面向水利信息资源目录服务的分布式语义检索方法研究
2015-11-26唐志贤卞一路
冯 钧,许 潇,唐志贤,卞一路
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
水利信息共享是我国信息资源共享建设的重要组成部分。信息资源的发现是共享的基础,对于采用元数据描述资源的目录服务而言,元数据的发现机制是目录服务的关键技术之一。传统搜索引擎对查询请求的处理局限于词的表面形式,存在“忠实表达”、“表达差异”、“词汇孤岛”等问题,限制了资源发现过程中的查全率和查准率。水利信息不是孤立存在的,相互之间在语义上存在复杂联系,例如降雪和降雨都属于降水,下雨与降雨等价等。对于以数据共享为目的的水利信息资源目录服务系统的目标用户来说,往往希望通过目录系统的发现服务来找到满足行业语义的所有相关数据资源,例如通过“降雨”来搜索信息资源,希望获取“降水”、“降雪”等水利信息元数据信息,而传统的检索方法无法应对这种应用需求。此外,水利信息的应用范围广泛,用户对数据的理解参差不齐,非专业用户往往希望通过输入非水利专业检索词以发现水利信息资源,例如通过关键词“下雨”甚至“雨天”检索出“降雨”、“降水”等相关信息资源,更是传统全文检索方法望尘莫及的。必须要从查询语句所表达的语义层次来认识和处理用户的检索请求,进行相应的语义扩展才能使检索结果更加准确和全面。随着水利信息资源整合和共享的深入推进,现有的集中式信息资源检索模式已经无法满足业务应用的实时性和并发性需求,迫切需要对检索处理进行并行化改造。
本文提出一种面向水利信息资源目录服务的分布式语义检索方法(Distributed Semantic Retrieval Method for Water Information Resources Directory Service,DSRM)。DSRM 将利用基于水利公文词表构建的水利领域本体,通过构建语义推理机实现对查询关键词的语义扩展,并根据语义相关度进行结果排序,解决水利信息资源目录服务发现过程中语义缺乏的问题;同时定义语义相似度阈值和选择方法防止“语义飘移”以保证检索的查准率;基于MapReduce 对索引创建和查询处理进行并化改造提高检索的处理效率。
1 相关研究
随着语义网技术和云计算技术的不断成熟和广泛应用,语义检索和分布式检索领域已经形成大量研究成果。针对信息资源的语义检索研究,Yu 等人从非语义相关词汇扩展和语义相关词2 个方面进行关键字扩展保障信息检索过程的查全率[1];文献[2-4]利用领域元数据的数据关系构建领域本体,通过引入本体技术提高解决空间信息检索效率;在应用项目方面,面向生物学领域的语义检索系统TextPresso[5]和对HTML 网页进行语义标注的实现语义检索的SHOE[6]最为经典。在分布式检索方面,文献[7]主要研究解决海量异构、多来源数据的处理效率和共享程度低的问题,其中通过Hadoop 存储空间数据原始文件以及索引文件。文献[8]主要是针对特定的多媒体收藏展开研究,提出一个高性能的高维索引以及使用Hadoop 集群来搜索海量数据的SIFT 描述符。文献[9-10]将Lucene 和HBase 相结合构建分布式全文搜索引擎。文献[11]基于MapReduce 计算模型构建了图片的分布式搜索引擎。从国内外的文献来看,水利领域还没有成熟的分布式语义检索技术,限制了水利信息检索效率和业务化应用。
2 面向水利信息资源目录服务的分布式语义检索方法
2.1 领域本体
《水利公文主题词表》是水利行业各部门在计算机网络环境下处理政务信息的规范性主题标引工具和检索工具。水利部办公厅于1994 年组织编制并使用,2000 年和2006 年2 次修订。词表自面世以来,在水利行业办公自动化过程中发挥了重要的作用,是水利公文主题标引和计算机检索的必备工具,其中词汇之间具有明确的上下位、兄弟、使用、代替、注释等关系,如表1 所示,其中权重是根据水利信息资源目录建设需求和行业经验进行设置的,在实际的使用过程中还可以根据需要调整,故本文将《水利公文主题词表》作为水利领域本体的基础资源,在抽取其中基本词汇的同时进行扩展以构建本体。

表1 水利领域本体的语义关系
2.2 基于领域本体的查询扩展
本文基于领域本体概念相似度进行查询扩展,基本思想是:通过查找与检索词相似度大于阈值的词,把相似度作为该扩展词的权重和扩展词一并提交给搜索引擎,进行关键词查询。为了能够支持对非水利专业用户的语义扩展,本文还引入了知网语义进行通用词汇的扩展,进一步提高检索语义扩展能力。
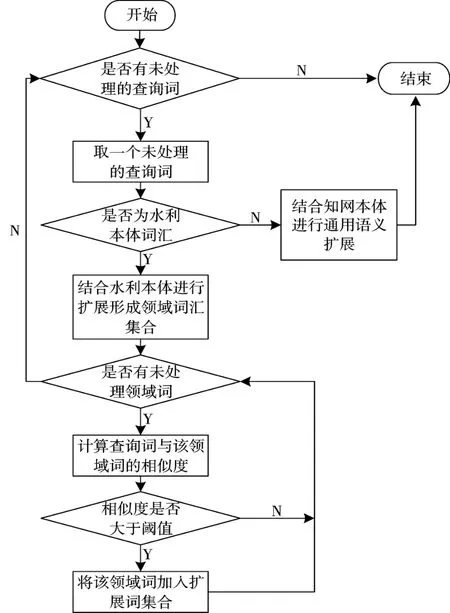
图1 语义查询扩展流程
如图1 所示,为语义扩展流程。对于用户提交的检索关键词,首先判断该关键词是否为水利专业词汇,若是则进行水利专业领域扩展,若不是则利用知网语义进行扩展。在进行语义扩展时需要计算词汇间的语义相关度,本体词汇间关系的基本相关度权值定义如表1 所示(其中β 为可调节的整体相似度)。在计算相关度的基础之上,通过设定语义相似阈值来过滤掉一些低相关的词汇,使扩展查询时扩展词尽量与原检索词相似。但是,由于词汇间可能会存在多条扩展路径,相应也会存在多个相似度值,在这种情况下本文采用相似度的较小值以减少扩展查询的语义漂移,保证查询的查准率。
2.3 语义推理
在进行语义扩展的过程中,需要利用语义推理机推断出与检索关键词相关的本体词汇,形成领域语义词汇集并计算词汇间的相似度。为了表达词汇及其关系的模糊性,借鉴模糊本体[8]的概念在每个本体的概念上加入隶属度集,用以表达词汇之间的相关性。同时,对水利信息资源进行文本分词,采用模糊资源描述框架FRDF[8]用三元组(主体、(谓词、权值)、客体)来描述分词后水利信息资源及其关系。在完成对资源及其关系进行规范化描述的基础上,本文借助Jena 构建语义推理机,定义相关推理规则实现语义推理,推理过程中先读取解析后的本体,然后对推理规则进行解析并绑定到模型中,最后使用Jena三元组对其进行查询。

图2 推理规则
推理规则如图2 所示,其中推理规则1 表示具有“subClassOf”传递关系,推理规则2 用以推理出“sameType”关系,推理规则3 用以推理出“brother”关系。通过图2 所示推理规则,结合水利领域本体的语义关系即可实现基于水利的语义扩展。
2.4 结果排名
在进行语义扩展的基础上,结合分词算法对水利数据目录服务的元数据进行全文检索,本文根据《水利公文主题词表》的结构和水利信息实践的经验对向量空间模型进行改进,元数据资源与检索词的文本相关度计算方法如公式(1)所示:

其中norm(T)为元数据资源文本内容T 进行最大匹配算法分词后词汇(wordi)集合的大小;hash(wordi)=(1-0.3)/n 为根据词汇的主题相关值,n 为《水利公文主题词表中》中主题词的等级,若wordi不在索引中,则hash 值为0。对采用知网语义进行扩展的词汇则按向量空间模型计算元数据资源与检索词的文本相关度。
在完成文本相关度计算的基础之上,结合检索词汇间的语义相关度即可计算出元数据资源与用户输入检索词间的相似度,按相似度降序将结果返回给用户。
2.5 基于MapReduce 的并行检索
为了提高检索效率,本文将云计算技术引入水利信息资源目录服务的资源发现处理过程中,利用Hadoop 构建基于云的检索模块,基于MapReduce 并行处理模型对基于Lucene 的全文检索算法进行并行化改造,以提高大规模查询请求条件下的查询处理效率。图3 为本文并行检索算法的处理流程,算法首先对检索请求进行划分,形成若干查询请求子集,每个查询请求子集交由一个Map 节点处理,Map 节点读取索引文件进行查询,并将查询结果交由Reduce 进行合并,实现查询的任务并行。对查询子集中的每一个查询请求,同样将其发送到多个Map 节点,由每个Map 节点对该节点存储的索引分片进行检索,最终再由Reduce 进行检索结果合并,实现查询的算法并行,处理流程与任务并行相似。

图3 基于MapReduce 的并行检索流程
3 原型实现与案例研究
3.1 原型系统设计与实现
图4 所示为基于DSRM 的原型系统架构,包含语义本体模块和语义查询处理模块。语义本体模块用于存储水利领域本体和知网语义本体,并完成领域词汇相似度的计算,包括水利本体库、知网本体库和语义词汇相似度计算单元(计算语义词汇相似度);其中水利本体库用于存储水利领域本体(采用模糊本体的形式描述)及其词汇的相似度;知网本体库用于存储知网本体词汇及子网词汇相似度。语义查询处理模块,利用查询请求处理单元获取用户的查询请求,并进行分词处理形成查询词集合;模糊语义推理单元进行推理形成语义扩展查询词集合,Lucene 分布式检索单元从水利信息资源目录服务元数据库中检索满足查询词集合和语义扩展查询词集合的元数据,形成语义检索结果集合;最后由检索结果排序单元按照相关度对查询结果进行排序,并按降序将查询结果返回用户。
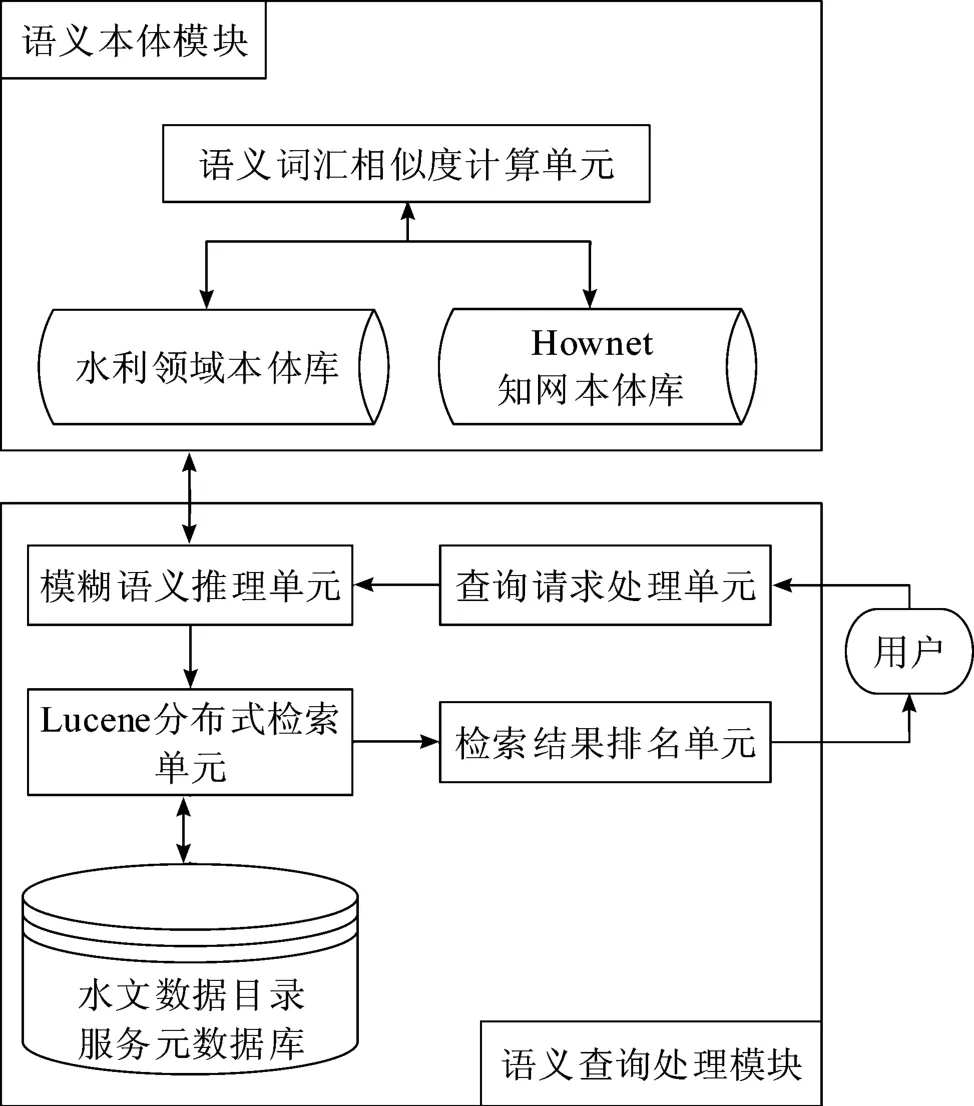
图4 DSRM 原型系统架构
3.2 语义检索实验分析
表2 所示为本实验的一个水利词汇语义扩展示例,其中可调节的整体相似度β 取值为0.9,语义相似度阈值为0.8。图5 为本语义检索的一个示例(左侧为语义检索结果,右侧为传统关键词匹配检索结果),分析图5 可以发现,由于元数据库中无任何包含“四荒”关键词的元数据资源,传统的检索方法没有检索结果,而本文提出的DSRM 方法在阈值为0.8时,找到4 个有关“四荒”的结果(与表2 中的扩展吻合),可以看出DSRM 检索方法能够有效地进行查询扩展,从而提高检索的查全率。
3.3 并行查询效率分析
为了分析并行效率,本文对1000 万条元数据建立索引,在此基础上分别模拟了100、1000、10000、20000 直到100000 个查询请求,进行查询时间的统计。实验平台由1 台名称节点和3 台数据节点组成,所有计算机的配置相同(CPU:Intel Pentium4 2 GHZ,内存:DDR2 2 GB,硬盘:80 GB,7200 r/min,2 MB 缓存,操作系统:Ubuntu Linux);Hadoop 集群版本为0.20.2,Hbase 版本为0.90.4。为了让数据更能反映实际,每组数据都作了若干次测试,最后取多次实验的平均值作为最终实验结果。实验结果如图6 所示,当查询请求较少时,并行模式的效率并未体现(启动Hadoop 需要一定的时间开销);当查询请求量逐步增大时,并行查询效率的优势就逐步体现出来了;当查询量达到10 万时,查询效率提高近3 倍,并且增长趋势比单机模式低,体现了并行查询的优势。
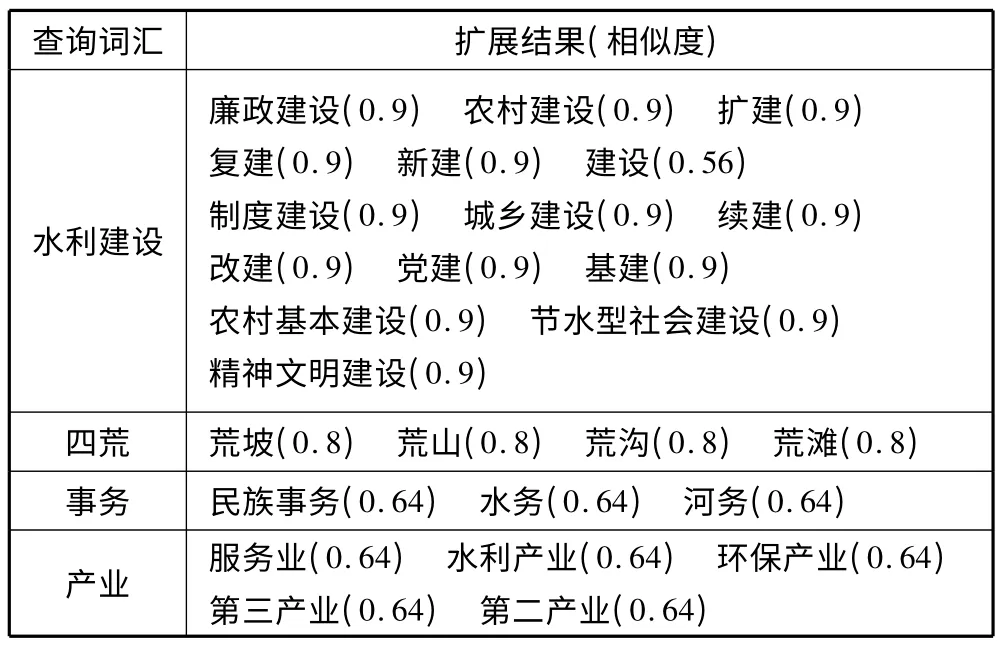
表2 查询词汇语义扩展示例

图5 语义检索结果示例
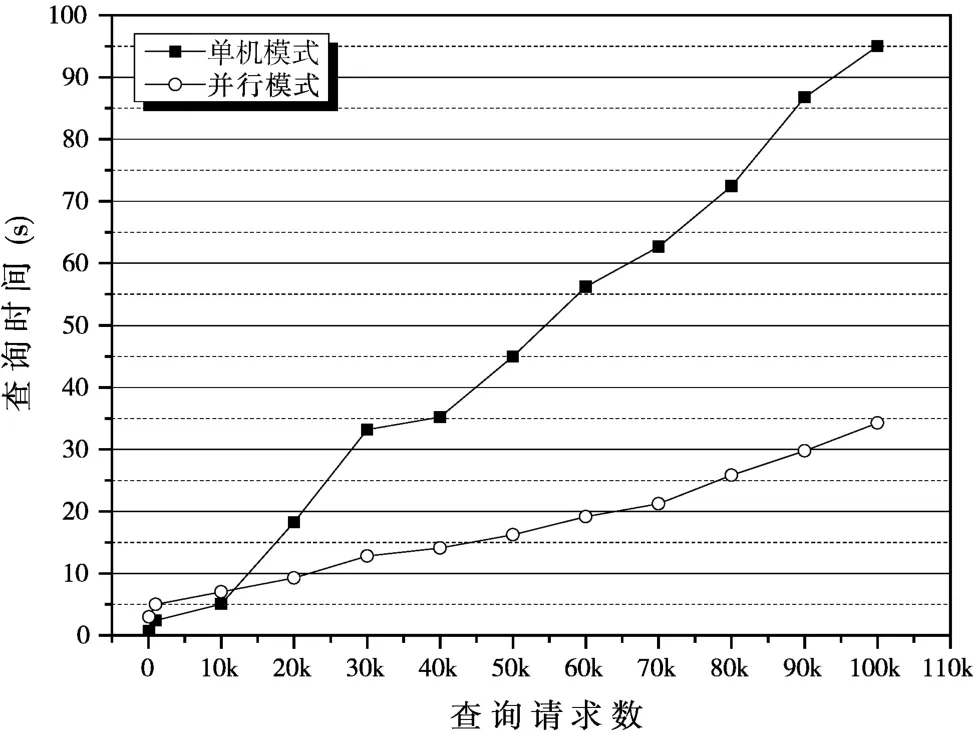
图6 并行查询效率分析
4 结束语
水利信息共享系统的建设是解决水利数据为科学研究、为社会提供信息服务的重要手段。水利数据目录服务利用元数据对分布存储的水利数据进行规范化的描述,通过构建元数据信息的发布、发现服务以支撑对水利实体数据的发现;不仅是数据发现的窗口,更是共享服务的起点。本文针对水利数据目录服务中元数据检索的查全率和查准率要求,结合推理机制提出了基于水利领域本体和知网语义的查询扩展方法,解决了查询过程中的“机械匹配”问题;基于MapReduce 的检索算法并行改造,有效提高了查询效率。在后续的研究中,可以考虑定义更多的推理规则实现更加完善的语义扩展。
[1]朱星明,耿庆.略论水利技术标准中信息共享类标准存在之问题[J].水利技术监督,2006(3):6-9.
[2]王欢,孙瑞志.基于领域本体和Lucene 的语义检索系统研究[J].计算机应用,2010,30(6):1655-1660.
[3]虞为,曹加恒,陈俊鹏.基于本体的地理信息查询和排序[J].计算机工程,2007,33(21):27-32.
[4]Yu Xuejun,Lv Jing.Keywords semantic extension in semantic search model[C]// International Conference on Computer,Networks and Communication Engineering.2013.
[5]段磊,李琦,毛曦.基于本体的空间搜索引擎研究[J].计算机科学,2009,36(2):172-174.
[6]Janowicz K,Raubal M,Kuhn W.The semantics of similarity in geographic information retrieval[J].Journal of Spatial Information Science,2013(2):29-57.
[7]Ahlers D.Towards a development process for geospatial in-formation retrieval and search[C]// Proceedings of the 22nd International Conference on World Wide Web Companion.International World Wide Web Conferences Steering Committee.2013:143-144.
[8]California Institute of Technology.Textpresso[EB/OL].http://www.textpresso.org,2014-10-31.
[9]SHOE Team.SHOE[EB/OL].http://www.cs.umd.edu/projects/plus/SHOE/,2014-10-31.
[10]Shestakov D,Moise D,Gudmundsson G,et al.Scalable high-dimensional indexing with Hadoop[C]// IEEE 2013 the 11th International Workshop on Content-Based Multimedia Indexing (CBMI).2013:207-212.
[11]Liu Tianyuan,Song Meina,Zhang Xiaoqi.Research of massive heterogeneous data integration based on Lucene and XQuery[C]// IEEE the 2nd Symposium on Web Society (SWS).2010:648-652.
[12]Gao X,Nachankar V,Qiu J.Experimenting lucene index on HBase in an HPC environment[C]// Proceedings of the first Annual Workshop on High Performance Computing Meets Databases.ACM,2011:25-28.
[13]Gu Chunhao,Gao Yang.A content-based image retrieval system based on Hadoop and Lucene[C]// IEEE 2012 the Second International Conference on Cloud and Green Computing(CGC).2012:684-687.
[14]王俊生,施运梅,张仰森.基于Hadoop 的分布式搜索引擎关键技术[J].北京信息科技大学学报(自然科学版),2011,26(4):53-56.
[15]黄果,周竹荣,周亭.基于领域本体的语义相似度计算研究[J].计算机工程与科学,2007,29(5):112-116.
[16]张承立,陈剑波,奇开悦.基于语义网的语义相似度算法改进[J].计算机工程与应用,2006,42(17):165-166.
[17]李鹏,陶兰,王弼佐.一种改进的本体语义相似度计算及其应用[J].计算机工程与设计,2007,28(1):227-229.
