基于主成分分析法及贝叶斯分类器的手写数字识别
2015-11-23尹东霞
尹东霞
(山东科技大学网络与信息中心,山东 青岛 266590)
基于主成分分析法及贝叶斯分类器的手写数字识别
尹东霞
(山东科技大学网络与信息中心,山东 青岛 266590)
针对目前手写数字难识别并且识别正确率低这一现象,提出了一套基于主成分分析法及贝叶斯分类器的手写数字识别方法。该方案首先利用主成分分析法减小输入数据的维数,而后把降维的数据作为训练过的贝叶斯分类器的输入,从而得到对于输入的手写数字的识别。在 MNIST手写数字数据集上该方法能够达到96.35%的识别率。该仿真结果说明文章提出的手写数字识别策略能够实现对手写数字的高效的识别。
手写数字识别;主成分分析法;贝叶斯分类器
1 引言
对于手写数字的识别是人们日常生活需要完成的任务之一。在人们日常的生活中,每个人每天都需要与数字打交道。在以往,对手写数字的识别多采用人工的方式。但是在现代化及信息化高度发达的时代,如何实现用计算机或者现代计算机器实现对于手写数字的高效快速的识别是一个亟需解决的问题。随着社会的发展以及经济的发展,每天需要处理的数据的数目在急剧增加,在需要处理的数据中,手写数字由于其难识别性等特点,成为阻碍大规模机器处理数据的难点,所以实现手写数字的高效快速识别是一项重要的任务。但是由于不同的人具有不用的字体,同时很可能存在书写不规范的现象,手写数字的识别是一个极其复杂的过程。针对目前手写数字难识别并且分辨正确率低这一现象,提出了一套基于主成分分析法(PCA)及贝叶斯分类器的手写数字识别方法。该方案首先利用主成分分析法减小输入数据的维数,而后把降维的数据作为训练过的贝叶斯分类器的输入,从而得到对于输入的手写数字的识别。
文章的章节安排如下:第一部分为引言,为第一节;在第二部分中,介绍本文采用的主成分分析法以及贝叶斯分类器,为第二节和第三节;在最后一部分,在MNIST数据集上对本文提出手写数字识别方法进行验证,为第四节。
2 主成分分析法
PCA(或称主分量分析)作为一种多元统计技术,是一种建立在统计特征基础上的多维正交线性变换,常用来对信号进行特征提取和对数据进行降维,是由Pearson于1901年首先提出其概念,随后由Hotelling、J.E.Jackson等学者对其进行了发展[1],后来研究者们用概率论的形式再次描述了主成分分析算法,使得 PCA法得到更进一步的理论上的发展。现今国内外已有很多学者对其进行了研究,它广泛应用于化学、模式识别、图像处理等各个领域[2],不同应用领域其被赋予不同名称,如KL变换(Karhunen-Loeve Transform)、霍特林变换(Hotelling Transform)、子空间法 (Subspace Approach)和特征结构法(Eigen-structure Approach)等[3,4]。
PCA作为一种最常用的数据降维算法,同时也可看作是一种掌握事物主要矛盾的多元统计分析方法,是最为常用的特征提取方法,一直受到人们的关注和研究。它通过对原始数据进行加工处理,使得问题处理的难度和复杂度大大简化,可以提高数据的信噪比,以改善原始数据的抗千扰能力。主成分分析法(Principal Component Analysis,PCA)的原理是利用一个特殊的特征向量矩阵U,将一个具有高维数的向量投影到一个低维的向量空间中,在这个过程中应该保证尽可能少的损失了重要信息,仅损失一些次要信息。该过程的逆过程为通过低维表征的向量和特征向量矩阵,可以重构或者大体重构出出所对应的原始高维向量。
本文针对手写数字的特点,设计通过空间投影的方式减少输入数据的维数,通过计算图像矩阵的协方差矩阵,选择出变化比较大同时区分度比较明显的像素点,并且形成投影矩阵,通过投影矩阵把原数据投影到投影空间中,该过程应该保证手写数字图像损失信息越少越好,即保证原数据与投影数据之间的空间距离越小越好。
3 贝叶斯分类器
贝叶斯分类器是建立在贝叶斯理论基础上的分类器,主要应用某个对象或者数据的先验概率,而后利用贝叶斯理论计算出后验概率,然后选择能够最大化后验概率的作为对象或者数据的属性。
上述的过程可以简化为下面的情况:假设某个对象具有m个属性,F1,F2,…,Fm。现在具有n个类,C1,C2,…,Cn。现在需要确定一个新的对象属于哪一类,贝叶斯分类器工作过程就是选择出概率最大的那个分类,即最大化公式(1)[5-7]

其中,P(F1,F2,…,Fm)对于同一个体或者对象而言,都是一样的。整个过程就简化为求解P(F1,F2,…,Fm|C)P(C)。
和其他数据挖掘或者模式识别中采用的分类器相同,应用贝叶斯分类器对对象或者数据进行分类的过程可以分成两步:第一步,对模型的训练,即从样本数据中进行学习;第二步是用训练出的模型对数据或者对象进行分类。在模型的训练过程以及后续的识别过程中,模型计算的复杂度会影响计算的效率以及结果。对于贝叶斯分类器而言,往往需要进行简化[8],本文采用主成分分析法来减少贝叶斯分类器的输入属性数目,从而减少训练分类器所消耗的时间。
4 数据集仿真及结果分析
本文采用MNIST手写数字数据集作为本文提出的手写数字识别策略的仿真数据集,该数据集具有60000个训练数据,并且具有10000个测试数据。在MNIST数据集中的数据均是经过大小统一化以及图形集中的固定大小的图像。并且采用MATLAB作为系统仿真软件进行仿真。

图1 MNIST数据集中的数据样式
在本次试验中,采用MNIST数据集中的10000个数据作为整体数据集的代表。MNIST数据集中的部分手写数字如图所示。并且用其中的8000个数据作为训练样本明确主成分分析的下降维数和训练贝叶斯分类器,剩下的 2000样本作为测试样本对于训练出的贝叶斯分类器进行验证。
MNIST数据集中的每一个数据为一个28*28像素点的图像,一共784维数据。这对于后续的贝叶斯分类器意味着其具有784维的输入数据,这样不仅会增加贝叶斯分类器的训练成本,而且会增加后续计算的时间。所以对于784维的输入数据,首先应该对其进行降维处理。本文采用主成分分析法对输入的训练以及测试样本数据降维。对于主成分分析法而言,应该需要明确需要选择哪几个维度进行投影,维度应该满足尽可能少的同时满足一定准确性。
在确定 PCA降低维数的过程中,采用相应的平方差的方式对数据进行衡量。数据的降维可以理解为原数据向数据空间内的某个平面进行投影,由于降维的存在,降维后的数据相比原数据会损失一部分信息,需要尽可能的减小原数据与降维后的数据之间的空间距离。
通过选取不同的数量的主成分,能够发现如图2所示的规律曲线。其中坐标的横轴为选取的主成分的数目,经过投影矩阵的变换,原数据与投影数据之间存在误差,全体数据的误差由纵轴表示。通过图像可以发现,当主成分数目位于30到50之间时,总体误差大概为1000左右,平均误差为0.125。并且通过计算原数据的协方差矩阵的特征值,并选取最大特征值的0.05作为选取主成分的阈值,小于阈值的笔者认为具有不重要的信息,通过选择的特征值能够得到相应的投影矩阵。通过主成分数目与数据误差之间的妥协,主成分数目应该选择为37。
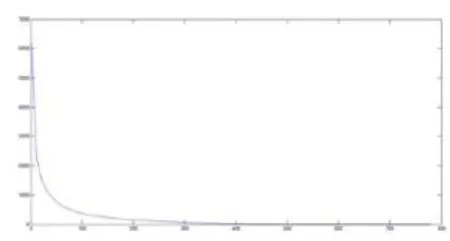
图2 主成分数目与数据平均差之间关系
MATLAB的仿真结果表明,对于2000个数据的测试集进行验证,识别错误的数目为73,正确率达到96.35%。混淆矩阵如图3所示。
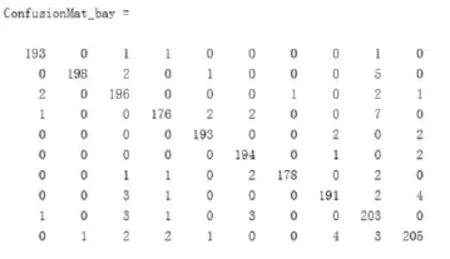
图3 混淆矩阵
通过实验结果能够发现,被错误识别的数字分布的比较平均,并且为实际的书写中容易被肉眼错误识别的数字。
综上所示,书写数字识别的全过程如图4所示。
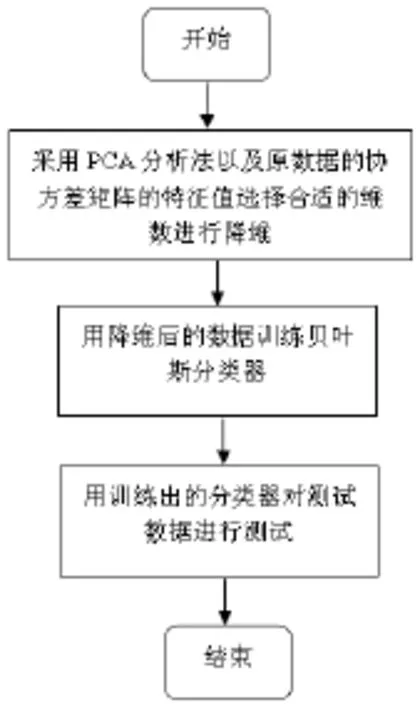
图4 书写数字识别全过程
5 结论
本文提出了一套基于主成分分析法及贝叶斯分类器的手写数字识别方法。该方法首先利用主成分分析法以及原数据协方差矩阵的特征值减小输入数据的维数,而后把降维的数据作为训练过的贝叶斯分类器的输入,从而得到对于输入的手写数字的识别。在MNIST手写数字数据集上该方法能够达到96.35%的识别率。
[1] 张媛,张燕平.一种 PCA算法及其应用[J].微机发展,2005, 15(2):67-69.
[2] K. Pearson, P. Mag. On lines and planes of closest fit to systems of points in space[J].1901,(2):559-572.
[3] D.E.Johnson.Applied multivariate methods for data analysis[M]. Beijing:Higher Education Press,2005:93-111.
[4] 佘映,王斌,张立明.一种面向数据学习的快速PCA算法[J].模式识别与人工智能,2009,22(4):568-573.
[5] 费爱蓉.基于贝叶斯方法的Web服务分类的研究[D].安徽:合肥工业大学,2004.
[6] 徐磊.基于贝叶斯网络的突发事件应急决策信息分析方法研究[D].黑龙江:哈尔滨工业大学,2013.
[7] 邸俊鹏.分位数回归的贝叶斯估计与应用研究[D].天津:南开大学,2013.
[8] 任晓明,李章吕.贝叶斯决策理论的发展概况和研究动态[J].科学技术哲学研究,2013,(2):1-7.
The identification of Hand-written digits based on Principal Component Analysis and Bayesian classifier
To deal with the low discrimination and low accuracy of the hand-written digits,this paper proposed a hand-written digits identification method which is based on the Principal Component Analysis (PCA) and the Bayesian classifier.This scheme employs the PCA to reduces the dimension of the input data,then the dimension-reduced data is regarded as the input for the Bayesian classifier,the result of the classifier is the identified digits.This method achieves the accuracy of 96.35% on the MNIST hand-written digits data set.The case study shows that the hand-written digit identification scheme this paper proposed can identify the hand-written digits effectively.
Hand-written digits identification; Principal Component Analysis(PCA);Bayesian classifier
TM732
A
1008-1151(2015)09-0039-03
2015-08-15
尹东霞(1964-),女,山东青岛人,山东科技大学网络与信息中心高级工程师,从事校园网络管理与服务工作。
