基于协同迭代及动态词库扩展的文本情感倾向分类算法
2015-12-02郑皎凌舒红平
文 俊, 郑皎凌, 舒红平
(成都信息工程大学软件工程学院,四川成都610225)
0 引言
伴随计算机技术和互联网技术的蓬勃发展,网络已经无可替代的成为人们发布信息和获取信息的重要场所,可以说人们的工作、学习以及生活已经到了完全离不开互联网的程度。尤其是随着Web2.0技术的兴起,人与人之间通过网络交互更加频繁了,不仅仅可以浏览信息,获取信息,还可以很轻松简便的发布信息。用户通过网络相互之间进行交流的方式,已成为互联网的一种最流行的旋律,而这种形势已经给互联网带来了海量的数据信息,挖掘出隐藏在这些海量数据中的有价值的信息是具有十分重要的社会意义和商业意义。但是面对如此庞大的数据信息,仅依靠人工对日益增长的海量数据的采集、处理、分析并预测显然是不切实际的,因此,利用先进技术和工具来获取其中有价值的信息成为人们的迫切需要。文本情感倾向分析研究正是在此背景下应运而生的,具有重要的研究意义。所谓情感分析[1-4],就是确定说话人或作者对某个特定主题的态度。其中,态度可以是他们的判断或者评估,他们(演说、写作时)的情绪状态,或者有意(向受众)传递的情感信息,在现有的网络社交平台里,如微博、论坛、Twitter、评论社区等,都含有大量的类似的信息数据。因此,情感分析的一个重要问题就是情感倾向性的判断,即判断作者的观点是褒义的、积极的,还是贬义的、消极的,这类问题也被称为情感分类。通过实验发现,利用基于情感词库的文本情感倾向分类方法对文本情感倾向进行分类时,可能存在2个影响分类准确率的因素:(1)情感词库不够丰富。目前已有的情感词典(Hownet情感词语集、台湾大学NTUSD、中文情感词汇本体库等)涉及的领域行业比较广泛,对某一领域行业来说,针对性不强;又或者说在跨领域应用[5]时,泛化能力不够好。(2)切词工具不够准确。切词工具如果不够准确,会导致情感词提取数量减少,包含情感信息量小。基于以上两个原因的考虑,我们试图寻找其他更行之有效的方法,一种既能对文本情感倾向进行分类并且还能扩展词库的算法。在进行多次数据统计并实验分析后,发现某些单词出现在某些类型文章中的频率是不规则的,具有一定的倾向性并且其词性分布集中,甚至可以说某些词基本只出现在正面文章中或负面文章中。比如“腐败”一词,出现在正面情感文章中的概率远小于出现在负面情感文章中的概率,根据这一规律,设计了一种基于协同迭代及动态词库扩展的文本情感倾向分类算法CACIDLE。
1 相关工作
文本倾向性分析研究始于国外,文本倾向性分析技术就是分析文本作者对某个事物或问题得立场、态度。是一个涵盖了文本挖掘、信息检索、机器学习、自然语言处理、概率统计学、语料库语言学等的多学科综合研究领域。在文本倾向性分析研究方面,从事该领域的国外科研工作者提出了很多经典且有效的技术方法,如支持向量机 SVM(support vector machine)[6],Boosting[7],kNN(k-nearest neighbors)[8]算法。在文献[9],Hatzivassiloglown和 Makeown(1997)针对形容词的语义倾向性展开研究,算法利用词汇之间的连词(and,or,but,either-or和 neither-nor等)训练生成词汇间的同义或反义倾向的连接图,然后用聚类的方法将词汇聚成褒义和贬义两类,来预测具有主观性的形容词的倾向,其准确率达到了78.08%。Turney和Littham(2003)通过计算倾向性基准词对与目标词汇间相似度的方法识别词汇语义倾向性。选择褒义倾向比较强烈的词汇,计算待定词与每个基准词的SO-PMI值来判定词汇的倾向性,其准确率在包含形容词、副词、名词、动词的完整测试集上达到82.18%。相对于国外,中国在这方面的研究起步较晚,再加之中英文语言结构及中西方文化的差异,中文在表达个人感情方面比英文更为复杂、多样化,给中文文本倾向性分析研究增加很大的难度。不过,随着文本倾向性分析研究越来越受到专家和学者的关注,在该方向的研究也取得了不错的成果。王建会等[10]提出一种基于互依赖和等效半径、易更新的分类算法SECTILE,该算法计算复杂度低,扩展性能好,分类速度快,适用于大规模场合,有利于对大规模信息样本进行实时在线的自动分类,提高查全率和查准率。叶强等[11]人在N-POS语言模型的基础上利用卡方(CHI-square)统计方法提取中文主观文本词类组合模式,建立中文双词主观情感词类组合模式2-POS模型来自动地判断中文语句的主观性程度。实验表明采用2-POS模型的分类器对主观句的查准率和查全率接近目前英文同类研究的结果。潘宇等[12]提出一种基于语义极性分析的餐馆评论挖掘方法,算法选取餐馆相关信息作为特征,结合中文句子语法结构并以句子为单位来分析评论句的语义极性和极性强度,其分类准确率优于Baseline方法。杜伟夫等[13]提出一种新的情感词汇语义倾向计算方法,算法利用多种词语相似度构建词语无向图,再利用以“最小切分”为目标的目标函数对该图进行划分,并利用模拟退火算法进行求解。李寿山等[14]人具体研究4种不同的分类方法在中文情感分类上的应用,并且采用一种基于Stacking的组合分类方法,用以组合不同的分类方法。实验结果表明组合方法在所有领域都能够获得比最好基分类方法更好的分类效果。周杰等[15]人选取不同的特征集、特征维度、权重计算方法和词性等因素对网络新闻评论进行分类测试,并对实验结果进行分析比较。陶富民等[16]人构建了一个面向话题的新闻评论的情感特征提取框架,通过对那些热门话题构造对应的情感特征表来达到改善情感分析的效果。
2 倾向特征挖掘
2.1 句子划分
一篇普通的文本由一个或多个段落组成,每个段落由一句或多个句子组成,每一句子有多个词组成。就文中算法以句子级为计算文本情感倾向性的最小单位,需要将文本内容划分为句子集合。由于文本内容可能存在标点符号使用不规范的现象,因此将“。”,“.”,“。。”,“?”,“!”,“!!”,“!!!”,“~”,“……”作为一个句子的边界符号。
2.2 特征词性集合选取
目前,中科院发布的“汉语文本词性标注标记集”文档中,中文各类词性大概总计有近百余种。通过多次实验的测试,发现具有明显倾向性的词,其词性主要集中分布在以下特征词性集合中,将以下词性集合选取作为特征词提取的范围,内容如表1所示。

表1 特征词性集合信息
2.3 特征倾向词库构建
定义1 特征词倾向频率FR,将特征词的文本情感倾向度的一个评判标准定义为特征词倾向频率。特征词倾向频率FR反映了特征词出现在某一情感类型文本的可能性。特征词倾向频率FR的计算公式为
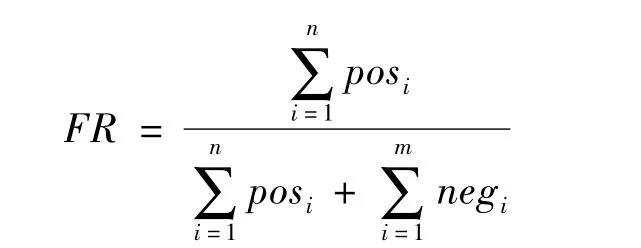
其中,posi表示特征词在第i篇正面文本中的出现的次数;negi表示特征词在第i篇负面文本中的出现的次数。
定义2 特征词倾向差DIFF,将特征词的文本情感倾向度的另一个评判标准定义为特征词特征词倾向差值。特征词倾向差值DIFF同样反映了特征词出现在某一情感类型文本的可能性。特征词倾向差值DIFF的计算公式为

其中,posi表示特征词在第i篇正面文本中的出现的次数;negi表示特征词在第i篇负面文本中的出现的次数。
获取等量的正面情感和负面情感两类文本作为语料,对照特征词性集合(表1)提取特征词,并按特征词总出现次数降序排序,计算特征词的文本情感倾向度的两个评判标准(FR和DIFF),并按特征词分类过程classifyWord(word)将特征词分类,分别构建等量的正面特征倾向词库posLib和负面特征倾向词库negLib。特征词分类过程描述如下:
算法1 classifyWord(word)
if(FR≥wordThd-pos& & DIFF≥diffThd)
将word从其他词库移除并加入posLib;return 1;
else if(FR≤wordThd-neg&&(-DIFF)≥diff-Thd)
将word从其他词库移除并加入negLib;return-1;
else
将word从其他词库移除并加入medLib;return 0;
其中,wordThd-pos为正面特征词阈值,wordThd-neg为负面特征词阈值,diffThd为差值阈值,中性特征倾向词库medLib。
2.4 简单示例
为增加对倾向特征挖掘流程的理解,利用下面的例子来介绍。
从正负5篇文章提取的特征词信息,如表2所示。

表2 文本特征信息
统计文本中所有特征词的信息,如正负面词频、倾向频率FR、倾向差值DIFF,并按总词库排序,详细信息如表3所示。

表3 特征词信息
从表3可以看出,“道德”和“抢救”的FR值都为0,然而DIFF值却相差5;“安全”和“抢救”的DIFF值都为-1,然而FR值却相差0.6;这说明单凭FR值或DIFF值来作为特征词的分类标准可能会出现很大的误差。所以将FR和DIFF相结合作共同作为为特征词的分类标准更为合适,正如分词算法1中所示。
3 CACIDLE算法描述与实现
本算法的核心思想来源于基于统计的分析方法,分类模式类似于基于情感词典的语义计算分析方法。主要由文本协同迭代分类和动态词库扩展两个部分构成。
3.1 文本协同迭代分类
文中算法以句子为最小单位,首先要通过特征句子分类过程classifySentence(sentence)将文本中的句子分类,再通过文本分类过程classifyText(text)将文本分类,再将文本中出现的所有新特征词去重过滤,按照特征词分类过程classifyWord(word)来重构特征倾向词库。经过多次这样迭代的过程collaClassify(textList),当分类的准确度连续3次变化微小或者中性词库medLib中的词连续3次不变化,即认为达到平衡状态,则完成整个分类流程。具体几个过程定义如下:

其中,sentenceThd为句子阈值,attributeList为表1的特征词性集合。
算法3 classifyText(text)


其中,textList为待分类的文本集合,balanceState为平衡状态布尔值。
3.2 动态词库扩展
由于扩展词库是基于某一次文本分类,对于某一特定的特征词,在不同容量的分类文本的情况下,按照同一特征词分类规则去分类此特征词,结果可能不一致。毫无疑问,对于某一特定的特征词,其正负倾向词频值随文本容量的增加而增加。然而,其正负倾向词频值的增长率不一定随文本容量的变大而增加,有可能保持不变甚至减小。比如,某些特征词的正负词频值平均趋势如图1所示。
观察图1可知当文本容量在250~300的某一点k时,正负面词频曲线的斜率明显改变了。当文本容量大于k值时,负面词频曲线的斜率变大,而正面词频曲线的斜率在减小。这说明k点可作为特征词的正负面词频值的区分点。为了确保特征基础词库中的每个新特征词都具有较明显的正负文本倾向性,取文本容量在250~300之间的多组正负词频对比值求平均值,将此平均值作为特征词阈值来分类特征词,以达到扩展特征词库的目的。为了保证下一次文本分类的准确性,当前文本分类结束后取等量且适宜(不大于200)的特征词加入相应的特征倾向词库。
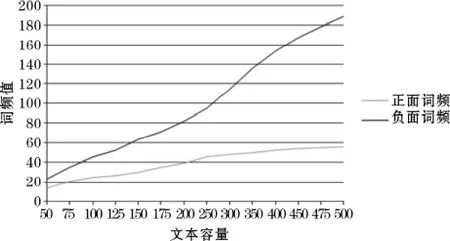
图1 正负面词频值平均趋势
3.3 CACIDLE算法实现
结合2.1和2.2两个过程,CACIDLE算法的整个过程如下:
算法5 CACIDLE
输入:文本阈值textThd,句子阈值 sentenceThd,正面特征词阈值wordThd-pos,负面特征词阈值wordThd-neg,差值阈值 diffThd,词库扩展阈值wordSizeThd。
输出:文本分类结果及新特征倾向词库.
过程:
设balanceState=false;
while(!balanceState)
balanceState=collaClassify(textList);
将文本中的特征词FR与DIFF按排序并取前wordSizeThd个词分别加入特征倾向词库;
输出结果;
分类结束。
4 实验结果及分析
4.1 实验数据
利用网络爬虫技术,从一些有名的网站模块(如:凤凰网的暖新闻模块http://news.ifeng.com)爬取具有情感倾向的新闻文章文本,再经过人工筛选过滤并进行正面和负面标注,将其作为实验的文本数据集。数据集的具体信息如表4所示。

表4 文本数据集具体信息
利用中科院中文切词工具ICTCLAS将文本数据集切词并进行词性标注,选取其中1000篇文本(正面倾向和负面倾向各500篇)作为训练数据集来构建基础种子词库,最终提取了各500个特征词到正面倾向词库和负面倾向词库。剩下的1000篇文本作为测试数据集。
4.2 实验评价
使用的精确度(accuracy)为文本情感倾向的判断标准,其基本定义公式为
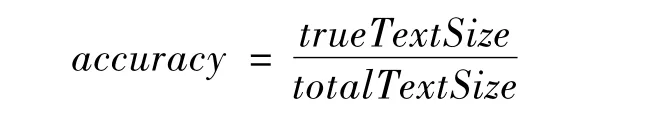
其中,trueTextSize表示分类正确的文本数量,totalTextSize为总测试文档数量。
4.3 总体结果比较
将测试数据集分别在K最近邻、支持向量机SVM以及本文分类方法做了不同文本容量的多次十字交叉测试实验,表5显示了各方法的文本分类实验的平均结果。
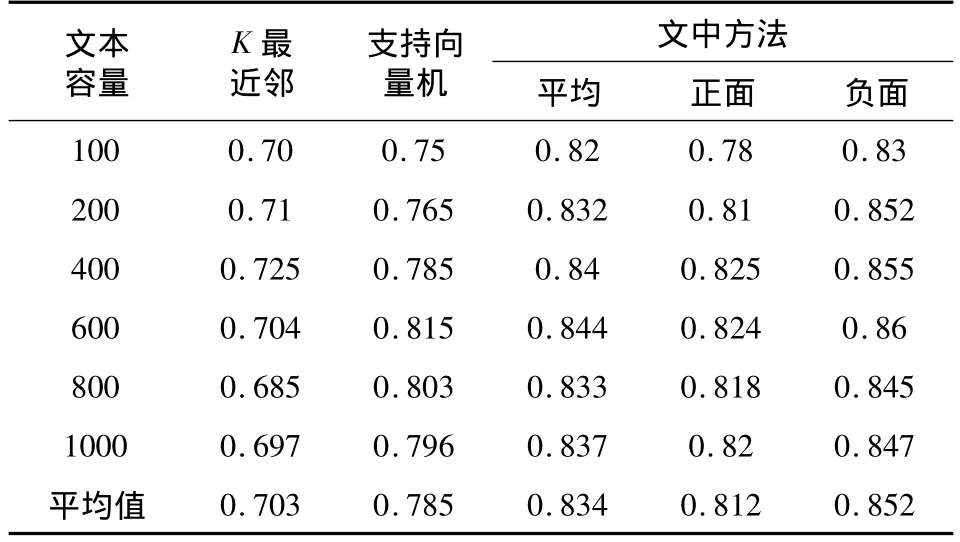
表5 各方法实验平均结果
从表5可以看出,在多次不同文本测试数据集的实验平均结果中,文中分类方法都优于其他两种分类方法。从结果数据上来对比,文中分类方法的平均精确度为83.4%,比支持向量机SVM分类方法所得的平均精确度78.5%高出4.9%,比K最近邻分类方法所得的平均精确度70.3%更高出13.1%,由此说明文中分类方法能提高中长文本的情感倾向分类的效果。
4.4 算法收敛性
算法是分类文本和特征词两者相互训练的迭代过程,由分类文本提取更多新特征词扩充基础种子词库,反过来,由更大容量的基础种子词库将更多的待分类文本进行更精确的分类。在进行迭代的过程中,将实验结果趋于稳定的状态作为迭代的结束条件,即算法收敛。通过多次实验测试了算法的收敛性,图2为表示本算法在不同容量的测试文本数据集的情况下,算法精度随迭代次数的增加而变化的曲线。从图2可以看出,迭代次数在10次左右时曲线就趋于稳定,能获得一个比较优良的精确度。

图2 算法收敛性
5 结束语
提出基于协同迭代及动态词库扩展的文本情感倾向分类算法CACIDLE,通过实验结果证明了是一种有效的文本情感分类的方法,分类效果也比较令人满意的,而且经过每一次文本分类,特征倾向词库的特征词在不断的丰富,这样更有利于提高文本的分类效果和算法的时间效率(迭代次数减少)。当然,算法CACIDLE还有待提高的方面,如特征词性集合的选取、扩展词库方法的优化以及分类效果的提高,这些都是接下来要进一步研究的重点。
[1] Sholom M Weiss,Nitin Indurkhya,Tong Zhang.预测性文本挖掘基础[M].赵仲孟,候迪,译.西安:西安交通大学出版社,2010.
[2] Liu B.Sentiment Analysis[C].Emerging Trends and Applications in Computer Science(ICETACS),2013 1st International Conference on-IEEE,2013:i.
[3] Singh V,Dubey S K.Opinion mining and analysis:A literature review[C].Confluence The Next Generation Information Technology Summit(Confluence),2014 5th International Conference IEEE,2014:232-239.
[4] 魏韦华,向阳,陈千.中文文本情感分析综述[J].计算机应用,2011,31(12).
[5] 吴琼,谭松波,徐洪波,等.基于随机游走模型的跨领域倾向性分析研究[J].计算机研究与发展,2010,47(12):2123-1231.
[6] C J C Burges.A tutorial on support vector machines for pattern recognition[J].Data Mining and Knowledge Discovery,1988,2(2):955-974.
[7] R Schapire,Y Singer.BoosTexter:A booting-based system for text categorization[J].Machine Learning,2000,39(2/3):135-168.
[8] Y Dasarathy B V.Minimal consistent set(MCS)identification for optimal nearnest neighbor decision system terms design[J].IEEE Trans.on System Man Cybern,1944,24(3):511-517.
[9] 翁彧.网络话题中的web文本挖掘技术[M].北京:中央名族大学出版社,2010.
[10] 王建会,王洪伟,申展,等.一种实用高效的文本分类算法[J].计算机研究与发展,2005,42(1):85-93.
[11] 叶强,张紫琼,罗振雄.面向互联网评论情感分析的中文主观性自动判别方法研究[J].信息系统学报,2007,1(1):79-91.
[12] 潘宇,林鸿飞.基于语义极性分析的餐馆评论挖掘[J]. 计算机工程,2008,34(17):1000-3428.
[13] 杜伟夫,谭松波,云晓春,等.一种新的情感词汇语义倾向计算方法[J].计算机研究与发展,2009,46(10):1713-1720.
[14] 李寿山,黄居仁.基于Stacking组合分类方法的中文情感分类研究[J].中文信息学报,2010,24(5):56-61.
[15] 周杰,林琛,李弼程.基于机器学习的网络新闻评论情感分类研究[J].计算机应用,2010,30(4):1011-1014.
[16] 陶富民,高军,王腾蛟,等.面向话题的新闻评论的情感特[J].中文信息学报,2010,24(3):37-43.
