时间窗口对个性化推荐算法的影响研究
2015-12-19宋文君刘建国
宋文君,郭 强,刘建国
(上海理工大学复杂系统科学研究中心,上海200093)
0 引言
推荐系统通过利用用户的历史行为来预测其潜在的需求,是解决信息过载问题的有效工具之一[1-2]。早期有关推荐系统的研究主要集中在静态用户的行为分析领域,也就是不考虑用户发生行为的时间。但是近几年来,随着很多包含时间信息的数据集的公开以及静态用户行为分析技术的成熟,许多学者开始致力于研究时间因素对推荐算法的影响。例如,Koren[3]通过改进两种经典的协同过滤算法,提出了一种新的模型用于追踪随时间变化的用户行为。刘继等[4]通过考虑不同用户选择产品的时间和同一个用户选择产品的时间差这两种因素,提出了一种基于时间因素的推荐算法,能够很好地提高推荐结果的准确性和多样性。
目前大多数的推荐系统都是采用全部的用户信息[5],然而考虑用户的早期行为意义不大,因为用户的选择行为是一个动态变化的过程。例如某个用户早期选择过的产品不能反映出他目前的兴趣所在。也就是说,只考虑用户的部分历史行为,同样能够保证推荐系统的性能。已经有学者开始关注这种现象,例如张千明等[6]将基于时间和拓扑结构这两类策略混合起来,提出了一种用于抽取在线系统中信息骨架的方法。虽然采用上述方法只需要处理部分数据,但是却缺乏对于时间窗口和个性化推荐算法之间关系的研究。而这一内容对于节省数据存储空间以及降低计算复杂性都至关重要。基于这一想法,郭强等[7]考查了时间窗口对于个性化推荐算法的影响。按照全部用户的时间先后排序,选取最近发生的10%的记录作为测试集,剩下的记录作为训练集,如图1a所示,其中打钩代表用户在该时刻有记录。然而采用这一方法,可能会导致同时出现在两个集合中的用户数量不多,难以保证最终的推荐效果。如果针对每一个用户的记录按照时间排序来划分数据,就可以保证大多数用户同时出现在两个集合中,从而能够更好地衡量推荐效果,如图1b所示。因此,首先我们针对每一个用户,选择其最近发生的前10%的记录作为测试集。在剩下的记录中通过逐渐扩大时间窗口的方法,生成一系列训练集。然后将每个训练集作为已知的数据来预测用户未来的兴趣偏好,最后再利用测试集来检验推荐结果的表现情况。在标准数据集MovieLens上的实证结果表明,采用部分的用户近期记录能够提升推荐系统的准确性和多样性。
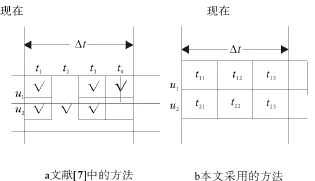
图1 与已有文献方法的对比Fig.1 Comparison between the presented method and the one proposed in Ref[7]
1 模型与方法
1.1 基于二部分网络的个性化推荐算法
一个用户-产品二部分网络包含一组由集合U={u1,u2,…,un}表示的用户节点,一组由集合O={o1,o2,…,om}表示的产品节点,以及连接这两组节点的连边,由集合E={e1,e2,…,ep}表示。其中如果用户uj选择过产品oi,就在uj和oi之间连接一条边aij=1,否则aij=0。
本文采用的个性化推荐算法[8-9],假设目标用户ui没有选择过某个产品oα,那么用户ui未来选择产品oα的可能性为

其中,sij为用户uj对ui的相似度。对于一个给定的目标用户,将他所有未选择过的产品,按照可能性大小vαi排序,最终将排序靠前的产品推荐给他。目前衡量用户相似性的方法有很多,如共同邻居指标、Jaccard指标[10]、Sørensen指标[11]、混合指标[12]等。本文研究了10种基于二部分网络的局部信息所得到的用户相似性指标。
1.2 基于局部信息的用户相似性指标
本节简要介绍一下在用户-产品二部分网络中,基于局部信息的10种用户相似性指标[13-14]。
1)Adamic-Adar(AA)指标:对于任意一个用户ui,他选择过的产品集合可以用Γ(ui)表示。这个指标只考虑了被两个用户共同选择过的产品,并且赋予度小的产品更大的权重[15],即

其中,kz为被用户ui和uj共同选择过的产品oz的度。
2)共同邻居指标(CN):如果任意两个用户ui和uj共同选择过的产品很多,也就是说他们极有可能具有相似的兴趣,因此这个指标可以被表示为

3)大度节点有利指标(HPI):这一指标最初被提出是用来定量地刻画新陈代谢网络中每对反应物的拓扑相似程度[16],即

4)Jaccard(JAC)指标:这个指标是Jaccard[10]100多年前提出的,其定义为

5)Leicht-Holme-Newman(LHN)指标:这个指标使得拥有更多共同邻居的节点对具有更高的相似性,且是相对于期望的邻居数目而言,具体可以被表示为

6)Sørensen(SOR)指标:这个指标主要应用于衡量生态系统中的数据[11],其定义为

7)Salton(SAL)指标:这个指标也被称为余弦相似性,可以表示为

8)基于随机游走的指标(RW):其基本思想是假设用户uj携带一定的资源,用户uj对ui的相似性sij指的就是用户uj愿意分配给ui的资源配额,因此这个指标被表示为

9)基于局部热传导算法的指标(HC):在计算用户uj对ui的相似性时,假设用户uj可以被看作为一个热源,且携带1个单位的热量,那么这些热量可以通过用户uj选择过的产品,最终传递给用户ui。那么最终用户ui所接收到的热量可以表示为

10)基于热传导算法的改进指标(IHC):考虑到产品的度信息对热传导算法的影响,对产品的度设置一个参数,并提出一种基于热传导算法的改进指标[14],可以表示为

2 数值实验
2.1 实验数据
本文采用了两个标准数据集MovieLens和Netflix来分析时间窗口对于个性化推荐算法的影响。MovieLens数据集包含943个用户对1 682部电影的打分情况。首先针对每一个用户,将其所有的记录按照时间降序排列,也就是说排在前面的记录是最近发生的。然后选择前10%的记录作为测试集,另外按照下面不断地扩大时间窗口的方法,划分出一系列训练集。在剩余的89 561条记录中,最晚的时间单位为893 286 638,记为t0。这里假设时间间隔Δt=86 400s(1d),在时间标T∈[t0-ηΔt,t0]这一范围内的记录就构成了第η个训练集,其中η=1,2,3,…,215。另外对于包含8 609个用户和5 081部电影的Netflix数据集来说,假设时间间隔Δt=2d,那么就可以划分出61个训练集。需要注意的是随着η的值不断增大,训练集中所包含的数据量也在不断增大,但是测试集却保持不变。本文将每一个训练集作为已知的数据,来预测用户对未选择产品的喜好程度,再利用测试集来检验推荐结果的表现情况。
2.2 算法表现性
本文采用了准确率、召回率和平均汉明距离3种指标来衡量推荐算法的表现情况。准确率以及召回率都可以被用来衡量推荐系统的准确度。其中准确率P表示用户对系统所推荐产品感兴趣的概率,也就是系统推荐的L个产品中用户喜欢的产品所占的比例,即:

其中,hi为同时出现在用户ui的测试集和其推荐列表中的产品数目。当推荐列表长度L给定,准确率越高说明推荐效果越好。召回率R则表示用户喜欢的产品被推荐的概率,即:

其中,hi与公式(12)中所代表的含义相同,而nip为测试集中用户ui喜欢的产品数目。同样地,召回率越大表明推荐结果越准确。另外本文利用汉明距离S=〈Hij〉来衡量推荐系统对不同用户推荐不同产品的能力,具体定义为其中,L为推荐列表的长度,Qij(L)为任意两个用户ui和uj的推荐列表中相同产品的个数。最大值S=1表示两个推荐列表没有任何重叠产品,也就代表推荐系统的多样性最高。反之如果S=0,就说明两个推荐列表完全一致。

本文分别把每个训练集作为已知的数据,采用上述基于10种用户相似性指标的个性化推荐算法来预测用户的喜好,并且利用测试集中的数据来检验算法的准确度情况,如图2所示。在MovieLens上的实验结果表明10种算法的准确率和召回率都基本上呈现出一种先上升后下降的趋势。本文只考虑27/215≈12.56%的用户近期记录,所得到的推荐准确性和多样性可以分别被提升27.27%和3.28%。产生这一现象的原因可能在于最初训练集中的数据量太少,因此不能准确地反映出用户的兴趣偏好。然而,随着时间窗口不断增大,当训练集中的数据达到一定数量时,已知的数据量越多反而会影响推荐结果的准确度。换句话说,只考虑部分的用户近期记录反而可以得到一个更准确的推荐结果。然而在Netflix数据集上的实验结果却表明,用户的历史记录越多则推荐效果就越好。这说明本文考虑时间窗口的方法只适用于某些特定的数据集合,推荐效果如何与数据集的统计特性有关。
为了更清楚地研究采用部分数据所得到的推荐准确度与采用全部用户记录相比所提高的比率,本文中表1用于说明时间窗口对个性化推荐算法的影响。其中,和分别为第50到第100个训练集所得到的平均准确率和召回率。另外,Δp代表与第215个训练集所得到的准确率相比较所能提高的比率,即:

相似地,与第215个训练集所得到的召回率r215相比所能提高的比率可以用Δr来表示,

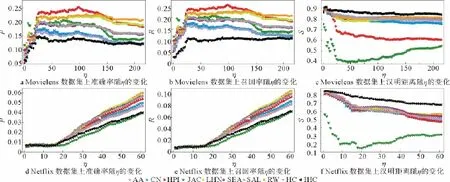
图2 在MovieLens和Netflix数据集上,推荐效果随η增大的变化情况Fig.2 The performance w.r.t.ηfor MovieLens and Netflix data sets
Δp和Δr的值越大,说明与采用全部的用户历史记录相比,采用部分数据所得到的推荐准确度被提高的比率就越大。从表1可以看出,在这10种推荐算法中除了RW和IHC两种指标以外,采用部分数据做推荐所得到的准确率与召回率都会被提高,其中Jaccard指标最适用于本文的方法。因此只需要采用一部分的用户近期记录就可以得到更准确的推荐结果。
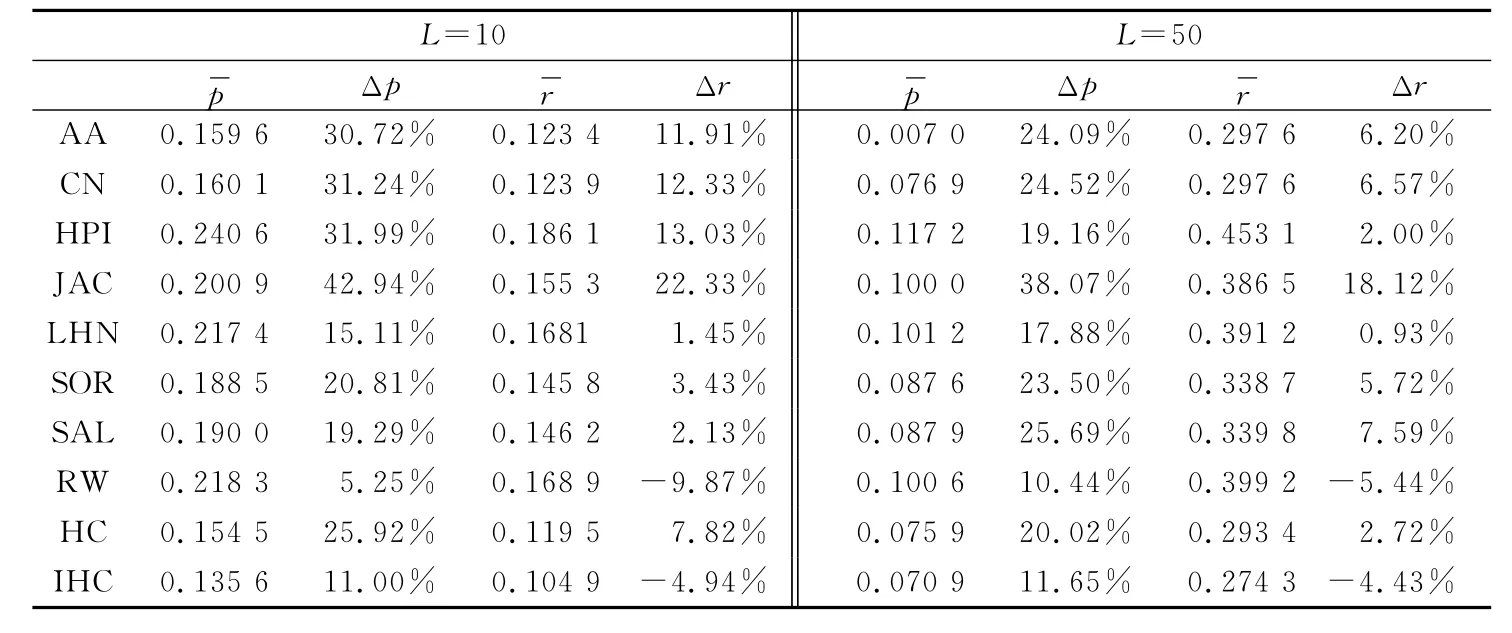
表1 推荐列表长度为10和50时,在MovieLens数据集上10种相似性指标的表现情况Tab.1 The performance of 10similarities for MovieLens data when the list length equals to 10and 50
3 总结与展望
随着互联网上信息爆炸现象的产生,人们提出了许多推荐算法来克服这一难题。本文采用的方法是把一个用户选择过的产品当作热源,并且假设它可以在用户-产品二部分网络中传递热量。在这个过程中,传统的做法是采用全部的用户历史记录来预测其未来的需求。然而我们发现采用用户的部分近期数据,反而能够提高推荐结果的准确性和多样性。与郭强等[7]提出的方法不同,本文针对每一个用户,选择其最近发生的前10%的记录作为测试集,再通过不断扩大时间窗口的方法,生成了一系列训练集,并且对每一个训练集都采用基于10种用户相似性指标的个性化推荐算法,来研究推荐结果的变化情况。在标准数据集MovieLens上的实验结果表明我们只需要采用大约12.56%的用户近期记录,就可以保证推荐结果的准确性和多样性不会降低。我们的发现在理论及应用上都具有一定价值。在理论上,对于深入理解时间窗口对于个性化推荐算法的影响很有帮助;在实践中,可以极大地降低大规模数据所带来的计算复杂性,并且缩小数据存储空间。
[1] LüL Y,Medo M,Yeung C H,et al.Recommender systems[J].Physics Reports,2012,519(1):1-49.
[2] 刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1-10.Liu Jianguo,Zhou Tao,Guo Qiang,et al.Overview of the evaluated algorithms for the personal recommendation systems[J].Complex Systems and Complexity Science,2009,6(3):1-10.
[3] Koren Y.Collaborative filtering with temporal dynamics[J].Communications of the ACM,2010,53(4):89-97.
[4] Liu J,Deng G.Link prediction in a user–object network based on time-weighted resource allocation[J].Physica A,2009,388(17):3643-3650.
[5]Zhou T,Kuscsik Z,Liu J G,et al.Solving the apparent diversity-accuracy dilemma of recommender systems[J].Proceedings of the National A-cademy of Sciences,2010,107(10):4511-4515.
[6] Zhang Q M,Zeng A,Shang M S.Extracting the information backbone in online system[J].PloS one,2013,8(5):e62624.
[7] Guo Q,Song W J,Hou L,et al.Effect of the time window on the heat-conduction information filtering model[J].Physica A,2014,401(5):15-21.
[8] Guo Q,Li Y,Liu J G.Information filtering based on users′negative opinions[J].International Journal of Modern Physics C,2013,24(5):1350032.
[9] 刘兆兴,张宁,李季明.基于协同过滤和网络结构的个性化推荐算法[J].复杂系统与复杂性科学,2011,8(2):45-50.Liu Zhaoxing,Zhang Ning,Li Jiming.One personal recommendation algorithm based on collaborative filtering and network structure[J].Complex Systems and Complexity Science,2011,8(2):45-50.
[10]Jaccard,P.étude comparative de la distribution florale dans une portion des Alpes et des Jura[J].Bull Soc Vandoise Sci Nat,1901,37:547-579.
[11]Sørensen T.A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons[J].Biol Skr,1948,5:1-34.
[12]Pan X,Deng G S,Liu J G.Information filtering via improved similarity definition[J].Chinese Physics Letters,2010,27(6):068903.
[13]Zhou T,LüL,Zhang Y C.Predicting missing links via local information[J].The European Physical Journal B,2009,71(4):623-630.
[14]Guo Q,Leng R,Shi K,et al.Heat conduction information filtering via local information of bipartite networks[J].The European Physical Journal B,2012,85(8):1-8.
[15]Adamic L A,Adar E.Friends and neighbors on the web[J].Social networks,2003,25(3):211-230.
[16]Ravasz E,Somera A L,Mongru D A,et al.Hierarchical organization of modularity in metabolic networks[J].Science,2002,297(5586):1551-1555.
