基于Hadoop的校园网站日志系统的设计与实现
2015-12-02姜开达章思宇
姜开达, 章思宇, 孙 强
(上海交通大学网络信息中心,上海 200240)
0 引 言
随着云计算等技术的兴起与发展,大数据正在深刻地影响着人们的工作、学习和生活,甚至左右着国家经济和社会发展,我们已经迈入了大数据时代.如何在教育信息化领域充分理解并迎接大数据技术带来的机遇和挑战,利用海量数据来挖掘信息、判断趋势、提高效率?这是高校信息化部门未来建设数字化校园过程中必须面对的挑战.
大数据作为一门还在快速发展中的技术,在校园网络应用中的落地需要一个渐进的过程.上海交通大学信息化部门建设了多个基于OpenStack和Hadoop的分布式云计算基础平台,给学校的科研工作和各类校园级应用提供了有力支撑,近年来也在利用Hadoop平台长期存储和快速分析海量校园网站访问日志方向进行了一系列探索和实践.
1 校园网站的日志搜集需求
从IT系统管理运维的角度出发,需要有统一的方案来监控全体服务器的运行数据,包括Web应用服务端程序的日志也值得集中分析和处理,以及时发现运行异常和评估网站服务状况.由于安全投入和重视普遍不足,高校网站一直是受黑客攻击的重灾区,面临着各种来源和不同类型的漏洞扫描、攻击入侵以及敏感数据泄露的威胁.彻底的网站日志分析可以及时发现安全薄弱点和已被入侵的站点,完整的网站日志在出现网络安全事件后可能也是回溯追踪的重要线索.
对大型互联网公司诸多网站产生的海量日志存储和分析,存在多种成熟的方案.一种流行的架构是使用Flume(采集)+Kafka(接入)+Storm(分析)+HDFS(存储)的组合.Flume是一个高可靠且分布式的海量日志采集、聚合和传输系统,可用于收集数据并在进行简单处理后写到各种数据接收方.Apache Kafka是LinkedIn开源的高吞吐量分布式发布订阅消息系统,主要用于处理活跃的流式数据,解决采集速度和处理速度不同步的问题.Storm是Twitter开源的一个分布式实时计算系统,支持对流式数据进行处理.HDFS(Hadoop分布式文件系统)是一个高容错性的系统,基于廉价的硬件来提供高吞吐量的数据访问,非常适合大规模数据的存储应用.
高校校园网站虽然单个规模都不大,但是数量众多.如上海交通大学校园网内的网站数量就已过千,并且极为分散.除了学校数据中心集中了一批重要Web的应用服务器以外,在校内机关/院系所/实验室还有大量的各类网站应用.这些网站服务器的操作系统和Web服务程序版本众多且无法统一,部分定制化的专业应用无法升级;管理人员的能力参差不齐,无法做到分布式的基于主机部署Agent的Web日志收集.这些特点决定了高校不能完全照搬互联网企业的模式,而应该有自己的创新措施来满足Web日志集中搜集的需求.
2 校园网站日志的采集模式
上海交通大学采取的方案是在校园网边界出口处分离出外网访问校园网内Web信息系统的网络流量,以及校内数据中心出口的访问服务器网络流量,对其进行应用层协议分析,提取完整的HTTP请求header报文信息(GET/POST)和Response报文信息,从网络流量中而不是主机上尽可能完整地按需要还原出所有类似access.log格式的Web访问日志.这样既可以集中获得所有访问日志,也可以跨网站服务器平台来统一日志格式,同时避免了某些系统被入侵后产生的日志被删除的缺陷,唯一的缺点是对于使用HTTPS类型的加密网络流量,没有SSL证书的情况下无法从网络流量中还原出原始内容,这部分还是需要依赖相关主机的日志系统.
有一些商业用户行为审计或者流控产品可以通过Syslog或以其他接口输出不同类型和格式的URL访问日志,但是灵活性和可扩展性不足.为了满足校园网10 Gbps的实际流量处理需求,我们基于开源软件和开源库,自行在x86平台底层实现了从高速网络流量中提取自定义的Web日志到本地文件,目前的主流服务器(Xeon E5-2600系列)下可以达到单机每日10亿字节量级的稳定日志生成能力.
从上海交通大学校园网今年前7个月的统计来看,存储全校一千多个网站的原始Web访问日志涉及到的数据量级已在百亿字节以上,并且这些数据还在随着时间的推移而线性增长.传统的Oracle、MySQL、SQL Server等关系型数据库并不适合海量日志存储这种低实时性要求的小并发查询应用场景,并且在数据量到达一定级别之后会出现各种瓶颈.如果没有合适的手段来查询和分析Web访问日志,这些数据中蕴含的真正价值就无法得到体现,因此把每天生成的海量日志文件定期增量导入到Hadoop大数据平台就成为必然选择.
日志文件的格式定义如下表所示,不同字段之间用“|”来完成分隔,为了避免文件的无限增长,日志文件按小时滚动生成.

表1 日志文件格式定义
3 Hadoop大数据平台的建立
Hadoop起源于Google,是目前由Apache基金会维护的分布式系统基础架构,用户可以使用相对廉价的分布式硬件系统,通过MapReduce的技术,满足海量数据存储和高性能的分析处理需求.围绕着Hadoop生态系统,又有HBase、Hive、Pig、Sqoop等众多的开源项目发展起来,形成了一个完善的、选择多样的大数据解决方案.在众多大数据解决方案中,Hadoop是实现企业级大数据分析平台的首选,已经在国内外互联网领域得到了广泛使用.
完全手动安装Hadoop平台需要集成很多周边组件,繁琐且不易于维护和扩展.类似于Linux操作系统存在众多发行版,Cloudera和Hortonworks等公司推出了集成的Hadoop发行版(包括开源和企业两个版本),极大的简化了大数据平台的部署和维护流程.
上海交通大学在校内使用了Cloudera的开源版本(CDH5.1.0)构建了一个28台物理机节点组成的Hadoop大数据分析平台(24个存储计算节点,4个管理节点).每计算节点配128 G内存,两路八核Xeon E5-2670 CPU,两块240 GB的SSD硬盘和12块2 TB硬盘,所有节点之间通过万M以太网完成高速互联,HDFS总容量超过450 TB.
通过Cloudera Manager,可以方便地使用图形界面在64位CentOS6.4上部署HDFS、YARN/MapReduce、HBase、Hive、Impala、Spark、Sqoop、Solr等服务,并且监控集群服务器的状态、资源使用情况和运行中的数据处理任务.
通过集中采集得到的网站日志会利用脚本定期自动导入Hadoop平台的登录节点,再采用Hadoop FS-put命令将文件日志导入进HDFS,并且每个文件导入HDFS时都可以单独选择分块尺寸和副本数,合理调整这些参数可以提高存储效率.创建HIVE表来定义存储格式,例如:

然后定期把HDFS上的新日志文件增量导入到HIVE表,例如:
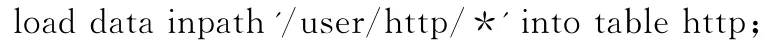
实际初期使用中对网站日志进行分析时,发现硬盘读取速度是最大瓶颈,但集群CPU使用率并不高,这时对数据进行压缩存储,降低文件大小成为一个必然的选择.Hadoop的MapReduce任务,以及Impala等SQL引擎在读取HDFS文件时可自动解开常用的压缩格式.将导入到HDFS的文件转换为压缩格式存储,一方面提高空间利用率,另一方面在处理日志时,相同的磁盘I/O速度读取的日志量更多,原本闲置的CPU资源用于在线解压缩,任务执行时间明显降低.
要运维好一个Hadoop集群和上面的应用,最大化发挥硬件潜能,需要管理人员在长期的实际使用过程中不断对配置进行调整优化,积累各方面经验.
4 网站日志分析
对Hadoop中存储的海量数据进行分析有多种方法,传统是编写MapReduce程序来进行处理,这种方式灵活性好,但是开发周期较长.Pig作为一种编程语言,简化了MapReduce的开发,提供了简单的编程接口.Hive提供了HiveQL语言接口,将类SQL语句翻译为MapReduce任务执行,对熟悉关系型数据库的使用人员更为友好.Impala是Cloudera公司主导开发的实时查询引擎,它提供SQL语义,直接跳过了MapReduce过程,可以高速查询存储在HDFS中的PB级大数据,给数据分析人员提供了快速实验和验证想法的手段.在我们实际日志分析过程中,Impala最快在4 min内完成了对400亿条网站日志数据的扫描,查询速度明显超过Hive,因此成为最常用的一种分析工具.Hadoop Streaming支持Shell命令的使用,因此grep/cat/awk等Linux下的分析统计工具还是可以继续针对HDFS上的数据文件来灵活调用.
国家对非经营性互联网信息服务实行备案制度,学校信息化部门是否了解校园网内有多少个网站?访问量排名的Top100 Sites是哪些?所有网站的网址分别是什么?不同时间段的访问量各有多少,来源如何分布?其中有多少使用了非edu.cn的域名?有多少网站仅使用IP而不是域名提供访问?有多少网站使用了非80端口提供服务?这些网站分别使用了何种Web服务端程序?要回答这些问题,显然不能依赖派发调查表这种低效的方式,只要对Hadoop平台的web日志用Impala进行各种针对性的数据挖掘,这些答案就全都可以准确给出.
对于突发性的重大安全漏洞,通过大数据分析可以在早期迅速给出安全预警和大范围安全评估.近年来的Apache Struts2漏洞每次爆发都在互联网上掀起腥风血雨,上海交通大学校园网内基于这种Java框架的应用信息系统也有近百个,不及时处理就难逃一劫.怎么快速的从数千个网站之中找出哪些使用了Struts 2开发框架?通过Impala查询HTTP访问URL数据中Path的一些特征字段(.action和.do等)并配合awk/grep/sed/sort等Linux Shell脚本分析,可以在一小时内给出准确的答案.从近两年的网络安全发展态势来看,发现并利用类似通用型软件漏洞的攻击有日益增长的趋势,今年三月份出的DedeCMS注入漏洞,七月份出的Discuz 7.2注入漏洞都给众多校园网站带来了严重影响,而这些受影响网站都可以通过海量日志数据分析快速反查得到.使用Python脚本结合对应的漏洞POC对这些可能受影响网站进行验证,可以迅速掌握究竟有多少站点中招.
对于APT(Advanced Persistent Threat,高级持续性威胁)类型的攻击,很难立即响应并处理,IDS、Firewall、WAF(Web应用防火墙)等常规安全防御体系面对0Day攻击可能都是无效的.这类攻击往往持续数月乃至几年,只有掌握全局且长期的海量日志并拥有关联分析能力,才可能从蛛丝马迹中追踪各类APT攻击和0Day利用行为,进行取证分析.
分析Web日志中的GET请求记录,Referer字段会显示用户访问流量从何处而转来,User-Agent字段会显示用户的操作系统和终端浏览器类型,SrcIP字段会显示用户来源(校内/校外/地区/国家),如果是由搜索引擎跳转而来,抽取Referer信息中查询字段并对应UTF-8/GB2312解码,就可以分析出访问者远端使用的搜索引擎以及输入的关键词.这些长期统计分析信息可用于校园网站的用户行为分析和针对性页面优化,分析用户使用的搜索关键词在安全领域也有着特殊的意义.日志里的HTTP返回状态码如果是4xx或5xx而不是200,也预示着服务器出现了某些异常情况.
对于网站后门(WebShell),其Web日志某些字段(path或Referer)中的特征比较明显,可以通过一系列异常挖掘算法及时发现.关联性日志分析可以得出这些木马是在什么时间,哪个源IP放进来的,网站哪些目录下还可能存在类似后门导致被利用,攻击者先后入侵了哪些网站,都在一系列深入分析之后得到了解答.很多服务器被入侵之后,攻击者会故意抹去其访问痕迹,不过基于网络流量的日志仍然忠实记录了当时发生的每个细节.一次成功的入侵背后往往伴随着多次的信息搜集过程,众多不成功的扫描和攻击尝试会在一系列日志数据记录中得到印证.很多时候人们的确无法实时阻断所有攻击,但事后的安全应急响应工作仍然非常有价值,亡羊补牢,为时未晚.如果没有足够的日志数据积累,缺乏快速的分析平台,对发生的历史攻击就毫无知晓,更难避免其反复出现.
5 未来展望和结束语
校园网站日志系统只是基于Hadoop平台的一个典型应用,在大数据平台上还可以提供校园云存储、教学科研基础支撑等更多的校园级应用.高校信息化部门要深入研究大数据平台的自动化灵活部署,做好后期运维保障,并且充分理解最终应用需求,才能用较少的投入来获得最大的收益,挖掘出大数据中的信息金矿.
对大数据的搜集、分析、可视化是循序渐进的过程,前两者在校园网站日志系统的建设过程中已经做了一系列基础研究,可视化输出通过图形的形式表现信息的内在规律及其传递、表达的过程,是诠释复杂数据的重要手段和途径.可视化的具体方法和形式多种多样,目的是使不具备专业背景的用户也可以直观理解原始数据中隐藏的规律和潜在关系,高校在这个方向上还需要做出更多的努力和进一步探索.
[1] 构建大型云计算平台分布式技术的实践[EB/OL].[2014-07-18].http://www.infoq.com/cn/news/2014/07/aliyun-distributed.
[2] Linxinsnow.大数据安全分析:我们从日志中得到的(一)[EB/OL].[2014-07-13].http://www.freebuf.com/articles/web/25613.html.
[3] BigHy.腾讯安全零距离之大眼——大型网络流量分析系统[EB/OL].[2014-12-06].http://security.tencent.com/index.php/blog/msg/33.
[4] 大数据Web日志分析用Hadoop统计KPI指标实例[EB/OL].[2014-02-08].http://www.aboutyun.com/thread-6832-1-1.html.
[5] Flume User Guide[EB/OL].[2014-10-317].http://flume.apache.org/FlumeUserGuide.html.
[6] CDH5.x Documentation[EB/OL].[2014-10-31].http://www.cloudera.com/content/support/en/documentation/cdh5-documentation/cdh5-documentation-v5-latest.html.
