等。
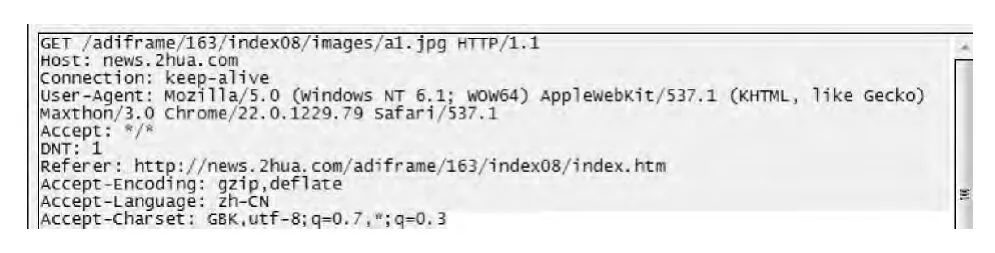
图3 GET 访问数据包头
匹配取证关键词时,为充分发挥多核计算机优势,采用并行计算模式进行检索。目前有多种并行编程方式,如多线程技术、苹果公司发起的并行异构编程OpenCL 以及微软推出C++加速大规模并行计算 (accelerated massive parallelism,AMP)[9]等,鉴于系统在Windows系统上采用C++语言开发,采用AMP 并行编程模式,AMP 实际上是由系统从底层启动多线程对容器中的数据并行计算并由系统对计算任务优化处理。同时实测结果表明,Windows系统下AMP相对于应用程序采用多线程技术并行计算有一定的优势[10]。对于本算法,字符串匹配可以作为相同的计算任务,数据包则是一个并行计算的数据,因此,可以考虑将网络数据分段而有利于并行计算。基于以上分析,将网络数据分割成n段,考虑到程序效率和当前CPU 大多采用超线程技术的现状,这里n设计CPU 个数的2倍;为保证包含关键词的数据内容分到同一数据段,分段时采用冗余分段,不同段之间至少重复的字符长度是最长取证关键词长度。将分段后的n段网络数据置于容器,利用boost函数库将匹配函数绑定为函数对象[11],调用该函数对象进行并行搜索匹配。
如果匹配成功,则认为是需要取证网络会话,将该会话加入取证会话列表,并通知高速网络数据缓存系统将之前缓存的相关网络数据包存入证据库。
3 网络数据还原技术
3.1 网络数据还原设计框架
由于HTML支持格式复杂性,不同的浏览器存在不同的显示风格,全新开发能够解析链路层数据到应用层并显示的浏览器是不现实的。基于浏览器都是将Web内容缓存于本地并显示,同时目前的主流浏览器提供了其浏览器内核插件如IE、Chrome、Firefox等。为此,将网络数据中的服务器资源还原到本地,利用插件技术,将这些网页重构并显示。
基于以上分析,设计还原网络数据过程如图4 所示。主要包含两部分:①根据网络数据还原服务器资源;②重构Web页面。
3.2 服务器资源还原算法
主要功能是利用IP/TCP 各层协议将网络会话重组到应用层,还原服务器资源。网络数据在传输过程中,由于网络的复杂性,可能会出现不同的异常状况,如数据的重传、网络数据异常断开等。因此,需要根据控制信息对异常数据处理。
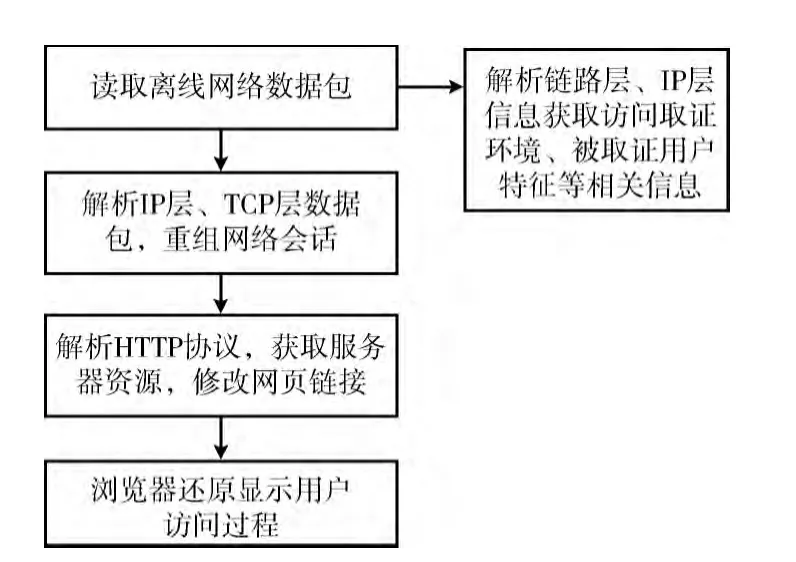
图4 网络数据还原显示流程
从证据文件读取数据为链路层数据包,链路层包含客户端和服务器相关物理信息 (如MAC 地址、物理网络类型等),因此利用链路层信息可以用于还原取证环境,从而间接证明取证过程的司法有效性。
根据通信双方的IP地址、端口号确定同一会话;同一会话中,根据数据包的序列号和确认号对网络数据重新排序,并丢弃重传数据,重组网络数据还原服务器端资源。
传输层通过控制位FIN/RST 终止会话,可能产生不完整文件;同时在高速网络环境下捕包,可能会产生少量丢包现象,利用TCP序列号无法重组文件。因此需要对这些不完整文件进一步处理,采取以下措施:所有正常数据处理完成之后,根据其序列号之差以及应用层获得文件长度判断丢弃数据的大小,并根据文件类型填充不同数据,使之符合该文件格式。
根据HTTP服务器响应头可以获取以下信息:文件的传输方式是压缩传输还是正常传输,采用的字符集、文件的长度,如果是chunked方式编码则没有文件长度,需要根据chunked协议判断文件传输是否结束,因此正常网络通信过程中,在应用层判断文件传输是否已经完成。
浏览的页面一般为HTML文件,页面内嵌了图片、音频等资源,根据HTTP 协议的各个域值来分析这种关联性:根据 “GET”域值和 “Host”域值合成本次访问的URL地址,如图3合成的URL 地址为 “news.2hua.com/adiframe/163/index08/images/a1.jpg”;根 据 “Referer”域值获取 该 链 接 源URL 地 址,为news.2hua.com/adiframe/163/index08/index.htm,该HTML 页 面 源 码 中 应 包 含 本URL地址链接,为该页面的内嵌图片。
3.3 网页重构算法
基于1.1分析,浏览器访问页面时,获得页面HTML脚本,解析编码内容,进一步获取其中的服务器资源。由于这些资源已经还原并保存于本地,为此可以修改页面脚本,将其修改为访问还原的本地 “服务器资源”。如图3中,还 原 的 网 页"news.2hua.com/adiframe/163/index08/index.htm"中 一 定 含 有 链 接 “news.2hua.com/adiframe/163/index08/images/a1.jpg”。将访问服务器的链接修改为访问本地文件a1.jpg,浏览器将直接显示本地a1.jpg。为此首要任务是在HTML脚本中析取出这些链接。根据HTML语法,表示获取资源语句位于HTML 属性值中,这些属性值可以用双引号、单引号、圆括号等不同的边界标识来区分属性值,同时对空格等字符忽略解析。为准确析取网页中链接资源,采用正则表达式表示网页中内嵌链接资源:"(\s*?=\s*?)*? ([’" =\ (]) (http://)(.+?)([’" \)])"。
正则搜索函数采用boost库中正则搜索函数 (boost::regex_search)[10],上述正则表达式中,函数匹配结果将析取服务器端资源URL以及网络资源类型如:HREF (超文本引用)、内嵌资源类型 (如bgsound为背景音乐、img为图片)。根据搜索结果,当网络资源类型为超文本引用时,表示用户可以通过本页面访问其它资源;如为内嵌资源,需要更改页面编码使之替换为已还原的本地“服务器资源”。
对于JS (javascript)、XML 以 及FALSH 等 内 嵌 的 脚本语言代码,由于其访问资源标识可能用变量来表示,需要解析其变量访问资源标识,为此设计了分析资源标识的正则表达式如下:" (src\d:\s*?")(.*?)(")";
获取变量标识后将其指向对应的服务器资源修改为指向已还原的本地 “服务器资源”。
4 测试分析
取证系统运行及开发环境为操作系统为64 位Windows7.0,采用Visual Studio 2013;实现语言采用C++11。取证系统运行于某高校出口处,交换机为千兆以太网交换机,流量最大为750 Mb/s左右。取证主机的内存采用DDR3代16G 内存,CPU 采用酷睿内核i7。
首先对并行关键词分析算法的有效性进行测试,图5显示了不同关键词个数在不同流量下的数据包未检测率,实测结果显示,采用AMP 并行分析技术即使在500 Mbps流量下,也有较好的检测效果,而采用串行分析时,4 个关键词在100 Mbps流量时,未检测率就会有明显提高,因此,AMP并行分析能够较大幅度地提高检测效果。

图5 关键词并行处理算法测试
同时还对页面还原有效性进行了测试,图6 (a)为对捕获的链路层数据重构并通过IE 提供的COM 控件还原显示的163主页效果。该页面内嵌了JS脚本、图片,声音等资源,并包含了弹出页面,重构结果显示,上述算法能够较好地还原原页面内容。图6 (b)为重构某学校OA 系统用户登录后的页面,并还原了用户下载文件的过程及内容,由于该系统网络数据没有加密,重构时,获取了用户登录时的用户名和密码。

图6 IE浏览器还原结果
5 结束语
本文采用监控网络方式对浏览器访问过程进行了取证和内容还原研究,通过取证用户浏览时所产生的网络数据,将取证的链路层数据还原到应用层并重构页面。实验结果显示,设计的系统能够对浏览器用户的上网过程进行初步的取证和还原,基本达到了设计的目的。但是由于网页是一种非常复杂且灵活的脚本语言,浏览器用户行为也是复杂多变,因此需要后续的工作中对不同复杂页面和不同浏览器用户行为进行大量测试,以期进一步验证系统的有效性并改进算法,进而实用化。
[1]Casey E.Digital evidence and computer crime:Forensic science,computers and the internet[M].Academic press,2011.
[2]TIAN Zhihong,YU Xiangzhan,ZHANG Hongli,et al.A real time network intrusion forensics method based on evidence reasoning network [J].Chinese Journal of Computers,2014,37 (5):1184-1186 (in Chinese). [田 志宏,余翔 湛,张 宏莉,等.基于证据推理网络的实时网络入侵取证方法 [J].计算机学报,2014,37 (5):1184-1186.]
[3]YANG Jun,MA Qinsheng,WANG Min,et al.Filtering for network forensics data on artificial immune network clustering[J].Engineering Journal of Wuhan University,2012,45(1):123-127 (in Chinese). [杨珺,马秦生,王敏,等.网络取证数据的人工免疫网络聚类过滤方法 [J].武汉大学学报工学版,2012,45 (1):123-127.]
[4]YANG Huazhi,XU Lan,LI Peifeng,et al.Design and realisation of IPQueue-based real-time Web pages restoring system[J].Computer Applications and Software,2011,28 (10):23-26 (in Chinese). [杨化志,许兰,李培峰,等.基于IPQueue实时网页还原系统的设计与实现 [J].计算机应用与软件,2011,28 (10):23-26.]
[5]WANG Wenqi,MIAO Fengjun,PAN Lei,et al.The research on integrity technique of network based forensic [J].Chinese Journal of Electronics,2010,38 (11):2529-2534(in Chinese).[王文奇,苗凤君,潘磊,等.网络取证完整性技术研究 [J].电子学报,2010,38 (11):2529-2534.]
[6]Pilli ES,Joshi RC,Niyogi R.Network forensic frameworks:Survey and research challenges [J].Digital Investigation,2010,7 (1):14-27.
[7]Palomoa EJ,Northb J,Elizondob D,et al.Application of growing hierarchical SOM for visualisation of network forensics traffic data[J].Neural Networks,2012,32:275-284.
[8]Orosz P,Skopko T,Imrek J.Performance evaluation of the nanosecond resolution time stamping feature of the enhanced lib-pcap [C]//The Sixth International Conference on Systems and Networks Communications,2011:220-225.
[9]Gregory K,Miller A.C++AMP:Accelerated massive parallelism with microsoft visual C++ [M].O’Reilly Media,Inc,2012.
[10]WANG Wenqi,XU Xiangyi.Parallel search technology research based on multi-core processor[J].Journal of Zhongyuan University of Technology,2014,24 (3):54-57 (in Chinese). [王文奇,徐香义.基于多核处理器的文本并行搜索技术研究 [J].中原工学院学报,2014,24 (3):54-57.]
[11]Jrvi J,Freeman J.C++lambda expressions and closures[J].Science of Computer Programming,2010,75 (9):762-772.
