协同知识生产社区的内容质量评估模型研究
2015-12-14张博乔欢
张博++乔欢


〔摘要〕基于互联网平台的大规模用户协作知识生产是一种新颖的知识生产模式,这种模式能够有效利用海量用户的集体智慧,提高知识传播的范围。但是,与传统的知识生产不同,这种生产模式由于参与人员水平参差不齐,内容质量难以保证,针对此种生产模式建立有效的内容质量评估和控制机制问题非常必要。本文采用层次分析方法,以维基百科为实例建立了协同知识生产社区的内容质量评估模型,综合体现用户需求和内容特征,能够为网络内容的质量控制和网络知识平台的建设与运营提供有益的方法支撑。
〔关键词〕信息质量;知识生产社区;知识社区;协同知识生产;维基百科;AHP
DOI:10.3969/j.issn.1008-0821.2015.10.004
〔中图分类号〕G25073〔文献标识码〕A〔文章编号〕1008-0821(2015)10-0017-06
Evaluating the Quality of Content in Online Collaborative
Knowledge Production CommunitiesZhang BoQiao Huan
(Printing Science and Art Design College,University of Shanghai for
Science and Technology,Shanghai 200093,China)
〔Abstract〕Based on the Internet platform,the large-scale user collaborative knowledge production is a new mode of knowledge production,which can effectively utilize the collective wisdom of massive users,and facilitate the dissemination of knowledge.While unlike the traditional mode of knowledge production and dissemination,quality control and evaluation problems of the new mode really need to be improved.This paper used the analytic hierarchy process(AHP)to establish the content quality assessment model of collaborative knowledge production.The model combined the user requirement and content feature.The paper intended to provide theoretical and methodological framework of construction and operation to network related knowledge production platform.
〔Key words〕information quality;knowledge production communities;knowledge communities;collaborative writing;Wikipedia;AHP
近年来,随着Web20技术的日益成熟与普及,依托于互联网平台的协同知识生产社区逐渐兴起,已然成为知识生产和传播的重要途径。在面向社群的协同式写作过程中,参与协同写作人员通过网络平台进行交流协商达成知识的生产和传播这一目标。此类社区主要有两个特点:一是内容开放,即社区中的内容允许任何用户不受限制地复制、修改和散播;二是全民参与,即通过全民参与的大规模协作方式来对相关领域知识进行采集和整理。以维基百科和百度百科为代表的协同知识生产社区,赋予了民众对于知识的定义权和诠释权,这种通过多人参与,协商交流并且可重复进行的知识创造形式一方面是对于传统意义上只能由精英和权威来进行知识定义和诠释模式的解构,另一方面也对于由网络共笔所产生的内容质量控制提出了挑战。
当前对于网络协同知识生产的内容质量评估和控制研究已成为一个横跨计算机科学、物理学、管理科学、情报与图书馆等多个学科领域的研究热点。大部分学者都是从内容角度出发,针对社区中的词条页面、编辑页面和用户页面进行数据挖掘和分析[23],从而建立质量评估模型。这种质量评估模型可以得到海量并且客观的数据,但是对于数据的分析方法、指标的挑选以及分析结果的解读却局限于内容特点和研究者的主观选择,没有考虑使用者的客观需求。
本文结合用户需求与内容特征建立内容质量评估模型,确定质量评估因素。并采用层次分析法对每一个评估因素设置了合理的权重。与现有的评估模型相比,本文提出的模型充分考虑了信息对于用户的有用性和内容本身的客观特征,使得质量评估模型更加具有普适性与客观性。
1国内外研究现状
11信息质量定义
到目前为止,信息质量还没有一个被学术界普遍接受和统一的定义。国外学者普遍认可和接受的信息质量的定义是“fit to use”。Wang将信息质量定义为适合信息消费者使用的信息。Hilligoss认为信息质量应该是用户基于对信息的期望,对信息的有用性和良好性做出的主观评价[4]。Marschak指出信息质量表征的是信息描述客观事物或时间的准确程度[5]。Rieh将信息质量划分为5个层面,分别是有用、良好、准确、通用和重要[6]。Eppler指出信息质量是一个多维概念,是由信息质量的多种属性构成的集合,由多个质量维度取值情况来表现和决定,高质量的信息资源既要满足用户需要,又要符合客观实际[7]。endprint
国内的学者虽然在信息质量领域起步较晚,但是在国外学者研究成果的基础上,也做了很多透彻的分析研究。丁敬达对国外信息质量内涵的认知发展历程进行了梳理和考察,将其归纳为3个主要方面:基于信息本身的质量认知、基于用户反映的质量认知和基于二者融合的质量认知,并认为信息质量是指用户在进行浏览、阅读的基础上,感知到的信息内容内在特征以及信息需求或期望的满足程度[8]。查先进认为信息质量是一个相对概念,是信息价值的重要表现,是信息结构、品种、效用等属性在质和量两个方面优劣程度的总和[9]。高志勇从消费者需求的角度出发,认为信息质量是对信息产品满足信息消费者需要程度的衡量[10]。
从上述研究评述可以发现针对信息质量的定义主要包含了用户和信息本身两个方面,从用户角度而言强调信息可用性,从信息本身角度而言则强调信息准确性。本研究中的信息专指基于协同写作的在线知识社区中内容,伴随着互联网和群体智慧等特定语境下的新特征,信息质量的定义也就将被赋予了更多的新内容和新角度。
2015年10月第35卷第10期现?代?情?报Journal of Modern InformationOct,2015Vol35No102015年10月第35卷第10期协同知识生产社区的内容质量评估模型研究Oct,2015Vol35No1012信息质量评估模型
在信息质量研究领域中,质量评估模型的设计与应用是主要研究方向之一,很多学者都致力于建立一个基于语义学的,可预测,可重用的高效实用的质量评估模型。本研究总结历年来国内外具有代表性的信息质量评估框架与模型,并评述这些模型所包含的因素、维度等内容。
Wang & Strong(1996)提出了3种方法来研究信息质量:直觉法、理论法和实证法。直觉法是指用户根据自己的直觉和经历来判断信息质量,理论法是指评估信息质量的维度都是属于信息理论范畴内的,而实证法是指利用信息用户数据作为评估信息质量的主要因素。Wang & Strong总结的方法更多的关注于信息产品的开发质量而不是信息的使用质量[16]。
Strong,Lee & Wang(1997)将15个对数据用户重要的信息质量维度分成4种类别的分级框架,分别是(1)内在信息质量:准确性、客观性、可信性和权威性;(2)可访问信息质量:可用性、安全性;(3)语境信息质量:相关性、附加价值、时效性、完整性、信息量;(4)具象信息质量:可解释性、可理解性、简洁性、一致性。之后这个框架在3个知识密集型组织被测试出是高效和实用的[17]。
Kahn,Strong & Wang(2002)提出了一个评估信息质量的two-by-two概念模型。学者认为信息质量包含两个方面:产品质量和服务质量,此模型还区分了信息评估的客观标准和主观标准:符合规范、满足并超出用户的期望,模型中评估维度也被划分为了4种类型:完整性、独立性、可用性、有用性。此外,模型还应用了用户调查数据[18]。
Eppler(2003)提出的模型应该说是目前最完整全面的。Eppler在比较分析了20种信息质量评估模型后提出针对知识生产过程新的信息质量评估和改善模型。这个模型包含4个层面和16个维度:(1)社区层面:完整、准确、清楚和适用;(2)产品层面:简洁、一致、正确、通用;(3)过程层面:方便、及时、可追溯和可互动;(4)基础层面:可访问、安全、快速和可维护[8]。
Besiki Stvilia(2006)针对维基百科的信息质量进行了实证研究,通过对英文维基百科中的特色条目的讨论页和条目编辑历史的定性定量分析,以期创建维基百科信息质量保障机制,通过分析比较之前制定的信息质量评估模型,建立了维基百科的信息质量测评模型,并开展了相关实证研究[19]。
针对信息质量的研究方法,国外学者主要采用了内容分析、用户调查、任务实验和多智能代理模拟等技术和方法。但是正如曹孟谊所总结的现有的这些信息质量评估模型大部分都有明显的特殊领域和语境,而且几乎所有的模型中的指标都没有加权系数[20]。
国内关于信息质量的研究则刚刚起步,马小闳等参考国内外研究成果,采用层次分析法总结出一个具有通用性的信息质量评估模型,并确定了模型中各指标的权重[21]。裘江南等参考维基百科原有页面分级标准,从页面编辑情况和页面编辑者情况两个方面归纳出15个页面质量影响指标。然后基于C45决策树的页面信息质量分级评价模型,最后对该模型的有效性进行了检验[22]。丁敬达等基于丰富的实证或实验研究结合相关质量评价理论进行系统、规范的分析、比较和归纳,以构建出一个不依赖于具体情境的、对不同类型信息用户适用的维基百科词条信息质量启发式评价框架,为广大信息用户挑选和判别维基百科词条提供相应的基准、标准和方法[23]。
国内的研究虽然在国外学者的研究成果基础之上做了很多改进,但是仍然存在不足之处,例如,马小闳研究中所得出的指标权重是基于已有质量框架的总结;裘江南所采用的决策树方法并没有得到令人满意的实验结果;丁敬达则是从定性的角度提出了质量评价框架,缺乏一定的数据支撑。因此,本文提出了一种结合用户需求和内容特点,针对于协同知识创造社区内容质量的评估模型,并结合层次分析法,为模型框架中的各个指标设置了合理权重。
2质量评估指标
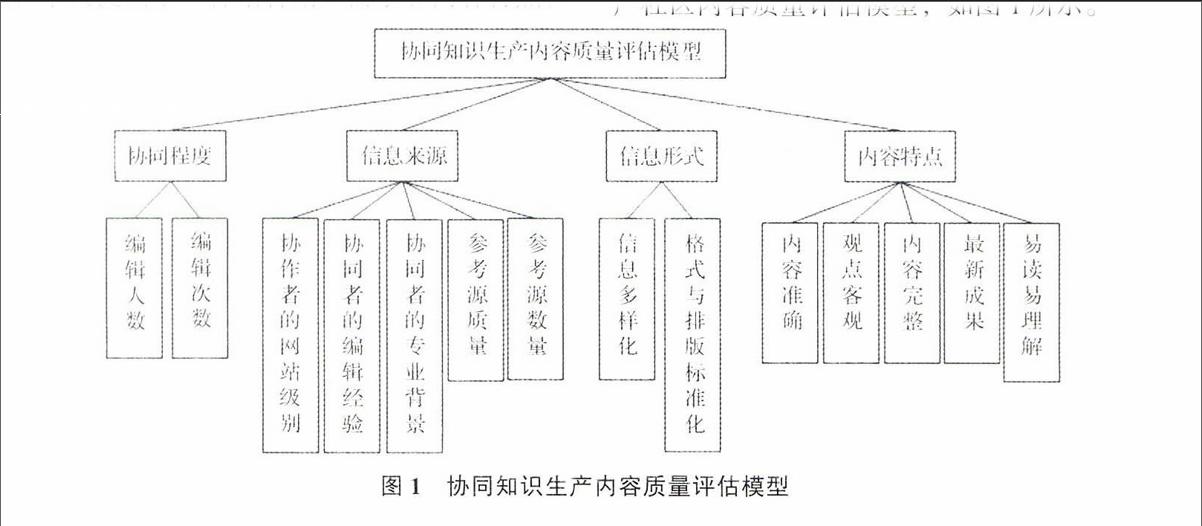
以上通过对信息质量概念和质量评估的研究综述,总结了现有工作的特点和不足。本文借鉴已有的研究成果,综合用户需求和内容特征,提出了影响协同知识生产社区内容质量的4个层面和14个维度,进而构建了协同知识生产社区内容质量评估模型,如图1所示。图1协同知识生产内容质量评估模型
21协同程度(A1)
借鉴张薇薇博士对开发内容可信度的实验研究,本文将编辑人数(A11)和编辑次数(A12)作为协同知识生产社区协同程度的衡量指标[11]。协同程度对于信息质量的影响程度历来众说纷纭,例如张薇薇在文章中提到了参与成员数量越多,意味着观点多样性越高,词条的可信度就越高。而Shyong在研究中却得到想要保证内容决策质量必须要控制群体规模和范围的结论[12]。本文暂不探究孰对孰错,因为无论编辑次数和人数与信息质量的关系如何,其作为协同程度的衡量标准还是有一定合理性的。endprint
22信息来源(A2)
221协作者
协作者包含协作者网站级别(A21)、协作者编辑经验(A22)和协作者专业背景(A23)这3个指标。协作者网站级别是指网站依据协作者在该网站中的活跃程度或参与程度而授予的称号,协作者的网站级别高并不代表协作者就是某一知识领域的专家,因为很多网站的积分或级别是可以通过多种方式获得的。协作者编辑经验是指协作者是否积极参与社区内容的编辑工作,而编辑经验也不代表协作者的专业水准,因为编辑内容不但包括对内容的增删改也包括对格式排版的修订,所以协作者编辑水平高既有可能说明协作者具有专业背景,也有可能说明协作者只是深谙社区规则和对文本的格式要求。Arazy O就曾通过编辑经验来确定这两类用户,他认为如果协作者只是专注于某特定类别条目的编辑,那么他们很可能是具有专业知识的人士,而如果协作者编辑的条目涉及多个类别和领域,那么他们就有可能是所谓的管理型用户,即参与的大部分工作是对内容格式和排版的修订工作[16]。
222参考源
参考源包含参考源数量(A24)和参考源权威(A25),维基百科认为最可靠的来源是大学出版社出版的同行评审期刊与书籍,大学级别的教科书,著名出版社出版的杂志、期刊、书籍,以及主流的报纸[15]。张薇薇博士根据现有研究和实践结果把各种类型的参考源划分为了4个等级,其权威性由高到低分别是基于同行审评的正式出版物和政府网站;新闻媒体和网站;电子商务网站;自媒体和UGC网站[12]。
23信息形式(A3)
本研究认为信息形式包含信息多样化(图片,音视频,链接)(A31)和格式排版标准化(A32)这两个方面。以图片、音视频和链接形式呈现的信息,虽然形式简单但包含的信息量却要多于文本。尤其是链接,链接是以互联网为平台的知识社区实现知识内关联和外关联最重要的方法。此外,每个网站对于文本格式都有自己的要求,格式排版的标准化反映了网站的正规性,同时也能帮助用户快速便捷地了解信息内容。
24内容特点(A4)
内容特点这一指标应该属于主观指标,不同用户对于相同内容的评价结果是不相同的。本研究中的内容特点包括内容准确(A41),观点客观(A42),内容完整(A43),包含最新成果(A44),易读性(A45)这五个方面。针对用户而言内容的准确、完整和客观更倾向于是对内容的可信程度,因为严格意义上讲用户认为可信的内容并不代表是正确的内容。而文章中是否包含最新成果是指内容的时效性,至于易读性则是指内容是否容易阅读和理解,将易读性归入内容特点这一指标也是有所疑虑的,因为易读性不但涉及到内容所反映的简易程度,同时也包括内容的呈现形式,而且不同专业领域里的知识内容的易读性对于不同的人而言差距较大,毕竟每个人的知识水平和专业背景也都不尽相同。也正是因为这一指标的主观性较大,所以最后还是决定将其归入内容特点中。
3实验方法及结果分析
31实验方法
根据评估指标设计问卷调查,问卷共包含14个测度项,并采用Likert 5级量表,来表示每个测度项的重要程度。调查对象主要是在大校学生,包括本科生、硕士研究生和博士研究生。在调查方法上,采用专业的在线问卷调查、测评、投票平台进行问卷发放,共收回有效问卷112份。而评估指标的重要程度则根据计算获得数据的平均值来表示。
32结果分析
321信度与效度分析
问卷在正式投入使用之前必须先对其信度和效度进行分析,只有信度和效度在研究可接受的范围之内时,使用该问卷所采集的数据才有分析价值。一般而言,克朗巴哈α系数在08以上都是可接受的,本实验在数据信度方面,克朗巴哈α系数为0892,这说明因子各测量指标具有较好的内部一致性。然后对所有自变量进行探索性因子分析,以检验结构效度。实验先进行Barlett球形检验及KMO样本测度,得到的结果值为0812,然后对应于14个测度项,使用主成分分析法和方差最大正交旋转的方法得到了4个因子,累计方差贡献率达到了72242%。各个测度项的因子载荷皆在06以上,表明问卷具有比较好的结构效度,并且因子分析结果符合预期。
322确定评价指标权重
本研究利用层次分析法来确定各个评估指标的权重。层次分析法(The Analytic Hierarchy Process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂正式提出。它是一种定性和定量相结合、系统化、层次化的分析方法,在处理复杂的决策问题上具有实用性和有效性等特点。
第一步:计算平均值,进行排序(见表1)。
第二步:构造两两比较判断矩阵。
在计算出的评估指标重要度的平均值的基础上,对各指标之间进行两两对比,然后按“1~9标度法”排定各评估指标的相对优劣顺序,得到各判断矩阵值,依次构造出评估指标的判断矩阵(如表3至7所示),它们分别是(A1,A2,A3,A4),(A11,A12),(A21,A22,A23,A24,A25),(A31,A32,A33),(A41,A42,A43,A44)。表1评价指标绝对重要程度排序
评估指标最小值最大值平均值协作者专业背景A23100500409协作者编辑经验A22100500379内容准确A41100500359易于理解与阅读A33100500359协作者网站级别A21100500357格式排版A32100500354观点客观A42100500349内容完整A43100500346编辑次数A12100500342信息形式A31100500339编辑人数A11100500338参考源数量A24100500335参考源权威A25100500331最新成果A44100500314
具体方法是比较第i个元素与第j个元素相对上一层某个因素的重要性时,使用数量化的相对权重aij来描述。成对比较矩阵中aij在1~9及其倒数中间取值。取值标准如下述标度方法(表2)所示。表21~9标度法endprint
标度含义1表示两个因素相比,具有同样重要性3表示两个因素相比,一个因素比另一个因素稍微重要5表示两个因素相比,一个因素比另一个因素明显重要7表示两个因素相比,一个因素比另一个因素强烈重要9表示两个因素相比,一个因素比另一个因素极端重要2,4,6,8上述两相邻判断的中值倒数因素i与j比较的判断aij,因素j与i比较的判断aij=1/aij
表3评估指标判断矩阵
A1A2A3A4A111/21/21A211/21/2A311A41
表4评估指标判断矩阵
A21A22A23A24〖〗A25A2111/21/522A2211/345A23178A2411A251
表5评估指标判断矩阵
A11A12A1111/2A121
表6评估指标判断矩阵
A31A32A3111/2A321
表7评估指标判断矩阵
A41A42A43A44〖〗A45A4112251A421141/2A43131/2A4411/5A451
第三步:计算权向量并做一致性检验
对每个矩阵计算最大特征值及其对应的特征向量,然后利用一致性指标和随机一致性指标做一致性检验。若检验通过,特征向量即为权向量;若不通过,则需要重新构造成对比较矩阵。
具体公式如下:AW=λW算得λmax=1n∑ni=1(AW)iWi,CI=λ-n〖〗n-1,CR=CIRI。
其中,λmax为矩阵最大特征值,n为判断矩阵的阶数,RI为平均随机一致性指标,可通过查表得到其值。当CR≤010时,判断矩阵满足一致性检验。针对本研究中的5个判断矩阵的一致性检验的结果分别00228,0000,00091,0000,00053,检验结果均小于010,所以判断矩阵具有一致性。
4质量评估模型构建
由上述计算步骤得到了各个指标的相对权重,建立了基于用户角度协同知识生产信息质量评估模型,如图2所示。模型中的数字表示指标权重,这里值得注意的是,每一个指标的权重指的是相对于上一级指标的重要程度,即一级指标权重是相对于总决策目标的重要程度,二级指标是相对于一级指标的重要程度。根据模型中的量化结果,我们可以得到如下结论。图2协同知识生产内容质量评估模型
(1)一级指标中的4个指标权重分别是01694、03944、02399、01972,其中信息来源对于用户而言是评估信息质量最重要的指标。而协同程度是被用户认为是对于评估信息质量重要程度最低的指标。
(2)对于信息来源指标,协同者专业背景对于信息来源的重要程度要远大于其它指标,这说明用户对于参与协同知识生产的用户专业背景要求很高,认为这个指标对于信息质量的影响程度是最大的。而通过其它指标的量化结果可以发现,同样是信息来源,协作者的个人作用要重于参考源的作用。
(3)信息形式对于信息质量的影响程度是02389,次于信息来源这一指标。而对于信息形式的影响程度,用户认为文章格式和排版的标准化要高于信息多样化。虽然量化结果如此,但在问卷中仍有不少用户提到信息多样化的问题,尤其是链接问题。
(4)在内容特点这一指标上,量化结果并没有像预期的那样认为是最重要最直观的指标,根据问卷结果发现很多用户不会过多的质疑知识社区的内容,也就是说,以维基百科和百度百科为主的百科全书网站中的内容可信度对于用户而言是很高的。因此,在这里可以解释为内容特点是呈现结果,在信息来源和信息形式有所保证之后,用户基本上就不会对内容质量产生质疑倾向。
(5)协同程度对于信息质量的影响程度最低,这个结论与用户更看重协作者的专业背景的结论可以综合起来进行分析。首先可以看出用户并不是认为编辑人数和次数越多,信息质量就会越高,其次协作者的质量要比协作者的数量对于用户而言更为重要,最后由高质量协作者参与编辑的内容编辑次数越多,信息质量就越高。
综上所述,本文从用户角度对以维基百科为代表的在线知识社区的信息质量评估做了初步的探索和研究,但是通过问卷调查我们也发现用户对于协同写作抑或是协同知识生产的概念理解得并不透彻。
大部分用户并不会积极参与条目的创建和编辑,因为用户认为参与此类活动的前提是自身必须具有完备的专业知识,而对于自身知识储备的评估使得大部分人是没有十足的信心认为自己可以参与这类活动的,也正是这种较为普遍的想法对社区吸引更多用户参与知识生产造成了阻碍。
因此,基于以上分析,本文对于协同知识生产社区的建设提出如下建议:
(1)社区应要求用户提供内容参考源的具体名称和详细信息,并且对此参考源进行核实查证,标明参考源的具体可信度。
(2)提高和完善用户的声誉评估系统,明确区分基于专业性和活跃度的不同评估标准。
(3)根据用户的反馈信息建立更加科学的用户激励机制,让用户更好地理解协同创造的含义,鼓励用户积极参与知识创造活动。
(4)网站还应更加注重完善条目内容的内外关联(链接)、信息形式多样性以及文本格式的规范性。
(5)目前维基百科和百度百科都没有提供下载服务,当然考虑到协同创造中的可持续重复的编辑活动特征,在什么情况下可以进行下载以及下载活动是有偿还是无偿等问题仍需要进一步的探讨和研究。
总而言之,协同知识生产的信息质量评估意义重大。由于协同写作过程非理性,修改无限制,认知多样性等问题,协同写作的成果质量一直无法预测和保证。本研究是从用户角度出发,结合了用户主观感受和客观内容特征因素,这有利于建立一个更加实用而客观的自动评价和分类模型,不但可以有效地对协同写作社区信息进行质量评估,而且还能对知识生产社区的建设提供可行参考,更好地促进知识生产社区的运营与管理。endprint
参考文献
[1]Paul Benjamin Lowry,Aaron Curtis,Michelle Rene Lowry,Building a Taxonomy and Nomenclature of Collaborative Writing to Improve Interdisciplinary Research and Practice[J].Journal of Business Communication,2004.
[2]Stvilia B,Twidale M B,Smith L C,et al.Information quality work organization in wikipedia[J].Journal of the American Society for Information Science and Technology,2008,59(6).
[3]wiki不完全手册[EB].http:∥www.cnblogs.com/Bonny.Wong/archive/2005/03/03/112084.html.
[4]2009中国维基发展报告[R].
[5]Hilligoss B,Rieh SY.Developing a unifying framework of crediblity assessment:Construct,heuristics,and interaction in context[J].Information Processing & Management,2008,44(4).
[6]Marschak J.Economics of information systems[J].Journal of the American Statistical Association,1971.
[7]Rieh S Y.Judgement of information quality and cognitive authority in the web[J].Journal of the American Society for Information Science and Technology,2002,53(2).
[8]Eppler M J.Managing information quality:Increasing the value of information in knowledge intensive products and processes[M].Berlin:Springer Verlag,2003.
[9]丁敬达.维基百科词条信息质量启发式评价框架研究[J].图书情报知识,2014,(2):11-17.
[10]查先进,陈明红.信息资源质量评估研究[J].中国图书馆学报,2010,(2):46-55.
[11]高志勇,高建民,陈富民.数字化制造中的信息质量问题研究[J].计算机集成制造系统,2005,11(7):981-985.
[12]张薇薇.开放内容可信度的实验研究[J].情报科学,2012,(12):1830-1839.
[13]Shyong(Tony)KLam,Jawed Karim,John Riedl.The Effects of Group Composition on Decision Quality in a Social Production Community[C].Proceedings of the 2010 International ACM SIGGROUP Conference on Supporting Group Work,GROUP 2010,Sanibel Island,Florida,USA,November 6-10,2010.
[14]莫祖英,马费成,罗毅.微博信息质量评价模型构建研究[J].信息资源管理学报,2013,(2):12-18.
[15]维基百科可供查证[EB].http:∥zh.wikipedia.org/wiki/Wikipedia:V#.E5.8F.AF.E9.9D.A0.E6.9D.A5.E6.BA.90.
[16]Arazy O,Nov O,Patterson R,et al.Information quality in Wikipedia:The effects of group composition and task conflict[J].Journal of Management Information Systems,2011,27(4):71-98.
[17]Wang R Y,Strong D M.Beyond Accuracy What Data Quality Means to Data Consumers[J].Journal of Management Information System,1996,12(4):5-30.
[18]Kahn B,Strong D M,Wang R Y.Information quality benchmars:product and service performance[J].Communications of the ACM,45(4):184-192.
[19]Besiki Stvilia.Measuring information quality[D].The University of Illinois at Urbana-Champaign(USA),2004.
[20]曹孟谊,吴建明,孟秀玲.国外信息质量评估指标体系研究[J].军事运筹与系统工程,2004,18(4):55-58.
[21]马小闳,龚国伟.信息质量评估研究[J].情报杂志,2006,(5):19-21.
[22]裘江南,翁楠,徐胜国.基于C45的维基百科信息质量评价模型研究[J].情报学报,2012,(12):1259-1264.
[23]丁敬达.维基百科词条信息启发式评价框架研究[J].图书情报知识,2014,(2):11-16.
(本文责任编辑:郭沫含)endprint
