基于Django框架的两种Web地震目录分页方法
2015-12-19马士振林向东白永福张红旗
马士振 林向东 白永福 张红旗 冯 刚
(中国北京 100080 北京市地震局)
0 引言
测震台网的一项重要工作是产出地震观测目录。作为一种重要的观测数据,在地震预测预报方面,地震观测目录可以用来研究中强地震前地震空区及条带的分布情况(杨芬等,2010);在地震应急方面,地震观测目录可以为有关部门提供地震的三要素信息,服务于应急救灾工作。
自“十五”网络项目以来,北京市测震台网已积累了近万条地震目录。为了更好的服务于行业和社会公众,测震台网开发了基于Django框架的B/S结构的地震目录服务系统,以提供地震目录的快速展示及目录数据的图像化服务。
在用户请求数据服务时,将数据一次性全部交付给用户是不合适的,因为这不但让用户等待时间较长,而且浪费宝贵的网络资源(李光耀等,2004);然而,在网络上传输小块数据,则既可以减小网络流量,又可以提高网页的响应速度,还可以有效降低服务器负载(王瑞波,2009)。因此,在构建Web数据服务系统时,为了提高系统的数据服务性能,可以采用把数据分批传送给用户的技术,即数据的分页技术。
Django来源于一个可满足每天数百万次页面查看请求的在线报纸服务,是采用Python 语言驱动的Web 应用程序框架,可以快速开发数据库驱动网站,有着开源、免费、敏捷开发的特点。使用Django框架,可以节省开发周期,并且便于维护和升级(程文芳等,2013)。Django广泛应用于博客系统(杨志庆,2013)、资源共享平台(程文芳等,2013)、数据库快速查询(齐金刚等,2014)等Web应用的开发工作中。
结合地震目录服务系统的开发实践,作者使用Django框架的Paginator函数和MySQL数据库的LIMIT子句,实现了两种Web地震目录的快速分页方法,可以有效提高Web页面上数据服务的响应速度。
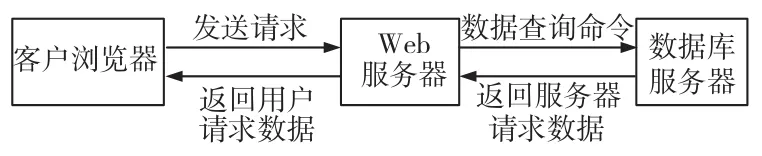
图1 Web查询执行过程示意Fig.1 Schematic diagram of the implementation process of Web data query
1 Web数据查询分页技术
在网络环境中,获取数据库中数据的性能主要受到数据库的查询代价和网络数据传输能力的约束。因此,在远程网络坏境中,为了提高获取数据的性能,主要依靠减少传输的次数和数据量来解决(王瑞波,2009)。在进行Web数据查询时,其执行过程可简化为一个3层的网络结构。由于这3层分别在不同的网络环境中,因此实现Web数据查询分页可以在3个不同层次中进行(齐金刚等,2014),见图1。
1.1 在客户端分页
Web服务器和数据库服务器将满足用户查询条件的数据一次性发送给用户,浏览器在用户显示时进行分页(齐金刚等,2014)。这种分页方式虽然减少了数据传输次数,但增加了传输的数据量,延长了用户的等待时间。因此,这种分页只能带来浏览的便利,对查询性能的改善没有帮助。本文中不再讨论。
1.2 在Web服务层分页
数据库服务器把符合条件的查询结果一次性发送给Web服务器,由其对查询结果进行分页操作。然后,根据客户端请求,Web服务器将对应的页面数据发送给客户浏览器(齐金刚等,2014),见图2。一般来讲,Web服务器与数据库服务器在一个局域网内,两者间的传输速度较客户浏览器到Web服务器间快。因此,相对于客户端分页方式,采用这种分页方法,客户浏览器将获得较快的响应,而且实现方便。
1.3 在数据库层分页
在数据库层分页的目标是:通过减少3层之间的数据流量以提高系统的查询性能,即数据库服务器每次只向Web服务器返回需要显示的数据记录,而后由Web服务器向用户提交这些数据(王博等,2006),见图3。目前,在数据库服务层实现分页的方法主要有两种:①利用数据库自身提供的分页方法;②调用存储过程。考虑到全国大部分测震台网使用的数据库是MySQL,而MySQL提供了便捷的limit子句来实现数据分页功能,因此本文介绍数据库自身提供的分页方法。

图2 Web层分页查询过程示意Fig.2 Schematic diagram of the implementation process of pagination in Web layer

图3 数据库层分页查询过程示意Fig.3 Schematic diagram of the implementation process of pagination in database layer
2 在地震目录服务系统中两种分页方法的实现
2.1 在Web服务层分页
在初步完成的地震目录服务系统中,使用Django框架的Paginator函数,对Web服务层的分页功能进行测试。通过为Paginator函数提供每页显示的地震目录行数,该函数自动对全部数据进行分页操作。分页操作完成后,即可使用Paginator对象的方法获得分页总数、页数列表、每个分页的具体地震目录等对象。而后,再将上述对象渲染到模板文件中,也就实现了地震目录数据在Web服务层的数据分页功能。在地震目录服务系统中,实现分页的核心代码如下。
from django.core.paginator import Paginator # 导入Paginator分页函数from django.db import connection # 导入数据库连接函数from django.shortcuts import render # 导入模板渲染函数def historyCataList(req)∶ # 定义视图函数
cursor = connection.cursor() # 建立数据库连接,获取游标
eqkCount = cursor.execute(“SELECT * FROM Catalog # 执行数据查询操作
ORDER BY O_time ”) # O_time 是主键
cata_All = cursor.fetchall() # 获取查询结果
cursor.close() # 关闭游标
connection.close() # 关闭连接
eqkPage = Paginator(cata_All,10) # 对查询结果分页,每页显示10条目录pageListCount = eqkPage.num_pages # 分页总数
pageList = eqkPage.page_range # 页数的列表
page1 = eqkPage.page(1) # 获得第一页的地震目录
# 将查询结果渲染到模板文件
return render(req,'historyCataList.html',{'eqkData'∶page1,
’pageListCount’∶pageListCount,’pageList’∶pageList})
此方法借助Django提供的函数,实现了在Web服务层对查询结果的分页。通过对性能测试,发现当数据量较小时,客户端的响应速度比较快;当数据量很大时,数据库需要较长时间才能查询到全部结果,然后将结果返回到Web服务层进行分页处理,最后把分页后的数据渲染到客户浏览器。在这个分页过程中,查询的次数少了,但数据库查询的工作量和网络负载变大了,而且,比较大的数据量还会消耗Web服务器的存储空间。因此,对于这种分页方法,较小数据量时可用;当数据量上升到一定量级时,Web查询性能降低。性能测试数据见表1。

表1 测试结果Table 1 The result of test
2.2 在数据库层分页
区域测震台网使用的JOPENS地震台网数据处理系统,采用流行的MySQL数据库对数据进行管理。该数据库提供limit查询子句,用于强制select 语句返回指定的记录数。limit接受一个或两个数字参数,参数必须是一个整数常量。如果给定两个参数,第1个参数指定第1个返回记录行的偏移量,第2个参数指定返回记录行的最大数目。需要注意的是,初始记录行的偏移量是 0,而不是 1。如“select * from table limit 5,10;”返回检索记录行 6—15的结果。在使用limit子句时,一个需要解决的问题是确认新的查询从哪一行开始,根据计算结果可知,第N页的起始位置应为:(第N页的页码-1)*每页显示的行数。由此,可以得知limit子句的格式应为:“limit (N页的页码-1)*每页显示的行数,每页显示的行数”。
在地震目录服务系统中,Web应用程序将包含LIMIT子句的SQL语句传递给数据库服务器,即可实现查询结果的分页。以下为使用LIMIT子句实现数据库层分页的核心代码。
from django.db import connection # 导入数据库连接函数from django.shortcuts import render # 导入模板渲染函数def historyCataList(req,pageId)∶ # 定义视图函数
cursor = connection.cursor() # 建立数据库连接,获取游标
currentPageNo = int(pageId) # 获得当前页页码
eqkPerPage = 10 #设置每页显示地震目录条数
# 生成分页查询语句,O_time是主键
queryLine =‘SELECT * FROM Catalog ORDER BY O_time LIMIT ‘ +
str((currentPageNo-1)*eqkPerPage) + ',' + str(eqkPerPage)
queryCountLine = ‘SELECT count(*) FROM Catalog’cursor.execute(queryLine) # 执行分页查询
cata_all = cursor.fetchall() # 获得查询得到的分页数据
cusor.execute(queryCountLine) # 执行获取条目总数查询
eqkCount = cursor.fetchone() # 获得符合条件的条目总数量cursor.close() # 关闭游标connection.close() # 关闭连接
if (eqkCount[0] % eqkPerPage == 0)∶ # 获得总的页数
pageListCount = eqkCount [0]/ eqkPerPage else∶
pageListCount = eqkCount [0]/ eqkPerPage + 1
pageList = range(pageListCount) # 获得页数的列表
# 将查询结果渲染到模板文件
return render(req,'historyCataList.html',{'cata_All'∶cata_All,
'pageListCount'∶pageListCount,'pageList'∶pageList})
此方法使用MySQL自带LIMIT子句,实现在数据库服务层对查询结果的分页,即请求哪一页,就查询哪一页,然后给客户端返回哪一页。采用该分页方法,减小了数据库服务器的工作量,降低了网络流量。通过对该方法的性能测试,发现当数据量较大时,客户端的响应速度依然比较快(表1)。
3 性能测试
在局域网中对Web服务层分页方法和数据库服务层分页方法进行性能时比测试:要求每页显示10条地震目录,地震目录的检索位置为第100—100 000条,采用Firefox浏览器的firebug进行查询耗时统计。测试结果见表1。
4 讨论
两种分页方法性能测试的结果(表1)表明,当查询数据量较小时,两者的分页用时接近。此时,由于在Web服务层实现地震目录的分页比较简单,可以考虑在Web服务层实现分页操作;当查询数据上升到万条或10万条量级时,两者的响应速度出现较大数据库层差异:在数据库层进行分页用时更少,页面的响应速度更快。在北京市测震台网的地震目录服务系统中,目前采用数据库层分页方法。对于北京市测震台网近万条地震目录分页,数据库层方法的查询效率更高。因此,当有关地震台网需要开发地震目录数据服务系统时,可以根据本台网数据库中地震目录的记录数量,酌情选择分页方法,以更好更快地提供地震目录查询服务。
在本文撰写过程中,获得王晨高级工程师和张英博士的支持,在此表示感谢。
程文芳,张洁,夏明一,张北辰.极地标本资源共享平台系统设计与实现[J]. 极地研究,2013,25(2):185-196.
李光耀,易虎,李波. 基于存储过程分页优化Web数据查询性能[J]. 微计算机应用,2004,25(4):475-479.
齐金刚,李滔,李晋军. Django框架Web数据查询分页技术研究[J]. 电子设计工程, 2014,22(5):33-37.
王博,任涛. Web数据库分页浏览方法性能分析[J]. 现代电子技术, 2006, 29(10):68-70.
王瑞波. 一种分页查询优化方法的研究与实现[D]. 北京:北京化工大学,2009:4.
杨芬,付虹. 滇西北东条带地震围空及条带与中强地震的时空关系[J]. 地震地磁观测与研究, 2010,31(5):7-12.
杨志庆. 基于Django的Blog系统的开发与实现[J]. 机电一体化, 2013,9:69-72.
