证据真实性及其强度的科学性评估
2015-12-08崔景旭
崔景旭
(中国刑警学院 辽宁 沈阳 110035)
证据真实性及其强度的科学性评估
崔景旭
(中国刑警学院辽宁沈阳110035)
结合DNA和语音证据的真实性和强度评估,讨论如何使证据达到“确实、充分”标准。证据真实性和强度评估是通过刑事鉴定技术进行的,传统鉴定方法是直接比对检材与样本的特征参数,根据其特征参数的异同与相似度,由鉴定人员给出鉴定意见。贝叶斯似然率理论不直接比对检材与样本,而比较检材与样本同源与不同源的概率。基于统计分析得到两个概率比值,自然地给出证据的真实性和强度,使鉴定意见摆脱人为因素影响。
贝叶斯似然率理论源内变异与源间差异参考数据库
1 引言
刑诉法第五十四条规定“在侦查、审查起诉、审判时发现有应当排除的证据的,应当依法予以排除,不得作为起诉意见、起诉决定和判决的依据。”首先应当依法予以排除的是非法收集的言词类证据,以及非法程序收集的实物证据;其次是达不到“确实、充分”标准的证据材料。刑诉法规定八类证据都是材料,不是事实,证据材料可能为真,也可能为假,它们的真伪需要鉴定。鉴定是对涉案未知客体(检材)和已知客体(样本)进行同一认定的过程。为检测客体同源与否,必须寻找客体源内变异(Within-source Variability) 和客体源间差异 (Between-sources Variability),同一认定的前提是源内变异小于源间差异。鉴定是采用物理的、化学的、生物的等不同技术方法实施查证核实的过程。修改前的刑诉法将鉴定结果称之为“鉴定结论”,刑诉法将其改为“鉴定意见”,应该说这个修改比较准确地反映了鉴定结果的属性。事实上,鉴定结果与技术方法,鉴定人员的专业水平和实践经验,分析、提取特征参数的设备性能以及判断同一认定模式,都会对鉴定结果产生影响。鉴定结果是鉴定人员的“一家之言”,不应该称之为“鉴定结论”。国外对近20年不同证据发生的错案率进行调查表明:DNA证据发生的错误率大约为1~2%,工具痕迹达35%,笔迹错误识别率为36%,咬痕的错误识别率为60%。中国缺少这类统计数据,但是,2006年召开的全国刑事科学技术会议曾经指出:在DNA、指纹、声纹、笔迹、足迹等法庭证据的同一认定上都出现过错误。在“重结果轻过程”思想影响下,一些执法、司法人员拿到鉴定书时,首先看的是“鉴定结论”,不关心鉴定结论的导出过程,也很少有人质疑“鉴定结论”。刑诉法规定“鉴定意见”是证据材料之一,公、检、法部门查证核实它是法定任务。
为减少因证据导致的错案,人们一直寻求评估证据真实性及其强度的科学方法。托马斯·贝叶斯是18世纪数学家,贝叶斯概率论的一个核心思想是:从不确定事件里得到的实验数据,以何种方式解释,才能给出符合事物本来面貌的结论?20世纪90年代末期,法庭科学家将贝叶斯概率理论应用于具有不确定性的案件证据,发展出贝叶斯似然率理论(Bayes’Likelihood Ratio),用于评估证据真实性和强度。对DNA,玻璃、油漆、语音等证据材料的强度评估都取得了满意的结果。本文结合DNA和语音证据的似然率评估,介绍贝叶斯似然率理论,并讨论该理论对完善证据制度的意义。
2 贝叶斯似然率理论
2.1似然率的基本概念
传统鉴定方法是对未知客体和已知客体直接比对,寻找其源间差异和源内变异。贝叶斯理论认为,检材与样本存在的差异使得同源与非同源都成为具有不确定性的概率事件,主张检材与样本同源也好,主张非同源也好,在未经证实以前都是一种假设。贝叶斯理论将主张同源的称为控方假设,主张非同源的称为辩方假设,它们都是以概率形式出现的,通常H0表示同源假设,H1表示非同源假设,其概率形式是:其中,P代表概率,E代表证据,|代表条件。(1)是控方假设概率,(2)是辩方假设概率,将两个概率之比定义为似然率(Likelihood Ratio,LR):


似然率方法与传统鉴定方法的最大区别是:不直接比较检材与样本,代之以同源与非同源概率之比,两个概率竞争的结果决定证据的真实性和强度。
似然率的意义是:在证据E与检材和样本都存在差异的条件下,检材与样本同源的概率是非同源概率的LR倍。
因为P(E|H0)+P(E|H1)=1,在LR已知时,可以得到:
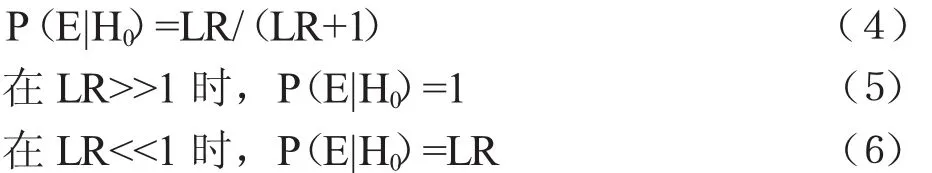
2.1.1似然率的定性作用
根据多种证据似然率的评估结果,可以将似然率的定性作用分为三种:①LR=1,从公式(4)得到:P(E|H0)=P(E|H1)=0.5,同源与非同源的概率都是0.5,与此对应的是无解,即无法判断;②LR>1,预示检材与样本同源;③LR<1,预示检材与样本非同源。
2.1.2似然率定量作用
根据LR数值范围,可以估计对控方和辩方的支持强度,表1给出了LR数值及与之对应的支持力度的文字解释。

表1 LR数值及解释
2.2DNA证据的似然率评估
在DNA检验中,似然率的定义是

该定义分子“嫌疑个体为物证DNA供体的可能性”等价于控方假设概率,分母“人群中随机供体为物证DNA供体的可能性”等同于辩方假设概率。
DNA似然率评估公式是

Pm是基因型频率(genotypic frequency),它是群体中某特定基因型个体数占全部个体数的比率。
满足哈代-韦恩贝格(Hardy-Weinberg)平衡法则时,可用基因频率计算基因型频率。纯合子基因型频率等于基因频率的平方,杂合子基因型频率是一对等位基因频率的乘积,再乘以2:

DNA似然率评估案例
表2给出的是某犯罪嫌疑人的基因型(样本)与现场物证检材的基因型的比对结果。表中列有短串联重复序列STR(Short Tandem Repeat)的13份基因座,等位基因1、等位基因2分别来自样本与检材,LR是单个基因给出的似然率。由于基因座是彼此无关的,累计LR是单个基因似然率之积。表中的D7S820、TH01、TP0X、CSF1PO是纯合子基因座,其余9个为杂合子基因座。
表中第一项是杂合子基因座D3S1358,它的等位基因频率是
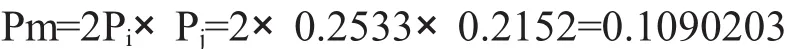
与之对应的似然率是
LR=1/Pm=1/0.1090203=9.17
同样方法可以计算出第二个杂合子基因座VWA的LR=8.87。表2给出头两项的累计LR是81。

表2 样本与检材的基因型匹配数据
表中第9项D7S820属于纯合子基因座,它的等位基因频率是

与之对应的似然率是

从表2可以看出,随着基因座数目的增加,累计的似然率LR增加很快,前4项累计LR已经达到16364,这意味着:嫌疑个体为DNA供体的可能性是人群中随机个体为DNA供体的可能性的16364倍,对照表1可知,此时已经是“非常强的证据支持控方”。根据公式(4),可以得到与此对应的控方假设概率是99.99%。
似然率方法在DNA证据评估上取得极大成功,主要归功于:①DNA具有极大的个体差异。实验发现:单用一个探针,个体间完全相同的概率小于3× 10-11。如果用两个探针,个体间的机会相关概率小于5×10-19。以当前世界70亿人口计算,与这样两个概率对应的人数分别小于0.21个和3.5×10-9个,这意味着世界上没有两个人的DNA指纹完全相同(同卵孪生除外);②存在并且发现携带个体特征的基因座。在人类基因组中约有5万~10万个短串联重复序列STR,它的重复单位小,仅为2~7bp,重复序列也很短,更易于扩增,分型检测的灵敏度更高;③各国对STR序列做了深入实验研究,已经揭示出STR基因座频率随着人种、民族和居住地区的变化规律,建立了不同人种、民族的基因座频率数据库;④深厚的基础研究。DNA是目前各国最为重视的学科。DNA的基础研究实验室、应用研究实验室遍布世界各地,大批生物学、遗传学、遗传工程、信息技术、数理统计等方面专家纷纷加入DNA研究领域。他们的研究不断加深对DNA本质的认识,能够持续地提供最新研究成果,用于完善DNA似然率评估方法。
DNA似然率评估是建立在数理统计基础上的,避免了经验式的主观判断,具有清晰和标准的分析过程,给出的是概率性的结果,不再是“认定/否定”绝对式的结论。可以说,DNA证据的评估方法为法庭物证鉴定提供了“标准样本”。
2.3语音证据的似然率评估
语音证据似然率公式是

其中,E代表语音证据,P(E|H0)是控方假设概率,P(E|H1)是辩方假设概率。
共振峰决定元音音色,它们也是话者语音声学特征的承载元,早期选择评估参数就是元音共振峰。表3给出利用澳大利亚英语“hello/heləu”里第二个音节之/l/和/əu/的第二共振峰F2测算的LR数据。表中x代表未知和已知语样F2的平均值,SD代表标准偏差,n代表提取语样的次数。表中的RS、MD、EM、PS、JM、DM等均表示发音人,他们在不同时段所发的“hello”构成未知与已知语样。表3给出了由/əu/和/l/的F2计算得到的LR,组合LR是二者的乘积。
从表3可以看到:①同一话者对RS1/RS2.1给出的LR都不大,组合LR也只有5.34;而同一话者对(MD1/MD2.2)的组合LR居然是0.06,与实际情况相反;②不同话者对EM2.1/RS2.1的LR都小于1,符合实际情况。而不同话者对JM1/DM2.2又出现与实际情况相反的结果:JM1/DM2.2之/əu/的F2给出LR=4.50,由于JM1/DM2.2的/l/之F2给出特别低LR值,它们的组合LR是小于1的。这些结果表明,元音共振峰虽然具有个体特征,但并不意味着每个共振峰评估结果都能给出符合真情况的结果。为改进评估效果,Aitken和 Lucy等人提出多变量似然率(Multivariate LR,MVLR)计算公式。
我们利用MVLR公式,测试了汉语普通话似然率区分能力。图1给出一幅代表性的Tippett图,也叫可靠性函数图谱。它的横坐标是以10为底的LR的对数值,纵坐标是累积的话者对得分。图1左边是/i/共振峰组合得到的Tippett图,左边是/y/共振峰组合得到的Tippett图,其中实线表示F1、F2和F3的组合结果,虚线代表F2和F3的组合结果。可以看到:图中代表不同话者对(DS)的左侧曲线随着Log10LR的增加逐渐下降,代表相同话者对(SS)的右侧曲线随着Log10LR的增加逐渐上升,二者的交汇点原则上出现在Log10LR=0处。DS和SS曲线的这种分布形态与前边关于LR具有定性区分功能的讨论是一致的。
在/i/的F1,F2和F3组合计算中,最大的Log10LR=2.397,即LR=249,根据表1,是中等强度的支持控方假设。最小LR值是2.0E-6,根据表1,该LR值非常强地支持辩方假设。
MVLR公式复杂,计算量很大,提取评估特征参数的工作量也很大。本世纪初,研制出基于贝叶斯原理的似然率自动评估系统,图2是该系统框图。
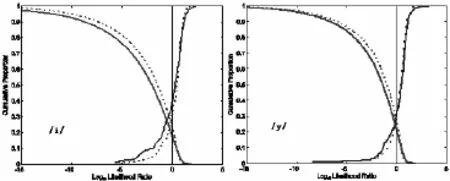
图1 利用元音/i/和/y/共振峰得到的Tippett图

图2 似然率自动评估系统框图
图底层的潜在人群样本数据库 P(Potential Population Database,P)、嫌疑话者参考数据库R(Suspect Reference Database,R)以及嫌疑话者控制数据库C(Suspect Ccontrol Database,C) 是整个计算的基础。未知语样(Trace)指的是在现场得到的语音检材。
P库:原则上它应该覆盖人群中可能出现的所有嗓音,从P库里应该能找到到和任何未知语样相似的嗓音。未知语样(Trace)录音条件多种多样,它们很难和P库完全匹配,其中以信道不匹配对似然率影响最大。目前是按照信道类别如座机、手机、录音机、MP3等建立几个P库。这样才能从P库找出与未知语样相关的潜在人群数据库。还可以按照性别、语种、方言等建立另外一些P库。P库用于计算源间差异的。
R库:记录嫌疑人的录音。建立该库时,其录制条件和语音学条件应尽可能的与P库记录一致。R库是用来构建嫌疑话者模型,用于计算源内变异。
C库:存储的是和检材很相似的嫌疑人的录音,C库的记录来自R库。
该图右路的任务是利用P库和未知语样,经过比较分析,得到LR的分母;中路的任务是利用未知语样与R库比较,得到证据值E;左路是利用R库与C库经过比较,得到得到LR的分子。
语音特征参数。早期话者话者自动识别系统使用的都是声学意义明确的短时声学特征量如基频,共振峰,短时帧能量等。现在自动识别系统,包括似然率自动评估系统,常用的特征量有梅尔倒谱系数(MFCC),线性预测倒谱系数(LPCC),感觉加权线性预测(PLP)等。
话者模型。目前似然率自动评估系统都采用MFCC构建的高斯混合模型(GMM)作为话者模型。GMM既能模拟瞬态、也能模拟稳态的声道特征,在信道噪声以及频谱失真的情况下表现比较稳定。混合数为M阶的GMM第i个话者的概率密度分布函数(probability density fuction,pdf)是:
其中,P(x/λ)是M阶加权的GMM密度值;D是多维矢量空间的特征参数,共有d个特征值;πi是混合权重;μi是某个分量密度的平均矢量也叫均值矢量;Σi是第i个分量密度的协方差矩阵,X是d维观测矢量;(x-μi)T是(x-μi)的转置。
GMM的一个话者模型可以表示为:
公式(12)的fi(x)和麦克斯韦速率分布f(v)物理意义相同。f(v)表示在平衡态下,分布在任一速率区间v~v+△v的分子数△N占总分子数N的百分率;fi(x)代表在在某个LR值附近的话者数目在统计人群里所占有的百分比。它们都是概率密度函数,差别仅仅在于变量数目:f(v)是标量v的一维函数,fi(x)是MFCC构成的多维变量函数。
图3是自动评估系统给出的概率密度分布随Log10LR的变化形态。虚线是P(E|H1)的pdf曲线,实线是P(E|H0)的pdf曲线。根据语音证据E计算得到Log10LR值,通过该值作横坐标的垂线,在P(E|H0)和P(E|H1)上截取两个概率密度值,二者之比即为语音证据E的似然率LR。图3给出的是
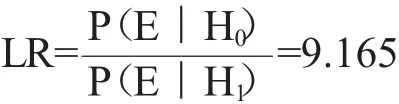
2.4似然率应用案例
2.4.1西安敲诈案
西安张某接到一个恐吓电话,一个男子要她往指定的卡上打10万元。张某从嗓音上听出他很年轻,问他哪里人,对方回答说“西安的”。敲诈电话(检材)长度116秒,内有女、男二人对话。张某报案后,警方从犯罪嫌疑人吴某那里提取了语音样本,制作了长度分别是68秒和44秒两段样本。送检方要求判断检材与样本是否同源。
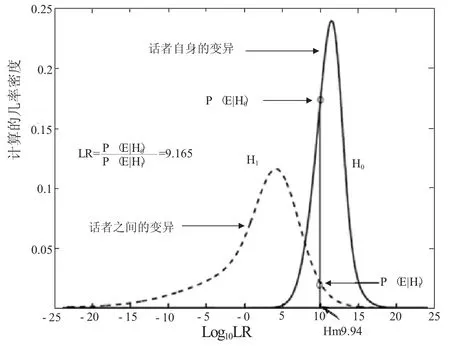
图3 概率密度曲线及LR的计算
我们利用西班牙的BATVOX系统测试了检材与样本的似然率,结果如图4所示,左侧高而窄的是P(E|H1)的pdf曲线,右侧低而宽的是P(E|H0)的pdf曲线,语音证据E的是垂直横坐标的绿线。根据证据的Log10LR与两个pdf的交点,计算得到的LR=9.9999× 109,该值强烈支持控方假设,即检材与样本嗓音是同源的。似然率评估和听觉感知与声学分析是一致的。

图4 西安敲诈案的P(E|H1)和P(E|H0)曲线
2.4.2房产纠纷案
大连某乡镇地区发生一起房产纠纷案。浦某将孙某告到法庭,因为孙在他的房屋居住十多年之久,一直不付购房款。在孙某到浦家交涉时,浦某做了录音,以此为证,浦某将孙某告上法庭。法院录制了浦、孙二人语音样本,要求确认录音中两位男性是否是浦某与孙某。

图5 孙某(左)浦某(右)的pdf曲线形态
利用BATVOX系统,分别测试了浦某与孙某检材与样本的LR数值。图5给出孙某(左)浦某(右)的pdf曲线分布以及语音证据E的位置。从该图可以看出:浦某证据E在P(E|H0)的pdf曲线交点处于较高位置,与P(E|H1)的pdf曲线交点处于很低位置,因此,浦某的LR值高达3.68E7。和浦某相比,孙某证据E在P(E|H0)的pdf曲线交点处于较低位置,而与P (E|H1)的pdf曲线交点处于较高位置,导致LR=P(E|H0)/P(E|H1)之值下降,实测LR值是11.59,虽然支持控方假设,但是“有限强度地支持”。出现这样结果的原因是:浦某是原告,录制样本时,他的发音状态与检材的状态差别很小。而孙某是被告,他的样本语音强度弱,基频低,语气和检材的差异也很大,这意味着孙某的源内变异加大,后果就是支持控方假设的概率降低。
2.4.3昆明贩毒案
昆明市公安局截获某男性与某女的电话录音(检材),男性何某杰归案后承认女的是帕·某某逊(女,维族),是他的贩毒伙伴。市局分别制作何某杰的样本1和帕·某某逊的样本2,送检方要求鉴别它们是否与男性、女性检材同源。
听觉感受到的男性检材和样本1里满是沙哑、干涩的语句,嗓音里有大量随机出现的清音浊化、浊音清化存在。声带疾患引起的嗓音个体特征非常明显,它们足以证明男性检材与样本1是同源的。
女性检材与样本2的发音偏离汉语调形规范,如“再见”尾音jiàn是去声,而她的尾部基频却呈现上扬态势,听起来有些洋腔洋调。元音三角形证明,两份女性语样发音者的舌位活动范围比汉族女性的小得多,存在明显的央化现象(图7)。听觉和声学检验表明,女性检材与样本2是同源的。
图6给出女性检材与样本2的似然率评估结果,LR=9.999×109,强烈支持帕·某某逊样本与检材女性语音同源的假设。男性检材与样本1的似然率评估结果却是LR=0.844<1,给出男性检材与样本1不同源的错误结果。原因是:本案男性病态嗓音非常特殊,P库也好,R库也好,都缺乏能够与之匹配的参考语音数据,导致使得似然率的分子、分母的计算失常。本案例证明,参考语音数据库与检材/样本的匹配功能对似然率评估影响很大。
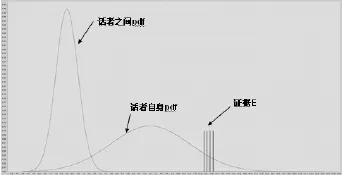
图6 昆明贩毒案女性pdf曲线

图7 检材女性与汉族女性元音三角形的比较
3 小结
贝叶斯似然率理论在DNA鉴定上的成功,证明该理论完全适用于法庭证据真实性及其强度的分析和评估。DNA似然率的分析和计算模式已经成为其他证据似然率评估的“标准样本”。
贝叶斯似然率理论已经对英语、澳大利亚英语、法语、日语、汉语等多种语音做过评估。我们对汉语似然率计算有过实验研究,并且将它应用于实际案例,这些实践证明似然率评估方法适用于汉语语音证据分析和判断。真实案例中严重影响人工鉴定的因素如检材与样本方言土语的差别,检材与样本基频的差别,语速的差别等等,对似然率评估几乎没有影响。目前,基于高斯混合模型(GMM)的似然率自动评估系统已经在中国公安、安全系统推广使用。
笔者建议应该像采集指纹、DNA数据那样,采集重点人口的语音数据,建立大规模的语音数据库,为语音证据似然率评提供包容性更强、适配性更高的参考语音数据库。
[1]Michael 1.Saks,Forensic Identification Science:A SummaryoftheTheory,the Science,and the LegalHistory[R].NACDL,NewOrleans,2005.
[2]Joaquin,G.R.,et al.BayesianAnalysis of Fingerprint,Face and Signature Evidences with Automatic BiometricSystems[J].Forensicscienceinternational,vol. 155,2005:126-140.
[3]Meuwly,D.Biometrics in forensic science: fingerprint,voice,DNA,invited presentation.Iden tech. 2005.
[4]Meuwly,D.,Drygajlo,A.Forensic speaker recognition based on a Bayesian framework and Gaussian mixture modelling(GMM).In:Proceedings of the 2001 Speaker Odyssey Speaker recognition Workshop,2001: 145-150.
[5]Baldwin,D.J.Weight ofevidence for forensic DNA profiles[M].Chichester,U.K.Wiley,2005.
[6]Rose,P.Difference and Distinguish Ability in the AcousticCharacteristicsof HelloinVoiceof Similar-sounding Speakers-A Forensic Phonetic Investigation[J].Australian Review ofAppliedLinguistic,1999,21(2):1-42.
[7]Aitken,C.G.G.,Lucy,D.Evaluation of trace evidence in the form ofmultivariate data,Applied Statistics, 53/4,109-122,2004.
[8]Hollien,H.TheAcousticof Crime[M].New York: Plenum Press,1990:209-210.
[9]王彦吉,王世全.刑事科学技术教程[M].北京:中国人民公安大学出版社,2009.
[10]张艳云.法庭语音证据强度评估的新方法研究[D],沈阳:中国刑警学院,2008.
(责任编辑:郭帅)
D918
A
2095-7939(2015)01-0029-06
2014-10-25
崔景旭(1938-),男,辽宁本溪人,中国刑警学院教授,主要从事司法语音学研究。
