基于自适应变异粒子群优化的SVM在混合气体分析中的应用
2015-11-29陈红岩刘文贞李志彬
曲 健,陈红岩,刘文贞,张 兵,李志彬
(中国计量学院机电工程学院,杭州310018)
基于自适应变异粒子群优化的SVM在混合气体分析中的应用
曲 健,陈红岩*,刘文贞,张 兵,李志彬
(中国计量学院机电工程学院,杭州310018)
针对混合气体定量分析中,支持向量机建模的参数难以确定、红外光谱数据计算量过大以及气体间交叉干扰等问题。提出了一种自适应变异粒子群优化的支持向量机方法,用于建立基于红外光谱的多组分混合气体定量分析模型。混合气体主要由浓度范围在0.5%~8%的CO、3.6%~12.5%的CO2及200×10-6~3270×10-6的C3H8三种组分气体组成。利用粒子群优化算法对支持向量机建模中的参数进行优化选择,并与遗传算法优化的支持向量机作对比。实验表明,采用此方法建模所用时间为39.524 s,遗传算法为26.272 s;针对CO2独立建模的预测结果,粒子群优化算法均方差为0.000 123 758,遗传算法均方差为2.14952。在建模时间略高的情况下,粒子群优化算法预测结果均方差明显低于遗传算法。
传感器应用;支持向量机;粒子群优化;遗传算法;定量分析
机动车尾气排放已经成为污染环境的重要因素,尾气排放的气体主要有CO、NO、CO2、HC化合物等。在混合气体定量分析方法中,主要采用红外光谱吸收法。对光谱的分析方法主要有棱镜和光栅光谱仪,但它属于单通道测量,不能同时进行多通道的测量;傅里叶变换红外光谱仪,可进行多通道的测量,光通量高,仪器灵敏度高,波数值的精确度高,但两种光谱分析仪都不便于携带,不能进行随车式检测。本实验采用的红外吸收法,可以应用于随车式汽车尾气传感器中,对车辆尾气排放进行动态实时检测。由于组分气体间交叉吸收干扰、传感器选择性能不一、温度的变化以及供电电压的波动等因素,导致测量的精度很低,无法对汽车尾气排放进行有效的检测和监督,需要后续的数据处理。
提高混合气体测量精度的方法主要有人工神经网络[1-2](Artificial Neural Network,ANN)方法和支持向量机[3-5](Support Vector Machine,SVM)方法等。其中,耿志广[1]等人将人工神经网络与气体传感器阵列技术相结合,克服了传感器阵列在混合气体检测中的交叉敏感现象;金翠云[6]等利用粒子群优化算法对支持向量机进行参数优化,并应用于电子鼻气体定量分析中,得到了最优参数组合,进一步提高了预测精度;李玉军[7]等人将粒子群优化与最小支持二乘向量机相结合,建立混合气体定量分析模型,并与遍历优化算法相比较,寻优时间节省40倍以上,预测结果误差水平相当;Manouchehrian Amin[8]等运用基于遗传算法寻优方法的支持向量机,建立回归模型,预测岩石的强度和可变性属性。神经网络算法的收敛性及预测的准确度受初始权值和阀值的选择影响很大,因此输出具有不一致性,容易陷入局部极小值。而支持向量机算法可以有效地避免上述问题。
本文针对红外光谱特征吸收谱线重叠严重的多组分混合气体,以SVM为基础对浓度范围在0.5%~8%的CO、3.6%~12.5%的CO2及200×10-6~3 270×10-6的C3H83种组分气体组成的20组混合气体样本进行独立建模定量分析,选取其中15组样本作为训练集,建立SVM回归校正模型,并对训练集进行预测分析,以检测模型的准确度;选择剩余的5组气体样本作为验证集,验证模型的预测精度和水平。在SVM参数的优选问题上,提出了自适应变异粒子群优化算法。并与基于遗传算法的参数优选相比较。
1 SVM回归校正模型理论
SVM[9]算法是根据结构风险最小化原则[10]设计的一种统计学习理论,具有模型推广性能好、小样本学习能力强以及高维数据处理能力强等优点。SVM回归校正模型,就是利用SVM核函数,将混合气体红外光谱输入数据利用非线性映射Φ,映射到高维空间,然后在高维空间进行回归分析,建立红外光谱数据与待测组分气体浓度的回归校正模型。
将已知组分浓度的混合气体样本红外光谱数据作为训练集T={(x1,y1),…,(xN,yN)}∈(Rn×R)N,其中xi∈Rn为第i个数据样本,xi=(x1,x2,…,xL)为在扫描波长范围内L个光谱数据,yi∈Rn为对应的混合气体的组分浓度值,i=1,2,…N。在高维空间需要求解的光谱数据样本与混合气体组分浓度的回归函数 f(xi)可表示为如下形式:
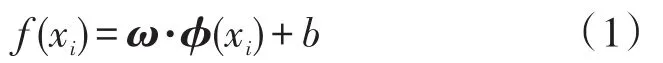
式中:ω·ϕ(xi)为向量ω与ϕ(xi)的内积;ω为回归系数,b为阀值。
在此引入松弛变量ξ,ξ*≥0来求解ω与b,,根据SRM准则,将式(1)转换为凸二次规划问题:
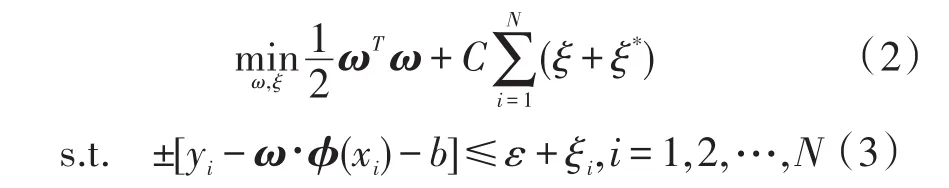
式中,C为惩罚参数,ε为回归函数结果与待测气体样本的误差精度。
引入Lagrange函数求解式(2),通过核函数k(xi,xj)将高维空间的内积运算转换在原二维空间计算,有:
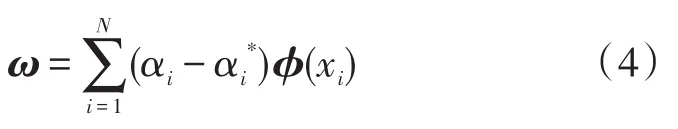
得到的SVM回归校正模型的回归函数为:
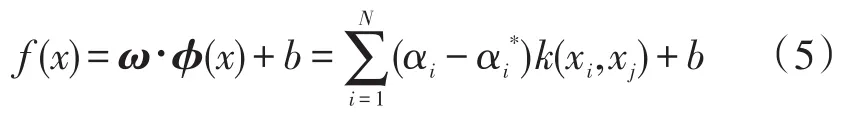
式中,若αi不为零或者αi*不为零,表示此样本即为支持向量。
常用的核函数有线性核函数、多项式核函数、径向基(RBF)核函数、Sigmoid核函数。由于Gauss函数能较好的模拟光谱信号,所以本文选用RBF核函数。其表达式如下:

式中,参数g为gamma参数函数设置(若k为属性的数目,则g默认为1/k)。
2 自适应变异粒子群优化算法
粒子群优化算法[11-12](Particle Swarm Optimization,PSO)是计算智能领域,除蚁群算法、鱼群算法之外的一种群体智能的优化算法。其基本思想是通过群里中个体之间的信息传递及信息共享来寻找最优解。
假设在一个D维的空间中,有n个粒子组成的种群X=(X1,X2,…,Xn),其中Xi=[xi1,xi2…,xiD]T为第i个粒子在D维搜索空间的位置,亦代表问题的一个潜在解。根据目标函数可以计算出每个粒子位置Xi对应的适应度值。第i个粒子的速度为Vi= [Vi1,Vi2…,ViD]T,其个体极值为 Pi=[Pi1,Pi2…,PiD]T,种群的全局极值为Pg=[Pg1,Pg2…,PgD]T。
在每一次迭代过程中,粒子通过个体极值和全局极值更新自己的速度和位置,更新公式为:
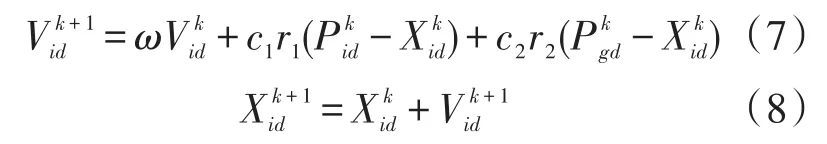
式中∶ω为惯性权重因子,其值非负,值的大小影响整体的寻优能力;i=1,2,…,n,n为群体中粒子总数;d=1,2,…,D,表示维数;k为当前迭代次数;Vid为粒子速度;Xid为粒子位置;c1和c2为加速度因子,通常在0~2之间取值,本实验中取c1=1.5,c2=1.7;r1和r2为分布在[0-1]之间的随机数。
粒子群优化算法收敛快,但存在着容易早熟收敛、搜索精度较低、后期迭代效率不高等缺点。因此,本文提出了自适应变异[13-14]的粒子群优化算法,指通过一定的准则和判定条件对相应的粒子采取变异操作,产生新的粒子,引导种群向最优解方向收敛。自适应变异操作拓展了在迭代中不断缩小的种群搜索空间,使粒子可以跳出之前搜索到的最优值位置,在更大的空间展开搜索,同时保持了种群的多样性,提高了算法寻找到最优质的可能性。其基本思想就是在粒子每次更新之后,以一定概率重新初始化粒子。
3 实验与分析
本实验采用不分光红外法(NDIR)对含CO、CO2和C3H8化合物的混合气体浓度进行检测。红外光源采用HawkEye公司生产的为快速电调制提供完美解决方案的IR55红外光源,输出光谱范围为中红外区2 μm~20 μm,而所需测量的CO、CO2、HC化合物的吸收光谱峰值主要在中红外区3 μm~5 μm区域,所以IR55完全满足红外吸收法对混合气体的测量要求,可以保证在3 μm~5 μm区域有足够的光能量输出。通过MCU产生的脉冲信号对红外光源进行调制,使其产生3 μm~5 μm范围的连续红外光,通过一定长度的气室内,气室中充有待测浓度的多组分混合气体。由于混合气体中各组分对红外线波段中特征波长红外线能量的吸收,特定波长范围的光源通过气体后,在相应气体的吸收谱线处会发生光强的衰减,红外线的能量将减少。探测器的4个通道分别为CO检测通道、CO2检测通道、HC化合物检测通道和参考通道。参考通道用来获得其他波长的光无吸收时的光能量,然后对各光路的输出进行作比运算,减少由于光源的发射功率起伏和探测器灵敏度不稳定引起的测量误差,使得到的计算结果与光源发射和探测器无关,只与气体的浓度和气室的长度有关。每个通道检测对应气体吸收后剩余光强度并转化为3组不同的电信号,与参考通道的输出作比后,经放大滤波作为模型的输入。整个测试系统的原理如图1所示。

图1 NDIR测试系统原理图
图1中,所选探测器是PerkinElmer公司生产的TPS4339热电堆探测器,是基于热电偶测温原理,用于红外光探测的2×2矩阵规则排列的4通道探测器,如图2所示。由许多热电偶串联而成,提高了探测器对红外辐射产生温度变化的响应度;各个输出的热电势叠加,因此热电堆探测器所产生的热电势远远大于普通的热电偶探测器;在探测节点处增加了光接收面的面积,可更加有效的吸收红外光;4个热电堆探测器分别拥有独立的密封了不同红外滤光片的透射窗口,相互之间没有信号干扰,通过在每个热电堆探测器前面的窗口处安装不同的红外滤光片,最多可同时测量四种气体。要同时测量的3种气体分别为:CO、CO2和HC化合物,通过气体吸收光谱分析,选择气体通道的滤光片滤波范围分别为:4.66 μm+0.015 nm、4.43 μm+40 nm、3.46 μm+50 nm;参考通道滤波范围:3.93 μm+50 nm。这些特点使得探测器应用于气体检测的信号处理能力明显提高,分辨率显著增强,满足气体检测的需要。

图2 TPS4339顶部视图
本实验以2×2探测器对含CO、CO2和C3H8的三种混合气体进行定量分析。所测混合气体为0.5%~8%的CO,3.6%~12.5%的CO2,和200×10-6~3 270×10-6的C3H8。为了便于数据处理,对标准浓度进行归一化处理,便是模型的期望输出。为提高检测精度,针对不同气体采用独立建模的方法。选择其中的15组样本为训练集,建立SVM模型并查看模型在训练集上的回归效果;选择剩余的5组样本为测试集,用建立好的模型对测试集进行回归预测,并验证SVM模型的预测精度和水平(详情见表3)。模型的建立需要对惩罚参数c(选取范围0~100)和RBF核参数g(选取范围0~1 000)进行合理的优化选择,本文采用自适应变异粒子群优化算法进行参数寻优,具体的优化流程如图3所示。
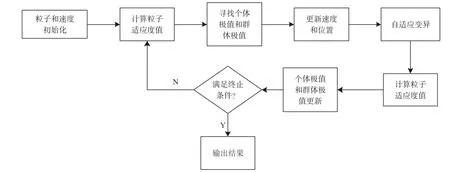
图3 自适应变异PSO参数优化流程图
优化流程为:①选取20组实验数据中的15组做训练样本,剩余的5组做测试样本;②初始化参数c和g,建立SVM回归模型;③由于每个粒子群只能优化一个参数,因此设置粒子群的维数为2,每维粒子群中粒子的数目选取10~30为宜,本实验选择20。迭代次数为200代。根据两个参数的优化范围对粒子群的初始位置和速度进行初始化;④设置适应度函数为模型预测结果的均方差;⑤将粒子适应度值进行横向或纵向比较后获得当前群体的最优位置。根据式(7)及式(8)更新粒子的速度和位置;⑥优化流程的结束条件为模型预测结果均方差为0或者迭代次数达到设定值。未达到结束条件则转第4步。
选定好最优参数组合(c,g)后,对训练集进行训练,建立SVM回归模型,之后对测试集进行回归分析,得到测试集的模型预测结果。
为提高模型预测精度,本实验针对不同组分气体采用独立建模的方法,因此在应用自适应变异粒子群优化算法对SVM的参数优选的过程中,应针对不同气体分别优化,在本实验中即分别优化CO、CO2和C3H8化合物的模型参数。以CO气体分析模型参数优化为例,选取粒子群维数为2,种群数量20,粒子群优化迭代次数200代,ω取初值为0.9,终止值为0.4,根据线性递减惯性权重(Linear Decreasing Inertia Weight,LDIW)进行调整,学习因子c1=1.5,c2=1.7。根据图3参数优化流程计算,可得到如图4所示的粒子群优化误差曲线。横轴为优化代数,纵轴为适应度值,即模型测试样本计算结果的均方误差。
由图4可以看出,粒子的适应度值基本在0.01~0.05之间很小的范围内,即模型预测结果的平均绝对误差很小,在4%以下,满足尾气检测标准的要求。优化200代所用时间为10.859 8 s,最优c为39.315 2,最优g为0.178 55。将得到的最优参数组合(c,g)代入支持向量机重建传感器模型,可以得到模型在训练样本和测试样本的预测结果,如图5、图6所示。其中训练样本的测试结果均方差为5.30263×10-5,测试样本预测结果的均方差为0.000 107 812。
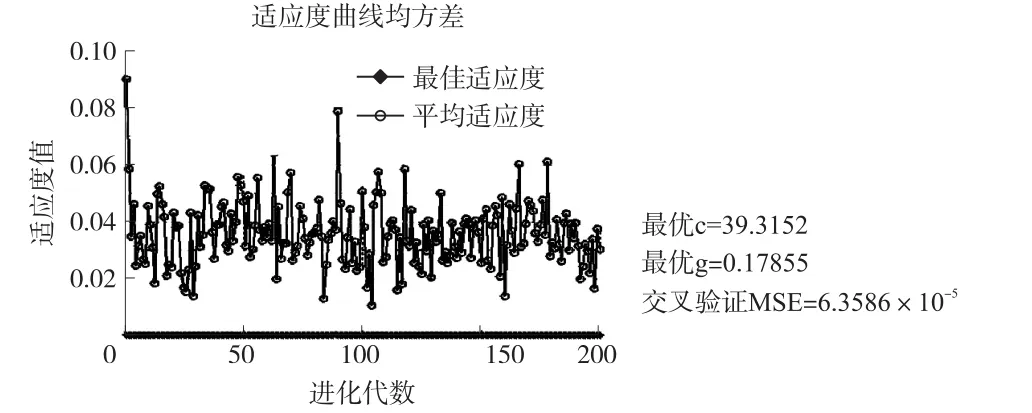
图4 自适应变异PSO参数寻优结果图(CO)
由图5可以看出利用训练集建立的模型对CO训练集本身做预测时,模型预测值和CO实际浓度值很好地吻合,误差极小;将模型应用于CO测试集的预测,如图6所示,效果明显,曲线很好地逼近真实浓度,说明本实验建立的模型预测精度高,可应用于混合气体中CO气体的回归预测。
同样的,可以得到经过自适应变异PSO优化建立其他气体模型所用时间、最优参数和训练集、测试集预测结果均方误差如表1所示。根据寻优结果建立的混合气体定量分析模型测试数据仿真结果如表3所示。若采用遗传算法[15]对SVM进行参数寻优,需要将解空间映射到编码空间,每个编码对应问题的一个潜在解。这里,将编码长度设置为3,每一位对应一个输入自变量(探测器检测的CO、CO2、C3H8),每一位的基因取值只有1和0两种情况。选取训练集样本均方差作为遗传算法的适应度函数,经过不断地迭代进化,最终找到最优解。本实验设定迭代次数200代,种群规模为20。寻优的流程如图7所示。以CO样本为例,选择同PSO优化相同的训练集,最终寻优结果曲线如图8所示。
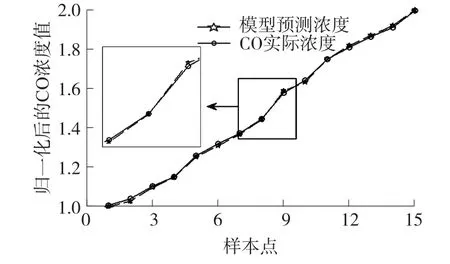
图5 CO训练集实际浓度和预测对比图
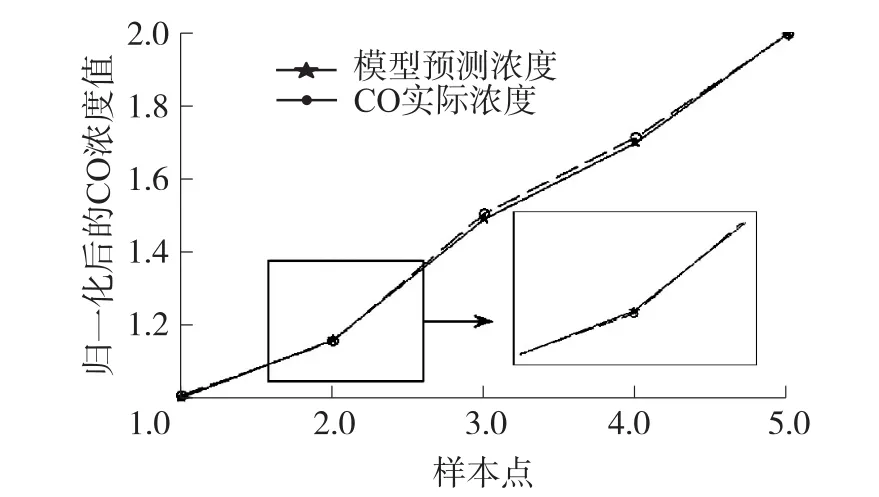
图6 CO测试集实际浓度和预测对比图

表1 PSO寻优结果对比
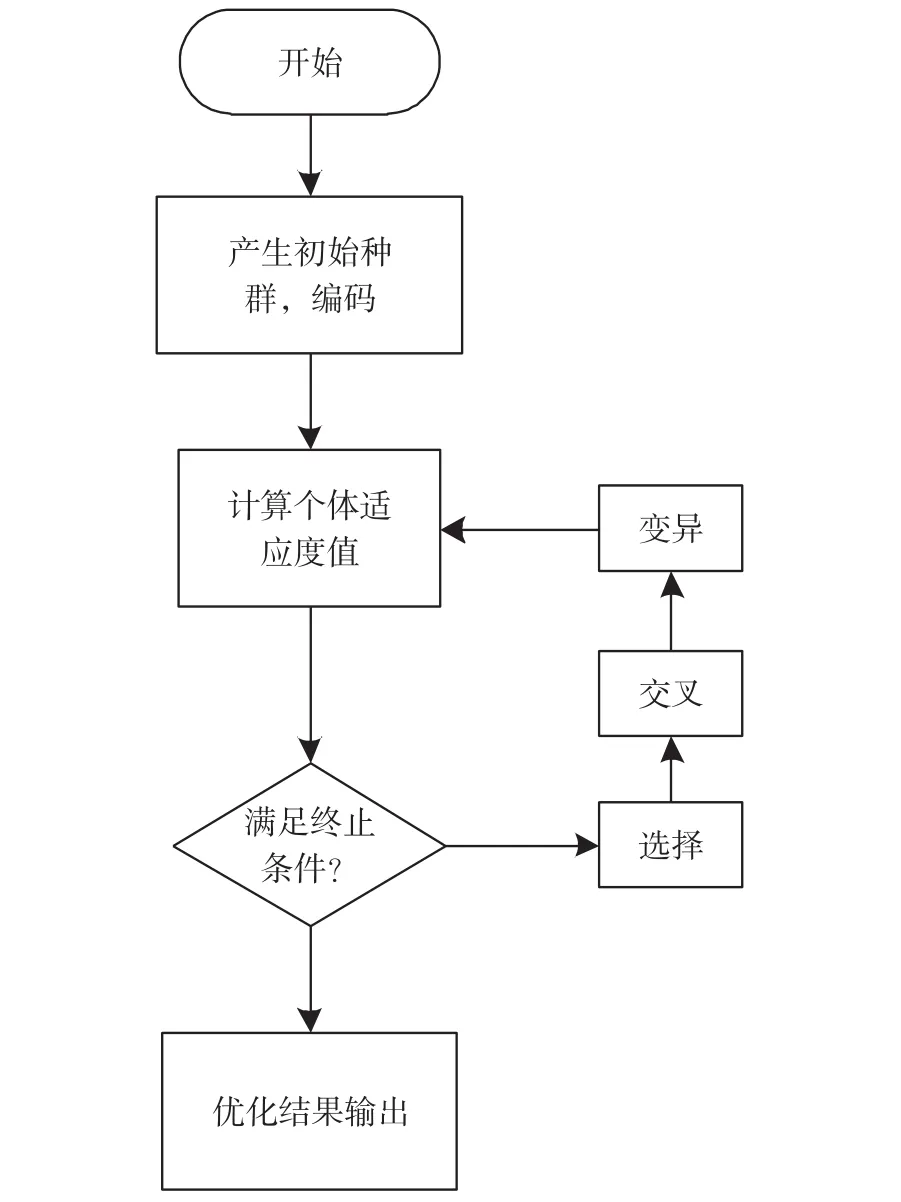
图7 遗传算法寻优流程图
由图8可以看到,CO训练集整个优化过程,适应度值变化比较大,平均适应度值最高达到0.08,最低达到0;最佳适应度值从0.03开始陡降,在大约12代趋于稳定,寻优终止于100代,所需时间约为14.644 s,最优c为1.470 3,最优g为0.222 21。将得到的最优参数组合(c,g)代入支持向量机重建传感器模型,可以得到训练样本的测试结果均方差为4.612 27×10-5,测试样本预测结果的均方差为0.000 1627 08。

图8 遗传算法参数寻优结果图(CO)
同样的,可以得到经过遗传算法优化建立其他气体模型所用时间、最优参数和训练集、测试集预测结果均方误差如表2所示。根据寻优结果建立的混合气体定量分析模型测试数据仿真结果如表3所示。

表2 遗传算法寻优结果对比
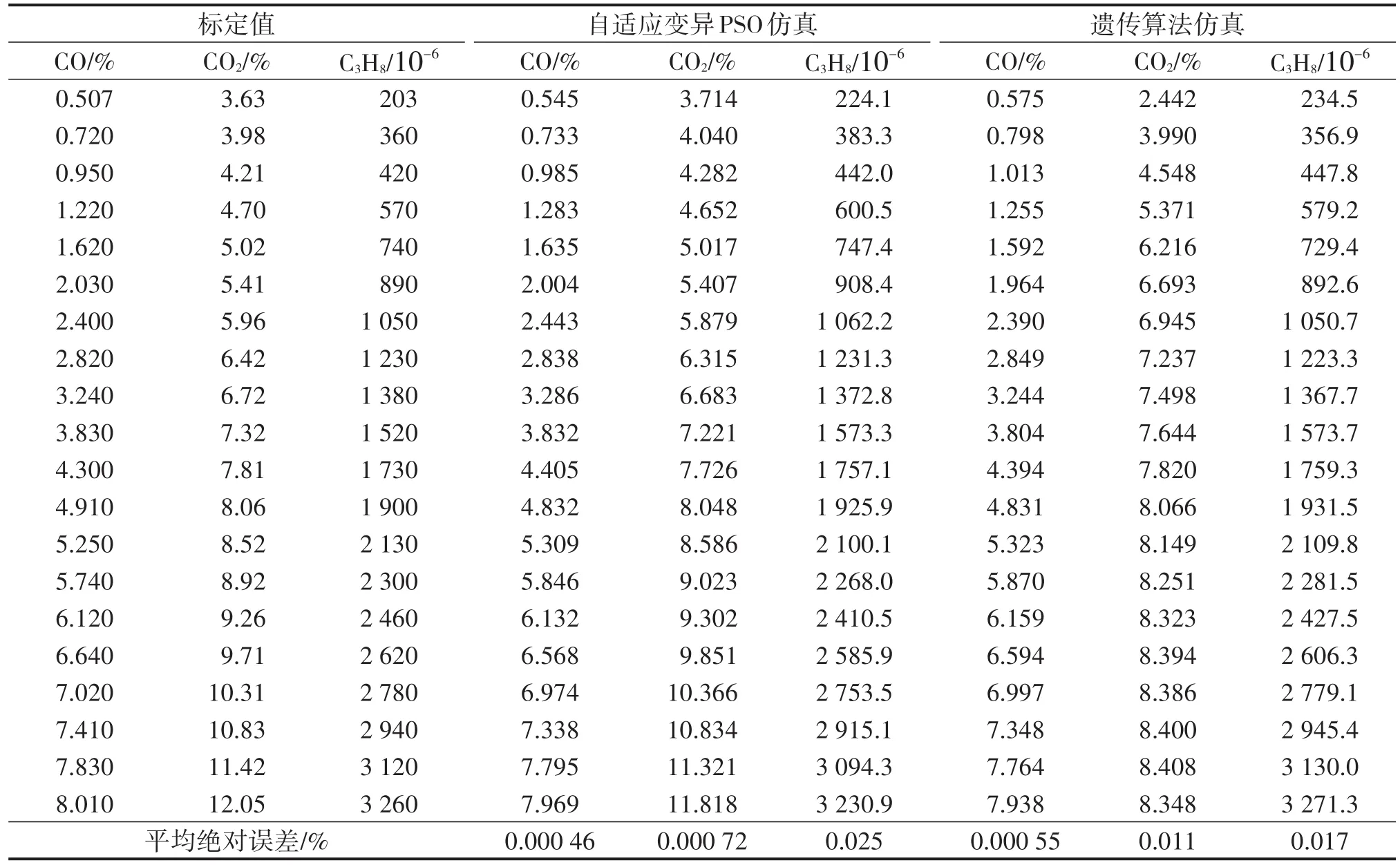
表3 仿真结果对比图
由表1~表3中的数据可以看出:两种方法建立的气体定量分析模型的测试误差水平是不相同的。遗传算法优化建立的CO2气体定量分析模型的误差很大,说明在进行混合气体独立建模的过程中,遗传算法并不能准确的预测出CO2组分。自适应变异粒子群优化建立的三组分混合气体定量分析模型可以很好地预测混合气体中各组分气体的浓度,误差很小,建模所需时间为39.524s。
因此将自适应变异粒子群优化算法结合SVM建立多组分混合气体定量分析模型是有效可行的。粒子群优化算法实现简单、优化率高,通过信息共享缩短了寻优时间,提高了收敛速度;通过自适应变异,跳出局部最优,保证在全局范围内找到最优解。
4 结论
本文将自适应变异粒子群优化算法应用于支持向量机的参数寻优,对浓度范围在0.5%~8%的CO、3.6%~12.5%的CO2及200×10-6~3 270×10-6的C3H83种组分混合气体进行定量分析,选取其中15组样本作为训练集,建立了SVM回归模型,并对训练集进行预测分析,以检测模型的准确度;选择剩余的5组气体样本作为验证集,验证模型的预测精度和水平。在SVM参数的选取问题上,提出了自适应变异粒子群参数寻优法,对各组分气体采取独立建模的方式。与启发式遗传算法相比,在寻优时间相差不大的情况下,测试结果均方差明显小于遗传算法。其中,粒子群优化建模所用时间为39.524 s,遗传算法为26.272 s;粒子群优化训练集预测结果均方差分别为:CO,5.302 63×10-5;CO2,0.000 123 758;C3H8,9.569 22×10-5。粒子群建模对测试集的预测结果均方差分别为:CO,0.000 107 812;CO2,0.000 221 996;C3H8,0.000 226 165。遗传算法优化训练集预测结果均方差分别为:CO,4.612 27×10-5;CO2,2.149 52;C3H8,3.719 87×10-5。遗传算法建模对测试集的预测结果均方差分别为:CO,0.000 162 708;CO2,2.146 01;C3H8,3.970 9×10-5。可以看出,虽然PSO寻优时间长于遗传算法,但是预测精度却高于遗传算法,特别是针对CO2独立建模的预测结果,牺牲一点时间而提高测量精度在实验中是可以接受的。因此,将自适应变异粒子群优化与SVM相结合建立多组分混合气体红外光谱的定量分析模型具有一定的发展潜力和可挖掘空间。
[1]余大洲.基于RBF神经网络的可燃气体检测系统的研究[D].长安大学,2014.
[2]耿志广,王希武,王寅龙,等.基于人工神经网络的电子鼻对混合气体检测研究[J].现代计算机:专业版,2010(5):45-48.
[3]乔聪明.PLS-SVR的三组分混合气体定量分析[J].太原理工大学学报,2014,45(1):120-122,127.
[4]张愉,童敏明,戴桂平.基于OBLPSO-LSSVM的一氧化碳浓度检测[J].计算机工程与应用,2013,49(24):249-252,261.
[5]张其林.基于支持向量机的红外光谱混合气体组分分析[J].计算机时代,2010(1):9-11.
[6]金翠云,崔瑶,王颖.粒子群优化的SVM算法在气体分析中的应用[J].电子测量与仪器学报,2012,26(7):635-639.
[7]李玉军,汤晓君,刘君华.基于粒子群优化的最小二乘支持向量机在混合气体定量分析中的应用[J].光谱学与光谱分析,2010,30(3):774-778.
[8]Manouchehrian Amin,Sharifzadeh Mostafa,Hamidzadeh,et al.Selection of Regression Models for Predicting Strength and Deformability Properties of Rocks Using GA[J].International Journal of Mining Science and Technology,2013,23(4):492-498.
[9]宋召青,崔和,胡云安.支持向量机理论的研究与进展[J].海军航空工程学院学报,2008,23(2):143-148,152.
[10]孙小慧,孙恒,吴涛.粗糙随机样本的结构风险最小化原则[J].周口师范学院学报,2012,29(5):7-12,17.
[11]付华,王馨蕊,杨本臣,等.基于MPSO-CWLS-SVM的瓦斯涌出量预测[J].传感技术学报,2014,27(11):1568-1572.
[12]付华,王馨蕊,王志军,等.基于PCA和PSO-ELM的煤与瓦斯突出软测量研究[J].传感技术学报,2014,27(12):1710-1715.
[13]Andrews P S.An Investigation into Mvolutionary Operators for Particle Swarm Optimization[C]//IEEE Congress on Evolutionary Computation,Vancouver,2006:1029-1036.
[14]Parsopoulos E,Vrahatis M N.Parameter Selection and Adaption in Unified Particle Swarm Optimization[J].Mathmatical and Computer Modeling,2007,46(3):198-213.
[15]徐冰,王星,Dhaene Tom,等.基于遗传算法的多目标最小二乘支持向量机在近红外多组分定量分析中的应用[J].光谱学与光谱分析,2014,34(3):638-642.

曲 健(1989-),男,山东青岛人,在读研究生,主要研究方向为检测技术,13645712326@163.com;

陈红岩(1965-),男,浙江杭州市,教授,研究生导师,浙江大学内燃机工程专业硕士、博士学位;上海交通大学动力与机械工程专业博士后。主要研究领域为汽车电子、发动机排放与控制等,bbchy@163.com。
Application of Support Vector Machine Based on Adaptive Mutation Particle Swarm Optimization in Analysis of Gas Mixture
QU Jian,CHEN Hongyan*,LIU Wenzhen,ZHANG Bing,LI Zhibin
(College of Mechanical and Electrical Engineering,China Jiliang University,Hangzhou 310018,China)
For the difficult in selecting parameter of SVM modeling,the data calculation excessive in infrared spectroscopy,as well as crosstalk between gases and other issues in the quantitative analysis of mixed gas.A solution of adaptive mutation particle swarm optimization support vector machine was proposed.It was to establish the models of a multi-component mixture gases quantitative analysis based on infrared spectroscopy.Multi-component mixture gases are composed of CO,with the concentration range from 0.5%to 8%;CO2,with the concentration range from 3.6%to 12.5%;C3H8,with the concentration range from 200×10-6to 3270×10-6.Use the Particle swarm optimization algorithm to optimize select the parameters in support vector machine modeling,and compare the support vector machine modeling parameters in genetic algorithm optimization.Experiments show that it takes 39.524 s for modeling and it takes 26.272 s with genetic algorithm;for the predict results of CO2in independent modeling,the variance of PSO algorithms is 0.000 123 758,the variance of genetic algorithms is 2.149 52.In the case of modeling time slightly higher,the predict results were significantly lower than the variance of the genetic algorithm.
sensor application;SVM;particle swarm optimization;genetic algorithms;quantitative analysis
TH744
A
1004-1699(2015)08-1262-07
��7230;4145
10.3969/j.issn.1004-1699.2015.08.027
2015-04-06 修改日期:2015-05-25
