GPU通用计算及其在计算智能领域的应用
2015-11-26丁科谭营
丁科,谭营
(1.北京大学 机器感知与智能教育部重点实验室,北京100871;2.北京大学 信息科学技术学院,北京100871)
GPU通用计算(general purpose computing on GPUs,GPGPU)是一种利用图形处理器(graphics processing unit,GPU)解决通用计算任务的异构计算方式。
最初的GPU只是功能专一的协处理器,用以帮助中央处理器(central processing unit,CPU)从繁重的图形图像处理任务中解脱出来。为满足人们对图像处理实时性和精确度不断高涨的需求,在过去的十多年间,GPU的体系结构和制造工艺都取得了长足的进步;GPU的计算性能及计算精度都得到了大幅提升。如今,GPU的浮点计算能力早已远超同时期的CPU。
图像处理任务具有高度并行的特点,这使得GPU从诞生之日起,便采用多核心的设计方案。随着GPU性能的不断增强和可编程性的日渐提高,GPU的用途不再局限于传统的图形图像处理。目前,GPU已经广泛应用于从小到图像解码,大到超级计算机的各种计算领域,进入到了高性能计算的主流行列。
Owens等[1-2]全面综述了 2007 年之前的 GPU通用计算的进展情况。然而,在过去的几年里,GPU软硬件条件都发生了极大的发展变化。GPU高级编程平台,如CUDA、OpenCL等的出现,更是使得GPU通用计算的面貌发生了深刻的变化。
本文在已有文献综述的基础上,总结了GPU通用计算领域最新的软硬件发展及在计算智能领域的应用。文章首先介绍GPU通用计算出现的背景,包括传统CPU面临的困难与挑战以及GPU作为通用计算器件的特点与优势。接着,文章回顾GPU通用计算开发工具和平台的发展历程。然后,本文转向GPU通用计算的现状,重点介绍主流的GPU编程平台——NVIDIA GPU专属的CUDA平台和开放标准的OpenCL平台。GPU通用计算的主要在计算智能领域的重要应用将在之后予以介绍。最后,文章对GPU通用计算的目前存在的挑战及未来发展趋势进行展望。
1 GPU通用计算背景
1.1 多核计算时代
CPU是计算机系统的核心部件,它为各种任务提供计算能力,是一种通用的计算单元。CPU的计算能力可以用每秒钟执行指令数(instructions per second,IPS)来衡量,而IPS则是由CPU的指令吞吐量(instructions per clock,IPC)和时钟频率F所共同决定的:

为了提高CPU的性能,可以从两方面入手:增加指令吞吐量(IPC)和提高时钟频率(F)。
随着制作工艺的不断提高,CPU芯片的集成度越来越高[3]。一方面,在集成度更高的芯片中,各个单元在物理上更加靠近,从而可以使器件运行在更高的频率上。另一方面,更多的晶体管也使得设计更复杂精细的逻辑控制结构,以提高单位时钟周期的指令吞吐量。
在经过了多年的发展之后,这2种策略都遭遇到了巨大的瓶颈。时钟频率的提高使得芯片消耗的功率密度(W/cm2)随之提高,供电和散热即将达到某些基本的物理极限。如图1所示,CPU的时钟频率在经历了长期高速增长后,其提升势头难以为继。
通过复杂的逻辑结构提高指令吞吐量也逐渐达到了收益递减点。现代处理器的内部结构已经十分复杂,并已经能够从指令流中压榨出大量的并行性。通过设计更复杂的结构来提高指令的执行能力变得更加困难[3]。
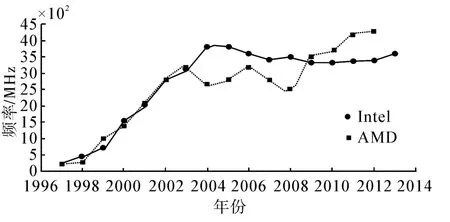
图1 CPU时钟频率变化趋势Fig.1 The tendency of CPU’s frequency
为应对上述困难,多核解决方案被提出,以便充分利用晶体管数量的增加,进一步改善CPU。
事实上,2004之后,主要的CPU厂商如Intel和AMD等相继转移到多核解决方案,多核计算时代已全面到来。
1.2 GPU的特点与优势
GPU最初是为了加速图形处理而设计的专用硬件。图形渲染等任务具有很强的并行性,需要密集的计算与巨大的数据传输带宽。因此,GPU从诞生之日起便被设计为拥有众多核心,具有高吞吐量的计算。并且,由于GPU的专用性,GPU芯片的晶体管也更多的用于计算,而非控制和缓存(如图2所示)。由于GPU与CPU在设计上存着巨大的差别,GPU通用计算有着自身的特点与优势。
1)计算能力强大
与CPU相比,GPU具有更加强大的计算能力。在相同时期,GPU的浮点计算的理论峰值能力相比CPU要高出一个数量级[6]。
强大的计算能力使GPU在高性能计算领域获得了广泛的应用。在全球最快的超级计算机之中,中国国家超级计算天津中心的天河1A号超级计算机和美国橡树岭实验室的TITAN号超级计算机,都是依靠装配GPU来提升性能,并提供大部分运算能力。GPU为高性能计算提供了新的巨大的发展潜能。
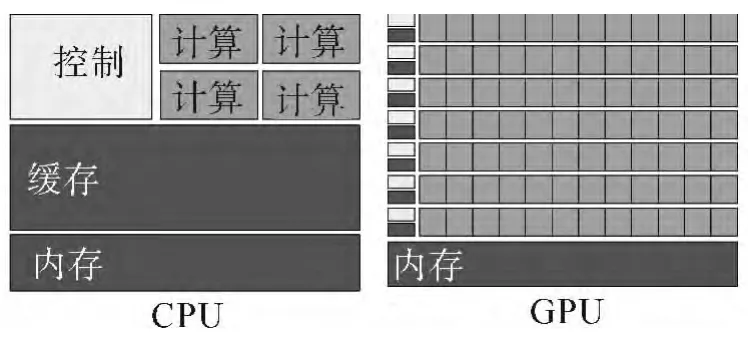
图2 GPU的晶体管更多的用于计算单元Fig.2 GPUs devote more transistors to data processing
2)廉价易得
相比与基于CPU的计算机系统,GPU更加廉价,也更容易为个人和小型机构所利用。
以NVIDIA的旗舰版GPU TITAN为例。TITAN GPU价格不足一万元人民币,共有2 688个计算核心,双精度浮点运算理论峰值计算能力达到1 500 GFLP/s,额定功耗约为250 W。作为对比,北京大学理论与应用地球物理研究所的集群,由1个服务器(Dell PowerEdge R710)、46个计算结点(Dell PowerEdge M610)、3个刀片机箱(Dell PowerEdge M1000)组成。每个计算结点有2颗四核Intel Xeon E5520(2.26 GHz,Nehalem-EP 架构)处理器,共 368个计算核心,理论计算峰值3 327 GFLP/s,满载功耗约为12 kW。
可以看到,在提供相同数量级的计算能力的情况下,GPU非常的廉价,也易于装配(只需要一台能够支持独立显卡的PC),个人和小型实验室都有条件利用。而集群等传统高性能计算设备,不但价格昂贵,对场地、供电和维护等有较高的要求。可以说,GPU为PC提供了小型集群的计算能力[7]。
3)开发灵活
现代的GPU都采用统一渲染架构,具有很强的可编程性。GPU编程的软件开发平台也趋于成熟,CUDA、OpenCL等工具的推出,使开发者能够使用高级编程语言为GPU开发通用计算程序。现在主流的GPU也对单精度和双精度浮点运算提供了满足IEEE标准的完全支持。对于GPU编程,我们会在下面的章节详细介绍。
2 GPU通用计算编程平台
最初的GPU功能固定,只能执行图形流水线中的特定任务,缺乏可编程性。此时,为了利用GPU进行通用计算,必须将计算任务封装成图形处理任务,然后交由GPU完成。这可以通过底层的汇编命令(低级着色语言)编程实现。更为高效的,通常我们可以通过诸如OpenGL、Cg等图形编程接口,利用高级着色语言(shading language,SL)进行编程。
但即使利用高级着色语言,这种方式也还存在诸多不便。首先,开发者需要熟悉图形处理的流程,掌握一系列图形处理接口,并且需要以与任务完成完全无关的一套图形处理思路来考虑问题的编程求解。其次,图形接口是专用的程序接口,缺乏通用计算所需要的灵活性,开发者必须面临如何将问题重新表述成图形处理问题的挑战。
为了简化GPU编程,具有更高层硬件层次的编程模式被相继提出。GPU的统一着色器被抽象为与具体硬件无关的、能够以特定方式并行执行线程的流处理器单元。GPU的内存、纹理缓存等存储单元,被抽象为具有层级结构的存储体系。经过抽象后,可以在流处理模式下,利用高级语言为GPU编写程序,完成通用的计算任务。
本节首先介绍与GPU通用计算密切相关的流处理模式。之后,转向介绍基于流行的GPU编程语言和工具。
2.1 流处理模式
流处理模式(stream programming model)是一种类似于单指令多数据(SIMD)的编程模式。
通过将数据组织成数据流,将计算表达成作用于数据流的核函数的方式,流处理能够暴露程序中内在的并行性。通过流处理模式,程序开发者能够更容易地利用GPU、FGPA等计算硬件的并行能力而不用显式地处理空间分配、同步和计算单元间的通信等问题。对于数据并行性良好的应用,流处理能够取得良好的性能[8]。
如图3所示,流处理与SIMD最大的不同之处在于,SIMD是以指令为操作单位的,而流处理模式则是以指令序列(核函数)为操作单元。数据流(输入流)与核函数一同进入流处理器,流中每个数据元素同时被核函数执行,从而完成指定的操作,得到输出数据(输出流)。
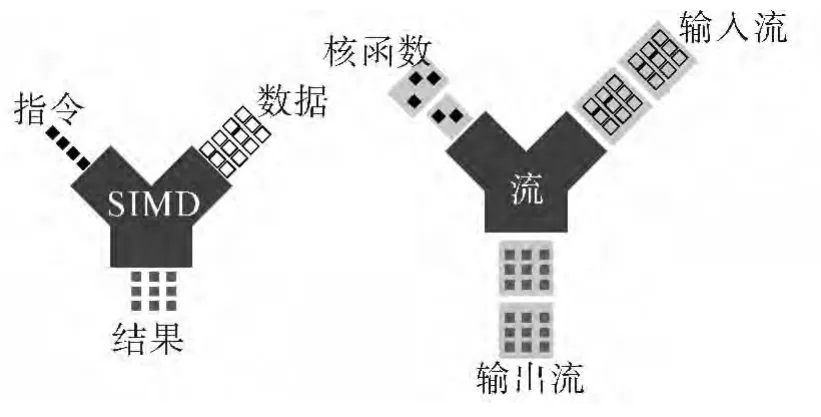
图3 流处理与SIMDFig.3 Stream processing and SIMD
流(stream)和核函数(kernel)是流处理模式中最重要的2个概念。流是一个数据集合,包含待处理的数据元素,并且这些数据的处理方式是相同或相似的。核函数是由若干操作(指令)组成的操作序列,它决定着要对每个数据做何种操作和处理。对GPU平台而言,纹理单元充当了流的角色,待处理数据需要作为2维的纹理信息被流处理器读取和操作。许多问题也可以很自然的映射为2维的纹理,如矩阵代数、物理仿真等等;而可编程着色器则起着核函数的作用。
2.2 Brook
Brook是一种基于标准C语言的流编程语言。它旨在基于流编程模式,对图形API进行封装,将GPU视为能够进行并行计算的协处理器,从而简化GPU通用计算的编程[8]。
Brook使人们看到了将GPU用于通用计算的巨大潜力,对GPU通用计算的发展有着深远的影响。Brook将GPU封装为通用的并行处理器的思想及语言规范更是为现在主流的GPU编程平台CUDA和OpenCL所借鉴,而这两者正是现在GPU编程的主流开发平台。
2.3 OpenACC
OpenACC是一个异构并行计算标准。与OpenMP类似,OpenACC定义了一套编译器指令,这些指令应用于C、C++和Fortran代码,以指导编译器将指定的循环或代码块,从主机CPU转移到相连的加速设备(例如GPU)上进行运算。
简言之,OpenACC提供了一种简洁的利用并行硬件的开发方式。目前,OpenACC已经在多种操作系统下实现,并支持NVIDIA、AMD和Intel的多种硬件计算设备[21]。未来,OpenACC可能会并入OpenMP标准,形成一个同时支持多核与众核并行编程的统一标准。
2.4 C++AMP
C++accelerated massive parallelism(C++AMP)是一个由微软倡导的开放标准,旨在直接利用C++语言实现数据的并行化编程[9]。
相比于常规的C++代码,C++AMP只需要按规定格式对数据进行绑定,然后应用并行原语启动数据操作(核函数)的运行。因此,C++AMP完全隐藏了硬件的细节。开发者只需要预先绑定数组和数组元素上的操作,并行化由C++AMP负责完成。C++AMP能够根据实际的硬件情况(GPU或CPU,计算核心算数等),决定并行化策略。当实际硬件不支持并行化时,代码还可以串行执行。
2.5 高级编程平台
在OpenACC和C++AMP这2种异构编程模式下,硬件对开发者而言完全是透明的。一方面,这简化了并行程序的开发——串行代码只需要少量的改动,便可以利用GPU等多核计算设备的并行计算能力。但这种简化并非没有代价,它使得并行化的过程不能被程序员显示地加以控制。而在很多情况下,根据硬件和程序的具体情况,对负载和并行粒度进行调整,对于充分利用计算设备能力、提高程序性能是至关重要的。
正如前文所述,CUDA和OpenCL是当前基于GPU的异构编程的主流平台。它们的共同特点是,既对硬件的计算和存储单元进行了很好的抽象,同时又对计算设备的计算核心数量这一重要参数,加以适度地暴露,并且对并行粒度和并行方式也给予了更大的控制可能。这样便对完全隐藏硬件这一极端情况的进行了良好的折衷。同时,这2种平台为GPU通用提供了从编程到调试再到性能测试的完整解决方案。
3 统一计算设备架构
统一计算设备架构(compute unified device architecture,CUDA)是由 NVIDIA公司于 2006年 11月发布的基于NVIDIA GPU的并行程序开发架构[10]。它包括一个SDK(NVCC编译器、调试器、函数库等)、一套API,以及添加了少量扩展的C/C++语言(CUDA C/C++)。由它开发的程序能够在所有支持CUDA的NVIDIA GPU上运行。CUDA的推出大大简化了对GPU进行并行编程的难度。图3示意了NVIDIA GPU的主要计算和存储部件。接合图3,对CUDA开发平台的核心逐一进行简要介绍。
3.1 核函数
CUDA允许使用C/C++为CUDA计算核心(CUDA Core,在较早的文档中也称了 Streaming Processor(SP),即流处理器)编写程序——“核函数”(kernel)。
不同于常规的C/C++函数,当核函数被调用后,它会被N个不同的CUDA线程(thread)并行的执行N次。执行核函数的每个线程都被赋予一个一的线程索引ID。
3.2 线程的层级结构
如图4所示,CUDA中的线程具有层次结构。一定数量线程组成线程块(block);线程块再组成更大的单位线程格(grid)。
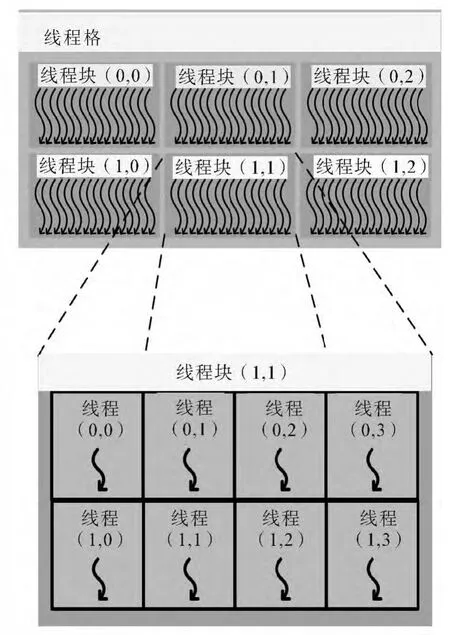
图4 线程的层级结构Fig.4 Hierarchy of threads
核函数启动后,每个线程块(thread block)被分配给某个流多处理器(streaming multiprocessor,SM)上执行。线程块执行的先后顺序是不确定的,它们必须相互独立地被执行。即不论它们按何种次序,也不论是按并行还是串行方式,最后的执行结果都应该一致。
不同流多处理器上的线程是相互独立的,相同流多处理器上的线程则是阻塞式的[10]。前者意味着,不同流多处理器上的线程由不同的处理器以任意先后顺序执行;后者意味着,当一个活跃线程受到阻塞(如执行延迟较大的数据读写操作)时,流多处理器可以切换执行其他的线程,避免浪费宝贵的计算资源。
3.3 内存层级结构
同基于CPU的常规计算机体系类似,GPU的存储体系也具有层次性:容量大的存储器,远离GPU,读写也延迟大;延迟小的存储单元容量小,位置靠近GPU。
如图5,CUDA程序在运行过程中,线程能够从不同的内存空间中读取数据。每个线程都有仅本线程可见的局部内存(local memory)。局部空间一般是片上的寄存器,可以几乎无延迟的读写。每个线程块分配有一块共享内存(shared memory),块中的所有线程都可以读写共享内存的数据。共享内存靠近GPU,虽然不如寄存器读写速度快,但访问延迟也非常小。离GPU最远的是大容量的全局内存。所有线程都可以访问全局内存,但读写延迟非常大,大约要比共享内存高出一个数量级。
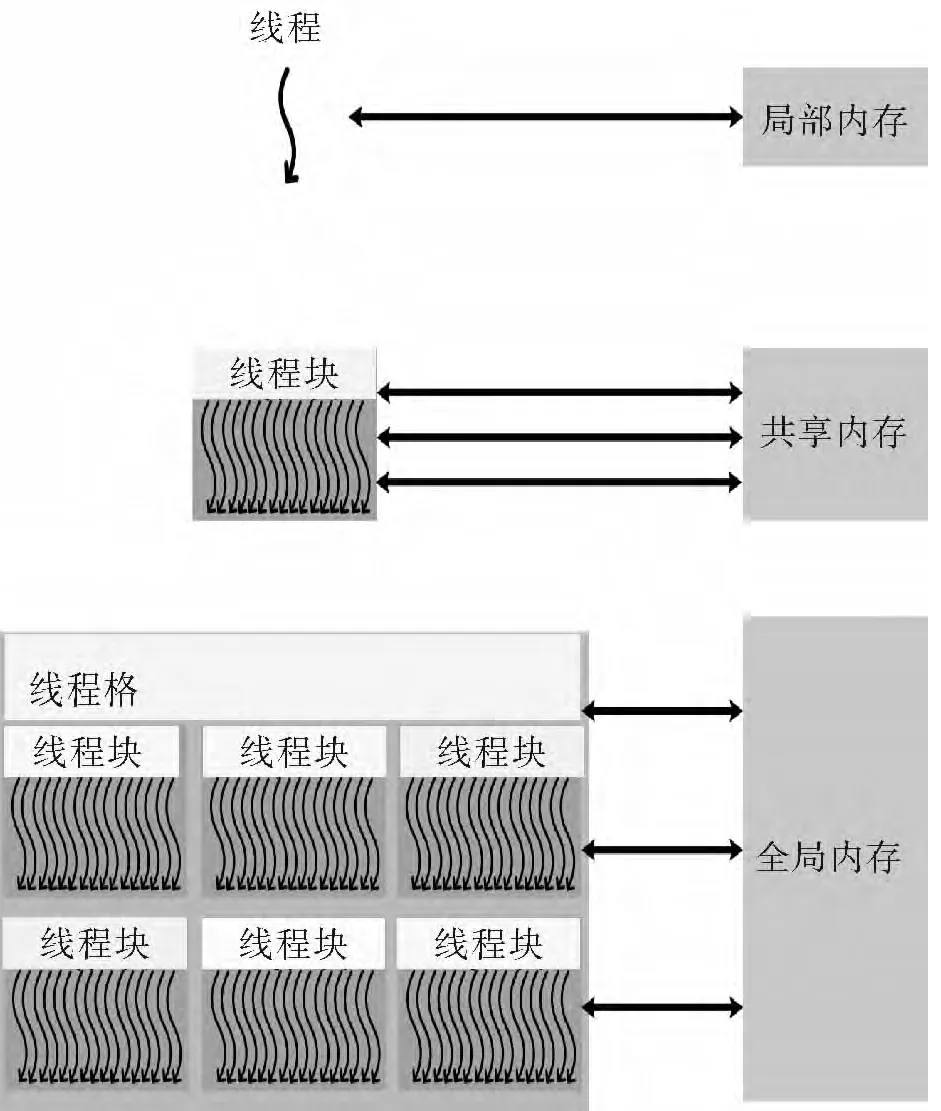
图5 线程的层级结构Fig.5 Hierarchy of threads
表1对比了在NVIDIA GeForce 560 Ti GPU中,不同层级内存的数据传输率。

表1 GPU 内存数据传输率(560 Ti,PCIe 2.0 x16)Table 1 GPU memory bandwidth(560 Ti,PCIe 2.0 x16)
除以上介绍的几种存储空间外,还存在2种对所有线程可见的只读存储空间——常量内存(constant memory)和纹理内存(texture memory)。常量内存和纹理内存的访问延迟同全局内存相同,但前者配备有缓存(cache),在数据局部性较好时,访问延迟要小于全局内存(参见图6)。

图6 NVIDIA GPU主要结构简图Fig.6 Diagram of NVIDIA GPU structure
同一线程块内的线程可以通过共享内存(shared memory)(块中每个都可以读写共享内存中的数据)和同步机制来相互协作。具体而言,程序员可以在核函数内调用内建函数来设置同步点,以使线程执行到该处后,停下来等待,直到同一块中的所有线程均达到同步点。
3.4 函数库
除了提供以C/C++为基础语言的高级编程平台,CUDA SDK还提供了许多函数库,高效实现常见操作,提高开发速度。例如,矩阵计算的cuBLAS和cuSPARSE,实施快速傅里叶变换的cuFFT,用于批量生成随机数的cuRAND,以及用于加速人工神经网络的 cuDNN[12-13]等。除了函数库外,还有大量第三方开源或商业函数库可供选择。这些函数库涵盖基本代数运算、数值计算、统计、图像处理、机器视觉、视频编码解码、GIS等领域。这些函数的数量和范围也在不断的增加,最新进展可以参见文献[11]。
3.5 调试与性能分析
调试和优化是编程开发重要的环节,也是GPU编程的一个难点。为简化调试和优化流程,提高开发效率,CUDA提供了一系列软件工具。
Parallel Nsight是集调试和性能测试于一体的编程辅助工具。Nsight可以集成在 Visual Studio(Windows下)和Eclipse(Linux下),实现交互式调试。在Linux环境下,开发者还可以在cuda-gdb在命令下进行调试,或将cuda-gdb同IDE配合使用。此外,CUDA SDK还提供了cuda-memcheck程序,检查内存越界访问错误。
除了上面提到的Nsight可以用于性能分析外,CUDA SDK还提供Visual Profiler工具,能够以可视化的方式展示程序各部分的运行时间,方便寻找性能瓶颈,以便有针对性地进行优化。
4 开放计算语言
开放计算语言(open computing language,OpenCL)是一个完全开放和免费的异构计算编程标准,它由非盈利性技术组织Khronos Group负责维护。OpenCL提供了一种跨平台、硬件无关的并行计算解决方案。由它编写的程序不仅能够在多核CPU、APU及GPU上运行,还能运行在单核CPU甚至DSP和FPGA等硬件设备上。OpenCL获得了主要硬件厂商Intel、AMD和NVIDIA的积极支持。
OpenCL的目标是提出一种跨硬件、跨平台的异构编程框架标准。OpenCL规范主要由平台模型、执行模型、内存模型和编程模型[13]4部分组成,它在硬件的抽象描述的基础上,制定了异构的并行编程模式。在制定OpenCL标准时,Khronos Group大量借鉴了CUDA[14],因此,2种并行解决方案有很多相似之处,其中,大部分关键概念都可以一一对应。
4.1 设备的层级模型
OpenCL定义了具有多级结构的异构并行体系模型。如图7所示,这一体系包括一个主机(host),多个设备(device);每个设备中包括若干计算单元(compute unit,CU)。计算单元对应于AMD GPU的计算单元(CU)或CUDA中的流多处理器(SM),但它也可以是CPU核心,还可以是DSP和FPGA等运算设备。计算单元又由若干处理单元(processing element,PE)组成。图8给出了内存模型。
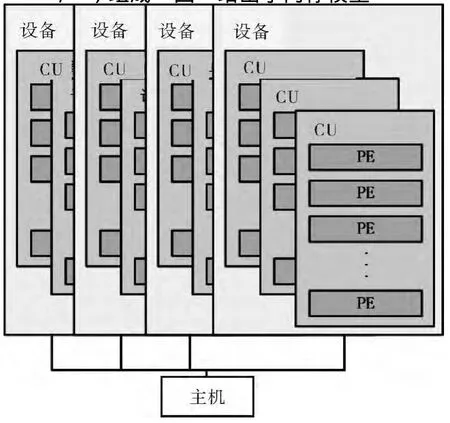
图7 OpenCL设备模型Fig.7 OpenCL device model
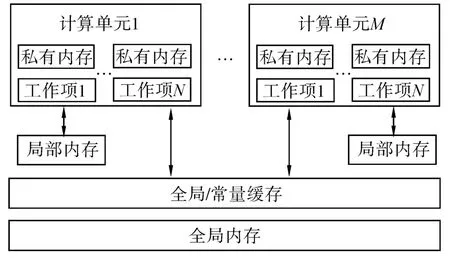
图8 OpenCL内存模型Fig.8 OpenCL memory model
如图8所示,OpenCL规范还定义了内存的层级结构和可见性:远离计算单元的全局内存(global memory)和常量内存(constant memory)是全局可见的,片上的局部内存(local memory)、计算单元内部的私有内存(private memory)则是局部可见的。
4.2 数据并行模型
OpenCL定义了程序的执行模式。图9给出了OpenCL抽象的数据并行模型。在OpenCL的概念中,执行单元也同是以层级结构进行组织的:工作项(work item)组成工作组(work group),工作组进而构成索引空间——NDRange。OpenCL的工作项,相当于CUDA的线程,是核函数执行的最小单元;工作组对应于CUDA的线程块,工作组内的项有更加方便的数据共享和同步机制,便于彼此协作。工作组又被置于更大的索引空间NDRange中,它发挥着CUDA中线程格的作用,为工作组和工作项提供全局索引。
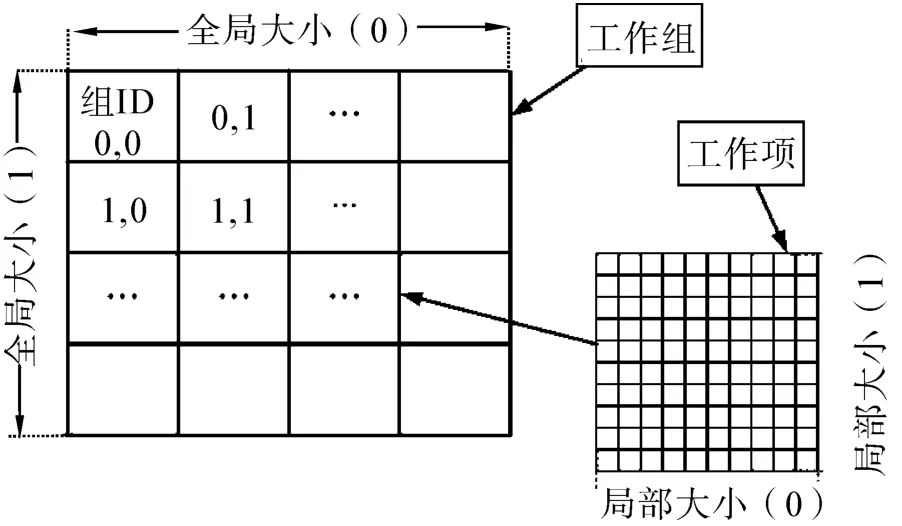
图9 OpenCL并行执行模型Fig.9 OpenCL execution model
同CUDA一样,工作项除了拥有在工作组内的坐标外,也具有工作组内的唯一的索引和唯一的全局索引;工作组也有着类似的索引结构。
4.3 设备管理与核函数启动
OpenCL的核函数的基本结构同CUDA完全相同,只是在具体编写时所使用的关键字不同。
OpenCL的核函数启动后,每个工作项都会执行核函数中指令,这一点也与 CUDA相同。由于OpenCL是与具体硬件无关的,因此,核函数的启动相对CUDA要复杂一些。(CUDA中,复杂的维护工作由运行时负责,用户也可以通过Driver API来显示的管理和查询。由于CUDA是针对专用硬件平台,因此,一般而言没有这样做的必要。)
如图10,OpenCL首先需要创建一个上下文(context)来管理设备,不同类型的硬件对应不同类型的上下文。上下文对硬件设备进行了封装,为主机调用设备的提供了统一的接口。主机启动核函数后,核函数被放在一个命令队列(CMD queue)中,等待执行。当设备完成一个核函数的执行后,会取出队列中的第一个核函数继续执行。关于OpenCL更详细的说明,可以参考[13,15];关于基于 AMD GPU的编程开发,可以参见[16]。

图10 OpenCL通过命令队列和上下文管理核函数执行Fig.10 OpenCL manages the kernels through command queue and context
4.4 函数库
OpenCL的生态系统也提供了大量的函数库,方便开发者利用。开源的数学函数库clMath实现了快速傅里叶变换(FFT)和基础线性代数全程库(BLAS)。其中,FFT支持1~3维的实数和复数变换;BLAS支持全部 1~3级别的代数运算。在clMath的基础上,MAGMA提供了矩阵的LU、QR和Chokesky分解、特征值计算等重要的矩阵操作的OpenCL实现。
4.5 调试和性能工具
目前已有许多优秀的工具,用于OpenCL程序的调试和优化。AMD APP SDK中的CodeXL包含了一整套软件工具,帮助开发者最大限度地发掘GPU的计算潜力。CodeXL包括功能强大的调试器,能够对CPU和GPU端的代码进行细致的监测,同时还能对OpenCL的kernel函数进行表态分析。CodeXL可以配合Visual Studio使用,也可以单独使用。
5 计算智能领域应用
GPU通用计算已经进入高性能计算的主流行列,被用于流体模拟、物理仿真、图像和信号处理、数值计算等诸多,并取得了良好的加速效果。文献[1-2]和[17]给出了GPU在许多关键领域和问题上的重要应用。本节主要回顾GPU在计算智能领域的应用。
计算智能算法一般具备并行性的特点,因此,特别适用利用GPU平台进行高效的并行化实现。
5.1 人工神经网络
人工神经网络(artificial neural network,ANN),模仿生物神经网络的结构和功能,通过联结大量的人工神经元进行计算。由于出色的特征学习能力,深度神经网络已经在图像识别、语言识别等领域取得了突破性进展。图11展示了深层卷积神经网络在学习图像的低阶和高阶特征上表现出的良好性能[18]。

图11 通过深度神经网络学习到的低阶和高阶特征[27]Fig.11 Low level and high level features learned by DNN[27]
随着深度学习[19](deep learning)研究的不断深入,人工神经网络的规模越来越大,计算复杂性不断膨胀。通常,深度神经网络包含上百万甚至上亿个自由参数,需要在海量的数据集上进行学习。因此,加速深度神经网络的训练速度是工程和科学领域的重要研究内容,直接关系到对深度神经网络的研究以及其在实际中的应用。
超级计算机和大规模集群的成本高昂,个人和中小型研究机和企业构难于负担。GPU通用计算,极大地降低了深度神经网络的研究和应用的门槛。
2012,Krizhevsky等[20],搭建了一个深度神经网络并用于图像识别。这个神经网络含有6 000万个参数,650 000个神经元。这个神经网络在ImageNet测试集(共有1 000个类别)上,取得了17%的Top 5分类错误率,取得了突破性的进展。而这个超大型神经网络的训练,正是得益于两块GPU的强大计算能力。
Stanford大学的研究人员提出了基于GPU阵列和分布式运算加速神经网络的计算框架[21]。这个由16个GPU组成的GPU阵列,能够训练比1 000 CPU的Google集群大6.5倍规模的深度神经网络。巨大的实用性使得基于GPU的人工神经网络受到科研机构和IT企业的重视,是GPU能用计算研究热点。
5.2 群体智能优化算法
群体智能优化算法是一类基于群体的启发式随机优化算法,在工程和科学领域有着广泛的应用。然而,群体算法优化过程中需要对目标函数进行大量的评估,这也极大的限制了群体算法在某些问题中的应用。群体算法的内在并行性,使得它们可以很好地利用GPU多核心、高度并行的特性。
Zhou等[22]最早利用GPU进行PSO算法的加速工作,在当时的硬件条件下,取得了8X倍的加速比。随后,基于GPU的PSO变种及多目标群体算也相继被提出[23-24]。
作为典型的基于GPU的群体智能优化方法实现,Ding等[25]提出了基于GPU并行加速的烟花算法(GPU-FWA)[26]。图 12 示意了烟花算法基于GPU实现的基本流程。
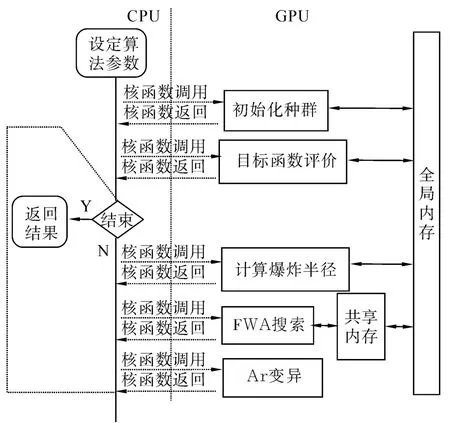
图12 基于GPU的烟花算法实现示意图Fig.12 Diagram of GPU-FWA
GPU-FWA充分利用了GPU内存层级结构,主要数据通讯被限制在共享内存之间,从而减少了数据传输开销。同时,GPU-FWA通过一种改进后的交互机制,进一步提高了运行速度。在对经典基准测试函数上的测试表明,GPU-FWA相对于传统基于CPU的烟花算法,加速近200倍。
群体智能优化方法也在大量实际问题获得良好应用。Rymut等[27]实现的GPU版本的基于PSO的体追踪算法提速20~40倍。Mussi等[28]实现的基于异步PSO的人体追踪算法,将原程序由CPU端的几分钟,提升到了几秒钟内完成,实现了跟踪的实时性,提高的算法的实用性。Nobile等[29]将GPU多种群PSO应用于生物系统的参数估计,运行时间从6 h缩减到14 min,大大加快了参数选择过程。利用GPU加速群体算法,不仅提高了原有应用的速度,而且也扩展了群体优化方法的应用范围。新的基于GPU的群体算法的应用在不断的出现,成研究的热点。
6 分析与讨论
6.1 GPU通用计算的缺点
首先,并非所有的计算任务都适合利用GPU进行计算。GPU适用于存在大量的数据并行性并且数据之间无复杂逻辑依赖的计算任务(典型的如矩阵计算)。对于存在复杂逻辑和随机读写的应用场景,GPU可能并不是最佳的选择。
其次,GPU对于算数运算的支持还有待提高。虽然现在主流GPU都支持符合IEEE标准的浮点运算,但在对双精度浮点的支持上还有待提高。例如,经验表明,对于同样的网络结构和训练方法,使用单精度运算的出错概率要明显高于双精度运算。同时,普通消费级别的GPU不支持ECC校验,这一点在开发对运算可靠性要求较高的应用时需要特别注意。
同常规的并行编程一样,GPU的高度并行性也使得程序的调试工作较为困难。虽然已有大量工具可以用来辅助调试,但对于逻辑错误等的调试依然是一项艰巨的挑战。
另外,目前基于GPU开发的程序在可移植上还存在不足。CUDA由于其简易性和相对完善的生态,在GPGPU领域处于绝对的领先地位,然而它仅仅支持NVIDIA的GPU。基于开放标准的OpenCL的程序虽然具有移植性,但是移植性能情况取决于硬件平台OpenCL驱动性能。目前,OpenCL的流行度正在不断提升,软硬件厂商对OpenCL支持力度也在不断增大。在未来几年,GPU编程的可移植性有望逐渐改善。
6.2 GPU通用计算发展趋势
由于智能手机、平板电脑和可穿戴设备的普及,以及人们对于语音、视频等多媒体资源需要的不断高涨,GPU也在这是相对新兴的领域得到广泛应用。未来,GPU通用计算也很有可能在这些领域发挥重要影响,有望在这一领域带来一场计算变革。而这些非传统的计算设备往往具有低功耗和嵌入式的特点,这也给GPU计算带来了新的挑战[30,31]。
互联网的日新月异,大数据的来势汹汹,也为大规模服务器端计算带来了巨大的挑战。将GPU用于服务器将是应对挑战的一种潜在的应对方案。由于GPU缺乏CPU的通用性和灵活性,选择合适的组织方式便尤为重要。一种可能的方案是将GPU和CPU按照一定的比例组合(例如,一个计算结点配置若干数量的CPU和GPU)。目前,针对GPU阵列或分布式集群,已经有一些硬件连接解决方案和中间件支持。然而,这CPU和GPU之间的通信可能带来潜在的性能瓶颈。混合架构是另一种可能的选择方案。例如,AMD等硬件厂商提出HSA(heterogeneous system architecture)概念,试图将 GPU和CPU在物理架构上进行深度整合,通过共享物理内存方式减小通信开销。由于基于HAS这一新型体系结构的硬件还未大规模面世,因此其性能还有待在理论和实践中进一步检验。
7 结束语
在计算领域,已经从多核时代跨向众核时代,具有众核架构的GPU已经进入高性能计算的主流行列。目前,GPU通用编程的软硬件平台已经相对成熟,成为了计算领域的重要力量。GPU能以相对低廉的价格提供巨大的计算能力,从而获得了广泛的应用。GPU通用计算的普及,使个人和小型机构能有机会获得以往昂贵的大型、超级计算机才能提供的计算能力。可以说,GPU在一定程度上改变了计算领域的格局和编程开发模式。
GPU高度并行的特点使得GPU能够高效地实现计算智能算法,以应对大规模复杂问题,并且已经在人工神经网络和群体智能优化算法等方面获得了大量的成功应用。GPU已经成为深度学习领域中事实上的标准计算平台,在图像、语音自然语言处理等领域发挥着不可替代的作用。基于多GPU和GPU集群的深度网络实现与训练,也是深度学习领域的研究热点。群体智能优化方法以其内在并行性,在GPU平台获得了良好的加速效果,从而扩大了群体算法求解问题的规模和范围。随着多目标优化应用和研究的日益广泛,基于GPU的多目标群体智能优化方法将逐步流行,以更好地应对大规模复杂优化问题。
总之,作为通用计算单元,GPU将以更加多样化的形式活跃在智能计算及其他计算领域。
[1]OWENS J D,LUEBKE D,GOVINDARAJU N,et al.A survey of general-purpose computation on graphics hardware[J].Computer Graphics Forum,2007,26(1):80-113.
[2]OWENS J D,LUEBKE D,GOVINDARAJU N,et al.GPU computing[J].Proceedings of the IEEE,2008,96(5):879-899.
[3]SUTTER H.The free lunch is over:a fundamental turn toward concurrency in software[J].Dr.Dobb’s Journal,2005,30(3):202-210.
[4]ROSS P E.Why CPU frequency stalled[J].Spectrum,2008,45(4):72-78.
[5]BORKAR S.Getting gigascale chips:challenges and opportunities in continuing Moore's Law[J].Queue,2003,1(7):26-33.
[6]NVIDIA.CUDA C programming guide v6.5[R].Santa Clara,CA,USA:NVIDIA Corporation,2014.
[7]JARARWEH Y,JARRAH M,BOUSSELHAM A,et al.GPU-based personal supercomputing[C]//2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies.Amman,2013:1-5.
[8]KAPASI U J,RIXNER S,DALLY W J,et al.Programmable stream processors[J].Computer,2003,36(8):54-62.
[9]BUCK I,FOLEY T,HORN D,et al.Brook for GPUs:stream computing on graphics hardware[J].ACM Transactions on Graphics,2004,23(3):777-786.
[10]Microsoft.C++accelerated massive parallelism[Z].Redmond,WA,USA:Microsoft,2013.
[11]NVIDIA.CUDA C best practices guide version 4.1[R].Santa Clara,CA,USA:NVIDIA Corporation,2012.
[12]NVIDIA.GPU-Accelerated Libraries[OL/EB].[2015-01-05].https://developer.nvidia.com/gpu-accelerated-libraries.
[13]JIA Y,SHELHAMER E,DONAHUE J,et al.Caffe:convolutional architecture for fast feature embedding[C]//Proceedings of the ACM International Conference on Multimedia,[s.l.],2014:675-678.
[14]GASTER B,HOWES L,KAELI D R,等.OpenCL异构计算[M].北京:清华大学出版社,2012:10-35.
[15]KIRK D B,HWU W W.Programming massively parallel processors:a Hands-on approach[M].Beijing:Tsinghua University Press,2010:205-220.
[16]MUNSHI A,GASTER B,MATTSON T G,et al.OpenCL Programming Guide[M].Boston:Addison_Wesley Professional,2011:63-68.
[17]AMD上海研发中心.跨平台的多核与从核编程讲义——OpenCL 的方式[M].上海:AMD,2010:1-154.
[18]FARBER R.高性能CUDA应用设计与开发[M].北京:机械工业出版社,2013:1-49.
[19]ZEILER M,FERGUS R.Visualizing and understanding convolutional networks[C]//Proceedings of the 13th European Conference on Computer Vision.Zurich,Switzerland,2014:818-833.
[20]HINTON G,OSINDERO S,WELLING M,et al.Unsupervised discovery of nonlinear structure using contrastive backpropagation[J].Nature,2006,30(4):725-731.
[21]KRIZHEVSKY A,SUTSKEVER I,HINTON G.Imagenet classification with deep convolutionalneuralnetworks[C]//Advances in Neural Information Processing Systems 25.Reno,Nevada,USA,2012:1106-1114.
[22]COATES A,HUVAL B,WANG T,et al.Deep learning with COTS HPC systems[C]//Proceedings of the 30th International Conference on Machine Learning.Atlanta,USA,2013:1337-1345.
[23]ZHOU Y,TAN Y.GPU-based parallel particle swarm optimization[C]//IEEE Congress on Evolutionary Computation.Trondheim,Norway,2009:1493-1500.
[24]ZHOU Y,TAN Y.Particle swarm optimization with triggered mutation and its implementation based on GPU[C]//GECCO'10:Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation.Portland,Oregon,USA,2010:1-8.
[25]ZHOU Y,TAN Y.GPU-based parallel multi-objective particle swarm optimization[J].International Journal of Artificial Intelligence,2011,7(A11):125-141.
[26]DING K,TAN Y.A GPU-based parallel fireworks algorithm for optimization[C]//GECCO'13:Proceedings of the Fifteenth Annual Conference on Genetic and Evolutionary Computation Conference.Amsterdam,the Netherlands,2013:9-16.
[27]TAN Y,ZHU Y.Fireworks algorithm for optimization[C]//First International Conference of Swarm Intelligence.Beijing,China,2010:355-364.
[28]RYMUT B,KWOLEK B.GPU-supported object tracking using adaptive appearance models and particle swarm optimization[C]//International Conference on Computer Vi-sion and Graphics,Warsaw,Poland,2010:227-234.
[29]MUSSI L,IVEKOVIC S,CAGNONI S.Markerless articulated human body tracking from multi-view video with GPU-PSO[C]//9th International Conference on Environmental Systems.York,UK,2010:97-108.
[30]NOBILE M S,BESOZZI D,CAZZANIGA P,et al.A GPU-based multi-swarm PSO method for parameter estimation in stochastic biological systems exploiting discretetime target series[C]//10th European Conference on Evolutionary Computation,Machine Learning and Data Mining in Computational Biology.Málaga,Spain,2012,7246:74-85.
[31]MAGHAZEH A,BORDOLOI UD,ELES P,et al.General purpose computing on low-power embedded GPUs:has it come of age[R].Linköping University Electronic Press,2013.
[32]HALLMANS D,SANDSTROM K,LINDGREN M,et al.GPGPU for industrial control systems[C]//2013 IEEE 18th Conference on Emerging Technologies Factory Automation.Cagliari,Italy,2013:1-4.
